
一、相关背景介绍

在 2023 年,人工智能技术得到了广泛的应用和发展,不仅在互联网行业,还在医疗、金融、教育等领域都有了重大突破。在互联网行业,
AI
技术被广泛应用于搜索引擎优化、推荐系统、智能客服等方面,为用户提供更加个性化、智能化的服务。在医疗领域,
AI
技术被用于辅助医生诊断、药物研发等方面,大大提高了医疗效率和质量。在金融领域,
AI
技术被应用于风险控制、客户画像等方面,为金融机构提供更加精准的服务。在教育领域,
AI
技术被用于个性化教学、智能教育管理等方面,为学生提供更加有效的学习方式。
另外,2023年还涌现了许多新型的
AI
应用,比如基于大模型的语音助手、智能家居控制系统、智能交通管理系统等,这些应用在各个领域都得到了广泛的应用和认可。可以说,2023年是人工智能技术蓬勃发展的一年,为各行各业带来了巨大的变革和创新。相信在未来,人工智能技术将继续发挥重要作用,为社会带来更多的便利和进步。
但是同时,数据分析应用在互联网商用领域、医疗、政府和公共服务等众多领域都有不可替代的地位。通过对海量数据的深入挖掘和分析,企业可以更好地理解市场趋势、客户需求和竞争对手的动态。数据分析可以帮助企业进行精准的市场定位,优化产品和服务,提高客户满意度和忠诚度。此外,数据分析还可以为企业提供预测和规划的依据,帮助企业更好地把握市场机会和风险。通过数据分析,企业可以实现运营流程的优化和成本的降低,提高效率和经营效益。总之,数据分析不仅可以帮助企业做出明智的决策,还可以为企业创造更多商机和竞争优势,因此在当今市场中具有不可忽视的重要性。
而今天我要介绍的就是在 11月21日九章云极 DataCanvas 刚刚发布的新星产品——
TableAgent
;它是一个在
