
Stable Diffusion 只做AI动画是基于把原有视频按照帧进行提取之后对每一帧的图像进行标准化流程操作,中间可以掺杂Controlnet对人物进行控制,使用关键词对画面进行控制,但是很多小伙伴不太会掌握一些编辑视频软件或者python的操作导致视频转帧,帧转视频会出现一些问题。
这里分享2套方法。
文章目录
自制Python脚本
在你的文件目录下和我一致即可。
视频转帧 fps_jpg.py
from moviepy.editor import*import os
import cv2
# 加载视频文件
dir_list = os.listdir("video")
video_capture = cv2.VideoCapture("video/"+ dir_list[0])# 初始化帧计数器
frame_count =0# 逐帧读取视频并保存图像whileTrue:# 读取视频帧
ret, frame = video_capture.read()# 检查是否成功读取帧ifnot ret:break# 保存图像
cv2.imwrite(f"video_img/frame{frame_count}.jpg", frame)# 帧计数器加1
frame_count +=1# 释放视频捕捉对象
video_capture.release()
帧转视频 jpg_fps.py
from moviepy.editor import*import os
import numpy as np
# 按帧合成视频
os.system("ffmpeg -i video_img/frame%d.jpg -acodec libvo_aacenc -vcodec mpeg4 -r 60 video_out/merged.mp4")# os.system("ffmpeg -i video_img/%6d.png -acodec libvo_aacenc -vcodec mpeg4 -r 60 video_out/merged.mp4")# 共读取原视频
dir_list = os.listdir("video")
video_source = VideoFileClip("video/"+ dir_list[0])# 提取视频中的音频
video_mp3 = video_source.audio
# 提取视频中的时长
video_duration = video_source.duration
# 读取merge视频
video_merge = VideoFileClip("video_out/merged.mp4")# 提取视频中的时长
merge_duration = video_merge.duration
# 计算加速的倍数
factor = merge_duration / video_duration
result = video_merge.speedx(factor)# 设置视频的音频
result = result.set_audio(video_mp3)
result.write_videofile("video_merge/diy_result.mp4")
Stable Diffusion 插件
自行下载脚本 sd-webui-video-frames
脚本放到你的 Stable Diffusion 的 Script 下。
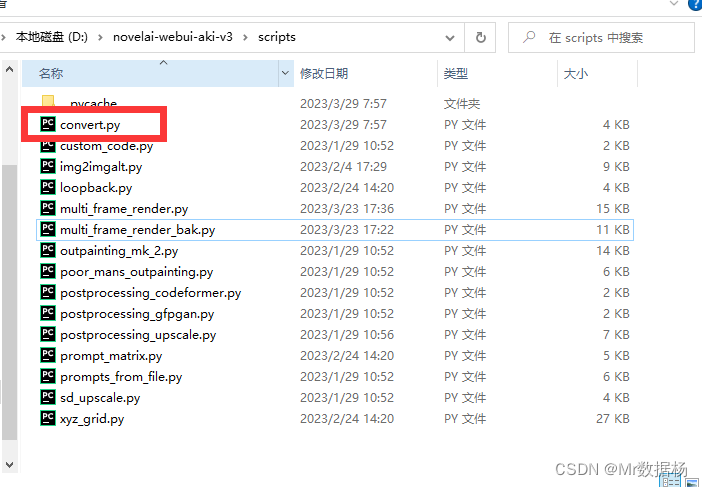
在你的Stable Diffusion中会看到对应的选项卡。
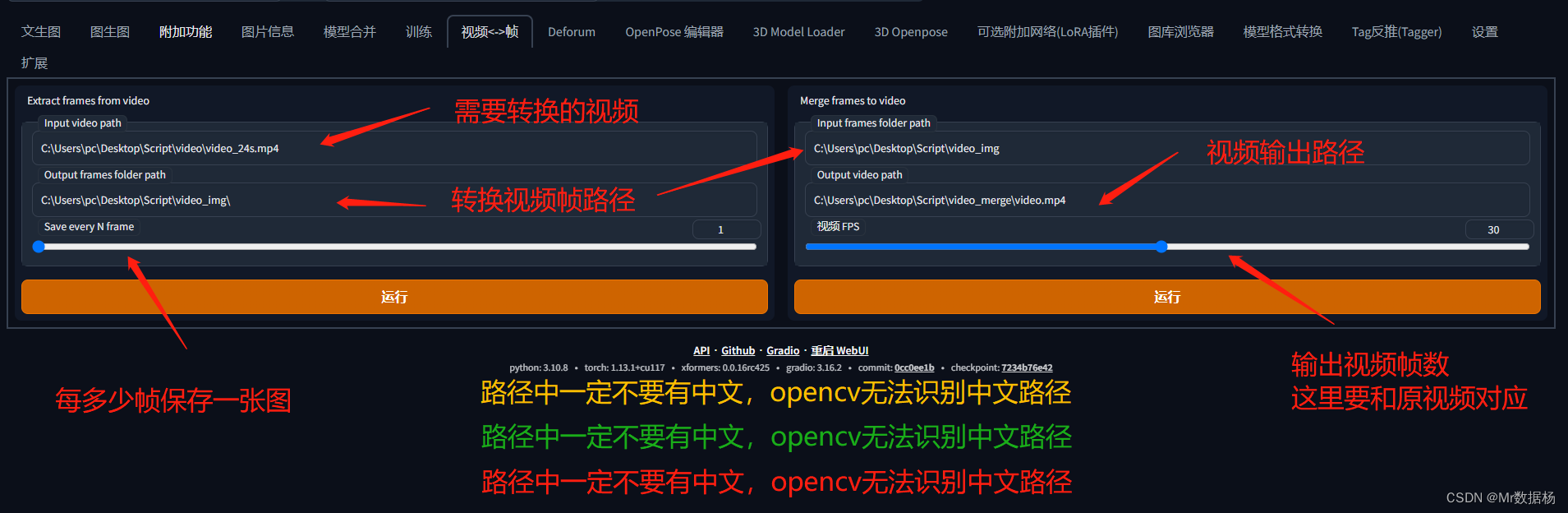
生成的视频转图像帧。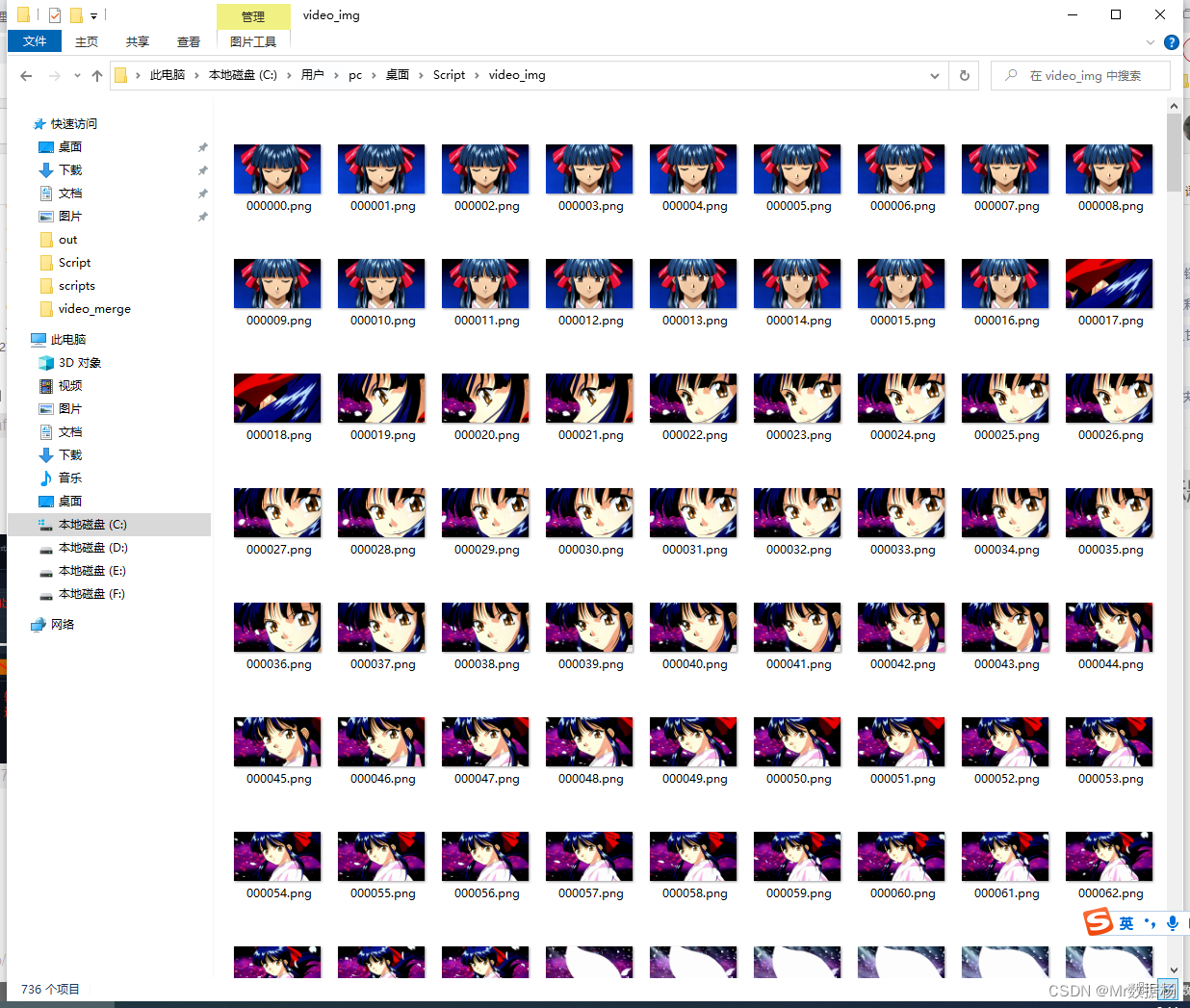
