
【人工智能学习之卷积神经网络实战(手把手教你搭网络,超详细!)】
经过一段时间的学习,相信你已经饥渴难耐迫不及待想要在深度学习方向中大展身手了吧!
接下来让我们一起进行一次卷积神经网络的搭建与训练。
爬虫获取训练集:
当然,读者老爷们也可以直接用我的数据集。下载链接见文章末尾。
四分类训练集样本数量统一为4352张:
import re
import threading
import time
from threading import Thread, Lock
import requests
# 关键字 摩托车,汽车,公交车,火车
keyword ='公交车'# 存放的目录
img_dir ='./bus/'# 每一页的图片数量
page_num =30# 爬取的地址
urls =[f'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word="{keyword}"&pn={30* index}'for index inrange(page_num)]# 统计图片数量
lock = Lock()
image_count =0classSpider(Thread):def__init__(self, name):super(Spider, self).__init__()
self.name = name
"""
下载数据
1. headers
2. 发起请求
"""defdown_load(self, url):global image_count
headers ={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36'}
result = requests.get(url, timeout=10, headers=headers)"""
# print(result.text)
# .除\n(换行符)之外的任意字符
# *匹配0 - 无穷次
# ?非贪婪模式(一旦拿到数据直接返回,不再向下匹配)
"objURL":"https://imgx.xiawu.com/xzimg/i4/i2/TB1FDR2FVXXXXXMXpXXXXXXXXXX_%21%210-item_pic.jpg",
'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word="草莓"&pn=0'
"""# 需要匹配包括换行符在内的所有字符。这时可以使用re.S标志
image_urls = re.findall('"objURL":"(.*?)",', result.text, re.S)print(image_urls)"""
请求图片
保存图片
图片命名 序号+格式
"""for image_url in image_urls:try:
image_name =str(int(time.time()*1000000))+'.jpg'
image_url = image_url.strip('"')
image_url = image_url.strip("'")
pic = requests.get(image_url, timeout=9)
img_path = img_dir + image_name
fp =open(img_path,'wb')
fp.write(pic.content)
fp.close()
image_count +=1
name = threading.current_thread().name
print(f'线程:{name}{image_name}保存成功 第{image_count}张')except:print(f'{image_name}出错啦')defrun(self):global urls
whileTrue:
lock.acquire()iflen(urls)==0:print('.............没有数据啦.............')
lock.release()return"""
在Python中,列表是线程不安全的数据结构,因为它不是线程安全的。
