
分类问题
分类:根据已知样本的某些特征,判断一个新的样本属于哪种已知的样本类
垃圾分类、图像分类
怎么解决分类问题

分类和回归的区别

1. 逻辑回归分类
用于解决分类问题的一种模型。根据数据特征或属性,计算其归属于某一类别
的概率P,根据概率数值判断其所属类别。主要应用场景:二分类问题。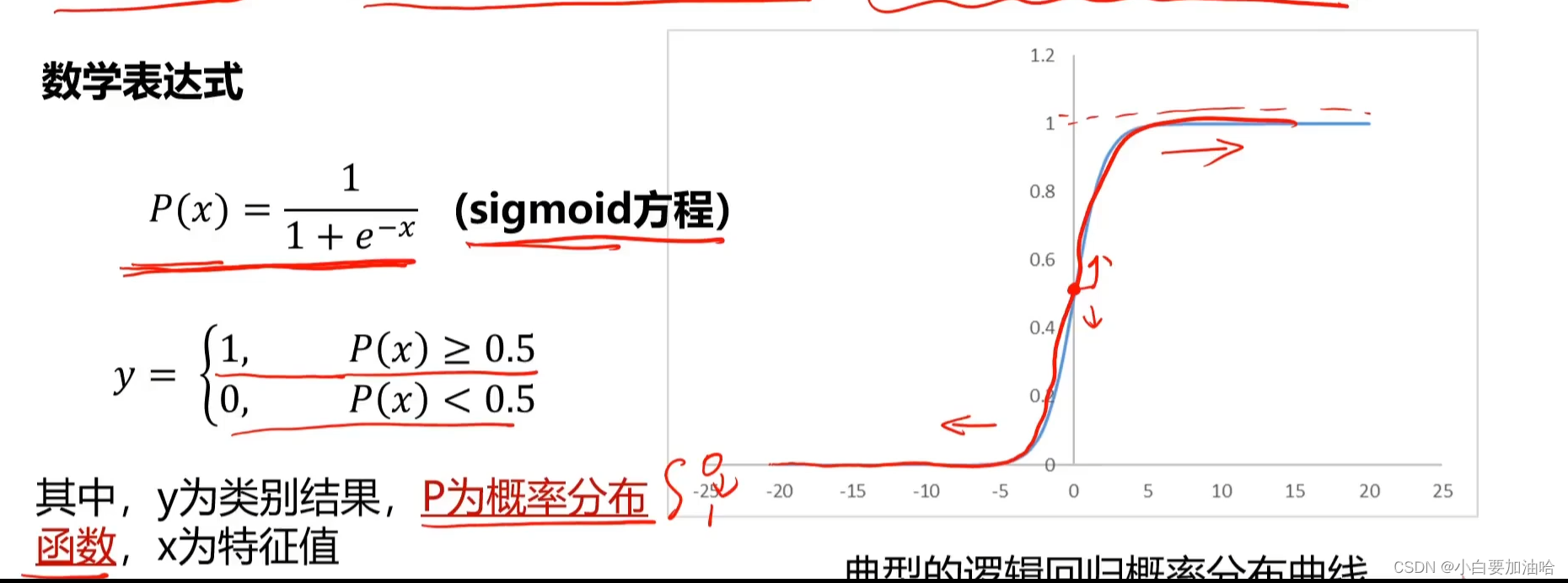
1. 谈谈你对机器学习的理解,包括回归和分类的相同点和不同点
机器学习是一种通过数据(经验)和算法让计算机从中学习并改善系统自身的性能的技术。
回归和分类的相同点:
预测性质:回归和分类都是用来预测未知数据的属性或类别。
监督学习:这两种任务都属于监督学习的范畴,即训练数据集包含了输入和相应的输出(标签)。
使用模型:它们都需要构建一个数学模型,该模型能够从训练数据中学习,然后用于对新数据进行预测。
回归和分类的不同点:
预测目标:
回归的目标是预测连续型变量的数值,例如房价、温度等。回归问题的输出是一个连续的数值。
分类的目标是预测离散的类别或标签,例如判断邮件是否为垃圾邮件、图片中的物体类别等。分类问题的输出是一个离散的类别。
输出类型:
回归的输出是连续的实数值,可以是任意范围内的数字。
分类的输出是离散的类别,通常是有限的、预定义的标签集合。
评估指标:
回归问题通常使用诸如均方误差(Mean Squared Error, MSE)、均方根误差(Root Mean Squared Error, RMSE)等连续型指标来评估预测结果的准确性。
分类问题通常使用准确率(Accuracy)、精确率(Precision)、召回率(Recall)等离散型指标来评估模型的性能。
2. 简述机器学习的流程
抽象实际问题,获取数据,数据预处理,特征工程,训练模型及调优,模型评估不断迭代模型,获取最终模型
3. 简述监督学习与无监督学习之间的区别
数据类型:监督学习使用有标签的数据,无监督学习使用无标签的数据。
目标:监督学习旨在预测输出,无监督学习旨在发现数据中的结构和模式。
应用:监督学习用于分类和回归,无监督学习用于聚类、降维等
4. 数据预处理的过程中,对于异常数据处理的方法有哪些
1.删除异常值
2.修正异常值
3.数据变换
4.使用离群值检测算法
5.使用模型
填空题
机器学习
- 机器学习的工作流程:抽象实际问题、获取数据、数据预处理、特征工程、训练模型及调优、模型评估、获取最终模型
- 数据预处理的方法:数据清洗、数据变换、数据过滤
- 特征工程定义:从原始数据中进行特征构建、特征提取、特征选择
- 数据集分为:训练集(用于学习的数据集)、验证集(用来预防过拟合的发生,辅助训练过程的数据集)、测试集(用于测试和评估训练好的模型的数据集)
- 机器学习分为:监督学习、半监督学习、无监督学习
- 监督学习:基于标签训练数据的机器学习模型的过程
- 半监督学习:使用大量的未标记数据、以及同时使用标记数据,来进行模型识别工作
- 无监督学习:建立及其学习模型的过程不依赖标签训练数据
在机器学习中,回归和分类是两种基本的任务类型
- 分类:根据数据的属性或特征是否相似,来把它们归为一类
