
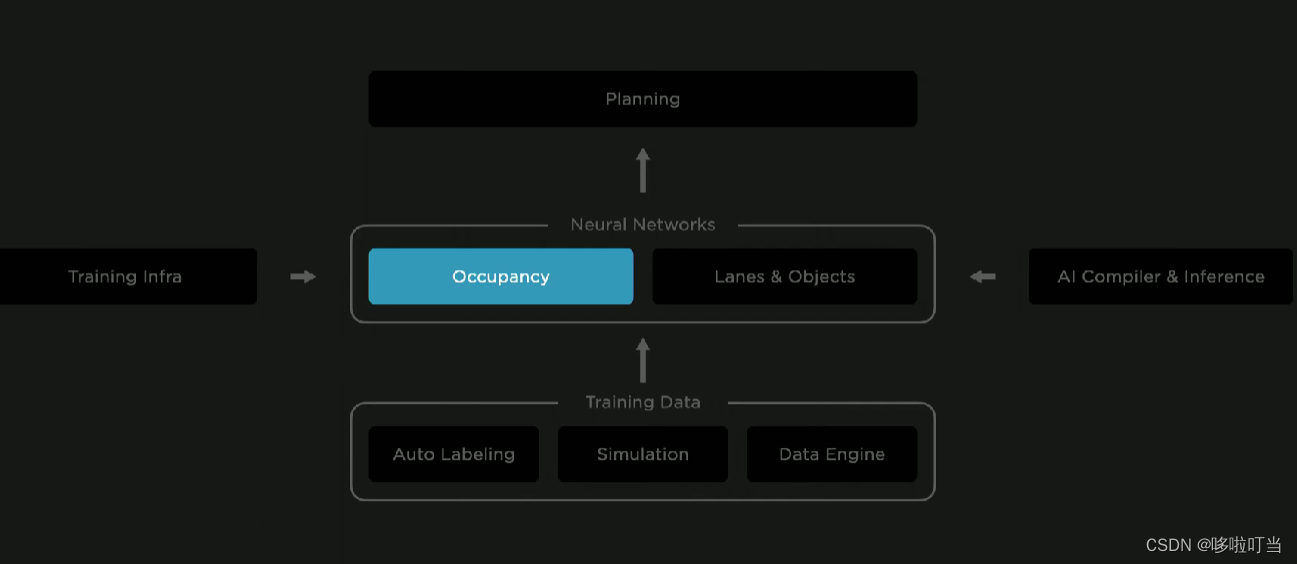
这是特斯拉的全自动驾驶(Full Self Driver)技术结构图,图中把自动驾驶模型拆分出分成了几个依赖的模块:
技术底座:自动标注技术处理大量数据,仿真技术创造图片数据,大数据引擎进不断地更新(大模型的数据基础)
核心部分:神经网络对场景的识别和理解(不仅仅是视觉技术的运用,结合了自然语言处理领域技术)
- 提出占有网络,这个网络能够实时地识别周围环境中各种物体的占有率,然后进行立体建模,体素化,还能够实现预测物体未来的运动趋势
- 然后进一步识别各种车道线,解决各种车道线交错的难题
增强神经网络的资源:AI训练集群,AI优化编译、接口
最终的目的是实现车端大模型直接处理原始的视频,做自动驾驶决策
基于Attention机制的占用网络
占有网络是特斯拉FSD中的核心部分,目的是识别周围物体占用空间中的部分,对空间做一个建模,并且区分物体,赋予不同的语义,然后还能够预测物体未来的变化趋势,即预测物体运动。
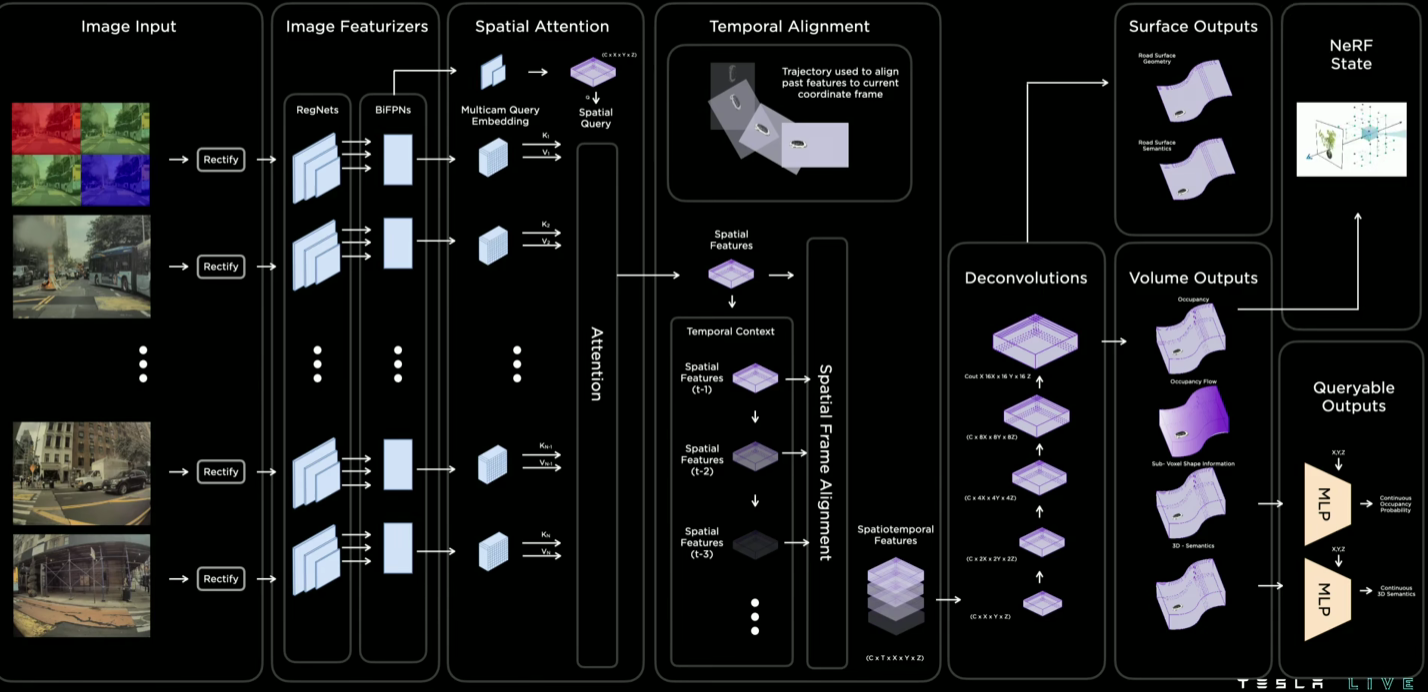
这个是Occupancy整体工作原理示意图,具体的流程如下:
- 输入图像校准,使用12位的原始图像,而非8位,这么做是因为可以获得更多的4位图像信息和16倍动态范围。
