

论文题目: Seamless: Multilingual Expressive and Streaming Speech Translation
论文链接: https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/
代码链接: GitHub - facebookresearch/seamless_communication: Foundational Models for State-of-the-Art Speech and Text Translation
项目主页: https://ai.meta.com/research/seamless-communication/
今年以来,以ChatGPT和GPT-4为代表的大型语言模型和视觉语言多模态大模型几乎完全引领了人工智能领域发展的潮流,在垂直领域也衍生出了一些行业专用的大模型,例如金融大模型、交通大模型和遥感大模型等。而对于数据输入的三种基本模态而言,语音信号在AI领域的重要性也不言而喻。近期,MetaAI的研究团队发布了一套全流程的语言语音大模型Seamless(”无缝沟通“),Seamless主打流畅高效的多语言无缝翻译功能,在传统翻译系统的基础上,对用户的说话方式进行快速模拟,保证翻译出的语音信号完整保留用户的语气、停顿和强调音等关键信息,帮助我们更好的传递情感和意图。需要指出的是,Seamless是由三个基础模型构成:
(1)SeamlessExpressive:旨在保留跨语言的表达方式和复杂性的模型,目前已经支持英语、西班牙语、德语、法语、意大利语和中文等语言。
(2)SeamlessStreaming:高效的流媒体翻译模型,可在大约两秒的延迟下进行语音和文本翻译。