AI动画脚本
感谢原作者提供脚本 multi-frame-rendering-for-stablediffusion
脚本安装
脚本放到你的 Stable Diffusion 的 Script 下,但是原作者这个脚本似乎有点问题,图片超过2800张之后就无法处理了,所以对这个脚本进行了一些修改,代码在最后先看流程在操作。
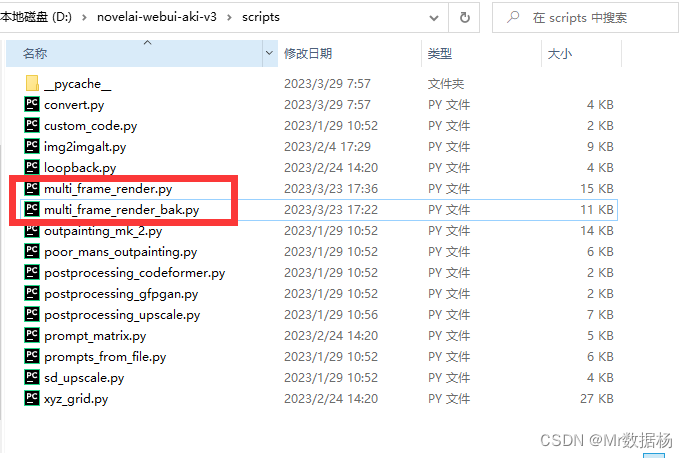
制作第一帧图像
这样进行基础的文生图的样子。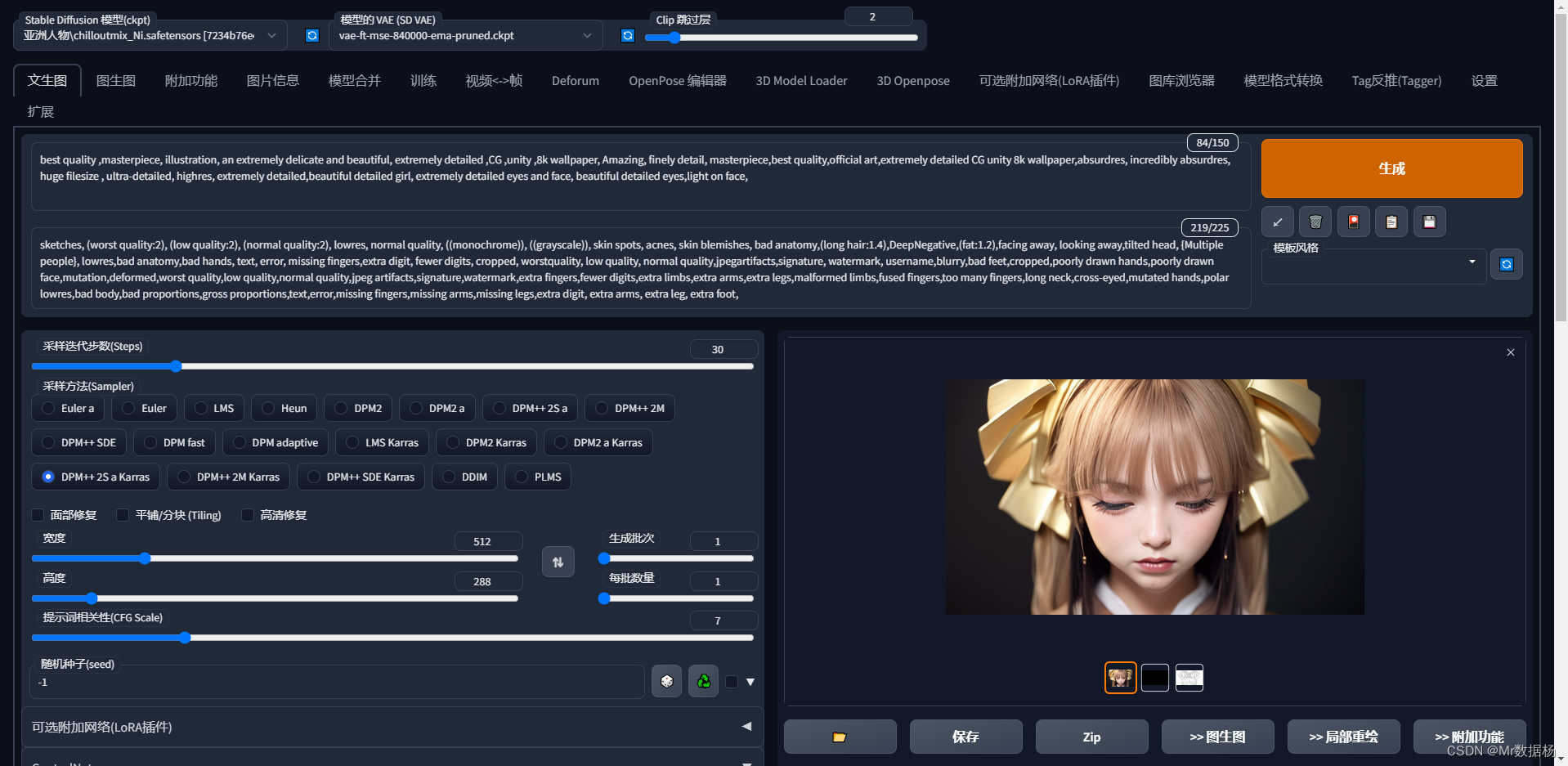
然后添加Controlnet控制人物,这里建议添加openpose和canny。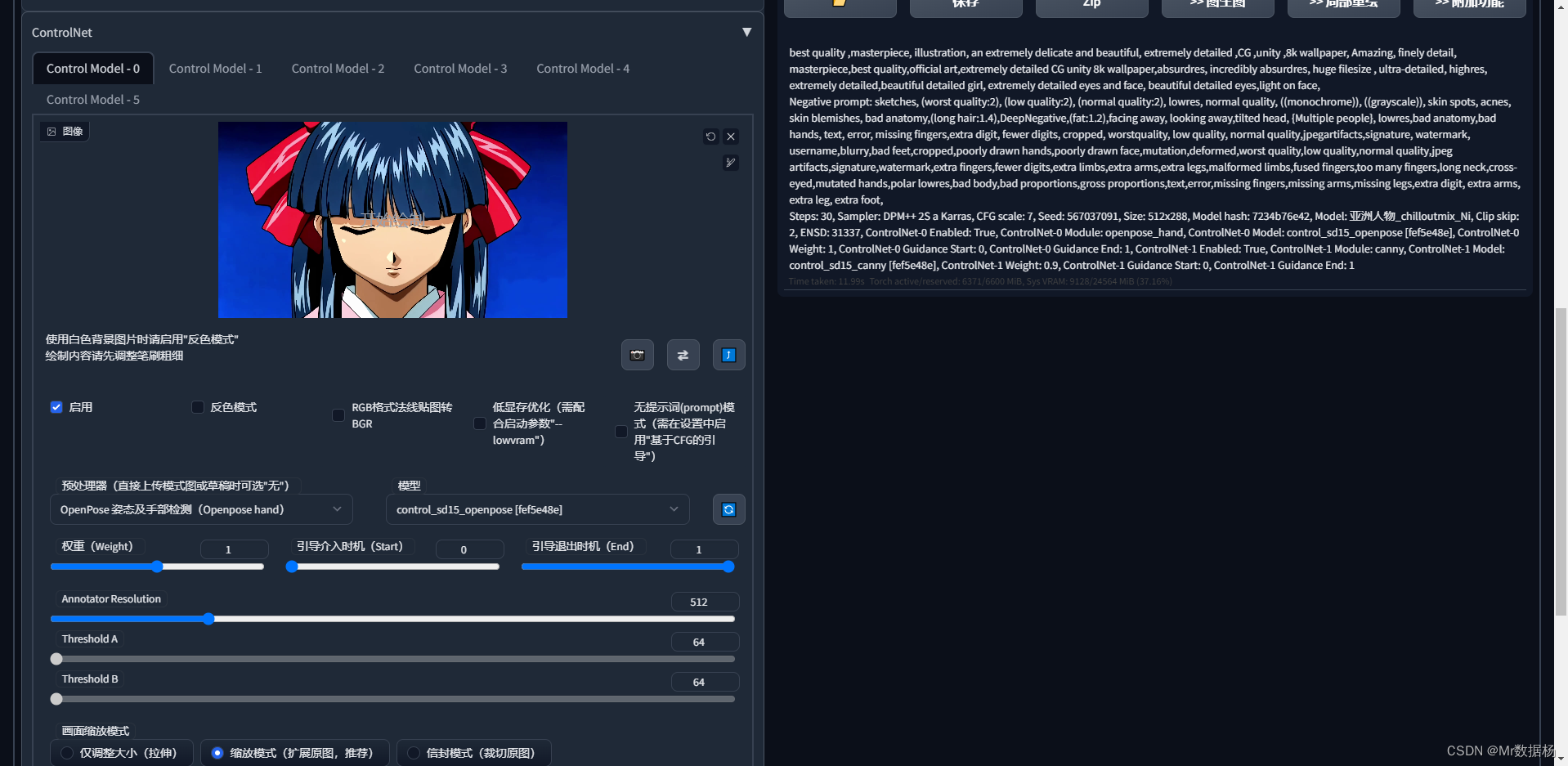
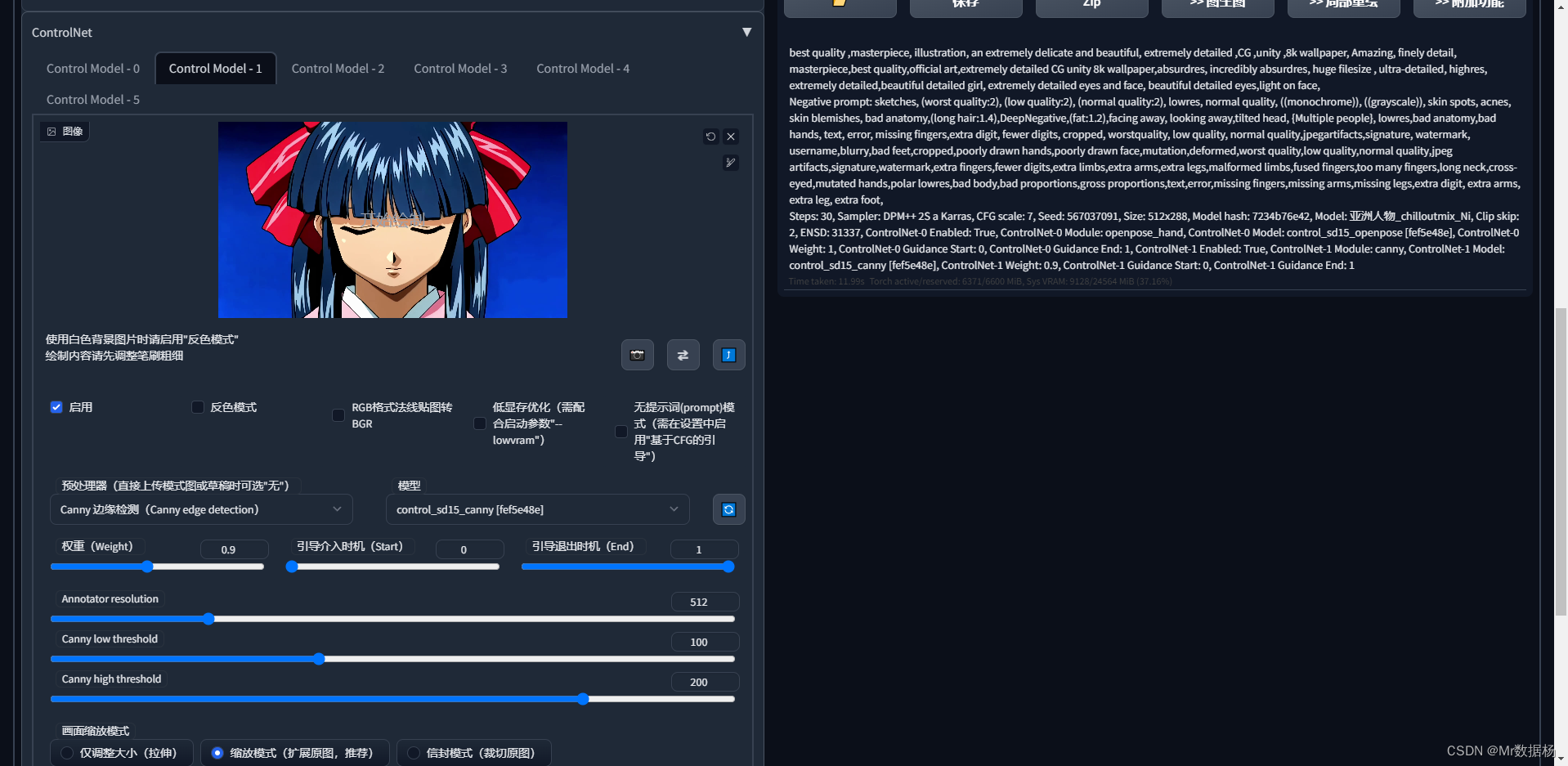
批量生成
点击生成好的图像到图生图界面,复制图像的种子。

勾选和之前文生图中Controlnet相同的配置,但是这里不需要加入图片。
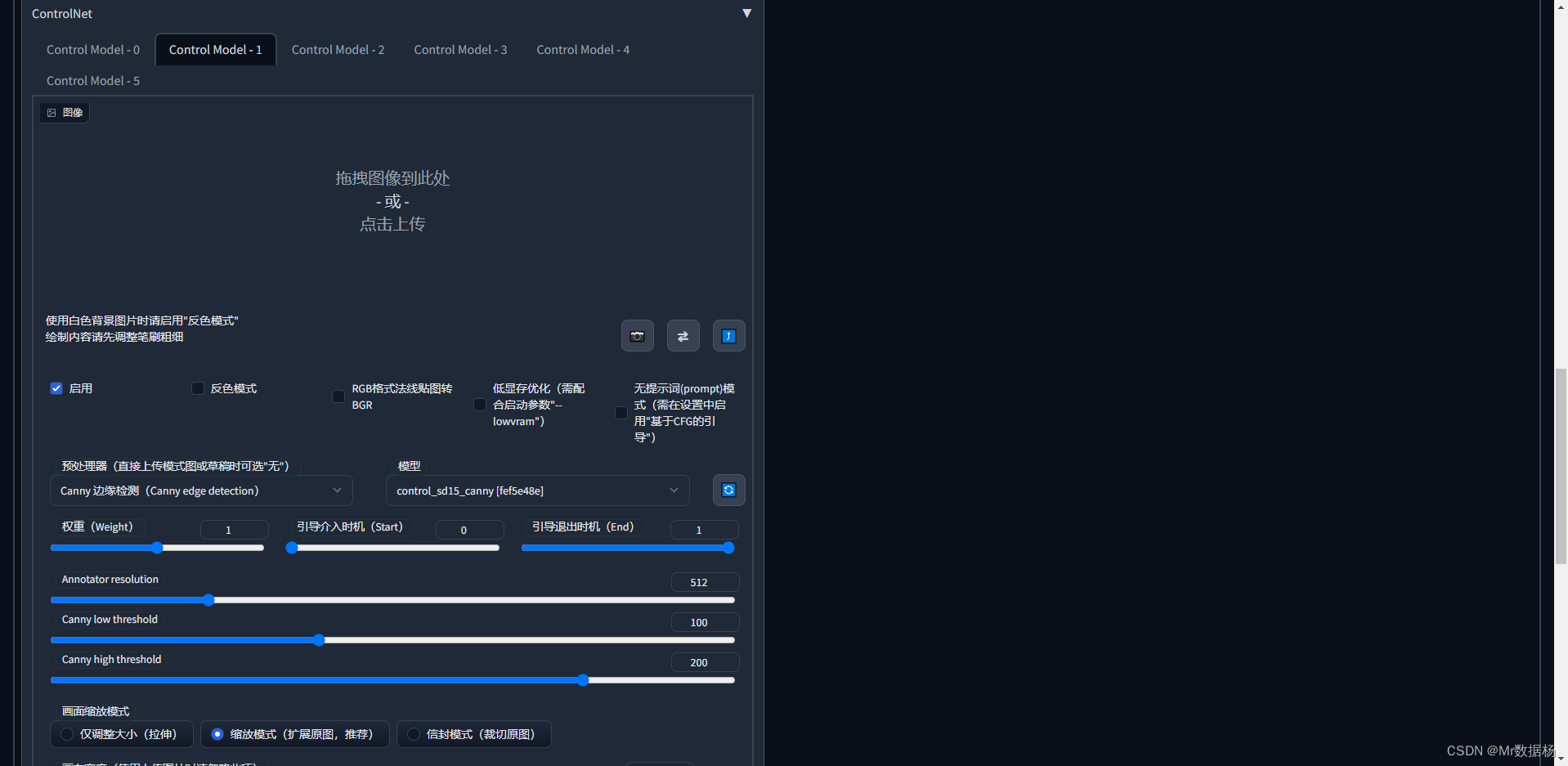
打开下方的脚本选择输入和输出的文件路径就按照下图配置好久可以点击生成。自己制定好图片输入输入的路径就可以了,其他的地方按照我这里设置即可。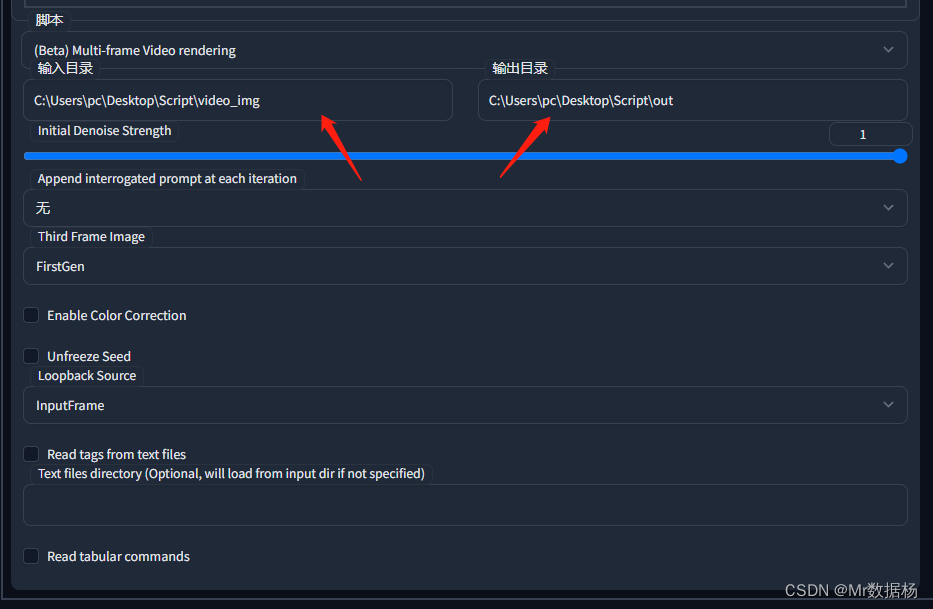
multi_frame_render.py
复制修改的代码新建一个脚本即可。
import numpy as np
from tqdm import trange
from PIL import Image, ImageSequence, ImageDraw, ImageFilter, PngImagePlugin
import modules.scripts as scripts
import gradio as gr
from modules import processing, shared, sd_samplers, images
from modules.processing import Processed
from modules.sd_samplers import samplers
from modules.shared import opts, cmd_opts, state
from modules import deepbooru
from modules.script_callbacks import ImageSaveParams, before_image_saved_callback
from modules.shared import opts, cmd_opts, state
from modules.sd_hijack import model_hijack
import pandas as pd
import piexif
import piexif.helper
import os, re
defgr_show(visible=True):return{"visible": visible,"__type__":"update"}defgr_show_value_none(visible=True):return{"value":None,"visible": visible,"__type__":"update"}defgr_show_and_load(value=None, visible=True):if value:if value.orig_name.endswith('.csv'):
value = pd.read_csv(value.name)else:
value = pd.read_excel(value.name)else:
visible =Falsereturn{"value": value,"visible": visible,"__type__":"update"}classScript(scripts.Script):deftitle(self):return"(Beta) Multi-frame Video rendering"defshow(self, is_img2img):return is_img2img
defui(self, is_img2img):with gr.Row():
input_dir = gr.Textbox(label='Input directory', lines=1)
output_dir = gr.Textbox(label='Output directory', lines=1)# reference_imgs = gr.UploadButton(label="Upload Guide Frames", file_types = ['.png','.jpg','.jpeg'], live=True, file_count = "multiple")
first_denoise = gr.Slider(minimum=0, maximum=1, step=0.05, label='Initial Denoise Strength', value=1, elem_id=self.elem_id("first_denoise"))
append_interrogation = gr.Dropdown(label="Append interrogated prompt at each iteration", choices=["None","CLIP","DeepBooru"], value="None")
third_frame_image = gr.Dropdown(label="Third Frame Image", choices=["None","FirstGen","OriginalImg","Historical"], value="FirstGen")
color_correction_enabled = gr.Checkbox(label="Enable Color Correction", value=False, elem_id=self.elem_id("color_correction_enabled"))
unfreeze_seed = gr.Checkbox(label="Unfreeze Seed", value=False, elem_id=self.elem_id("unfreeze_seed"))
loopback_source = gr.Dropdown(label="Loopback Source", choices=["PreviousFrame","InputFrame","FirstGen"], value="InputFrame")with gr.Row():
use_txt = gr.Checkbox(label='Read tags from text files')with gr.Row():
txt_path = gr.Textbox(label='Text files directory (Optional, will load from input dir if not specified)', lines=1)with gr.Row():
use_csv = gr.Checkbox(label='Read tabular commands')
csv_path = gr.File(label='.csv or .xlsx', file_types=['file'], visible=False)with gr.Row():with gr.Column():