- 图片特征提取,用RegNet+BiFPN来实现图片的卷积特增提取和多尺度特征的提取结合
- Spatial Attention空间注意力机制,这里先把图片加上相机特征做embedding,这样子Spatial Query就蕴含了空间位置信息,即含有三维空间特征的Query和二维的图片特征的Value做注意力机制。Attention实现了对多个相机的3D空间位置信息和2D图像的信息融合,模型从中学习对应的特征关系,最终输出高维的空间特征。
- Temporal Alignment时空对齐,获得时空特征数据,利用行车的轨迹结合Attention得到的空间特征,做Channel维度的拼接,输出会进入反卷积的部分
- 反卷积和体积空间输出,把时空特征数据做反卷积,得到空间占用流的输出
- 上一步得到的体素化是不够精确的,于是进一步设计了一个Queryable MLP部分来提高分辨率。这部分其实是多层感知机的解码器,用于对于生成任务。主要流程就是生成每个体素特征图,并将其输入到 MLP 中,以此进一步生产获得连续的体素语义,占用流信息,这也实现了对未来行为的预测
- 在反卷积后还输出表面的信息,目的是为了在坡道,弯曲路面灯地方实现精确的控制。表面和体素化的输出预测不是独立的,内在他们其实是一致的
- 最后基于生成的体素化信息结合NERF模型可以尝试还原真实的场景,这还需要未来的研究和探索