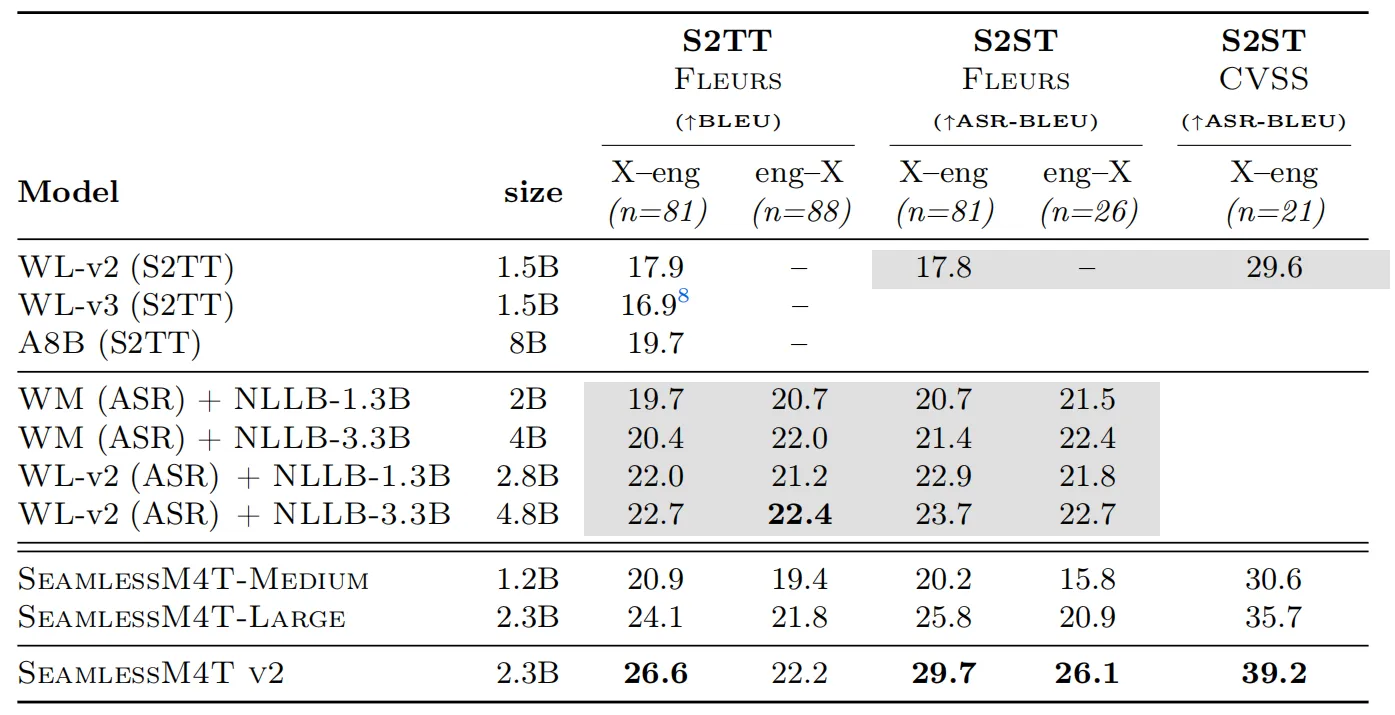
(3)SeamlessM4T v2:是Meta在今年8月份发布的SeamlessM4T升级版本,基础的多语言和多任务模型,在接近450万小时的语音数据上进行了训练,在自动语音识别、语音转语音、语音转文本和文本转语音等多种基线任务上实现了性能提升。
Seamless一经发布就引起了广泛的关注,作为Meta首席人工智能科学家的LeCun第一时间为Seamless进行宣传。

此外,开源区大佬Georgi Gerganov已经开始了对Seamless的Cpp重写和推理加速工作,先前,Georgi Gerganov已经对Meta的LLaMA、OpenAI的Wisper等明星大模型开发了C++版本,其中llama.cpp在GitHub上的star数已经突破了6.5w。
01. 多任务基座模型SeamlessM4T v2
多任务预训练范式可以说是GPT系列模型的底层技术,Seamless作为语音翻译领域的统一系统,同样借鉴了这样的构建逻辑。SeamlessM4T在广泛的语种和语音翻译任务上进行了大规模预训练,作者团队在构建SeamlessM4T v2版本时,重点对其多任务预测单元UnitY进行了升级,SeamlessM4T v2将语音翻译任务分为语音到文本翻译(speech-to-text translation,S2TT)和文本到单元转换(text-to-unit conversion,T2U)两种。由于先前版本的UnitY在面对语音序列和文本序列长度不匹配情况时出现幻觉现象,作者提出了一种新的两阶段UnitY2单元,UnitY2采用了一种非自回归(non-autoregressive,NAR)的单元解码器架构,可以更好的对离散单元进行建模,基于UnitY2预测单元的SeamlessM4T v2模型整体架构如下图所示。