DataCanvas Alaya
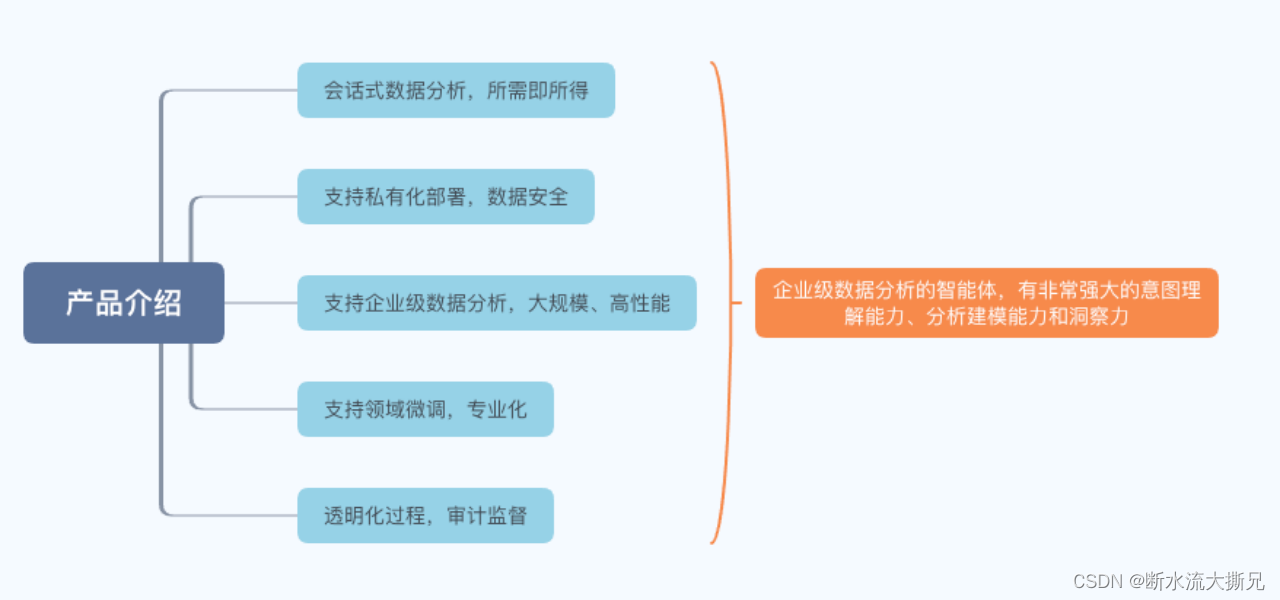
九章元识大模型基础上开发的 能够实现私有化部署的企业级数据分析的智能体,有非常强大的意图理解能力、分析建模能力和洞察力。
TableAgent
在充分的理解用户意图后,自主的利用统计科学、机器学习、因果推断等高级建模技术从数据中挖掘价值,进而提供分析观点和指导行动的深刻见解。
二、产品介绍及体验
首先值得一说的是,参加这次活动主要是在11月21号下午摸鱼的时候看到了九章云极
DataCanvas大模型
系列成果的发布会,从杨总那里得知刚刚上线了一个他们的新产品,
TableAgent
,并且这是一个大模型和数据分析的结合体;很早之前,接触
Canvas
大数据类型的产品还是在2021年底体验的
SageMaker Canvas
这个产品,但是两者在交互上有着天壤之别,一个是传统的点点,框框,然后生成想要的
Canvas
数据展现。然而
TableAgent
的交互方式却很特别,属于类似即时聊天这种方式,交互更加便捷,使用方式门槛更低。
好了,话不多说,我们来体验一下这个产品。我们来个手把手带你沉浸式体验
TableAgent
。
 - TableAgent公测地址
- TableAgent公测地址
https://tableagent.DataCanvas.com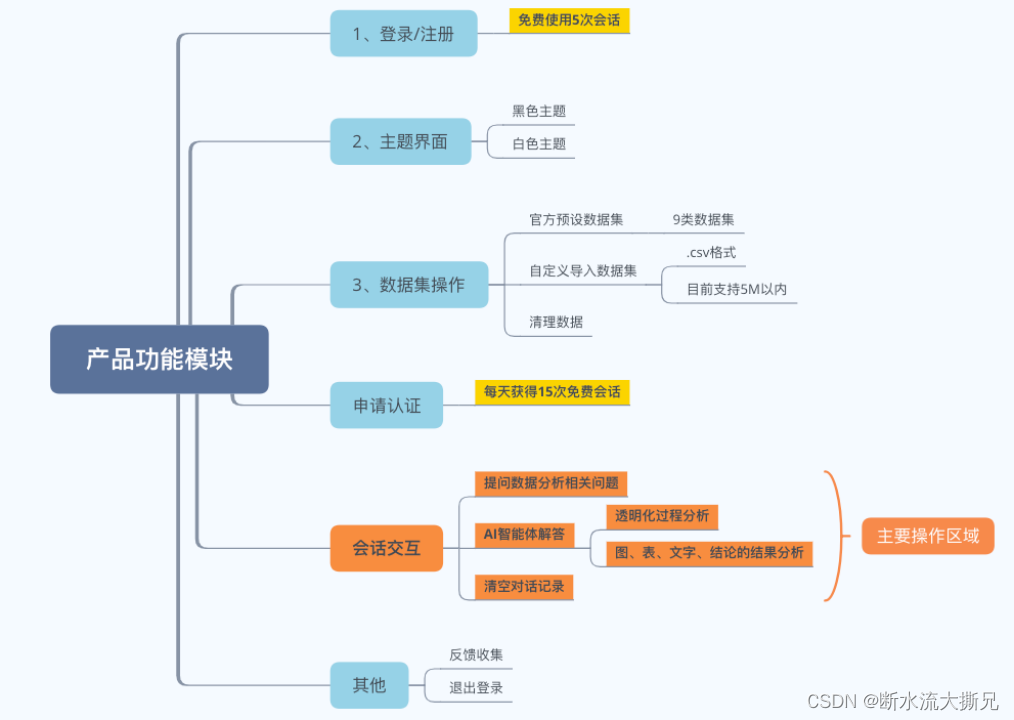
打开公测地址后,首先映入眼帘的是一个非常简介风的页面。主页部分没有太多常规网站那样对产品的一顿海吹,我们直接点击立即体验即可;下面黑色部分则是公众号和核心产品以及九章云极 DataCanvas 的开源项目贡献(可以看到都是目前比较火的技术)