table_content = gr.Dataframe(visible=False, wrap=True)
use_csv.change(
fn=lambda x:[gr_show_value_none(x), gr_show_value_none(False)],
inputs=[use_csv],
outputs=[csv_path, table_content],)
csv_path.change(
fn=lambda x: gr_show_and_load(x),
inputs=[csv_path],
outputs=[table_content],)return[append_interrogation, input_dir, output_dir, first_denoise, third_frame_image, color_correction_enabled, unfreeze_seed, loopback_source, use_csv, table_content, use_txt, txt_path]defrun(self, p, append_interrogation, input_dir, output_dir, first_denoise, third_frame_image, color_correction_enabled, unfreeze_seed, loopback_source, use_csv, table_content, use_txt, txt_path):
freeze_seed =not unfreeze_seed
if use_csv:
prompt_list =[i[0]for i in table_content.values.tolist()]
prompt_list.insert(0, prompt_list.pop())
reference_imgs =[os.path.join(input_dir, f)for f in os.listdir(input_dir)if re.match(r'.+\.(jpg|png)$', f)]print(f'Will process following files: {", ".join(reference_imgs)}')if use_txt:if txt_path =="":
files =[re.sub(r'\.(jpg|png)$','.txt', path)for path in reference_imgs]else:
files =[os.path.join(txt_path, os.path.basename(re.sub(r'\.(jpg|png)$','.txt', path)))for path in reference_imgs]
prompt_list =[open(file,'r').read().rstrip('\n')forfilein files]
loops =len(reference_imgs)
processing.fix_seed(p)
batch_count = p.n_iter
p.batch_size =1
p.n_iter =1
output_images, info =None,None
initial_seed =None
initial_info =None
initial_width = p.width
initial_img = reference_imgs[0]# p.init_images[0]
grids =[]
all_images =[]