这意味着,在多线程环境中,如果多个线程同时对同一个列表进行操作,可能会导致竞态条件和数据不一致问题
"""
url = urls[0]# 这里多一句代码就会演示出问题 出现线程安全问题# print('--------')del urls[0]
name = threading.current_thread().name
print(f'{name} 获取了数据{url}')# time.sleep(0.1)
lock.release()
self.down_load(url)if __name__ =='__main__':"""
输入需要爬取的页数
1. 输入需要爬取的页数
2. 每页返回60个数据
3. 请求数据
"""# page_num = int(input('请输入需要爬取的页数:'))# pn 页数# 0 第1页# 20 第2页# 40 第3页
t1 = time.time()
queue =[]for index inrange(3):
spider = Spider(f'th-{index}')
spider.start()
queue.append(spider)for spider in queue:
spider.join()
t2 = time.time()# 4个线程# 结束用时:76.23213601112366# 1个线程print(f'结束用时:{t2-t1}')
批量改名:
import os.path
import time
defrename(img_folder):for img_name in os.listdir(img_folder):# os.listdir(): 列出路径下所有的文件#os.path.join() 拼接文件路径
src = os.path.join(img_folder, img_name)#src:要修改的目录名
image_name =str(int(time.time()*1000000))+'.jpg'
dst = os.path.join(img_folder, image_name)#dst: 修改后的目录名
os.rename(src, dst)#用dst替代srcdefmain():
img_folder0 =r'D:\ai_study\AI_pic\train\3'#图片的文件夹路径 直接放文件夹路径即可\train&\test
rename(img_folder0)if __name__=="__main__":
main()
数据集预处理:
import cv2
import os
import glob
from PIL import Image
import warnings
import time
from torchvision import transforms
warnings.filterwarnings('error')
pic_transform = transforms.Compose([# transforms.ToTensor(),
transforms.Grayscale(num_output_channels=3),
transforms.RandomHorizontalFlip(p=0.5),# 执行水平翻转的概率为0.5
transforms.RandomVerticalFlip(p=0.5),# 执行垂直翻转的概率为0.5
transforms.RandomRotation((90), expand=True),
transforms.Resize((96,96), antialias=True),# transforms.Normalize(0.5,0.5),])
org_img_paths = glob.glob(os.path.join("../AI_dataset_pic/train","*","*"))# AI_pic/test trainfor path in org_img_paths:try:# png转jpg
image_name =str(int(time.time()*1000000))+'.jpg'
targe_path = path.rsplit('/', maxsplit=1)[0]
