
文章目录
1. 课程简介
该门课程是由
XGBoost
的作者陈天奇进行授课的。 从2022年6月18日正式开始(新鲜出炉的),每周讲授一节课程。具体内容可参考链接:中文官网或者英文官网。如果有相关问题也可以在讨论区进行留言:中文讨论区、英文讨论区。
课程目录如下所示:
- 机器学习编译概述
- 张量算子函数
- 张量函数与整网模型的整合
- 整合自定义计算库
- 自动化程序优化
- 与机器学习框架的整合
- 自定义硬件后端
- 自动张量化
- 计算图优化:算子融合和内存优化
- 部署模型到服务环境
- 部署模型到边缘设备
客观来说,本课程并不适合机器学习或者深度学习的初学者。但强烈推荐同学们先学习第一课:机器学习编译概述。然后再决定是否进行更加深入的学习。
本节课的slides链接如下:https://mlc.ai/summer22-zh/slides/1-Introduction.pdf;notes链接如下:https://mlc.ai/zh/chapter_introduction/。
2. 本节课内容大纲
- 什么是机器学习编译?
- 机器学习编译的目标是什么?
- 为什么要学习机器学习编译?
- 机器学习编译的核心要素是什么?
3. 机器学习编译的定义
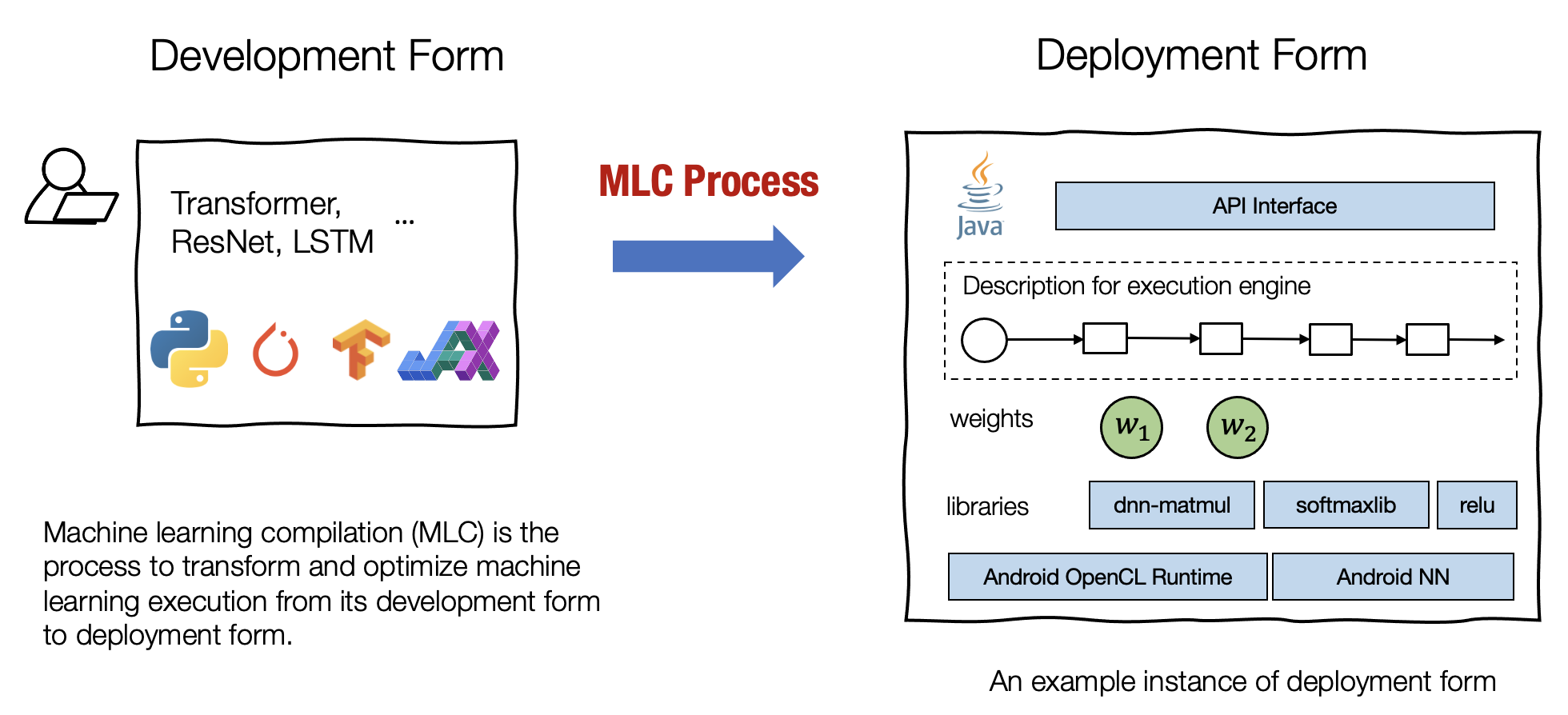
机器学习编译 (machine learning compilation, MLC) 是指,将机器学习算法从
开发形态
,通过变换和优化算法,使其变成
部署形态
。简单来说,就是将训练好的机器学习模型应用落地,部署在特定的系统环境之中的过程。
#mermaid-svg-3XmHl123LLsU371Y {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3XmHl123LLsU371Y .error-icon{fill:#552222;}#mermaid-svg-3XmHl123LLsU371Y .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-3XmHl123LLsU371Y .edge-thickness-normal{stroke-width:2px;}#mermaid-svg-3XmHl123LLsU371Y .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-3XmHl123LLsU371Y .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-3XmHl123LLsU371Y .