- 回归:评估输入变量和输出变量之间关系的过程
回归和分类的不同点:
预测目标:
回归的目标是预测连续型变量的数值,例如房价、温度等。回归问题的输出是一个连续的数值。
分类的目标是预测离散的类别或标签,例如判断邮件是否为垃圾邮件、图片中的物体类别等。分类问题的输出是一个离散的类别。
输出类型:
回归的输出是连续的实数值,可以是任意范围内的数字。
分类的输出是离散的类别,通常是有限的、预定义的标签集合。
评估指标:
回归问题通常使用诸如均方误差(Mean Squared Error, MSE)、均方根误差(Root Mean Squared Error, RMSE)等连续型指标来评估预测结果的准确性。
分类问题通常使用准确率(Accuracy)、精确率(Precision)、召回率(Recall)等离散型指标来评估模型的性能。
课本原话
区别在于输出变量类型不同,分类的输出是离散的,回归的输出是连续的,分类问题是从不同类型的数据中学习数据的边界,而回归问题是从同一类型的数据中学习到这种数据中不同维度间的规律,去拟合真实规律
- 数据清洗的目的:将数据集中的”脏“数据去除
- 脏数据:缺少的数据、异常的数据、重复的数据
- 缺少的数据的处理方法:直接删去、填充为一个常量、取均值、中位数或使用频率高的值、插值填充、模型填充
- 异常数据的发现方法:建模法、计算机检查和人工检查相结合、聚类、密度法
- 数据变换:对对象的属性再数值上进行处理,包括规范化、离散化、稀疏化
- sklearn基本功能主要分为:数据预处理、数据降维、模型选择、分类、回归、聚类
逻辑回归分类
逻辑回归定义:用来解释输入变量和输出变量之间关系的一种技术,主要用于二分类问题
- sigmoid()函数:
线性回归预测
线性回归定义:利用数理统计中回归分析来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法
聚类(无标红,非重点)
聚类定义:根据相似性原则,将具有较高相似度的数据对象划分为同一类簇,将具有较高相异度的数据对象划分为不同类簇。(无监督学习)
聚类算法:K-Means算法(K均值算法)
- 初始化质点
- 聚类对象
- 更新质点
第4章 自然语言处理(NLP)
- 自然语言处理工具包:NLTK
- 使用stemming、lemmatization还原词汇
- 词袋模型:文本特征提取方式
- 文本分析的主要目的之一:把文本转化为数值
- 分析文档的步骤:1. 提取文档 2. 转换为数值形式
- 使用TF-IDF算法构建文档类别检测器 作用:对文档所属的类别进行检测 TF-IDF:是一种用于信息检索与数据挖掘的常用加权技术 TF-IDF的值是这两个值的乘积:TF*IDF TF-IDF主要思想:p113 TF-IDF作用:去除过滤常见的词语,从而保留重要的词语
- 主题模型算法不需要任何被标记的数据
- LDA包括三层结构:词、主题、文档(重点)
- LDA是非监督机器学习
课后习题
列出几种文本特征提取算法:词袋模型、TF-IDF、文本主题模型(LDA)
列出几种自然语言处理开源工具包:NLTK、Gensim、TextBlob
第5章 语言识别
将音频信号从时域转换为频域