png_image = Image.open(path)# png_image.save(targe_path + '/' + image_name, format="jpeg")# os.remove(path)
pic = pic_transform(png_image)#数据增强
pic.save(targe_path +'/'+ image_name,format="jpeg")print(f'修改成功{path}')# img = cv2.imread(path)# # 检查是否能灰度# img_gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)# print(f"已检查文件: {path}")# # 重新保存,部分有问题图片[1,192,192]>>[3,96,96]# img_resize = cv2.resize(img, (96, 96))# cv2.imwrite(path, img_resize, [cv2.IMWRITE_JPEG_QUALITY, 90])except Exception as e:# 打印异常信息print("发生异常:",str(e))# 删除异常文件
os.remove(path)print(f"已删除文件: {path}!!!!!!!!!!!!!!!!!!!!!!!!!!!")
网络模型:
import torch
from torch import nn
import torch.nn.functional as F
classVGGnet_pro(nn.Module):def__init__(self):super().__init__()# nn.Sequential 连接多层
self.conv_res = nn.Sequential(
nn.Conv2d(64,64,1,2,0, bias=False),
nn.BatchNorm2d(64),)
self.conv_layer1 = nn.Sequential(
nn.Conv2d(3,64,7,2,3, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(3,2,1))
self.conv_layer2 = nn.Sequential(
nn.Conv2d(64,128,1,1,0, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(128,128,3,1,1,groups=128, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(128,64,1,1,0, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),)
self.conv_layer3 = nn.Sequential(
nn.Conv2d(64,64,3,2,1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64,64,3,1,1, bias=False),
nn.BatchNorm2d(64),)
self.conv_layer4 = nn.Sequential(
nn.Conv2d(64,64,3,1,1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64,64,3,1,1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64,64,3,1,1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.AvgPool2d(4,2))
self.classifier = nn.Sequential(
nn.Linear(1600,400),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(400,4))defforward(self, x):