登录完成后,会有一个过渡页面,应该是初始化模型和模型部署启动的一个过程。

加载完毕后,我们进入了操作主页面(默认是白色主题的,可以选择切换黑色主题)其他操作点也一目了然。整体的功能模块分布可以看下面的图能非常清晰的感知。(如图所示)
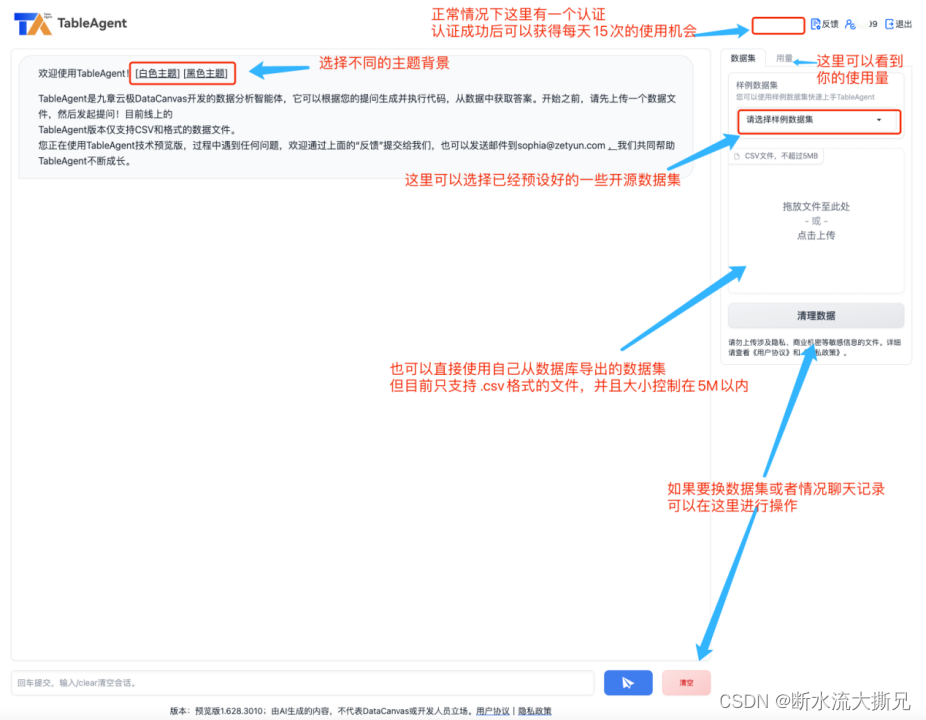
由于个人喜欢黑色,所以我打算换成黑色主题,然后选择一个开源的数据集后,与AI进行交互体验;顺便把所有功能都进行体验体验,最后我们再来进行总结。
(一)使用预设数据集进行体验
首先我们换成黑色的主题,然后选择预设的数据集,目前预设的数据集总共有9类,我们选择
“Airbnb民宿价格&评价”
数据集。
接下来,我们使用自然语言与
AI智能体
进行交流,看看我们提出的数据分析的问题是否能够非常效率的得到解答。
我们加载了
“Airbnb民宿价格&评价”
数据集后,
AI
会自动回复,我们可能关心的问题,展开详情后是该数据集的字段及对应的部分数据示例(如下图)。
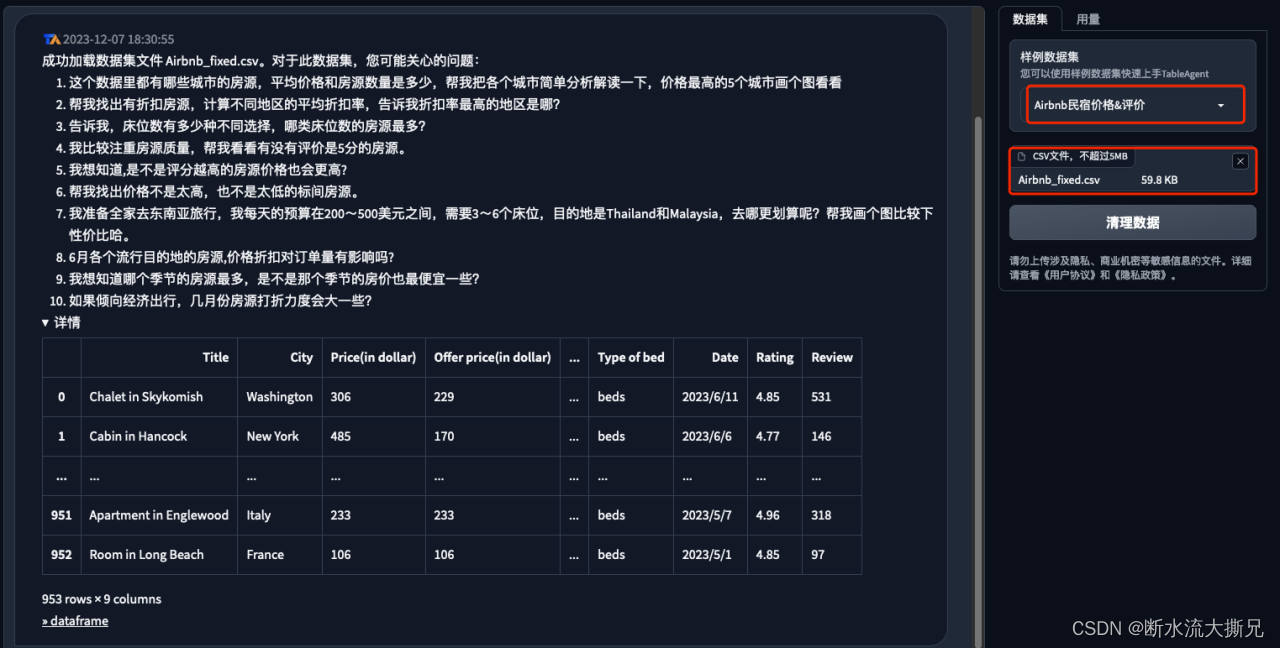
虽然我们通过AI的自动回复基本可以了解数据集的基本情况了,我们试试,他是否能够进一步的为我们解释数据集概况。
【提问1】帮我描述一下这个数据集的内容、字段以及数量,我想了解一下这个数据集
【AI回答1】
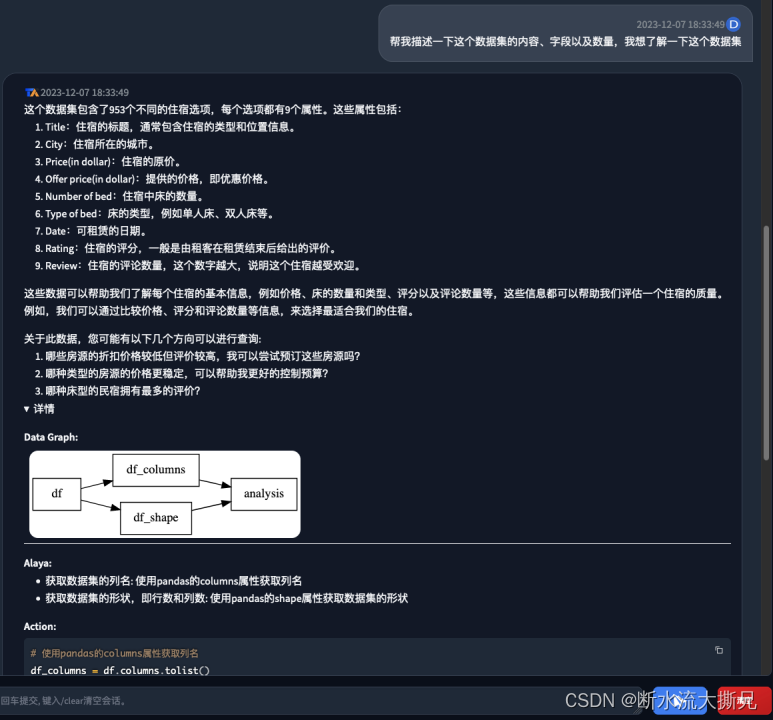
可以看到,它告诉了我们数据的总量,以及数据的9个字段,并且分别做了中文解释,同时告诉我们可以关心哪些数据分析的问题,最后也给出了几条可以查询的建议。接下来我们继续提问一个统计分析。
【提问2】帮我统计一下住宿评分最高和最低的它们价格的平均值是多少?
