
【关注我,思路实时更新,详细思路持续更新。去年原创思路,被很多机构贩卖,都是免费的,程序也是免费的,以前是您好啊数模君/数模孵化园,现在改名啦,认准:小叶的趣味数模,原创发布,别被坑了】
【详细思路,B已更新】
B题思路
整个题没有组合投资就比较简单,给的是宏观数据,首先宏观数据都是需要进行预测的,然后选择相关性较高的指标用于预测股票走势,不管是线性回归还是其他算法都可以,数据可以做插值拟合进行补充,以股票时刻为准。插值拟合推荐使用保形样条插值法,在matlab使用filliming函数的pchip参数实现。关于很多人说的指标时间刻度不一样的问题,一种是以股票时刻为准,其他的指标按趋势拆为每5分钟的数据,或者是都按天取平均,不管怎么样,需要统一下时间刻度,很多人也说数据相关性不是特别大,毕竟时间精度不一样,所以再求相关性时,可以对数据先进行平滑处理
K线图怎么画就通过Kplot函数实现,这个肯定论文里需要放一个图的,一般股票的预测都是拿收盘价来预测。
来看看第一问,刚刚说了一般都是拿股票收盘价来预测,那么这里的主要指标,肯定是与收盘价相关性较高的指标,第一问就比较简单,直接通过相关性方法(推荐余弦相似度、方差分析)来做就行,不是主成分哈,那求得是映射基向量,是用来反映数据整体特征的,虽然是主要成分,但是这道题要求是找到与“数字经济”板块有关的重要指标,别用错算法了,后问也提到了成交量,这里在做一个关于成交量的相关性分析,找出相关性较强的指标。
第二问第三问就是分别用主要指标作为输入,成交量和收盘价分别作为输出,带入机器学习算法(推荐神经网络、Xgboost)中训练,最后记得做误差验证。
第四问这里普及下,可以买多也可以买空,买多就是股票涨了,你买入就赚了,买空就是股票降低买入你就赚了,一个是买多一个是买空,别绕进去了,程序中一定要记录好,关于交易多少,这个是需要大家构建一个风控模型的,股票价格就假设收盘价是一笔的价格,后面买入和卖出,都按整数笔交易,虽然题目是有2022年1月4日至2022年1月28 日的数据,你如果参考的话那肯定你的收益很高,要理解题目背景,肯定是你不知道未来的数据,通过预测得到的结果,也就是第三问的结果,然后在这基础上,依次取预测数据片段例如k+1:k+n的n数据分析看是买入还是卖出,买入的话是买多还是买空,同样依次取真实数据片段,如果预期会亏损那么会触发风控机制,会清空股票,当然也可以设定不同阈值,在不同阈值时的清空比例不一样,比如说到风险值0.5了,清空一部分,到风险值0.8了,清空全部,还有就是你把钱花去买了股票了,股票的价值可不是你的现金,卖了后到手里的钱才能用来再次做投资,关于回撤率再说一下,你在1日交易了一笔,在2日交易了一笔,这是分开的,如果1日买的一笔在遇到风险触发风控机制卖出的就算是回撤了,2日买的刚好达到卖出条件卖出了,那么此时的回撤率是50%,如果是触发你的卖出机制,那么就不算回撤,这个要理解。第四问可不是简单的预测买入卖出,肯定需要还原真实股票交易场景,风控、买入、卖出机制都需要构建模型,怎么风控,就取真实片段数据例如k+1:k+n的n数据去进行风险评估,最简单的就是计算方差,怎么买入,预测后面一段时间都是上涨,取预测片段数据如果上升的次数较多,那么可以买入,同样取预测片段数据,如果下降的次数多就卖,这是买多的情况,那么买空也是同样道理,一般股票操作软件中也会设置卖出线,比如说上涨15%自动平仓,下降15%自动平仓。
不建议大家把第四问想的太复杂,可以适当简化,第一个要注意的是风控和卖出是用的真实数据,买入是用的预测数据,第二要注意的是买多和买空要区分好。