x = self.conv_layer1(x)
res = self.conv_res(x)
x = self.conv_layer2(x)
x = self.conv_layer3(x)
x = F.relu(x + res)
x = self.conv_layer4(x)
x = x.reshape(x.shape[0],-1)
out = self.classifier(x)return out
模型训练:
本人经过学习优化后自主设计的模型流程图: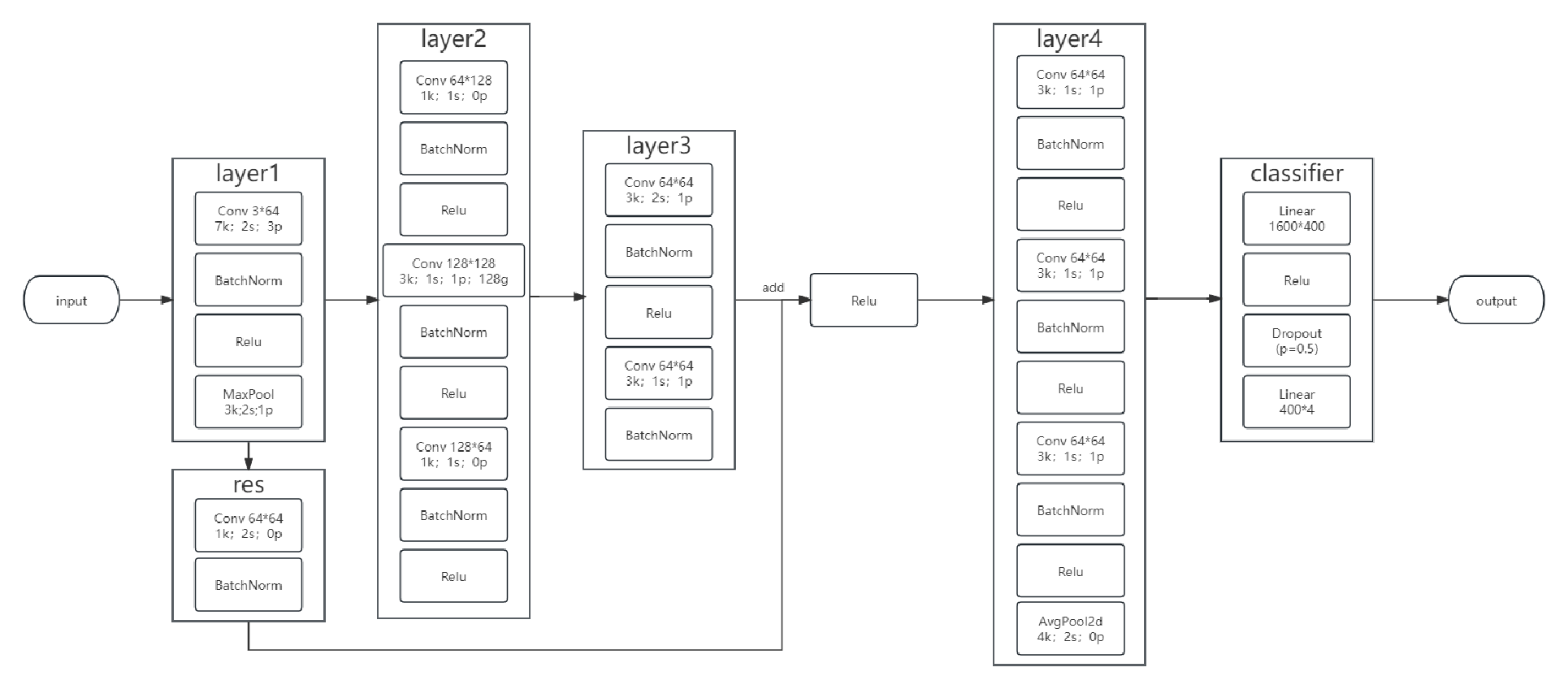
import glob
import os.path
from PIL import Image
import torch
import cv2
import json
import tqdm
from torch import nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torch.utils.data import Dataset
from torch.utils.tensorboard import SummaryWriter
from net import VGGnet_pro
# 定义一个训练的设备device
device = torch.device("cuda"if torch.cuda.is_available()else"cpu")# 设置参数
epoches =1
learn_radio =0.001
train_batch_size =50
test_batch_size =50
net_dict ="VGGnet_pro.pt"
wrong_img_path ='./wrong_data.json'
workers =0
one_hot_size =4
train_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Grayscale(num_output_channels=3),
transforms.RandomHorizontalFlip(p=0.5),# 执行水平翻转的概率为0.5
transforms.RandomVerticalFlip(p=0.5),# 执行垂直翻转的概率为0.5# transforms.RandomRotation((45), expand=True),# transforms.Resize((64, 64)),# transforms.Normalize(0.5,0.5),])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Grayscale(num_output_channels=3),# transforms.Normalize(0.5,0.5),])classMNISTDataset(Dataset):def__init__(self,root=r"C:\Users\Administrator\Desktop\net_dabian\AI_dataset_pic",isTrain=True, transform=train_transform):super().__init__()type="train"if isTrain else"test"
img_paths = glob.glob(os.path.join(root,type,"*","*"))
self.dataset =[]for path in img_paths:
label = path.rsplit('\\',maxsplit=2)[-2]# linux系统:'/',windows系统:'\\'
self.dataset.append((label,path))
self.transform = transform
def__len__(self):returnlen(self.dataset)def__getitem__(self, idx):
label, img_path = self.dataset[idx]
img = Image.open(img_path)