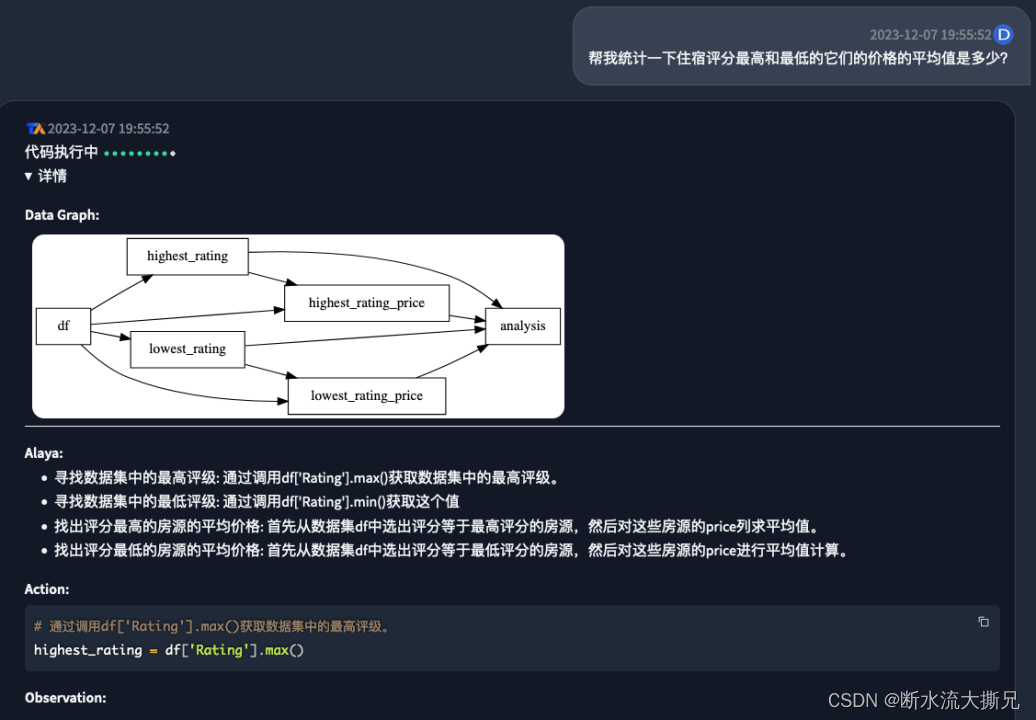
我们可以看到AI的整个执行过程和它的分析思路都展现在我们的面前,它分别通过调用两个函数
df['Rating'].max()
和
df['Rating'].min()
先得到评分最高的住宿房源以及最低的住宿房源是5.0和3.67。(通过上面字段介绍我们知道,
Rating
是住宿评分的字段)
# 获取评分最高的住宿评分值
# 通过调用df['Rating'].max()获取数据集中的最高评级。
highest_rating = df['Rating'].max()
# Observation 5.0
# 获取评分最低的住宿评分值
# 通过调用df['Rating'].min()获取这个值
lowest_rating = df['Rating'].min()
# Observation 3.67
然后再根据
df[df['Rating'] == highest_rating]['Price(in dollar)'].mean()
和
df[df['Rating'] == lowest_rating]['Price(in dollar)'].mean()
获得我们想要的答案。
# 首先从数据集df中选出评分等于最高评分的房源,然后对这些房源的price列求平均值。
highest_rating_price = df[df['Rating']== highest_rating]['Price(in dollar)'].mean()
