
论文:https://arxiv.org/pdf/1708.06519.pdf
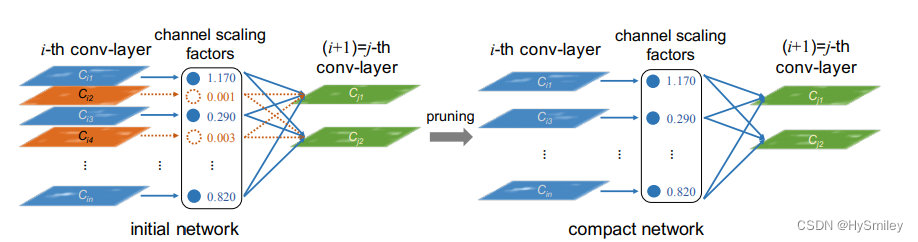
BN层中缩放因子γ与卷积层中的每个通道关联起来。在训练过程中对这些比例因子进行稀疏正则化,以自动识别不重要的通道。缩放因子值较小的通道(橙色)将被修剪(左侧)。剪枝后,获得了紧凑的模型(右侧),然后对其进行微调,以达到与正常训练的全网络相当(甚至更高)的精度。
BN层原理:

归一化化后,BN层服从正态分布,当γ,β趋于0时,经过阈值分离,输出为0,与之连接的卷积层输入为0。
剪枝流程:
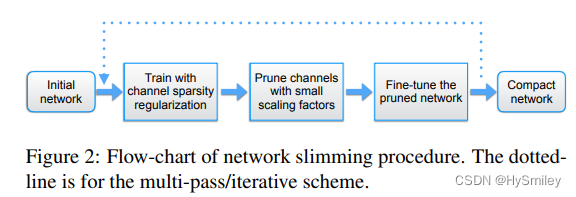
剪枝原理:
在BN层网络中加入稀疏因子,训练使得BN层稀疏化,对稀疏训练的后的模型中所有BN层权重进行统计排序,获取指定保留BN层数量即取得排序后权重阈值thres。遍历模型中的BN层权重,制作各层mask(权重>thres值为1,权重<thres值为0)。剪枝操作,根据各层的mask构建新模型结构(各层保留的通道数),获取BN层权重*mask非零值的索引,非零索引对应的原始conv层、BN层、linear层各通道的权重、偏置等值赋值给新模型各层。加载剪枝后模型,进行fine-tune。
如下实现一个简单的网络剪枝。
1、自定义一个网络
对网络进行
import torch
import torch.nn as nn
import numpy as np
class net(nn.Module):
def __init__(self,cfg=None):
super(net, self).__init__()
if cfg:
self.features=self.make_layer(cfg)
self.linear = nn.Linear(cfg[2], 2)
else:
layers=[]
layers+=[nn.Conv2d(3,64,7,2,1,bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)]
layers += [
nn.Conv2d(64,128,3,2,1,bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True)
]
layers += [
nn.Conv2d(128, 256, 3, 2, 1,bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True)
]
layers += [nn.AvgPool2d(2)]
self.features=nn.Sequential(*layers)
self.linear=nn.Linear(256,2)
def make_layer(self,cfg):
layers=[]
layers += [nn.Conv2d(3, cfg[0], 7, 2, 1, bias=False),
nn.BatchNorm2d(cfg[0]),
nn.ReLU(inplace=True)]
layers += [
nn.Conv2d(cfg[0], cfg[1], 3, 2, 1, bias=False),
nn.BatchNorm2d(cfg[1]),
nn.ReLU(inplace=True)
]
layers += [
nn.Conv2d(cfg[1], cfg[2], 3, 2, 1, bias=False),
nn.BatchNorm2d(cfg[2]),
nn.ReLU(inplace=True)
]
layers += [nn.AvgPool2d(2)]
return nn.Sequential(*layers)
def forward(self,x):
x=self.features(x)
# print(x.shape)
x=x.view(x.size(0),-1)
x=self.linear(x)
return x
网络参数信息:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [1, 64, 8, 8] 9,408
BatchNorm2d-2 [1, 64, 8, 8] 128
ReLU-3 [1, 64, 8, 8] 0
Conv2d-4 [1, 128, 4, 4] 73,728
BatchNorm2d-5 [1, 128, 4, 4] 256
ReLU-6 [1, 128, 4, 4] 0
Conv2d-7 [1, 256, 2, 2] 294,912
BatchNorm2d-8 [1, 256, 2, 2] 512
ReLU-9 [1, 256, 2, 2] 0
AvgPool2d-10 [1, 256, 1, 1] 0
Linear-11 [1, 2] 514
================================================================
Total params: 379,458
Trainable params: 379,458
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.17
Params size (MB): 1.45
Estimated Total Size (MB): 1.62
2、稀疏训练
在BN层中各权重加入稀疏因子。
def updateBN(model,s=0.0001):
for m in model.modules():
if isinstance(m,nn.BatchNorm2d):
m.weight.grad.data.add_(s*torch.sign(m.weight.data))
if __name__=="__main__":
model=net()
# from torchsummary import summary
# print(summary(model,(3,20,20),1))
# x = torch.rand((1, 3, 20, 20))
# print(model(x))
optimer=torch.optim.Adam(model.parameters())