img_tensor = self.transform(img)
one_hot = torch.zeros(one_hot_size)
one_hot[int(label)]=1return one_hot,img_tensor,img_path
classTrainer:def__init__(self):# 1. 准备数据
train_dataset = MNISTDataset(isTrain=True, transform=train_transform)
test_dataset = MNISTDataset(isTrain=False, transform=test_transform)
self.train_loader = DataLoader(train_dataset, batch_size=train_batch_size,num_workers = workers, shuffle=True)
self.test_loader = DataLoader(test_dataset, batch_size=test_batch_size,num_workers = workers, shuffle=False)# 初始化网络# net = VGGNet().to(device)# net = ResNet().to(device)
net = VGGnet_pro().to(device)try:
net.load_state_dict(torch.load(net_dict,map_location='cpu'))# 加载之前的学习成果,权重记录print(f'已加载学习记录:{net_dict}')except:print('没有学习记录')
self.net = net.to(device)# 损失函数# self.loss_fn = nn.MSELoss().to(device) #均方差
self.loss_fn = nn.CrossEntropyLoss().to(device)#交叉熵# 优化器
self.opt = torch.optim.Adam(self.net.parameters(), lr=learn_radio)# 指标可视化
self.writer = SummaryWriter("./logs")deftrain(self,epoch):
sum_loss =0
sum_acc =0
self.net.train()for target,input, _ in tqdm.tqdm(self.train_loader,total=len(self.train_loader), desc="训练中。。。"):
target = target.to(device)input=input.to(device)# 前向传播得到模型的输出值
pred_out = self.net(input)# 计算损失
loss = self.loss_fn(pred_out, target)
sum_loss += loss.item()# 梯度清零
self.opt.zero_grad()# 反向传播求梯度
loss.backward()# 更新参数
self.opt.step()# 准确率
pred_cls = torch.argmax(pred_out, dim=1)
target_cls = torch.argmax(target, dim=1)
sum_acc += torch.mean((pred_cls == target_cls).to(torch.float32)).item()print('\n')
avg_loss = sum_loss /len(self.train_loader)
avg_acc = sum_acc /len(self.train_loader)print(f"轮次:{epoch} 训练平均损失率:{avg_loss}")print(f"轮次:{epoch} 训练平均准确率:{avg_acc}")
self.writer.add_scalars("loss",{"train_avg_loss":avg_loss}, epoch)