# Observation 209.7608695652174
# 首先从数据集df中选出评分等于最低评分的房源,然后对这些房源的price进行平均值计算。
lowest_rating_price = df[df['Rating']== lowest_rating]['Price(in dollar)'].mean()
# Observation 80.0
最高评分的房源平均价格是
209.76$
,最低的评分的房源平均价格是
80.00$
,由此我们基本可以得知,房源的价格与服务质量、舒适度、顾客的感受是有直接的关系的,这也导致了最终的评分差异。
【AI回答2】
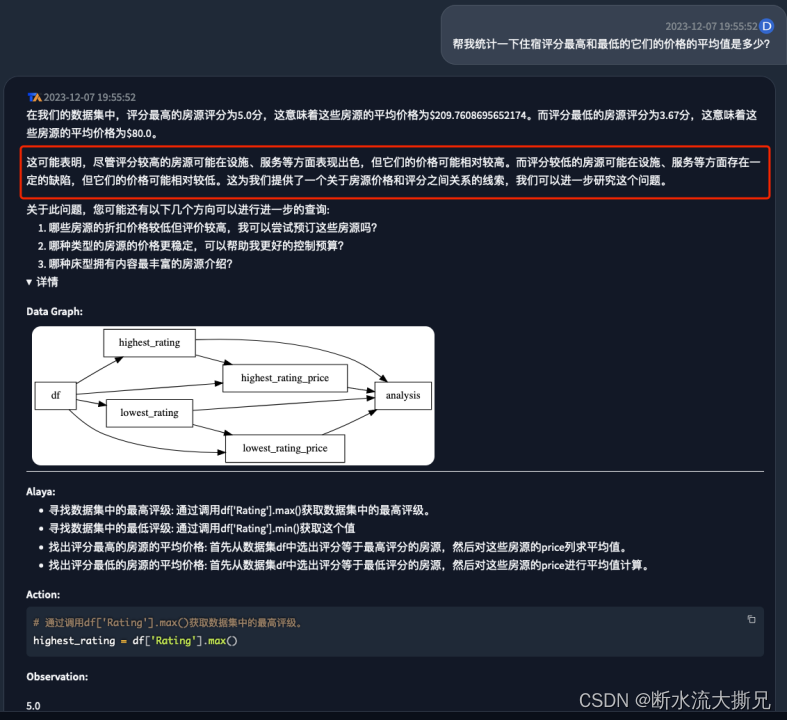
从完整的回答截图中,我们可以看到,其实AI也根据这一结果分析了房源评价与价格的一个可能关系;接下来我们继续深挖一下住宿价格与评分的相关性的分析。
【提问3】帮我分析一下2023年度所有住宿的价格与评分之间的关系,并分析价格对住宿评分的影响。
【AI回答3】
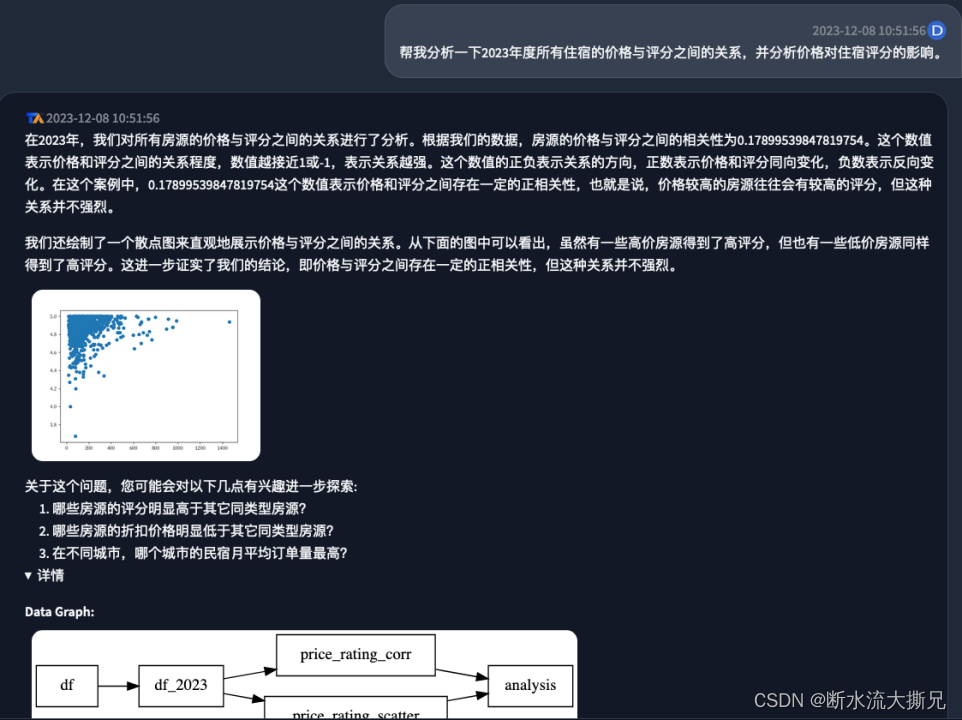
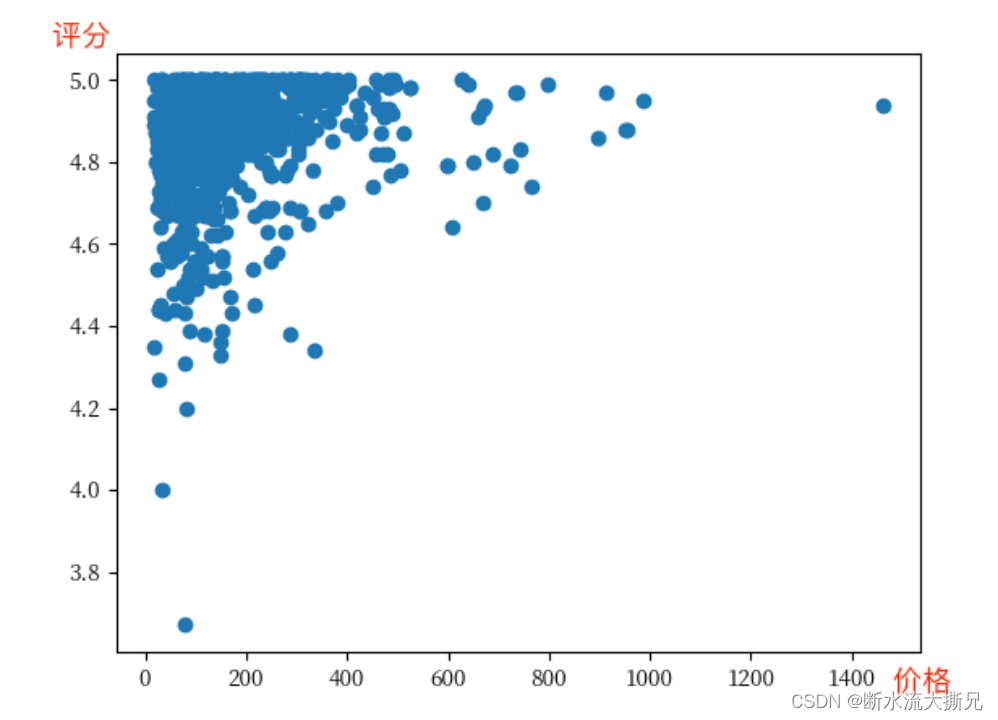
从回答中我们可以看到,
AI
首先是对相关性的指数进行了科普,然后告诉了我们最终结论:有一定相关性,但并不强烈。同时为了让我们有一个更加直观的感受,还绘制了一个散点图进行展现从散点图中我们可以看到评分主要还是汇集在
50-400$
的区间内的,其他的价格区间也有零零散散的一些评分而且这些费用在
400$
以上的评分也基本上在
4.6