- 音频信号包括:频率、相位、振幅的正弦波
- 信号的基本性质:时域、频域
- 时域是唯一实际存在的域,真实世界的,频域是一个数学构造,正弦波是频域唯一存在的波形
- 时域的基本变量:时间
- 频域的基本变量:频率
- 将音频信号从时域转换为频域:快速傅里叶变换
提取语音特征
- MFCC:用于从给定音频信号中提取频域特征
- 只使用低频MFCC,丢弃中高频MFCC
- 提取语言特征参数MFCC主要流程:预加重、分帧、加窗、FFT、Mel滤波器组、对数对算、DCT离散余弦变换
课后习题
- 列举几个语言识别技术的应用领域:通信、家电、工业、汽车电子、家庭服务、医疗、消费电子产品
- 简单概述语言识别技术的原理: 先采集并预处理信号,使用数字信号处理技术提取声音的特征,利用声学模型和语言模型分析声音的特征和语言规律,以实现对语音输入的理解和处理
- 实现音频信号从时域转换为频域: 首先将连续的模拟信号采样为离散的数字信号。然后,使用傅里叶变换(如快速傅里叶变换)将离散时域信号转换为频域信号,以分析信号在不同频率上的能量分布。
第6章 计算机视觉
视频中移动物体检测方法
- 帧间差分法
- 色彩空间
- 背景差分法
差分法的实现
- 视频采集
- 图像预处理
- 提取背景
- 二值化
- 获取前景图片
第7章 人工神经网络
- 循环神经网络基本原理:一个序列当前的输入与前面的输出有点联系,在网络会记忆前面的信息并计算当前的输出,隐藏层之间的节点是有连接的,隐藏层的输入包括输入层的输出和上一时刻隐藏层的输出。
简答题(概念)
- 机器学习:机器学习是一种通过数据(经验)和算法让计算机从中学习并改善系统自身的性能的技术,分为监督学习、半监督学习、无监督学习。
- 人工神经网络定义:一种模仿人类大脑结构和作用的数学模型,从而模拟人脑神经系统对复杂信息处理。
- 循环神经网络定义(必考):是对序列数据建模的人工神经网络,目的是处理序列数据。一个序列当前的输入与前面的输出有点联系,在网络会记忆前面的信息并计算当前的输出,隐藏层之间的节点是有连接的,隐藏层的输入包括输入层的输出和上一时刻隐藏层的输出。
- 深度学习定义:是一种精确的分层学习,指在多个计算阶段中精确第分配信用,以转换网络中的聚合激活,从而由简单的基础来学习和分析处理复杂的问题。
- 卷积神经网络:一种专门用于处理具有网格结构数据的深度学习模型,本质为前馈神经网络,包括卷积计算且具有深度结构。
- 强化学习:解决智能体在与外部环境交互活动的过程中,能够通过自身学习策略来应对外部环境问题,从而达到回报效益最大化的状态。
- 前馈神经网络:没有反馈机制,只能向前传播而不能反向传播来调整权值参数的神经网络模型。
- 神经元结构:神经元是ANN中的基本单元,每个神经元接收多个输入信号(通常包括权重和偏置),对这些输入信号进行加权求和,然后通过一个激活函数生成输出。
- 感知器:感知机(Perceptron)是一种最简单的人工神经网络模型,通常用于二元分类任务。它由输入层、权值、偏置、激活函数和输出层组成
第8章 强化学习和深度学习
- 卷积层的三个参数:核大小、步长、填充
版权归原作者 小白要加油哈 所有, 如有侵权,请联系我们删除。