original_init_image = p.init_images
original_prompt = p.prompt
if original_prompt !="":
original_prompt = original_prompt.rstrip(', ')+', 'ifnot original_prompt.rstrip().endswith(',')else original_prompt.rstrip()+' '
original_denoise = p.denoising_strength
state.job_count = loops * batch_count
initial_color_corrections =[processing.setup_color_correction(p.init_images[0])]# for n in range(batch_count):
history =None# frames = []
third_image =None
third_image_index =0
frame_color_correction =None# Reset to original init image at the start of each batch
p.init_images = original_init_image
p.width = initial_width
for i inrange(loops):if state.interrupted:break
filename = os.path.basename(reference_imgs[i])
p.n_iter =1
p.batch_size =1
p.do_not_save_grid =True
p.control_net_input_image = Image.open(reference_imgs[i]).convert("RGB").resize((initial_width, p.height), Image.ANTIALIAS)if(i >0):
loopback_image = p.init_images[0]if loopback_source =="InputFrame":
loopback_image = p.control_net_input_image
elif loopback_source =="FirstGen":
loopback_image = history
if third_frame_image !="None":
p.width = initial_width *3
img = Image.new("RGB",(initial_width*3, p.height))
img.paste(p.init_images[0],(0,0))# img.paste(p.init_images[0], (initial_width, 0))
img.paste(loopback_image,(initial_width,0))if i ==1:
third_image = p.init_images[0]
img.paste(third_image,(initial_width*2,0))
p.init_images =[img]if color_correction_enabled:
p.color_corrections =[processing.setup_color_correction(img)]
msk = Image.new("RGB",(initial_width*3, p.height))
msk.paste(Image.open(reference_imgs[i-1]).convert("RGB").resize((initial_width, p.height), Image.ANTIALIAS),(0,0))