在特斯拉介绍的占有网络中,中间特征的学习部分用到了Attention的思想,即Spatial Attention部分。当我们用卷积网络去识别图像时,卷积核识的都是图像的局部信息,但是其实图像识别的时候每个部分对于识别的正确性的影响是不同的。注意力机制的引入就是为了解决这个问题,其实就是模拟人看图片时能够注意到的重点,抛弃不重要的局部信息。
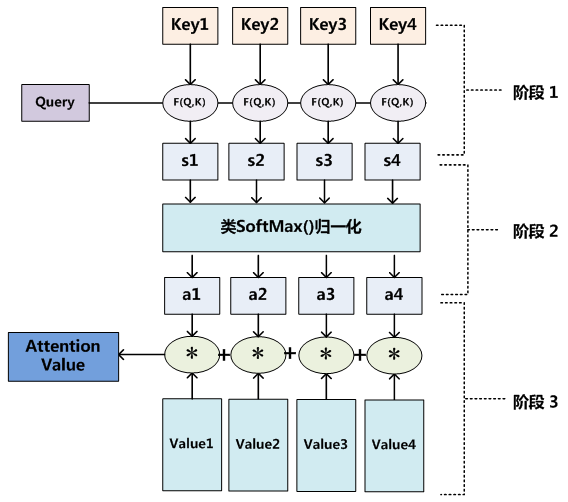
这个图片画出Attention计算的三个阶段,结合前面特斯拉的介绍可以进一步理解Attention被结合在占有网络这个视觉任务中的意义。找图片的特点其实就是找图片的图片的特征,构造Query矩阵来查找特征。占有网络这里用的是Spatial Query,就是结合了空间信息的一个询问。这里面比较特殊的地方是被询问的Value是来自图片,图片一开始是二维的,使用图片的特征信息都是源于二维的。通过Q*K做计算,然后更新Attention Value。这么做注意力机制的目的其实就是学习到他们之间的相关性,即三维特征和二维特征的联系,让模型学习图片中对应的物体占有的空间。学习到了这些就代表有了根据二维图片和相机空间位置对应三维空间中物体实际位置和体积的能力,依照这个思路特斯拉的占有网络才能有后面进一步训练和计算然以及体素化重建空间。