【详细思路,C已更新】
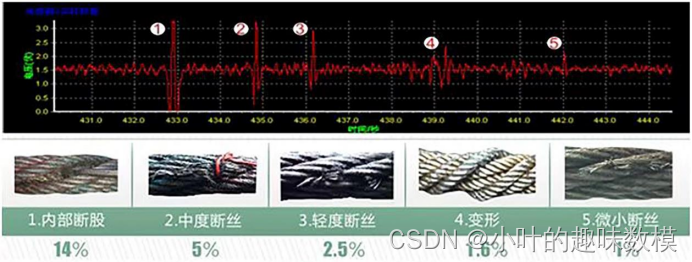
C题非常简单,数据不用多说了吧,数据有相应解释,但是要注意题目没有给你们将缺陷的数据是怎样的,需要你们建立模型后通过设置阈值判断,题目也说了五中波形情况
如果不会读取数据就用matlab导入功能
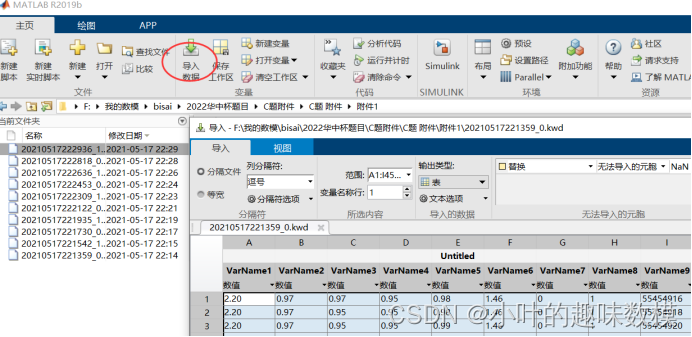
1)文件格式:
1号电压,2号电压,3号电压,4号电压,5号电压,6号电压,方向, 脉冲, 时间戳
1.61, 1.06, 0.97, 0.95, 0.98, 1.47, 1, 1, 102070423
2)电压值一共有六个,对应了六根钢丝绳的数据。一行数据就是一帧数据。第一列表示第一根绳子的电压值,第二列表示第二根绳子的电压值,…,第六列表示第六根绳子的电压值。
3)方向“0”代表下行,方向“1”表示上行。
4)脉冲:其实就是距离,通过距离传感器得到。从1到n递增,每一帧(一行数据代表一帧数据)对应一个脉冲数字,脉冲数每增加1,代表距离增加了0.4米。
可能有多帧数据对应一个脉冲(表示在0.4米内进行了多次测量)。在绘制波形图时,每一帧所对应的距离等于0.4米除以帧数。
5)时间戳主要用来给文件命名,避免重复。这个数据可以忽略。
6)钢丝绳长为960米,断丝的位置可以用帧表示。
7)每一个文件记录一次运行的监测数据,10个文件记录了10次往返运行的监测数据。注意上行和下行的监测数据不是从同一端记录。
第一问,既然题目说了存在噪音,那就小波降噪就可以了,然后进行异常检验,注意这里的异常检验不是说用个LOF算法将所有异常数据带进去检验,而是取片段根据时间戳依次遍历取片段数据来检验,取的数据长度自定,最简单异常检测可以就按题目说的片段数据中的电压值和平均值之差的绝对值与平均值的百分比,设定阈值识别相应的异常点位,注意一个电压对应的是一条钢丝,脉冲1对应的是0.4米。
小波降噪给个案例程序,自行修改
%%初始化程序
clear,clc
t1=clock;
%% 载入噪声信号数据,数据为.mat格式,并且和程序放置在同一个文件夹下
load('filename.mat');%matrix
YSJ= filename;
%% 数据预处理,数据可能是存储在矩阵或者是EXCEL中的二维数据,衔接为一维的,如果数据是一维数据,此步骤也不会影响数据
[c,l]=size(YSJ);
Y=[];
for i=1:c
Y=[Y,YSJ(i,:)];
end
[c1,l1]=size(Y);
X=[1:l1];
%% 绘制噪声信号图像
figure(1);
plot(X,Y);
xlabel('横坐标');
ylabel('纵坐标');
title('原始信号');
%% 硬阈值处理
lev=3;
xd=wden(Y,'heursure','h','one',lev,'db4');%硬阈值去噪处理后的信号序列
figure(2)
plot(X,xd)
xlabel('横坐标');
ylabel('纵坐标');
title('硬阈值去噪处理')
set(gcf,'Color',[1 1 1])
%% 软阈值处理
lev=3;
xs=wden(Y,'heursure','s','one',lev,'db4');%软阈值去噪处理后的信号序列
figure(3)
plot(X,xs)
xlabel('横坐标');
ylabel('纵坐标');
title('软阈值去噪处理')