loss_fn=torch.nn.CrossEntropyLoss()
for e in range(100):
x = torch.rand((1, 3, 20, 20))
y=torch.tensor(np.random.randint(0,2,(1))).long()
out=model(x)
loss=loss_fn(out,y)
optimer.zero_grad()
loss.backward()
#BN权重稀疏化
updateBN(model)
optimer.step()
torch.save(model.state_dict(),"net.pth")
3、剪枝
稀疏训练后的模型,解析。
import net
import torch
import torch.nn as nn
import numpy as np
model = net.net()
#加载稀疏训练的模型
model.load_state_dict(torch.load("net.pth"))
total = 0 # 统计所有BN层的参数量
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):
# print(m.weight.data.shape[0]) # 每个BN层权重w参数量:64/128/256
# print(m.weight.data)
total += m.weight.data.shape[0]
print("所有BN层总weight数量:",total)
bn_data=torch.zeros(total)
index=0
for m in model.modules():
#将各个BN层的参数值拷贝到bn中
if isinstance(m,nn.BatchNorm2d):
size=m.weight.data.shape[0]
bn_data[index:(index+size)]=m.weight.data.abs().clone()
index=size
#对bn中的weight值排序
data,id=torch.sort(bn_data)
percent=0.7#保留70%的BN层通道数
thresh_index=int(total*percent)
thresh=data[thresh_index]#取bn排序后的第thresh_index索引值为bn权重的截断阈值
#制作mask
pruned_num=0#统计BN层剪枝通道数
cfg=[]#统计保存通道数
cfg_mask=[]#BN层权重矩阵,剪枝的通道记为0,未剪枝通道记为1
for k,m in enumerate(model.modules()):
if isinstance(m,nn.BatchNorm2d):
weight_copy=m.weight.data.abs().clone()
# print(weight_copy)
mask=weight_copy.gt(thresh).float()#阈值分离权重
# print(mask)
# exit()
pruned_num+=mask.shape[0]-torch.sum(mask)#
# print(pruned_num)
m.weight.data.mul_(mask)#更新BN层的权重,剪枝通道的权重值为0
m.bias.data.mul_(mask)
cfg.append(int(torch.sum(mask)))#记录未被剪枝的通道数量
cfg_mask.append(mask.clone())
print("layer index:{:d}\t total channel:{:d}\t remaining channel:{:d}".format(k,mask.shape[0],int(torch.sum(mask))))
elif isinstance(m,nn.AvgPool2d):
cfg.append("A")
pruned_ratio=pruned_num/total
print("剪枝通道占比:",pruned_ratio)
print(cfg)
newmodel=net.net(cfg)
# print(newmodel)
# from torchsummary import summary
# print(summary(newmodel,(3,20,20),1))
layer_id_in_cfg=0#层
start_mask=torch.ones(3)
end_mask=cfg_mask[layer_id_in_cfg]#第一个BN层对应的mask
# print(cfg_mask)
# print(end_mask)
for(m0,m1)in zip(model.modules(),newmodel.modules()):#以最少的为准
if isinstance(m0,nn.BatchNorm2d):
# idx1=np.squeeze(np.argwhere(np.asarray(end_mask.numpy())))#获得mask中非零索引即未被减掉的序号
# print(idx1)
# exit()
# idx1=np.array([1])
# # print(idx1)
if idx1.size==1:
idx1=np.resize(idx1,(1,))
# print(idx1)
# exit()
#将旧模型的参数值拷贝到新模型中
m1.weight.data=m0.weight.data[idx1.tolist()].clone()
m1.bias.data=m0.bias.data[idx1.tolist()].clone()
m1.running_mean=m0.running_mean[idx1.tolist()].clone()
m1.running_var = m0.running_var[idx1.tolist()].clone()
layer_id_in_cfg+=1#下一个mask
start_mask=end_mask.clone()
if layer_id_in_cfg<len(cfg_mask):
end_mask=cfg_mask[layer_id_in_cfg]
elif isinstance(m0,nn.Conv2d):#输入