self.writer.add_scalars("acc",{"train_avg_acc":avg_acc}, epoch)
torch.save(self.net.state_dict(), net_dict)print('\n')deftest(self,epoch):
sum_loss =0
sum_acc =0
self.net.eval()
paths =[]for target,input, _ in tqdm.tqdm(self.test_loader, total=len(self.test_loader), desc="测试中。。。"):
target = target.to(device)input=input.to(device)# 前向传播得到模型的输出值
pred_out = self.net(input)# 计算损失
loss = self.loss_fn(pred_out, target)
sum_loss += loss.item()# 准确率
pred_cls = torch.argmax(pred_out, dim=1)
target_cls = torch.argmax(target, dim=1)
sum_acc += torch.mean((pred_cls == target_cls).to(torch.float32)).item()# 找出测试不准确的图片路径,并显示for idx inrange(len(pred_cls)):if pred_cls[idx]!= target_cls[idx]:print('\n测试不准确的图片路径:',self.test_loader.dataset[idx][2])print(f'预测结果:{pred_cls[idx]},真实结果:{target_cls[idx]}')
paths.append(self.test_loader.dataset[idx][2])# img_warn = cv2.imread(self.test_loader.dataset[idx][2])# cv2.imshow('img_warning',img_warn)# cv2.waitKey(50)# 存储图片路径withopen(wrong_img_path,'w')asfile:if paths isnotNone:
json.dump(paths,file)print('\n')
avg_loss = sum_loss /len(self.test_loader)
avg_acc = sum_acc /len(self.test_loader)
self.writer.add_scalars("loss",{"test_avg_loss": avg_loss}, epoch)
self.writer.add_scalars("acc",{"test_avg_acc": avg_acc}, epoch)print(f"轮次:{epoch} 测试平均损失率:{avg_loss}")print(f"轮次:{epoch} 测试平均准确率: {avg_acc}")print('\n')defrun(self):global learn_radio
for epoch inrange(epoches):# self.train(epoch)
self.test(epoch)
learn_radio *=0.99if __name__ =='__main__':
tra = Trainer()
tra.run()
训练效果:
在cmd系统窗口中输入:(=你的logs路径)
tensorboard --logdir=C:\Users\Administrator\Desktop\logs
输入后复制提示你的网页地址即可查看训练效果,如下图: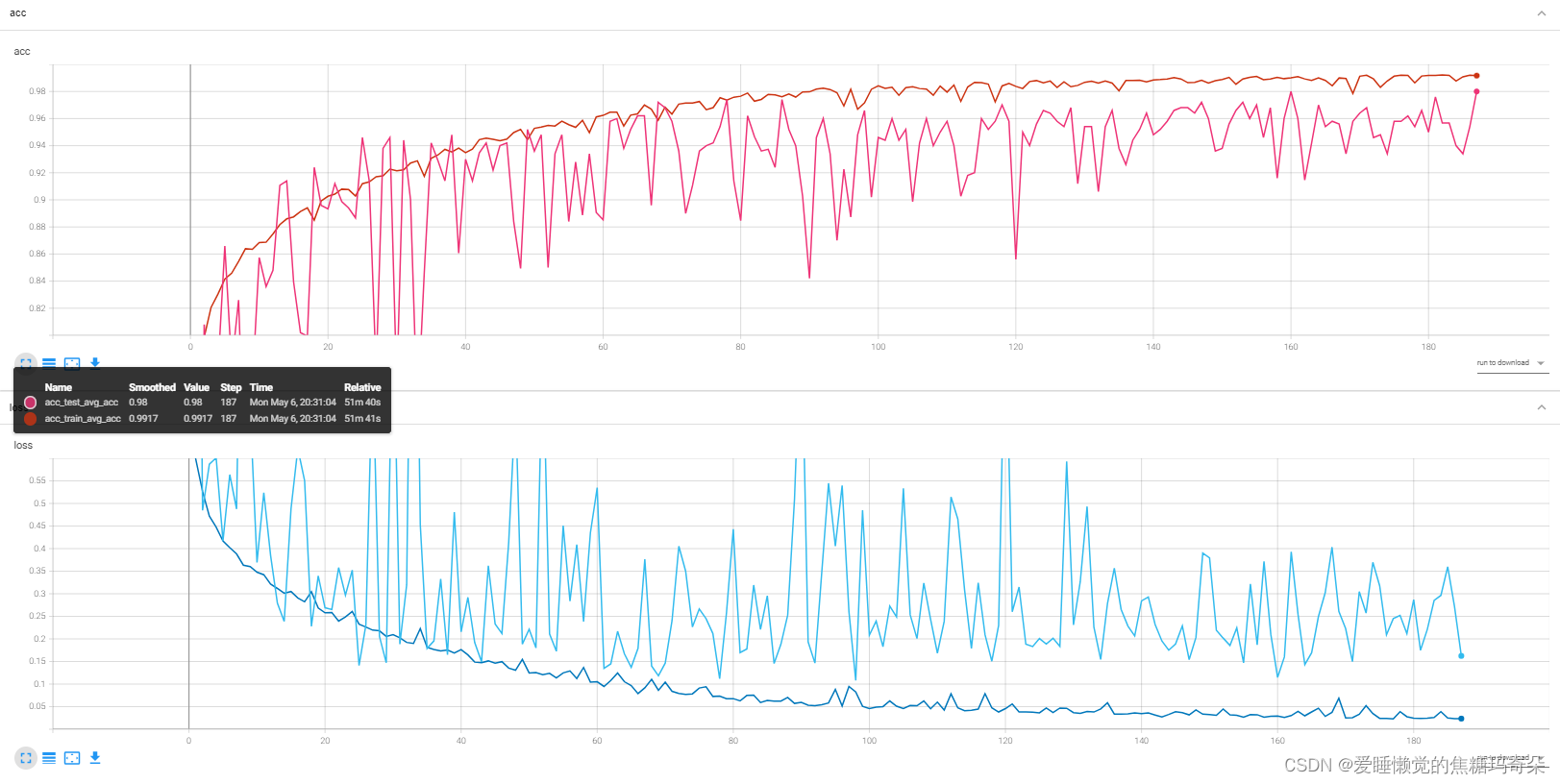
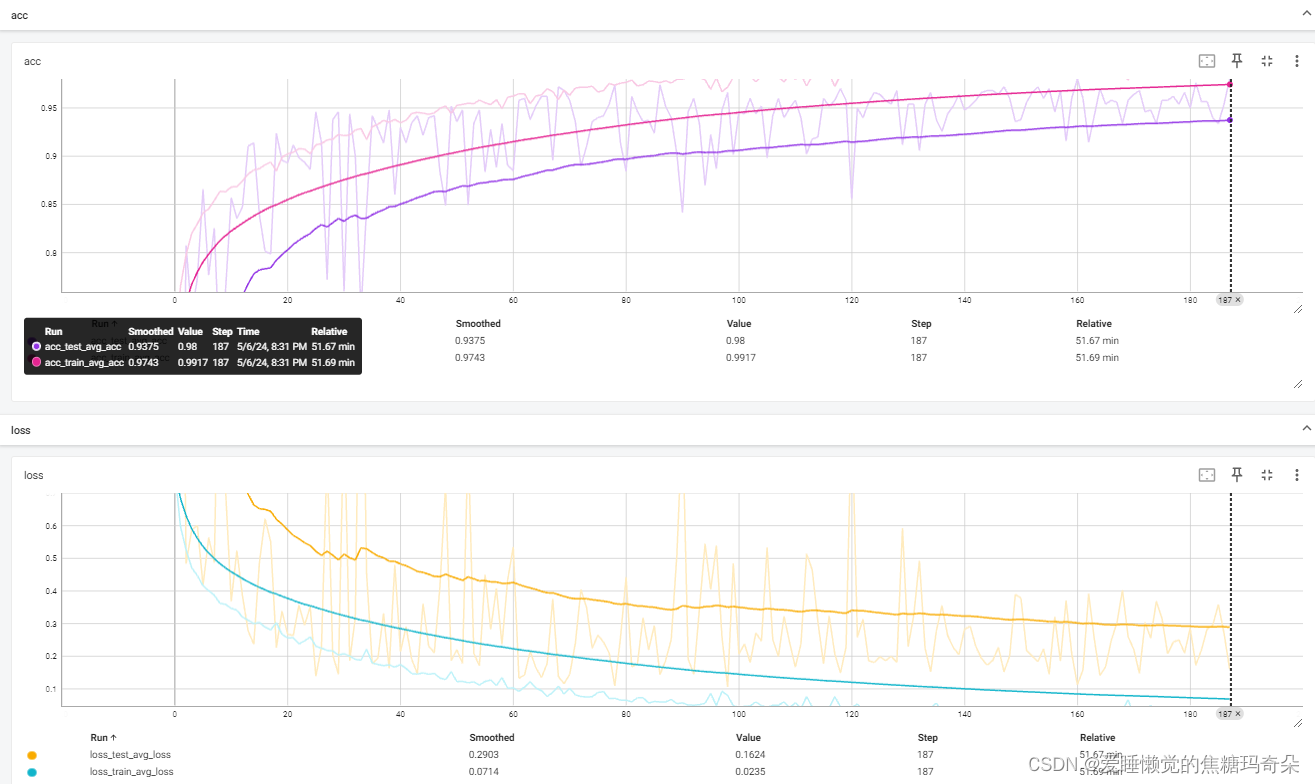
耶!准确率高达98%,叼不叼兄弟
以图搜图,验证学习效果:
import glob
import json