set(gcf,'Color',[1 1 1])
%% 固定阈值后的去噪处理
lev=3;
xz=wden(Y,'sqtwolog','s','sln',lev,'db4');%固定阈值去噪处理后的信号序列
figure(4)
plot(X,xz);
xlabel('横坐标');
ylabel('纵坐标');
title('固定阈值后的去噪处理')
set(gcf,'Color',[1 1 1])
%% 计算信噪比SNR
Psig=sum(Y*Y')/l1;
Pnoi1=sum((Y-xd)*(Y-xd)')/l1;
Pnoi2=sum((Y-xs)*(Y-xs)')/l1;
Pnoi3=sum((Y-xz)*(Y-xz)')/l1;
SNR1=10*log10(Psig/Pnoi1);
SNR2=10*log10(Psig/Pnoi2);
SNR3=10*log10(Psig/Pnoi3);
%% 计算均方根误差RMSE
RMSE1=sqrt(Pnoi1);
RMSE2=sqrt(Pnoi2);
RMSE3=sqrt(Pnoi3);
%% 输出结果
disp('-------------三种阈值设定方式的降噪处理结果---------------');
disp(['硬阈值去噪处理的SNR=',num2str(SNR1),',RMSE=',num2str(RMSE1)]);
disp(['软阈值去噪处理的SNR=',num2str(SNR2),',RMSE=',num2str(RMSE2)]);
disp(['固定阈值后的去噪处理SNR=',num2str(SNR3),',RMSE=',num2str(RMSE3)]);
t2=clock;
tim=etime(t2,t1);
disp(['------------------运行耗时',num2str(tim),'秒-------------------'])
第二问,需要挖掘出一些指标,然后通过评价算法进行评价,得到的值是相对的,将其作为安全性能的高低,指标可以是信号异常次数、方差等,可以尽可能多挖掘一些指标出来。
【详细思路,A已更新】【第一二问程序已更新】
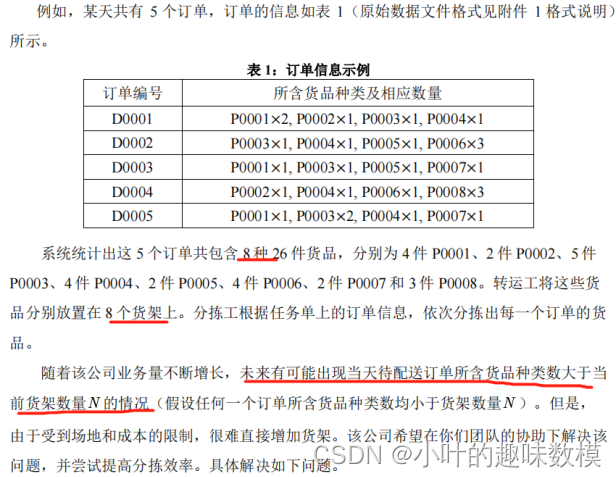
一订单包含多种货品,每种商品有不同的数量,题目没说订单的需求时间,那就考虑怎么最短时间内分拣完
题目介绍中我们可以得知,一个货架放一种货品
下面就是我们要解决的问题

其实大家只要先把背景理解了,就特别简单,我们直接来看第一问怎么编程
第一问将当日订单分为多个批次。要求每个批次的订单所含货品种类数均不超过N=200 ,且批次越少越好(相应转运次数也越少,效率越高)。就是说将附件1中的订单进行打包,这里不是聚类哈,别乱搞,反正一个批次就放200多种货品,这里没讲一个货架能放多少数量,那我们也就无所谓了,我们程序怎么编,首先923个订单,是我,我就直接用randperm函数来一个随机序列再说,然后每个通过返回索引,依次遍历用矩阵保存并通过unique函数去重,直到货品种类不超过200为止作为第一个批次,后面类推,当然,肯定是用优化算法解决,这里就是说我们的每个个体都是randperm函数生成的随机序列,然后目标函数则是通过依次打包订单后的批次次数,直接来程序吧
这是完整第一问程序,用的是遗传算法,种群大小和迭代次数等相关参数自己修改,想用其他算法的可以自己改框架
clear
clc
%% 第一问最优批次
%第一问最终结果在PC矩阵中
%数据准备
[~,~,X]=xlsread('附件1:订单信息.csv');