,但是由于
50-400$
区间的评分基数非常大,并且也存在很多高分评价,所以价格和评分的关系并没有那么明显。
最后我们再问一个预测分析相关的问题。
【提问4】基于住宿属性,比如价格、床的数量和评分,建立一个预测模型来预测住宿的评论数量。
【AI回答4】
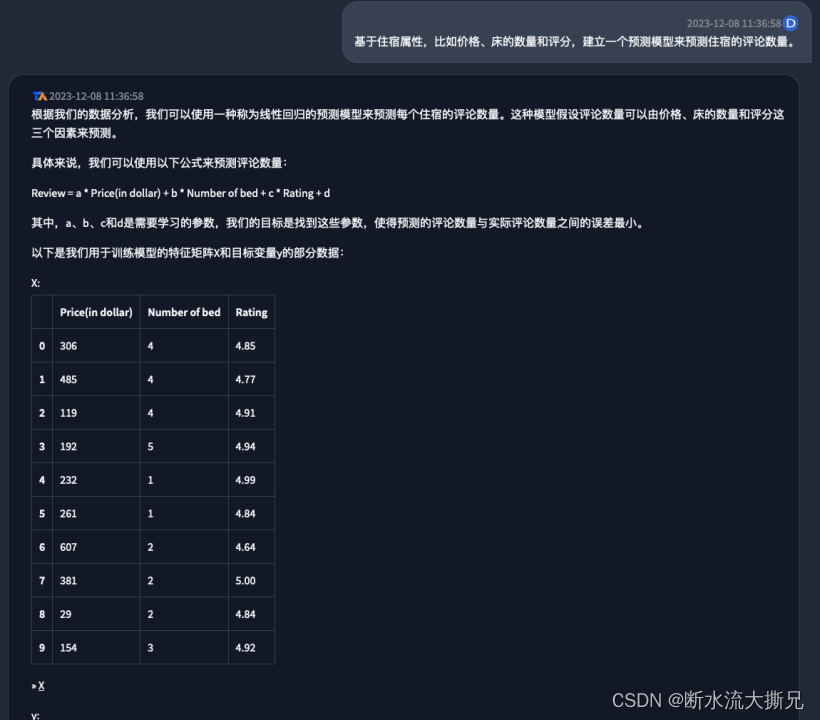
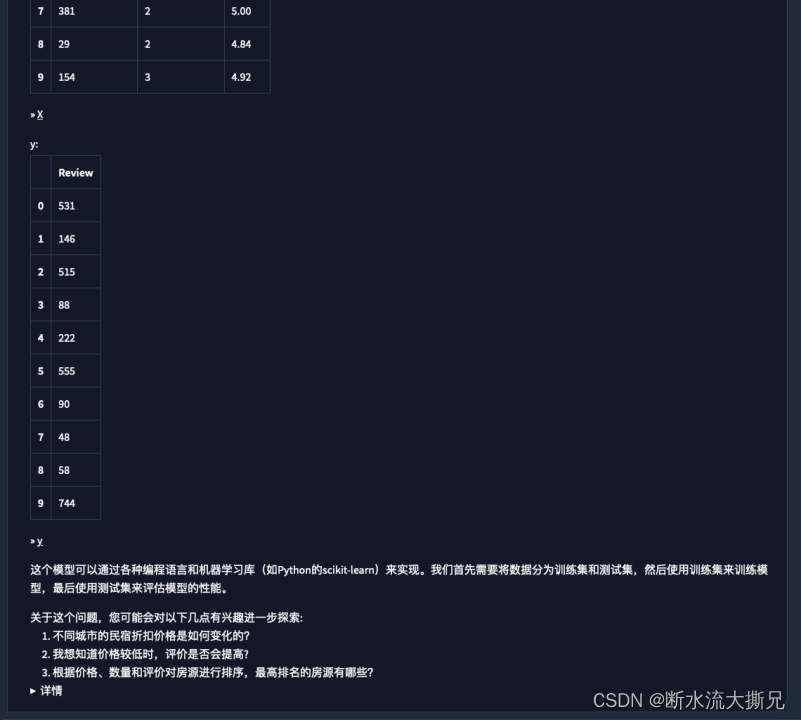
经过三次的尝试
AI
终于给出了最终的预测结果,根据下面的公式以及四个需要学习的参数得出了我们最终询问的结果,根据价格、床的数量和评分预测出了评论数量的结果。并且在最后内容块里告诉我们是通过哪个库来实现这个预测分析的。

好了,预设的模型我们先体验到这里,通过上面一系列的操作,由浅入深,我们基本上可以感受到
TableAgent
在产品介绍中的部分特性实质性的体现。
(二)导入B站《王者荣耀》相关高播放量视频数据集进行体验

1、数据介绍
这是一份来自于 阿里云天池 的b站《王者荣耀》相关视频,播放量最高的 1000 个视频数据 数据集,大小
432.60KB
。
共包含9个字段:
标题 、视频地址、图片 视频时长 关键词 播放量 发布时间 up主链接 up主
标题视频地址图片视频时长关键词播放量发布时间up主链接up主
这里解释一下,由于这个数据集的时间格式不太规范,导致比较中报的发布时间在下面的示例中无法使用。
拖入文件加载完毕后,可以看到AI已经识别并将数据的结构和部分数据已经反馈出来了。

接下来我们进行第一个预测需求提问.