msk.paste(p.control_net_input_image,(initial_width,0))
msk.paste(Image.open(reference_imgs[third_image_index]).convert("RGB").resize((initial_width, p.height), Image.ANTIALIAS),(initial_width*2,0))
p.control_net_input_image = msk
latent_mask = Image.new("RGB",(initial_width*3, p.height),"black")
latent_draw = ImageDraw.Draw(latent_mask)
latent_draw.rectangle((initial_width,0,initial_width*2,p.height), fill="white")
p.image_mask = latent_mask
p.denoising_strength = original_denoise
else:
p.width = initial_width *2
img = Image.new("RGB",(initial_width*2, p.height))
img.paste(p.init_images[0],(0,0))# img.paste(p.init_images[0], (initial_width, 0))
img.paste(loopback_image,(initial_width,0))
p.init_images =[img]if color_correction_enabled:
p.color_corrections =[processing.setup_color_correction(img)]
msk = Image.new("RGB",(initial_width*2, p.height))
msk.paste(Image.open(reference_imgs[i-1]).convert("RGB").resize((initial_width, p.height), Image.ANTIALIAS),(0,0))
msk.paste(p.control_net_input_image,(initial_width,0))
p.control_net_input_image = msk
# frames.append(msk)# latent_mask = Image.new("RGB", (initial_width*2, p.height), "white")# latent_draw = ImageDraw.Draw(latent_mask)# latent_draw.rectangle((0,0,initial_width,p.height), fill="black")
latent_mask = Image.new("RGB",(initial_width*2, p.height),"black")
latent_draw = ImageDraw.Draw(latent_mask)
latent_draw.rectangle((initial_width,0,initial_width*2,p.height), fill="white")# p.latent_mask = latent_mask
p.image_mask = latent_mask
p.denoising_strength = original_denoise
else:
latent_mask = Image.new("RGB",(initial_width, p.height),"white")# p.latent_mask = latent_mask
p.image_mask = latent_mask
p.denoising_strength = first_denoise
p.control_net_input_image = p.control_net_input_image.resize((initial_width, p.height))# frames.append(p.control_net_input_image)# if opts.img2img_color_correction:# p.color_corrections = initial_color_correctionsif append_interrogation !="None":
p.prompt = original_prompt
if append_interrogation =="CLIP":
p.prompt += shared.interrogator.interrogate(p.init_images[0])elif append_interrogation =="DeepBooru":
p.prompt += deepbooru.model.tag(p.init_images[0])if use_csv or use_txt:
p.prompt = original_prompt + prompt_list[i]# state.job = f"Iteration {i + 1}/{loops}, batch {n + 1}/{batch_count}"
processed = processing.process_images(p)if initial_seed isNone:
initial_seed = processed.seed
initial_info = processed.info
init_img = processed.images[0]if(i >0):
init_img = init_img.crop((initial_width,0, initial_width*2, p.height))
comments ={}iflen(model_hijack.comments)>0:for comment in model_hijack.comments:
comments[comment]=1
info = processing.create_infotext(
p,
p.all_prompts,
p.all_seeds,
p.all_subseeds,
comments,0,0)
pnginfo ={}if info isnotNone:
pnginfo['parameters']= info
params = ImageSaveParams(init_img, p, filename, pnginfo)
before_image_saved_callback(params)
fullfn_without_extension, extension = os.path.splitext(
filename)
info = params.pnginfo.get('parameters',None)defexif_bytes():return piexif.dump({'Exif':{
piexif.ExifIFD.UserComment: piexif.helper.UserComment.dump(info or'', encoding='unicode')},})if extension.lower()=='.png':