X=string(X);
X(1,:)=[];
Y=unique(X(:,1));
n=length(Y);
Z=[];
V=[];
for i=1:size(Y)
z=X(find(X(:,1)==Y(i)),2);
Z{i,1}=z;%记录每个订单下的货品数
V(i,1)=sum(double(X(find(X(:,1)==Y(i)),3)));
end
%生成初始个体
N=200;%货架数
num=10;%种群大小
num_gen=10;%最大迭代次数
q1=0.7;%交叉率
q2=0.7;%变异率
chrom=[];
f=[];
for i=1:num
chrom(i,:)=randperm(n);
%计算目标函数
%U=[];
UU=[];
u=1;
for j=1:n
UU=[UU;Z{chrom(i,j),1}];
UU=unique(UU);
if length(UU)<=N %如果小于200,那么就直接记录
%U{u,1}=UU;
else%如果大于,那么记录于下一批次
u=u+1;
UU=[];
UU=[UU;Z{chrom(i,j),1}];
%U{u,1}=UU;
end
end
f(i,1)=u;%记录最大批次,目标函数
end
trace(1)=min(f);
%迭代
for k_gen=1:num_gen
selchrom=chrom;%选择,寻优维度较高,这里就全部进行交叉遗传
selchrom=jiaocha(selchrom,q1,k_gen,num_gen);
selchrom=bianyi(selchrom,q2,k_gen,num_gen);
ff=[];
for i=1:num
%计算目标函数
%U=[];
UU=[];
u=1;
for j=1:n
UU=[UU;Z{selchrom(i,j),1}];
UU=unique(UU);
if length(UU)<=N%如果小于200,那么就直接记录
%U{u,1}=UU;
else%如果大于,那么记录于下一批次
u=u+1;
UU=[];
UU=[UU;Z{selchrom(i,j),1}];
%U{u,1}=UU;
end
end
ff(i,1)=u;%记录最大批次,目标函数
end
%两代合并排序
f=[f;ff];
chrom=[chrom;selchrom];
[f,b]=sort(f);
chrom=chrom(b,:);
f=f(1:num,:);
chrom=chrom(1:num,:);
trace=[trace;min(f)];
end
%迭代图
figure
plot(trace)
xlabel('迭代次数')
ylabel('批次');
%记录最优
[bestf,b]=min(f);
bestchrom=chrom(b,:);
%计算最优方案下每个批次的货品数和货物数
F=[];%第一列是每个批次货品数,第二列是货物数
U=[];%记录每批次具体货品种类
UU=[];
YY=[];
YYY=[];
u=1;
f1=0;
f2=0;
for j=1:n
UU=[UU;Z{bestchrom(j),1}];
YY=[YY;Y(bestchrom(j),1)];
UU=unique(UU);
if length(UU)<=N%如果小于200,那么就直接记录
U{u,1}=UU;
YYY{u,1}=YY;
f1=length(UU);
f2=f2+V(bestchrom(j),1);
F(u,:)=[f1,f2];