【提问1】视频时长对播放量是否有影响,长视频和短视频在播放量上有何不同表现?
【AI回答1】
经过三次尝试,AI成功完成分析结果。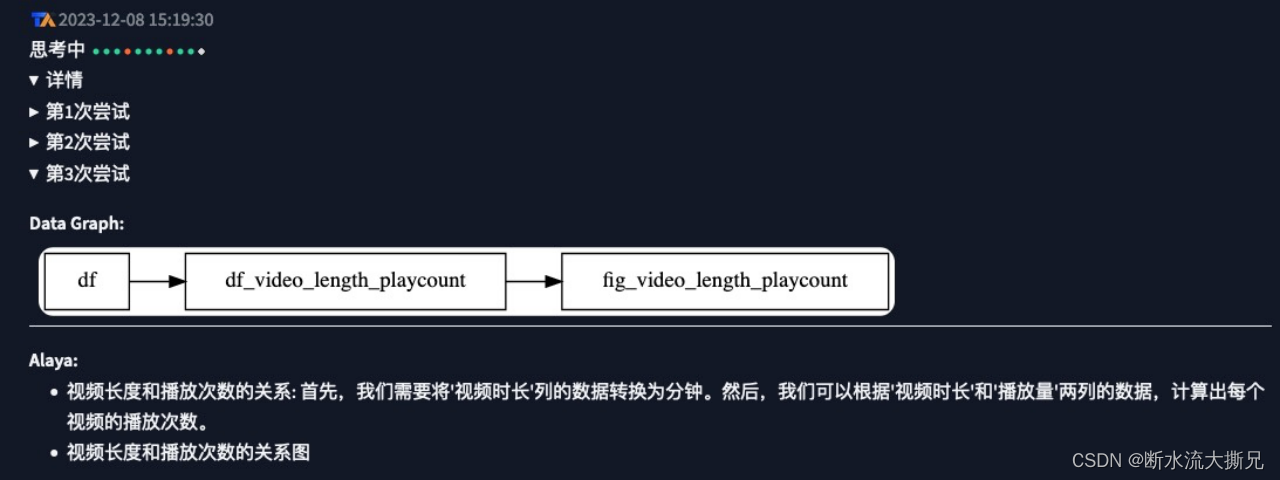

从回答中我们可以得知,视频的长短与播放量有一定关系,但这种关系并不强烈。长短视频的播放量表现也只是长视频略高于短视频。OK,那我们进一步深挖!
【提问2】分析不同视频的播放量变化趋势,了解哪些视频受欢迎,哪些视频的播放量呈现下降趋势,最后以图表呈现。
【AI回答2】
最受欢迎的视频排名
播放量下降的视频排名

这里非常清晰的列举出了数据,并且最后以表的方式呈现了一个视频和播放量的对比图。
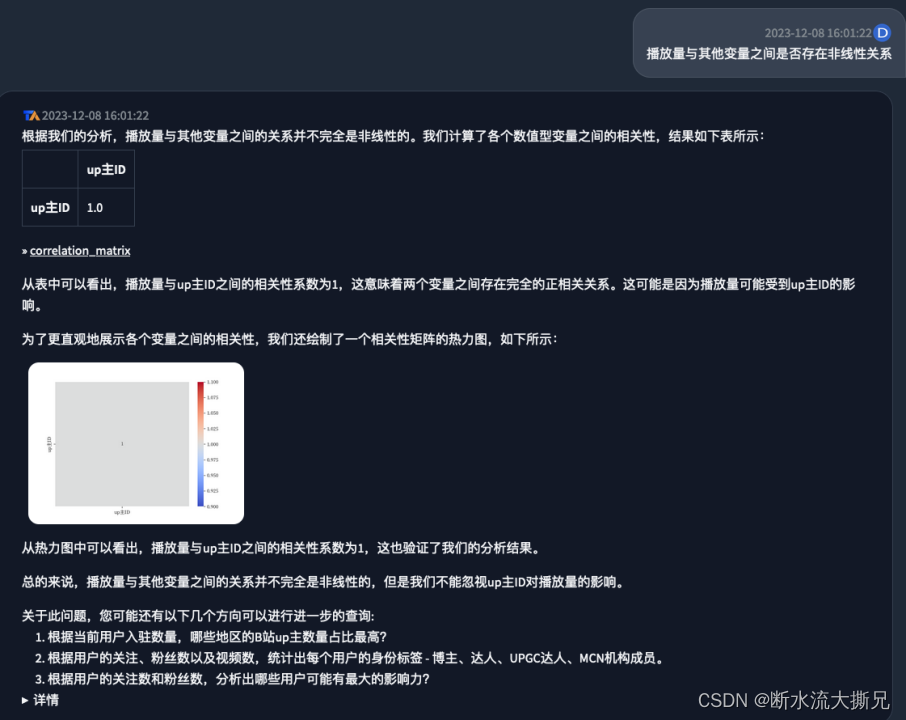
【提问3】播放量与其他变量之间是否存在非线性关系。
【AI回答3】

最终的回答是,
UP主ID
与
播放量
存在完全的正想关系,这也非常符合现实情况,一些知名的、粉丝量高的
UP主
,肯定对视频的播放量起着至关重要的作用。
(三)体验后的小结
好了,通过分别的2个数据集(自带数据集,导入的自定义数据集)
TableAgent
都能够很好,并且非常快捷的完成各方面的数据分析相关的工作;而且在交互过程中我们发现,在数据分析相关的自然语言需求中,它也能够非常好的理解你的语言意图,比如在上述的提问2中,我既要受欢迎的视频数据,也要呈现下降趋势的视频数据,并且最后还要求它以图表的方式呈现出来,结果大家也看到了,它都做到了;再一个就是大家伙可能都发现了,那就是数据分析的使用门槛降到了极地的程度,真的可以说是在推文中提到的人人都是数据分析师。
三、综合各方面的对比
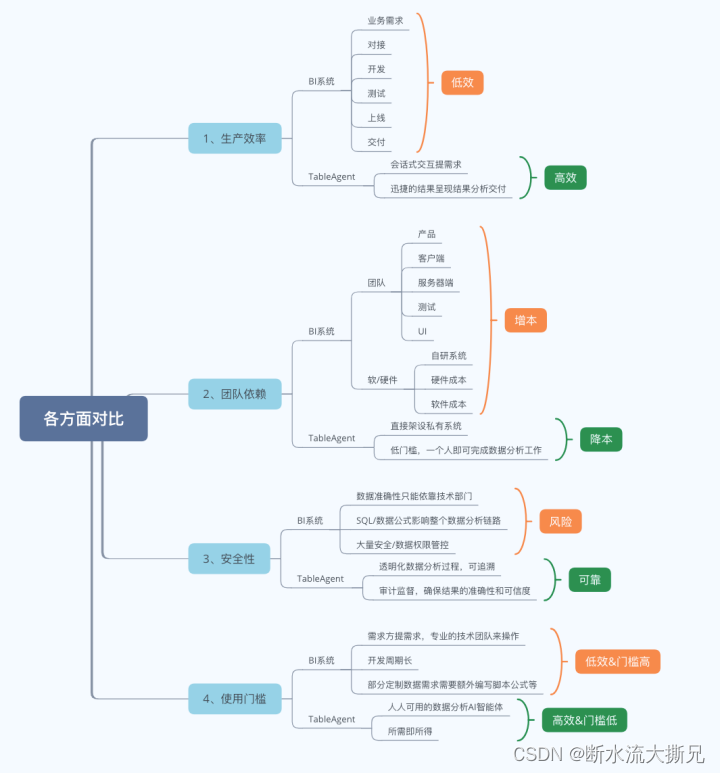
(一)纵向对比——与目前互联网传统数据方式对比
作为互联网人,大多数公司其实目前主流的数据分析方式,还是依赖于
BI系统
和
BI团队