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-3XmHl123LLsU371Y .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-3XmHl123LLsU371Y .marker{fill:#333333;stroke:#333333;}#mermaid-svg-3XmHl123LLsU371Y .marker.cross{stroke:#333333;}#mermaid-svg-3XmHl123LLsU371Y svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-3XmHl123LLsU371Y .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-3XmHl123LLsU371Y .cluster-label text{fill:#333;}#mermaid-svg-3XmHl123LLsU371Y .cluster-label span{color:#333;}#mermaid-svg-3XmHl123LLsU371Y .label text,#mermaid-svg-3XmHl123LLsU371Y span{fill:#333;color:#333;}#mermaid-svg-3XmHl123LLsU371Y .node rect,#mermaid-svg-3XmHl123LLsU371Y .node circle,#mermaid-svg-3XmHl123LLsU371Y .node ellipse,#mermaid-svg-3XmHl123LLsU371Y .node polygon,#mermaid-svg-3XmHl123LLsU371Y .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-3XmHl123LLsU371Y .node .label{text-align:center;}#mermaid-svg-3XmHl123LLsU371Y .node.clickable{cursor:pointer;}#mermaid-svg-3XmHl123LLsU371Y .arrowheadPath{fill:#333333;}#mermaid-svg-3XmHl123LLsU371Y .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-3XmHl123LLsU371Y .