else%如果大于,那么记录于下一批次
u=u+1;
f1=0;
f2=0;
UU=[];
YY=[];
UU=[UU;Z{bestchrom(j),1}];
YY=[YY;Y(bestchrom(j),1)];
U{u,1}=UU;
YYY{u,1}=YY;
f1=length(UU);
f2=f2+V(bestchrom(j),1);
F(u,:)=[f1,f2];
end
end
PC=[];%订单对应批次
for i=1:length(YYY)
PC=[PC;YYY{i,1},repmat(string(i),length(YYY{i,1}),1)];
end
function x=jiaocha(x,a,k_gen,num_gen)
%交叉率变化
a = a*exp(-k_gen/num_gen);
for i = 1:size(x,1)
if rand < a
%选择交叉位点
b = randi(size(x,2))-1;
x(i,:)=[x(i,b+1:end),x(i,1:b)];
end
end
function x=bianyi(x,a,k_gen,num_gen)
%变异率变化
a = a*exp(-k_gen/num_gen);
for i = 1:size(x,1)
if rand < a
%选择变异位点
b1 = randi(size(x,2));
b2 = randi(size(x,2));
%产生变异(针对序列问题,产生两个变异点进行两两交换)
c = x(i,b1);
x(i,b1)=x(i,b2);
x(i,b2)=c;
end
end
第一问结果矩阵说一下最优结果,上面程序运行完后,工作区中bestx矩阵为最优排序,bestf为最少批次,最少批次是九十多次,自己可以算下
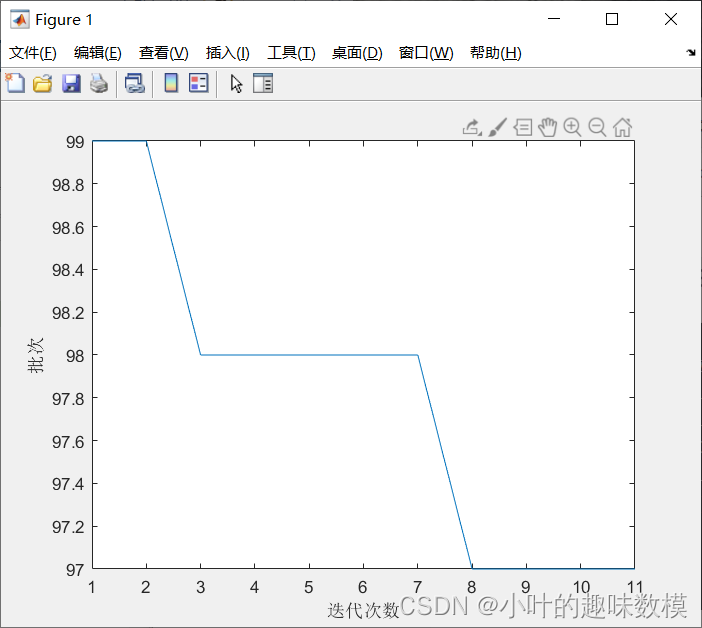
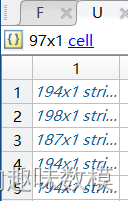
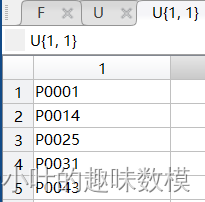
F矩阵是每个批次的种类数和货物总数,U矩阵是每个批次的具体种类

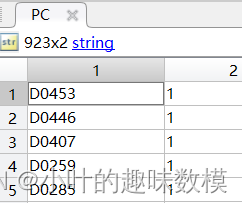
第一问最终结果在PC矩阵中
第二问,在第一问结果基础上,考虑货架编号,第二问程序思路为:遍历每个批次通过模拟退火算法分别寻找最优位置分布,每个颗粒对应一组随机生成位置编号,然后遍历批次中的订单,通过ismember函数匹配并抽取出其货品对应的位置,按题目距离公式计算,目标函数为总距离最小化对位置分布进行寻优,每个批次的位置寻优是单独的
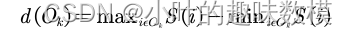
这是完整第一二问程序,用的是遗传算法+模拟退火算法,种群大小和迭代次数、颗粒数和温度等相关参数自己修改,想用其他算法的可以自己改框架
clear
clc
%% 第一问最优批次
%第一问最终结果在PC矩阵中
%数据准备
[~,~,X]=xlsread('附件1:订单信息.csv');
X=string(X);
X(1,:)=[];
Y=unique(X(:,1));
n=length(Y);
Z=[];
V=[];
for i=1:size(Y)
z=X(find(X(:,1)==Y(i)),2);
Z{i,1}=z;%记录每个订单下的货品数
V(i,1)=sum(double(X(find(X(:,1)==Y(i)),3)));
end
%生成初始个体
N=200;%货架数