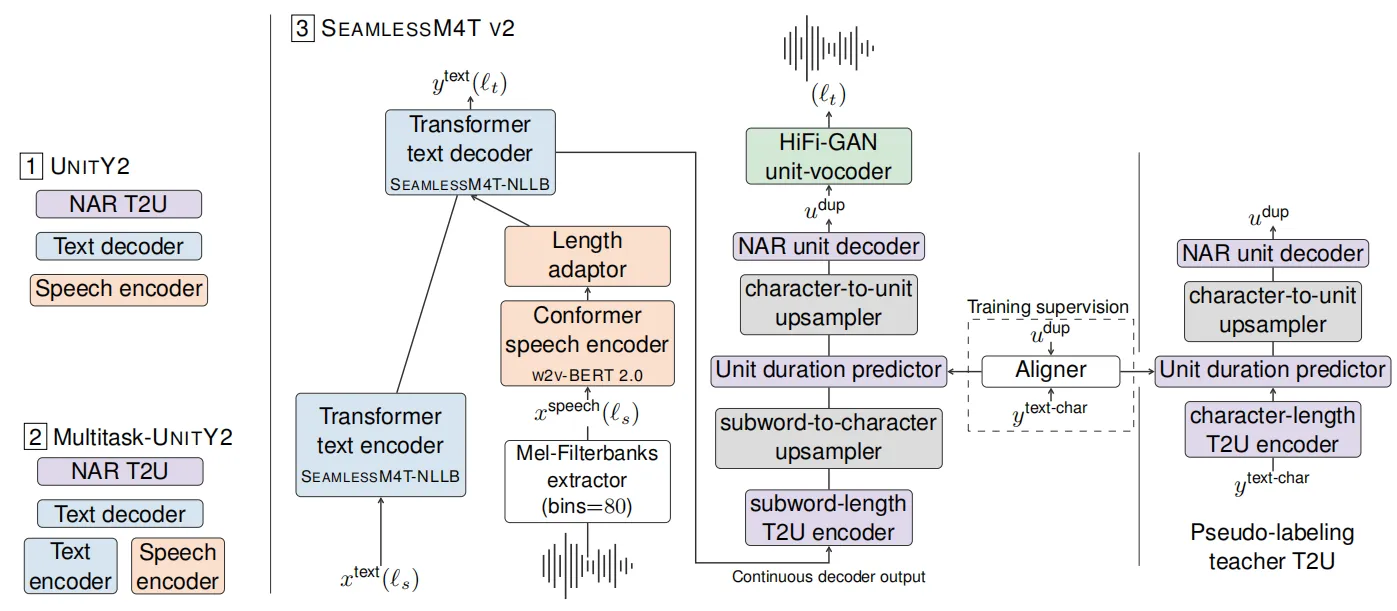
UnitY2的更新提高了SeamlessM4T v2在各种任务上的翻译质量,目前,SeamlessM4T v2 实现了在 100 种语言上的语音到语音和语音到文本翻译的SOTA性能。
02. SeamlessExpressive完美攻克翻译语调保留难题
语音中的韵律在人类交流中扮演着重要的角色,它能够表现出说话者的情绪状态、态度和意图,而这一重要因素在以往的语音翻译模型和系统中却被忽视了。通常,我们会使用音调(高或低)、响度(强或弱)和持续时间(快或慢)的变化来在不同情况下表达自己的真实意图,SeamlessExpressive可以在保留语义内容不变的情况下,精确捕捉说话人的语速和停顿等信息,并使用目标语言进行转述。

下图展示了SeamlessExpressive的整体框架,从实现角度来看,SeamlessExpressive主要基于SeamlessM4T v2模型进行构建,其继承了高质量的语义翻译能力。作者团队提出了一种基于UnitY2单元的韵律感知单元Prosody UnitY2,同时提出了一种无文本的声学模型PRETSSEL,Prosody UnitY2 和 PRETSSEL 可以在传递源语言语音的表现力方面进行相互补充。具体来说,Prosody UnitY2 主要关注语音中的短语级韵律,例如语速或停顿,而 PRETSSEL 则更着重于翻译话语级的表达力,例如整体的声音风格。