import os.path
import cv2
import numpy as np
import torch
import tqdm
from torch import nn
from net import VGGnet_pro
from torchvision import models, transforms
import torch.nn.functional as F
from PIL import Image
from torchvision.models import MobileNet_V2_Weights
test_transforms = transforms.Compose([# 将 H W C--> C H W# [0 255] -->[0, 1]
transforms.ToTensor(),
transforms.Resize(size=(64,64), antialias=True)])
BASE_PATH ="../AI_dataset_pic/AllTest"classSearchImage:def__init__(self):
self.model = self.load_model()# 加载已存储的数据
self.db_feats, self.db_names = self.load_db_feat()defload_model(self):# 创建网络加载参数
model = VGGnet_pro()
model.load_state_dict(torch.load('./VGGnet_pro3.pt', map_location=torch.device('cpu')))# 开启验证
model.eval()# print(model)return model
defpre_process(self, img_path):"""
预处理
"""# H W C# img = cv2.imread(img_path)
img = Image.open(img_path)# C H W
img = test_transforms(img)# N C H W
img = torch.unsqueeze(img,0)return img
deflayer_to_feat(self,x):
x = self.model.conv_layer1(x)
res = self.model.conv_res(x)
x = self.model.conv_layer2(x)
x = self.model.conv_layer3(x)
x = F.relu(x + res)
x = self.model.conv_layer4(x)return x
defextract_img_feat(self, img_path):"""
提取特征
"""
img = self.pre_process(img_path)# 不能直接这样使用 这样使用获取的是分类# feat = self.model(img)
x = self.layer_to_feat(img)# Cannot use "squeeze" as batch-size can be 1
x = nn.functional.adaptive_avg_pool2d(x,(1,1))# (1, 1280) --(1280, )
feat = torch.flatten(x,1)[0]# print(feat.shape)
feat = feat.detach().numpy().astype(np.float64)return feat
definit_img_feats(self):"""
提取图片特征进行储存
"""
img_paths = glob.glob(os.path.join(BASE_PATH,"*"))withopen("features.txt","w",encoding="utf-8")asfile:for img_path in tqdm.tqdm(img_paths,total=len(img_paths)):
feat = self.extract_img_feat(img_path)