num=10;%种群大小
num_gen=10;%最大迭代次数
q1=0.7;%交叉率
q2=0.7;%变异率
chrom=[];
f=[];
for i=1:num
chrom(i,:)=randperm(n);
%计算目标函数
%U=[];
UU=[];
u=1;
for j=1:n
UU=[UU;Z{chrom(i,j),1}];
UU=unique(UU);
if length(UU)<=N %如果小于200,那么就直接记录
%U{u,1}=UU;
else%如果大于,那么记录于下一批次
u=u+1;
UU=[];
UU=[UU;Z{chrom(i,j),1}];
%U{u,1}=UU;
end
end
f(i,1)=u;%记录最大批次,目标函数
end
trace(1)=min(f);
%迭代
for k_gen=1:num_gen
selchrom=chrom;%选择,寻优维度较高,这里就全部进行交叉遗传
selchrom=jiaocha(selchrom,q1,k_gen,num_gen);
selchrom=bianyi(selchrom,q2,k_gen,num_gen);
ff=[];
for i=1:num
%计算目标函数
%U=[];
UU=[];
u=1;
for j=1:n
UU=[UU;Z{selchrom(i,j),1}];
UU=unique(UU);
if length(UU)<=N%如果小于200,那么就直接记录
%U{u,1}=UU;
else%如果大于,那么记录于下一批次
u=u+1;
UU=[];
UU=[UU;Z{selchrom(i,j),1}];
%U{u,1}=UU;
end
end
ff(i,1)=u;%记录最大批次,目标函数
end
%两代合并排序
f=[f;ff];
chrom=[chrom;selchrom];
[f,b]=sort(f);
chrom=chrom(b,:);
f=f(1:num,:);
chrom=chrom(1:num,:);
trace=[trace;min(f)];
end
%迭代图
figure
plot(trace)
xlabel('迭代次数')
ylabel('批次');
%记录最优
[bestf,b]=min(f);
bestchrom=chrom(b,:);
%计算最优方案下每个批次的货品数和货物数
F=[];%第一列是每个批次货品数,第二列是货物数
U=[];%记录每批次具体货品种类
UU=[];
YY=[];
YYY=[];
u=1;
f1=0;
f2=0;
for j=1:n
UU=[UU;Z{bestchrom(j),1}];
YY=[YY;Y(bestchrom(j),1)];
UU=unique(UU);
if length(UU)<=N%如果小于200,那么就直接记录
U{u,1}=UU;
YYY{u,1}=YY;
f1=length(UU);
f2=f2+V(bestchrom(j),1);
F(u,:)=[f1,f2];
else%如果大于,那么记录于下一批次
u=u+1;
f1=0;
f2=0;
UU=[];
YY=[];
UU=[UU;Z{bestchrom(j),1}];
YY=[YY;Y(bestchrom(j),1)];
U{u,1}=UU;
YYY{u,1}=YY;
f1=length(UU);
f2=f2+V(bestchrom(j),1);
F(u,:)=[f1,f2];
end
end
PC=[];%订单对应批次