在上面这个图片中蓝色代表的是占有网络预测的部分。在这里占有网络很容易就预测到了大巴要转弯的动作且很好地拟合了体积,这在传统的视觉技术上是很复杂的问题,可以看作是多个层长方体的拟合,但是这个地方简化成了空间被占有的部分,模型就更容易理解和拟合了。对于坡面也是如此,占有网络可以更快更准确实现地面的预测。
来语言模型的灵感

之前的神经网络已经实现了分割当前行驶的车道线和其他的车道线,这个是在汽车驾驶环境比较单一的时候才比较好用,比如高速公路保持行驶。但是现实中会有很多的线条交错的场景,比如在一个多分叉的路口,这种地方分割、识别车道线就不好用了,只有进一步研究车道线之间的拓扑连接关系,才能实现更好的规划。
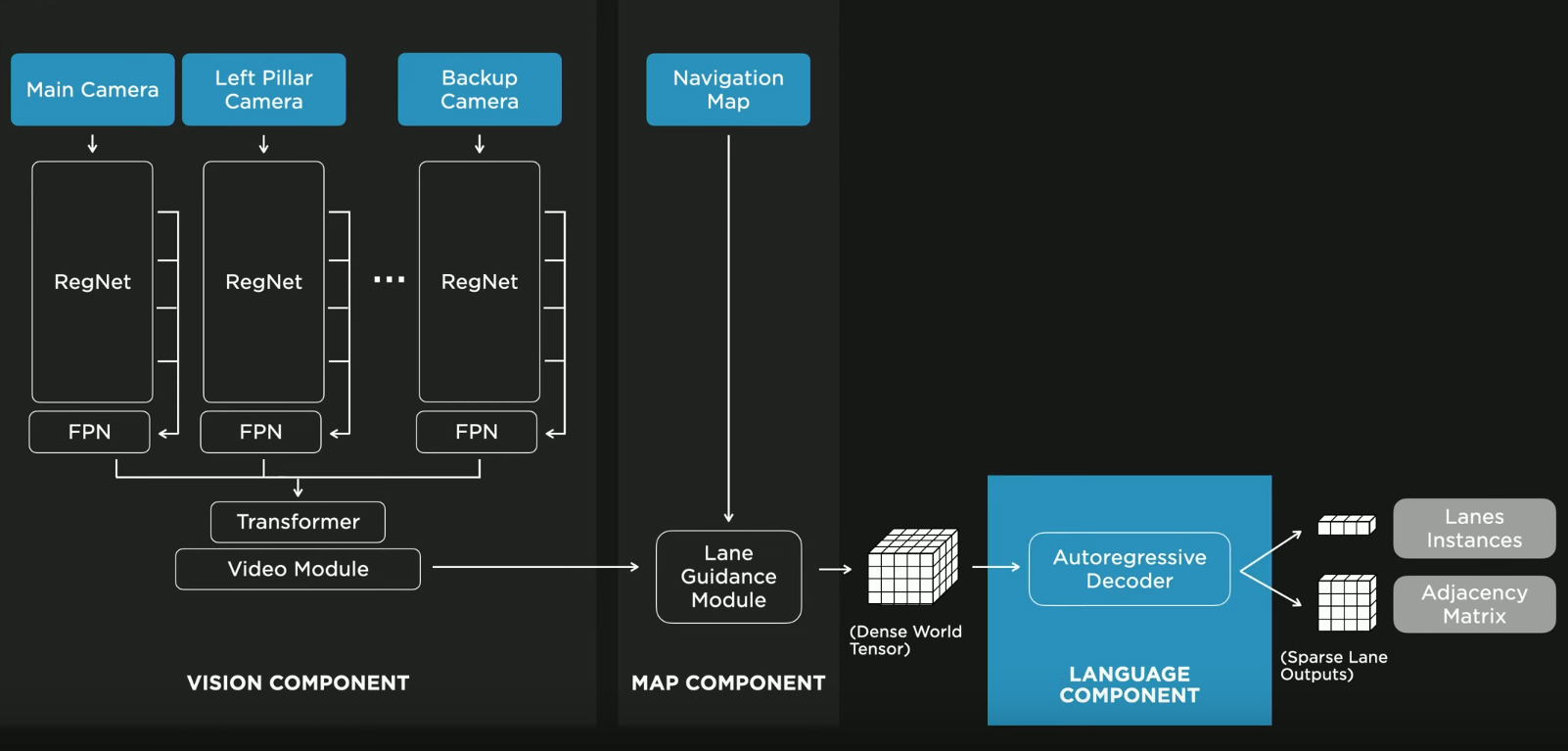
特斯拉车道神经网络Lanes Neural Network示意图,网络主要是由三个部分组成:Vision,Map,Language。
Vision部分是采集车身上的摄像头的视频流做一个编码,并且希望他产生丰富的视觉内容,所以这里用到了卷积层,注意力层等提取特征,任何用到Transformer做编码。
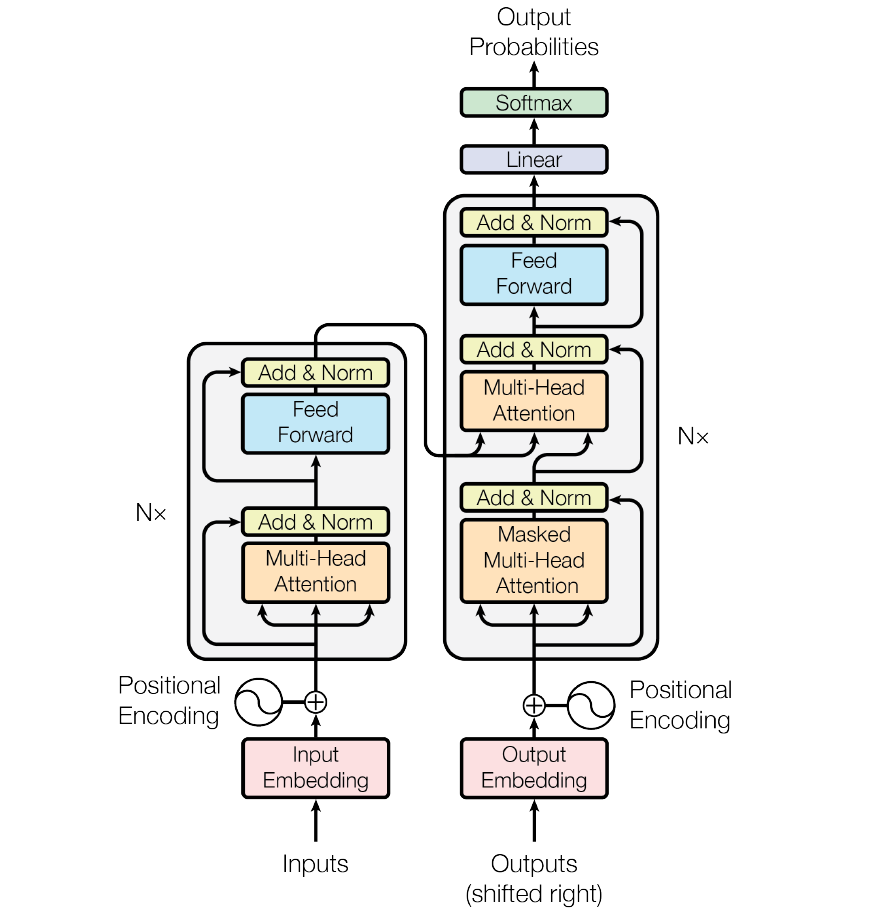
这是Transformer的结构示意图,可以发现它是由编解码两块组成的,Encoder和Decoder。特斯拉在这里使用Transformer来进行编码是认为Encoder能够实现图片的基于位置的编码,然后里面的自注意力和多头注意力可以学习到很多有用的特征,输出的是蕴含内容十分丰富的向量,有助于下一步的训练。