idx0=np.squeeze(np.argwhere(np.asarray(start_mask.numpy())))#输入非0索引
idx1=np.squeeze(np.argwhere(np.asarray(end_mask.numpy())))#输出非0索引
if idx0.size==1:
idx0=np.resize(idx0,(1,))
if idx1.size==1:
idx1=np.resize(idx1,(1,))
w1=m0.weight.data[:,idx0.tolist(),:,:].clone()
w1=w1[idx1.tolist(),:,:,:].clone()
m1.weight.data=w1.clone()
elif isinstance(m0,nn.Linear):
idx0 = np.squeeze(np.argwhere(np.asarray(start_mask.numpy()))) # 输入非0索引
if idx0.size==1:
idx0=np.resize(idx0,(1,))
m1.weight.data=m0.weight.data[:,idx0].clone()
m1.bias.data=m0.bias.data.clone()
torch.save(newmodel.state_dict(),"prune_net.pth")
print(newmodel)
新模型结构:
所有BN层总weight数量: 448
layer index:3 total channel:64 remaining channel:29
layer index:6 total channel:128 remaining channel:56
layer index:9 total channel:256 remaining channel:75
剪枝通道占比: tensor(0.6429)
[29, 56, 75, 'A']
net(
(features): Sequential(
(0): Conv2d(3, 29, kernel_size=(7, 7), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(29, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(29, 56, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(4): BatchNorm2d(56, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(56, 75, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(7): BatchNorm2d(75, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): AvgPool2d(kernel_size=2, stride=2, padding=0)
)
(linear): Linear(in_features=75, out_features=2, bias=True)
)
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [1, 29, 8, 8] 4,263
BatchNorm2d-2 [1, 29, 8, 8] 58
ReLU-3 [1, 29, 8, 8] 0
Conv2d-4 [1, 56, 4, 4] 14,616
BatchNorm2d-5 [1, 56, 4, 4] 112
ReLU-6 [1, 56, 4, 4] 0
Conv2d-7 [1, 75, 2, 2] 37,800
BatchNorm2d-8 [1, 75, 2, 2] 150
ReLU-9 [1, 75, 2, 2] 0
AvgPool2d-10 [1, 75, 1, 1] 0
Linear-11 [1, 2] 152
================================================================
Total params: 57,151
Trainable params: 57,151
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.07
Params size (MB): 0.22
Estimated Total Size (MB): 0.29
----------------------------------------------------------------
模型大小由1.45m压缩到230k,压缩率:84%
4、fine-tune训练
newmodel.load_state_dict(torch.load("prune_net.pth"))
#
optimer=torch.optim.Adam(model.parameters())
loss_fn=torch.nn.CrossEntropyLoss()
for e in range(100):
x = torch.rand((1, 3, 20, 20))
y=torch.tensor(np.random.randint(0,2,(1))).long()
out=newmodel(x)
loss=loss_fn(out,y)
optimer.zero_grad()
loss.backward()
optimer.step()
torch.save(newmodel.state_dict(),"prune_net.pth")
以上过程仅供参考。
参考:GitHub - foolwood/pytorch-slimming: Learning Efficient Convolutional Networks through Network Slimming, In ICCV 2017.
Network Slimming——有效的通道剪枝方法(Channel Pruning)_Law-Yao的博客-CSDN博客_通道剪枝算法
版权归原作者 HySmiley 所有, 如有侵权,请联系我们删除。