为了实现在多种语言之间的韵律对齐,作者通过数据调试、自动对齐和合成等手段构建了一个大规模的韵律对齐和语音对齐数据集,同时支持英语、法语、德语、意大利语、普通话和西班牙语在内的6种语言。
03. 同声传译SeamlessStreaming
在国际会议中,同声传译是一个非常关键的会议任务,人类口译员需要快速的理解说话人的含义,并根据自己的经验知识在低延迟和准确翻译之间找到一个适当的平衡,还需要留意说话人的语调、停顿和态度等信号,综合来看,该任务的难度系数非常高,SeamlessStreaming完美实现了以上列出的同声传译要点。

与传统翻译系统相比,SeamlessStreaming并不是等说话人说完句子才进行翻译,而是与说话人几乎相同的步调进行翻译,这能够实现一种接近于实时翻译的效果。目前,SeamlessStreaming 支持近 100 种输入和输出语言的自动语音识别和语音到文本翻译。
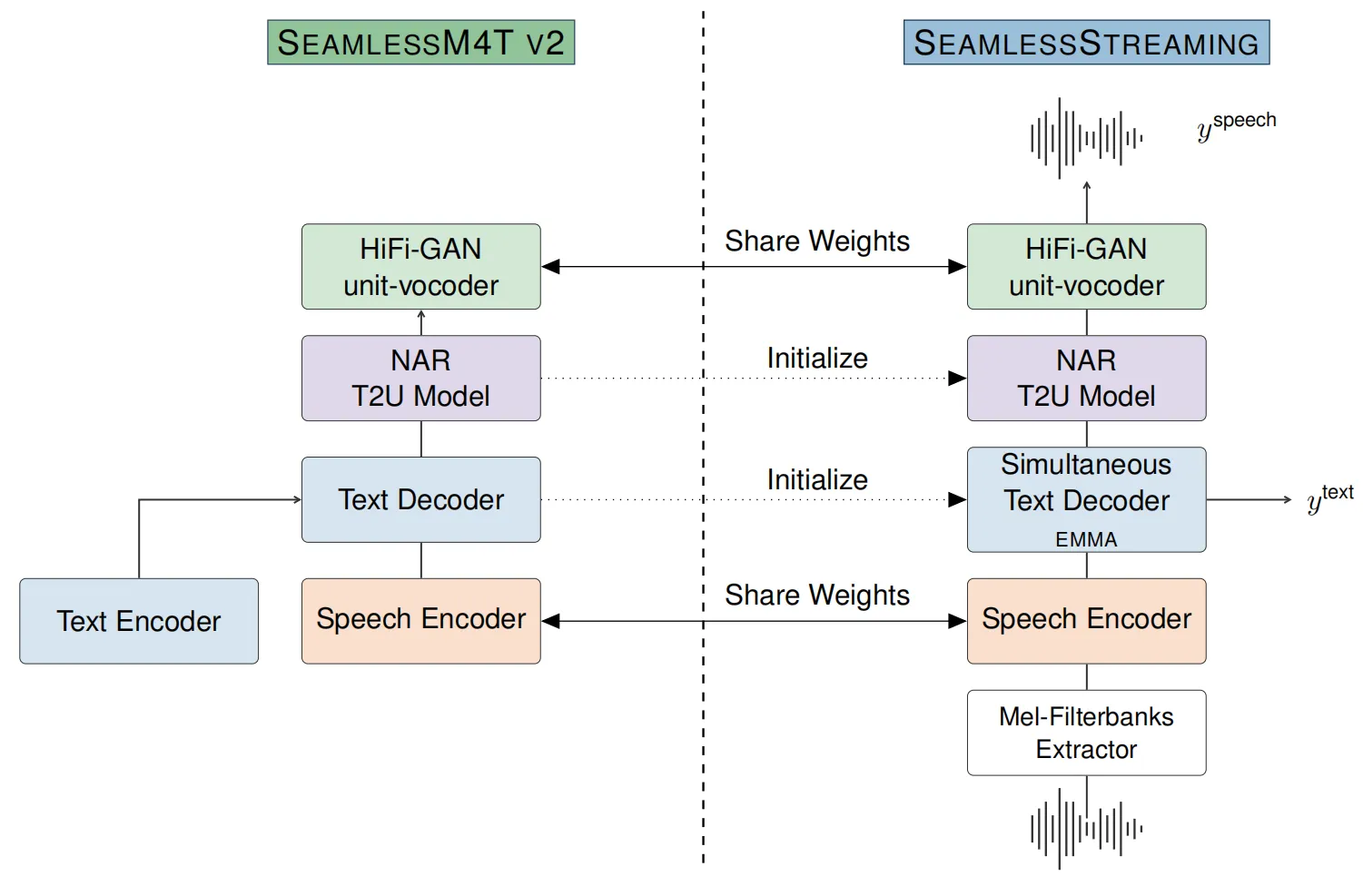
SeamlessStreaming直接从SeamlessM4T v2进行初始化,其构建过程如下图所示,其继承了SeamlessM4T v2模型的多任务实时翻译能力。SeamlessStreaming的高效流推理能力主要来源于研究团队提出的新型EMMA(Efficient Monotonic Multihead Attention)多头注意力模块,EMMA是一种单调注意力方法,其中的每个注意力头都执行单独的同步策略。这使得模型能够智能地判断当前状态是否拥有足够的信息量来生成下一个语音片段或目标文本,这对于低时延的语音翻译至关重要,特别是对于长输入序列。
04. 音频水印技术