Map部分是结合粗糙地图数据做进一步的增强,即使这里是低精度的地图,但是已经包含了在交叉口车道的拓扑信息。车道和车道数信息都在其中,把这些信息和前面Transformer产生出的蕴含丰富信息的向量编码进行融合,经过重新编码后再拿来训练可以学习到很多有用的信息。最终Vision模块和Map模块结合后输出了Dense World Tensor这个多维度且内容十分丰富的向量,这个向量就是对于周围世界信息的编码。接下来再输入第三个Language部分。
第三个部分之所以取名Language是结合了自然语言处理的思路。特斯拉在这个部分把车道相关信息和各种的车道节点位置、点位属性:起点、终点、分叉、合并等以及车道曲线几何参数进行编码。这个编码是基于创造新语言单词的思路去做的。目的就是实现了一种视觉问题到语言问题的转换,用这些创造出来的词组成句,帮助描述他们各种图像场景,这样就能够进一步去使用当前先进的自然语言处理技术来尝试解决问题。
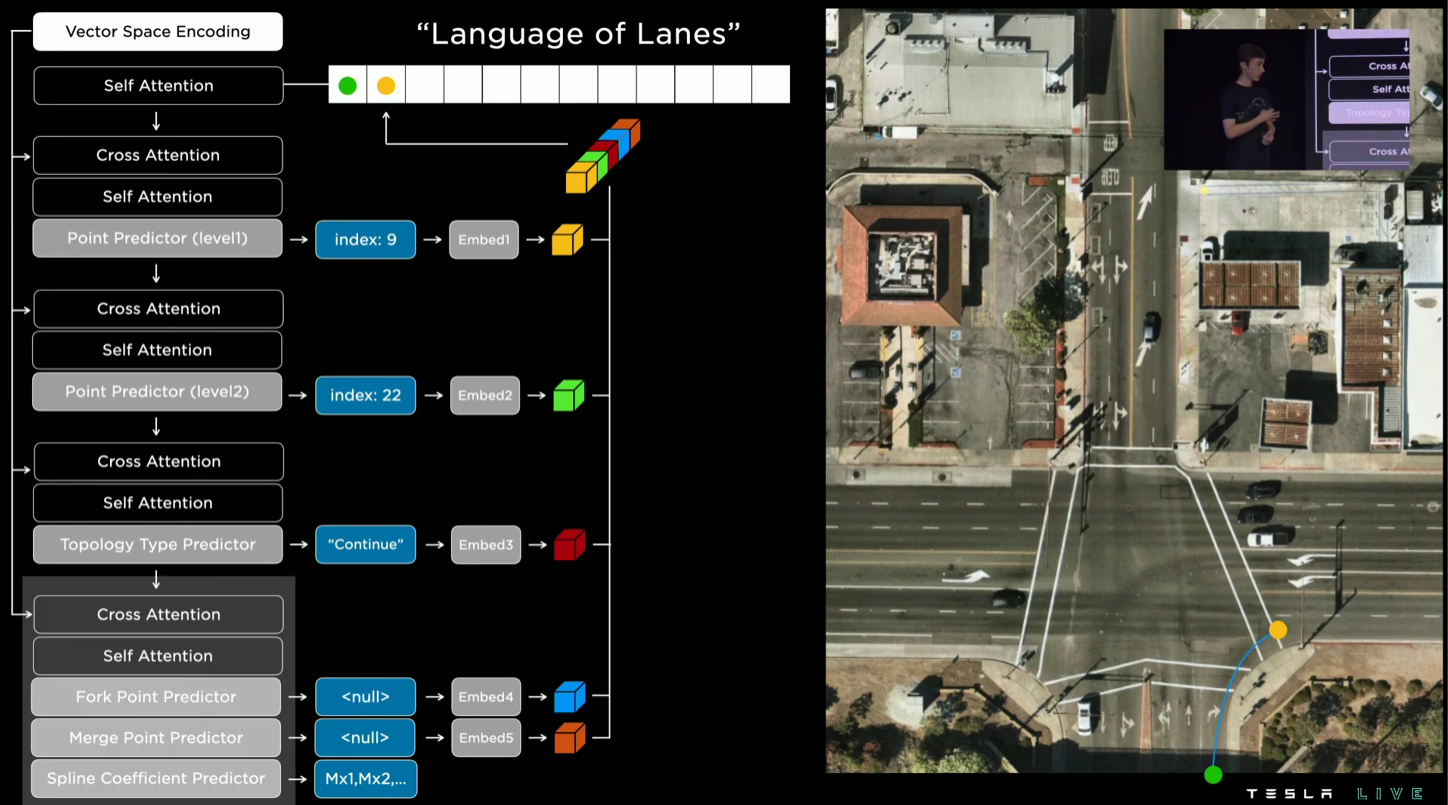