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-3XmHl123LLsU371Y .edgeLabel{background-color:#e8e8e8;text-align:center;}#mermaid-svg-3XmHl123LLsU371Y .edgeLabel rect{opacity:0.5;background-color:#e8e8e8;fill:#e8e8e8;}#mermaid-svg-3XmHl123LLsU371Y .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-3XmHl123LLsU371Y .cluster text{fill:#333;}#mermaid-svg-3XmHl123LLsU371Y .cluster span{color:#333;}#mermaid-svg-3XmHl123LLsU371Y div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-3XmHl123LLsU371Y :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;}
转换
开发形态
部署形态
开发形态是指我们在开发机器学习模型时使用的形态。典型的开发形式包括用 PyTorch、TensorFlow 或 JAX(主要指的是深度学习学习模型)等通用框架编写的模型描述,以及与之相关的权重。
部署形态是指执行机器学习应用程序所需的形态。它通常涉及机器学习模型的每个步骤的支撑代码、管理资源(例如内存)的控制器,以及与应用程序开发环境的接口(例如用于Android 应用程序的Java API)。
不同的AI应用对应的部署环境是互不相同的。以下图为例:电商平台不可或缺的推荐系统算法通常是部署在云平台(服务器)上;自动驾驶算法通常是部署在车辆上的专用计算设备;手机的各种APP以语音转文字的输入法为例,最终是部署在手机上的计算设备的。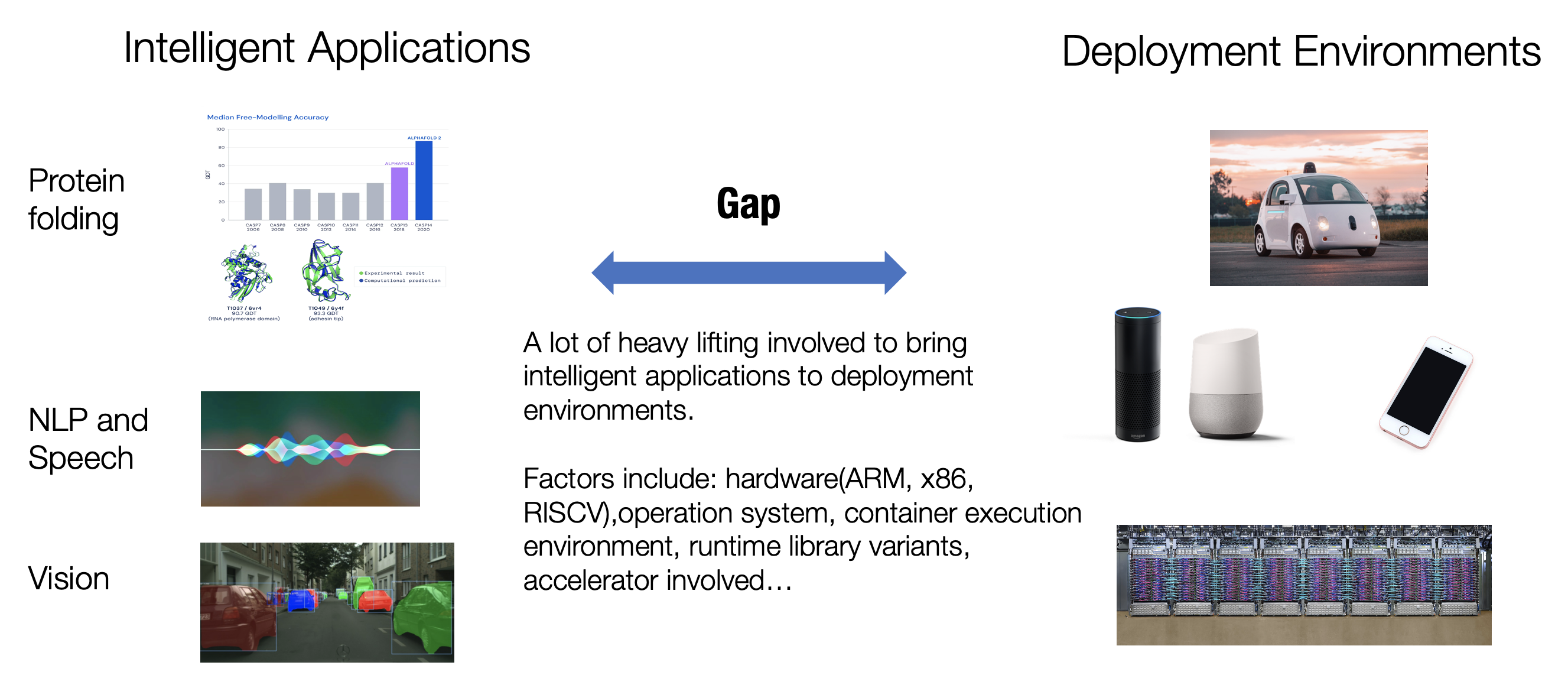
在进行机器学习模型部署时,不仅要考虑硬件系统环境,与此同时也需要考虑软件环境(如操作系统环境、机器学习平台环境等)。
4. 机器学习编译的目标
机器学习编译的直接目标包括两点:最小化依赖和利用硬件加速。机器学习编译的最终目的是实现性能(时间复杂度、空间复杂度)优化。
最小化依赖可以认为是集成(Integration)的一部分,提取出与应用相关的库(删除与应用无关的库),从而减少应用的大小,达到节省空间的目的。
利用硬件加速指的是利用硬件本身的特性进行加速。可以通过构建调用原生加速库的部署代码或生成利用原生指令(如 TensorCore)的代码来做到这一点。
5. 为什么要学习机器学习编译?