虽然目前的大模型可以帮助我们更好的进行生产生活,但同样重要的是,我们必须考虑采取一定的措施来防止这些技术被滥用到有危害的场景中,因此MetaAI研究团队针对Seamless开发了一种音频水印技术,这种水印主要基于一些人耳无法察觉的信号,但仍然可以使用检测器模型在音频中检测到。
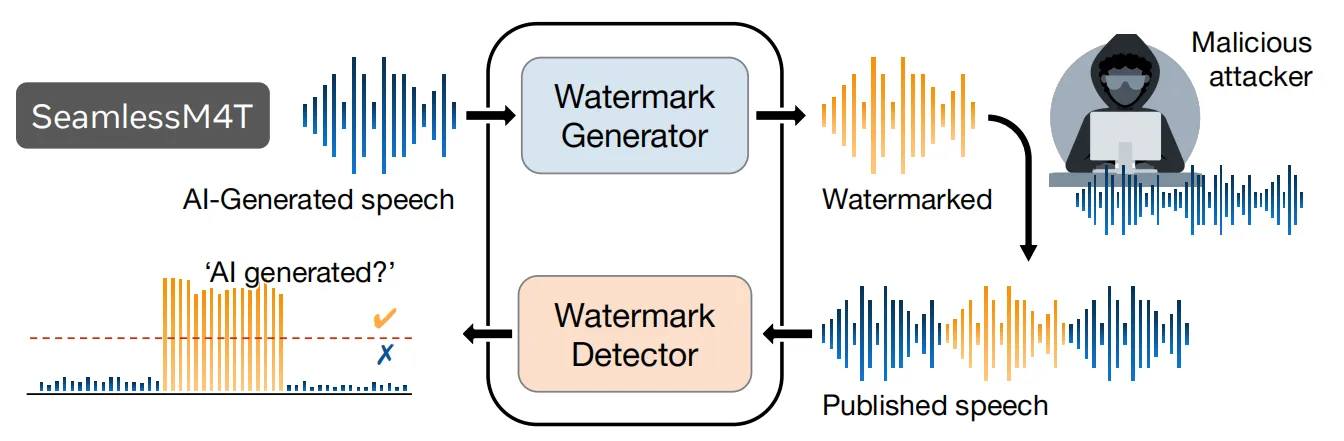
除了能够对生成音频进行身份信息验证之外,Seamless水印还支持抗攻击能力,例如一些破坏者可能会尝试通过添加噪声、回声或过滤某些频率来修改音频,以淡化水印来绕过检测。Seamless水印对多种攻击方式都具有良好的鲁棒性,并且可以实现精确到帧的音频片段定位效果。此外,作者提到,Seamless水印模型的成本非常低,它可以进行单独微调,而不会影响SeamlessExpressive和SeamlessStreaming的翻译效果。
05. 总结
MetaAI发布的Seamless模型为我们展现出了惊人的同声传译效果,并且支持近 100 种语言,其中的多任务基础模型SeamlessM4T v2在多个语音基线上实现了SOTA性能,Seamless Expressive可以保证翻译时保留说话人的韵律和语音风格,SeamlessStreaming中的高效多头注意力EMMA可以有针对性地实现并行低延迟翻译,而无需等待当前话语结束。作为下一代语音智能大模型,Seamless系列模型所展现出的端到端多语言、富有表现力和低时延的流媒体式翻译模式,标志着人工智能技术在语音翻译领域实现了全新的突破。
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区
版权归原作者 TechBeat人工智能社区 所有, 如有侵权,请联系我们删除。