这是Language of Lanes的流程演示。这是一个Self Attention的过程。直接把整个图片分成很多的点,然后直接预测车道线是不可行的,计算成本很高。他们的思路是先选取一个粗略的点,即第一集的点预测,目的是划分出一个可行的预测区域,然后再进一步改进,得到准确的点,就是二级预测的结果。一级和二级的操作是重复的。然后对于这个点就能够预测他的类型,这个是利用到了前面提到的编码。最后一步是结合判断是否为分叉点,合并点并且用回归的方式做线条的拟合。最终得到的结果会加入句子,即更新Attention的结果。
可以注意到在获得车道线的语言的过程中除了自注意力机制Self Attention之外还用到了交叉注意力机制Cross Attention。这两者之间是有区别的,后者可以看作是对前者思想的一个扩展,自注意力机制是在当前的序列中获取上下文信息,而交叉注意力是让模型在两个序列之间建立交互。在特斯拉的任务中,交替使用这两种Attention可以让模型结合整体和局部的各种信息,学习到其中的关联性和依赖性。

Language of Lanes最终就是表示了一组车道线的连接关系。因为是语言描述的场景,所以还能实现行为的预测。比如上图这个场景,有一辆车是因为事故停在了红绿灯前面,而有一个车是走到红绿灯前减速停车等红灯,模型有了语言的描述,就能够从语义中理解和识别场景里面的物体并预测行为,从而实现避让这个场景中的事故车辆的智能驾驶动作。
版权归原作者 哆啦叮当 所有, 如有侵权,请联系我们删除。