
山东大学软件学院2022-2023数据仓库数据挖掘期末考试(回忆版)
前言
1、考试时间:2023/2/14 14:30-16:30 (因疫情推迟到开学考的期末考试)
2、考试科目:数据仓库数据挖掘(老师:PanPeng)
3、考试语言:中文
4、考试题型:简答、计算、画图(最好带个尺子,容易画图)。
5、考后感想:题量比较大,需要对题目比较熟练,题目类型和ppt上差不多,不过相对而言比较难。备考的同学注重算法题(fp-tree、GSP、DB-SCAN),还有MOLAP和逻辑模型、数据流等。
一、简答题
(1)数据预处理的主要任务有哪些?每个人物要解决的问题主要有那些?
(2)维度归约有哪两类技术?有什么区别。
(3)什么是离群点?离群点挖掘有什么意义?主要有哪四种方法?
(4)数据仓库的主要特征,画出数据仓库的体系结构图。
二、下面是两组COVID病毒阳性的真实和预测情况表,根据要求完成作答。
(数据大概可能如此吧…)
模型一:
PositiveNegativePositive255Negative104960
模型二:
PositiveNegativePositive466Negative79940
(1)写出两组模型的准确率、错误率、精确率、召回率。
(2)结合实际,说明哪种模型更合理。
三、利用fp-tree算法完成以下作答。
(原图忘了,找的ppt上的)
(1)写出挖掘过程,画出fp树,写出在挖掘过程中的数据集的变化。
(2)给出m的条件模式基,写出挖掘过程。
四、给出如下概念模型,完成以下作答。
(模型大概是这样吧,记不清了)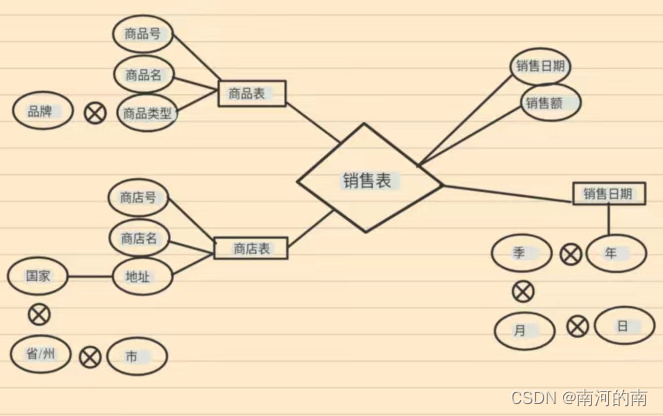
(1)画出逻辑模型。
(2)如果在时间要在时间维度上进行归约,那么维度表和事实表如何设计。
(3)现在要查询2017年第一季度商品的销售额,由基本方体[日,商品名,地址]开始,写出需要进行的OLAP操作。
(4)写出MOLAP的工作原理。
五、用GSP算法完成以下作答。
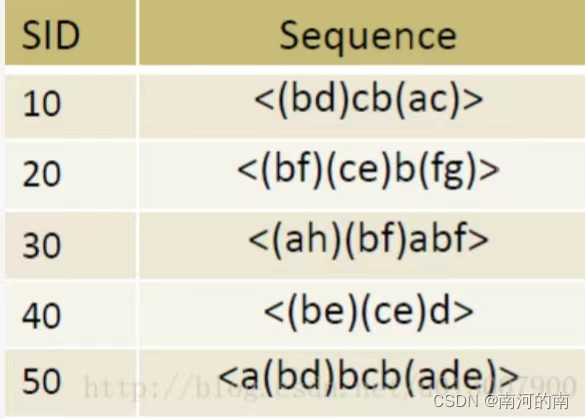
(1)根据上图写出挖掘频繁序列模式的过程。
(2)写出最长的序列。
(3)写出由k-1序列生成k序列的两个重要过程,设种子集合Ck-1,频繁模式Lk。
六、DBSCAN
下面给出一个样本事务表数据库,对它实施DBSCAN算法,设
ϵ
\epsilon
ϵ=3, MinPts=3。(原图记不住,图是找的ppt上的,不过ppt上面这道题的
ϵ
\epsilon
ϵ=1, MinPts=4)
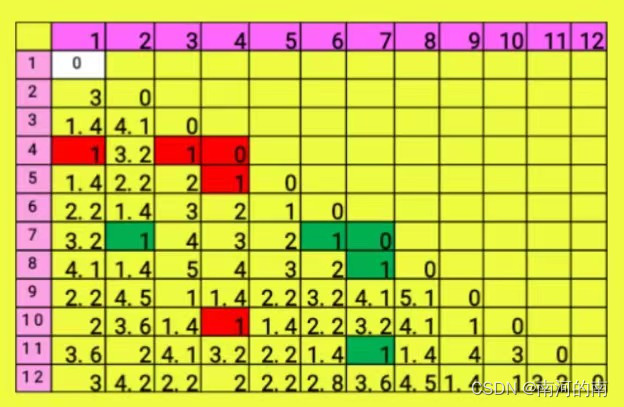
(1)根据上图写出挖掘频繁序列模式的过程。
(2)写出上图中数据点中的核心对象。
(3)找出两组密度可达和密度相连的点。
七、数据流问题。
给出如下数据流,在接下来的时间内数据流进入了二进制串:11011。根据要求完成作答。(具体数据流想不起来,找的ppt上的)
(1)写出二进制串全部进入后,bucket的情况。
(2)写出二进制串全部进入后,所有1的个数。
总结
注意:Aprior、FP-tree、Aprior-all、GSP、k-means、k-medoid、AGNES、DIANA、DB-SCAN、DGIM、MOLAP和逻辑模型、数据流、推荐算法。
================= 题量比较大、注意时间!!!==================
祝考试顺利~~
点个赞呗~~
版权归原作者 南河的南 所有, 如有侵权,请联系我们删除。