for i=1:length(YYY)
PC=[PC;YYY{i,1},repmat(string(i),length(YYY{i,1}),1)];
end
%% 第二问就是在第一问结果基础上寻优不同种类货品摆放位置,一个批次的种类有200个货架可以摆放
%第二问遍历每个批次通过模拟退火算法分别寻找最优位置分布
%程序逻辑是随机生成位置编号,然后遍历批次中的订单,通过ismember函数匹配并抽取出其货品对应的位置,按题目距离公式计算
%每个批次的位置寻优是单独的,最后结果保存在P矩阵中,与每个批次的货品种类U矩阵对应
%最终的记过在PP矩阵里
T=100; %初始化温度值
T_min=1; %设置温度下界
alpha=0.99; %温度的下降率
num=10; %颗粒总数
P=[];
for i=1:length(U)
a=find(PC(:,2)==string(i));%依次遍历每个批次
XX=[];%记录订单及货品种类,后续调用
for j=1:length(a)
XX{j,1}=PC(j,1);
XX{j,2}=X(find(X(:,1)==PC(a(j),1)),2);
end
%初始颗粒分布
x=[];
y=[];
for j=1:num
y1=0;
x{j,1}=randperm(N);
x{j,1}=x{j,1}(1:length(U{i,1}));
for k=1:size(XX,1)
%ismember函数可批量匹配自字符串
b=find(ismember(U{i,1},XX{k,2})==1);
c=x{j,1}(b);
y1=y1+max(c)-min(c);%距离
end
y(j,1)=y1;
end
[besty,b]=min(y);
bestx=x{b,1};
%以最小化
while(T>T_min)
xx=[];
yy=[];
for j=1:num
y1=0;
xx{j,1}=randperm(N);
xx{j,1}=x{j,1}(1:length(U{i,1}));
for k=1:size(XX,1)
%ismember函数可批量匹配自字符串
b=find(ismember(U{i,1},XX{k,2})==1);
c=xx{j,1}(b);
y1=y1+max(c)-min(c);%距离
end
yy(j,1)=y1;
%是否更新最优
delta=yy(j,1)-y(j,1);
if delta<0
y(j,1)=yy(j,1);
x(j,:)=xx(j,:);
else
p=exp(-delta/T);
if p>rand
y(j,1)=yy(j,1);
x(j,:)=xx(j,:);
end
end
end
if min(y)<besty
[besty,b]=min(y);
bestx=x{b,1};
end
T=T*alpha;
end
P{i,1}=bestx;
end
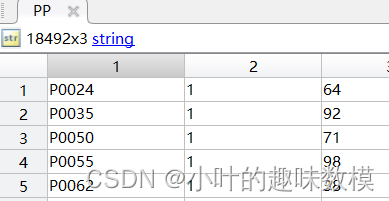
PP=[];
for i=1:length(P)
PP=[PP;U{i,1},repmat(string(i),length(U{i,1}),1),string(P{i,1}')];
end
第二问结果,最后结果保存在P矩阵中,与每个批次的货品种类U矩阵对应,最终结果见PP矩阵
第三问,在第二问结果基础上,又考虑多个技术工,第三问编程稍微复杂些,入手的话一个一个规则写进去,注意别弄错了。
三个问都是单目标寻优,别想的太复杂
版权归原作者 小叶的趣味数模 所有, 如有侵权,请联系我们删除。