pnginfo_data = PngImagePlugin.PngInfo()for k, v in params.pnginfo.items():
pnginfo_data.add_text(k,str(v))
init_img.save(
os.path.join(
output_dir,
filename),
pnginfo=pnginfo_data)elif extension.lower()in('.jpg','.jpeg','.webp'):
init_img.save(os.path.join(output_dir, filename))if opts.enable_pnginfo and info isnotNone:
piexif.insert(
exif_bytes(), os.path.join(
output_dir, filename))else:
init_img.save(os.path.join(output_dir, filename))if third_frame_image !="None":if third_frame_image =="FirstGen"and i ==0:
third_image = init_img
third_image_index =0elif third_frame_image =="OriginalImg"and i ==0:
third_image = original_init_image[0]
third_image_index =0elif third_frame_image =="Historical":
third_image = processed.images[0].crop((0,0, initial_width, p.height))
third_image_index =(i-1)
p.init_images =[init_img]if(freeze_seed):
p.seed = processed.seed
else:
p.seed = processed.seed +1# p.seed = processed.seedif i ==0:
history = init_img
# history.append(processed.images[0])# frames.append(processed.images[0])# grid = images.image_grid(history, rows=1)# if opts.grid_save:# images.save_image(grid, p.outpath_grids, "grid", initial_seed, p.prompt, opts.grid_format, info=info, short_filename=not opts.grid_extended_filename, grid=True, p=p)# grids.append(grid)# # all_images += history + frames# all_images += history# p.seed = p.seed+1# if opts.return_grid:# all_images = grids + all_images
processed = Processed(p,[], initial_seed, initial_info)return processed
本文转载自: https://blog.csdn.net/qq_20288327/article/details/129829258
版权归原作者 Mr数据杨 所有, 如有侵权,请联系我们删除。
版权归原作者 Mr数据杨 所有, 如有侵权,请联系我们删除。