- 构建机器学习部署的解决方案。
- 对现有机器学习框架形成更加深刻的理解。
6. 机器学习编译的核心要素
张量(Tensor) 是执行中最重要的元素。张量是表示神经网络模型执行的输入、输出和中间结果的多维数组。张量函数(Tensor functions) 神经网络的“知识”被编码在权重和接受张量和输出张量的计算序列中。我们将这些计算称为张量函数。值得注意的是,张量函数不需要对应于神经网络计算的单个步骤。部分计算或整个端到端计算也可以看作张量函数。也就是说,不仅单个函数可以认为是张量函数,也可以把其中一部分(或者整个整体)看作是张量函数。

下图中举了个实际的例子,第一个linear层和relu计算被折叠成一个linear_relu 函数,这需要有一个特定的linear_relu的详细实现。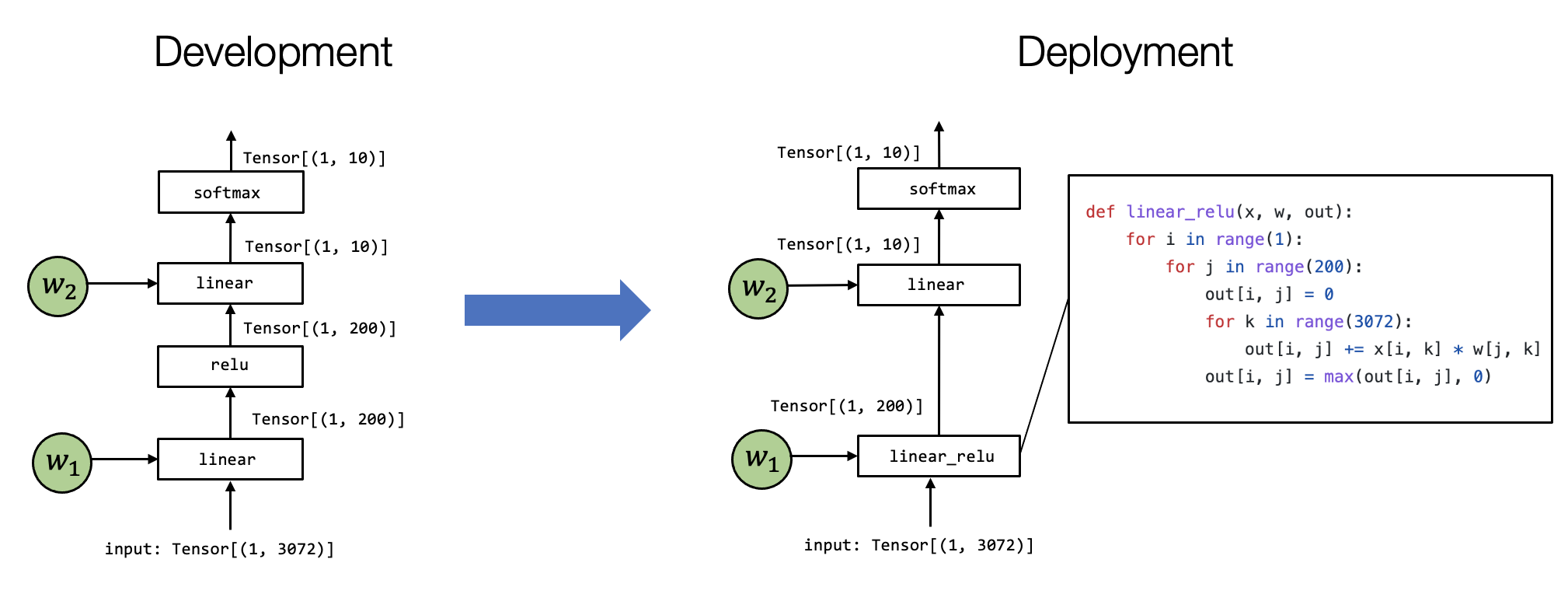
6.1. 备注:抽象和实现
对同样的目标有不同颗粒度的表示。例如对linear_relu而言,既可以使用左边两个框图进行表示,也可以用右边的循环进行表示。
我们使用
抽象
(Abstraction)来表示我们用来表示相同张量函数的方式。不同的抽象可能会指定一些细节,而忽略其他实现(Implementations)细节。例如,linear_relu 可以使用另一个不同的 for 循环来实现。
抽象
和
实现
可能是所有计算机系统中最重要的关键字。抽象指定“做什么”,实现提供“如何”做。没有具体的界限。根据我们的看法,for 循环本身可以被视为一种抽象,因为它可以使用 python 解释器实现或编译为本地汇编代码。
机器学习编译实际上是在相同或不同抽象下转换和组装张量函数的过程。我们将研究张量函数的不同抽象类型,以及它们如何协同工作以解决机器学习部署中的挑战。
在后续课程中分别会涉及到四种类型的抽象:
- 计算图
- 张量程序
- 库(运行时)
- 硬件专用指令
7. 总结
- 机器学习编译的目标- 集成与最小化依赖- 利用硬件加速- 通用优化
- 为什么学习机器学习编译- 构建机器学习部署解决方案- 深入了解现有机器学习框架- 为新兴硬件建立软件栈
- 机器学习编译的关键要素- 张量和张量函数- 抽象和实现是值得思考的工具
版权归原作者 herosunly 所有, 如有侵权,请联系我们删除。