feat =list(feat)# img_name feat
img_name = img_path.split("\\")[-1]# python 对象转换为 json字符串
feat_str = json.dumps(feat)file.write(img_name +"|"+ feat_str +"\n")passdefload_db_feat(self):"""
加载已存储的特征
"""
db_names, db_feats =[],[]withopen("features.txt",'r',encoding='utf-8')asfile:
lines =file.readlines()for line in lines:
img_name, feat_str = line.split("|")# 将json字符串转换为python对象
feat = json.loads(feat_str)
db_names.append(img_name)
db_feats.append(feat)pass
db_feats = np.array(db_feats)# "O" -->object 会保持原有的类型
db_names = np.array(db_names, dtype="O")return db_feats, db_names
defcal_similarity(self, img_path):"""
相识度的计算
提取当前图片的特征 img_feat
获取到已存储的图片的特征以及名称 db_feats,
db_names
"""
img_feat = self.extract_img_feat(img_path)
db_feats, db_names = self.db_feats, self.db_names
dist = np.linalg.norm(db_feats - img_feat, axis=1)# 排序
dist_name = np.column_stack((dist, db_names))
sort_idx = np.argsort(dist_name[:,0])[:15]
sort_dist_name = dist_name[sort_idx]print(sort_dist_name)
img_names = sort_dist_name[:,1]# 可视化图像
self.visual_img(img_names)defvisual_img(self, img_names):
window_x =1for img_name in img_names:
img_path = os.path.join(BASE_PATH, img_name)
img = cv2.imread(img_path)
cv2.imshow(f"{img_path}", img)
cv2.moveWindow(f"{img_path}", window_x*98,100)
window_x +=1
cv2.waitKey(0)# image = Image.open(img_path)# image.show('img')if __name__ =='__main__':
search_img = SearchImage()
search_img.init_img_feats()#验证之前需要使用高精度模型获取图库中训练集的特征,使用该函数获取特征文件之后即可注释
img_path ="../AI_dataset_pic/AllTest/1713842106378851.jpg"
search_img.cal_similarity(img_path)
搜图效果也非常好,搜索摩托车出来前15个都是摩托车: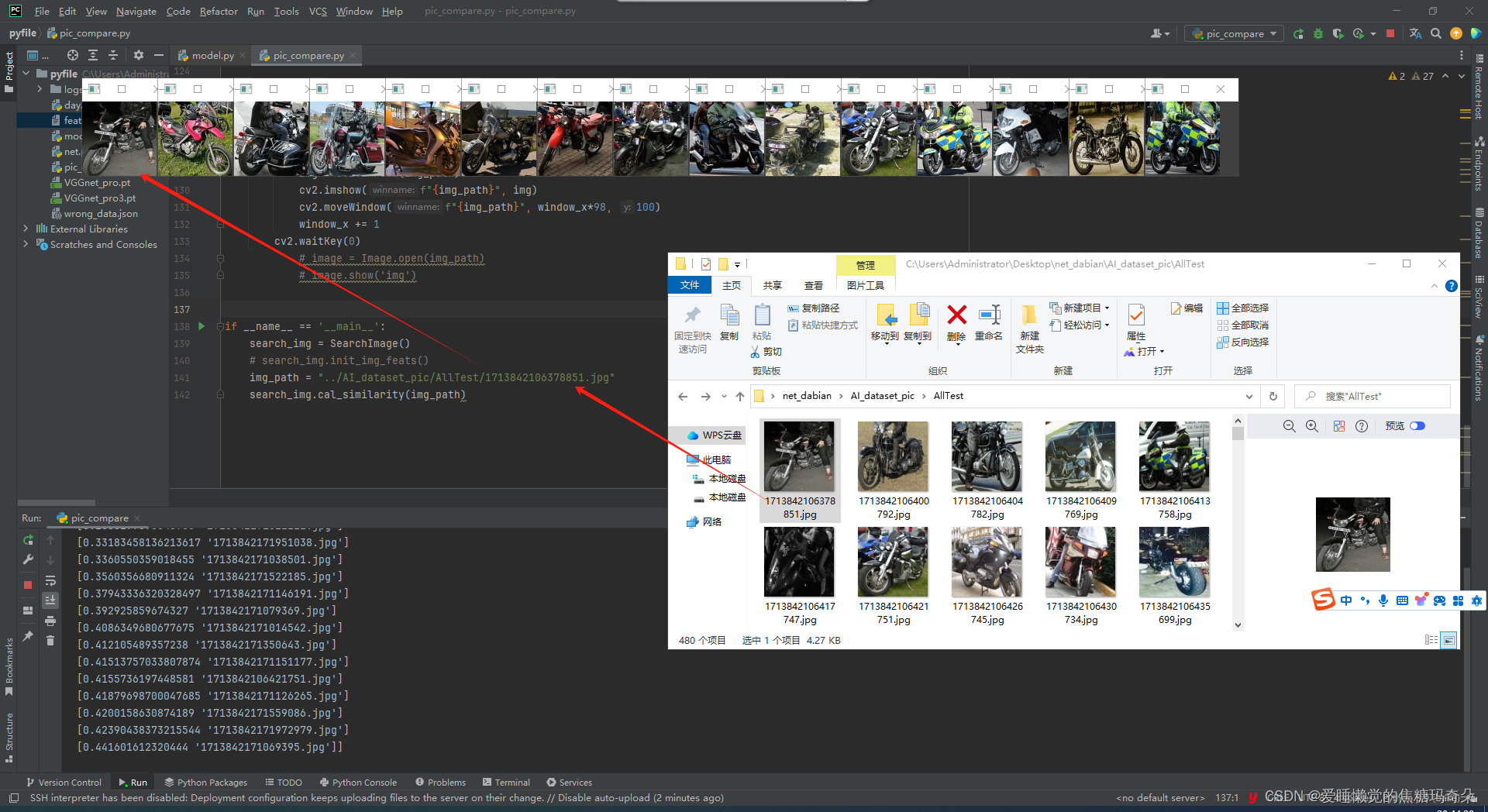
数据集下载链接:
数据集四分类
本文转载自: https://blog.csdn.net/Jiagym/article/details/138579221
版权归原作者 爱睡懒觉的焦糖玛奇朵 所有, 如有侵权,请联系我们删除。
版权归原作者 爱睡懒觉的焦糖玛奇朵 所有, 如有侵权,请联系我们删除。