的方式来做各种业务所需的数据分析需求。然而让我们看看,我在做完体验之后的一个直观感受对比,主要对比目前大多数互联网企业目前做分析的方式,可以一目了然的发现TableAgent 智能体的独特优势。总之对比总结如下图所示,灰常的清晰!
(二)横向对比——与其他数据分析产品对比
产品间的比较,我就拿去年我在AWS体验的数据分析产品来说——
Amazon SageMaker Canvas
来对比分析分析。
首先
Amazon SageMaker Canvas
是一个
AWS
一直在强推的一个集机器学习、算法/模型、低代码融合一身的数据分析云产品;当初体验这个产品我可是写了两篇的教学性的技术博文,为什么是两篇,一篇是《【无门槛】机器学习——Amazon SageMaker Canvas 【实验配置篇】》,另一篇是《【无门槛】机器学习——Amazon SageMaker Canvas 【供应链准时交付(场景)】》这个相当于某个数据集的应用了,具体的实验过程我不再在本篇文章里赘述了。
其实肯定有小伙伴问为什么是写两篇,其实就是因为准备工作(配置),与使用流程(操作)都具有一定的复杂性,并不是开箱即用,包括国外产品的后付费方式,也让国内大多数开发者都不太习惯(创建后,不关闭会继续扣费)。

首先就使用流程上来说,Amazon SageMaker Canvas的步骤大概如下:
1、创建
Amazon SageMaker Canvas
环境
- 设置
SageMaker域 Create a new role(创建新角色)
2、启动应用(
Launch app
)
3、添加
IAM
信任策略
- 这里是一系列的权限与策略配置
4、创建
S3
并设置
S3
存储桶
CORS
跨域策略
- 这里也是一步步的设置跨域策略的配置步骤
5、将数据集上次到S3存储桶(
Amazon SageMaker Canvas
仅支持访问S3上的数据集)
6、在
Amazon SageMaker Canvas
中导入数据集
7、开始构建与模型训练(
Quick build
)
8、分析自定义预测结果
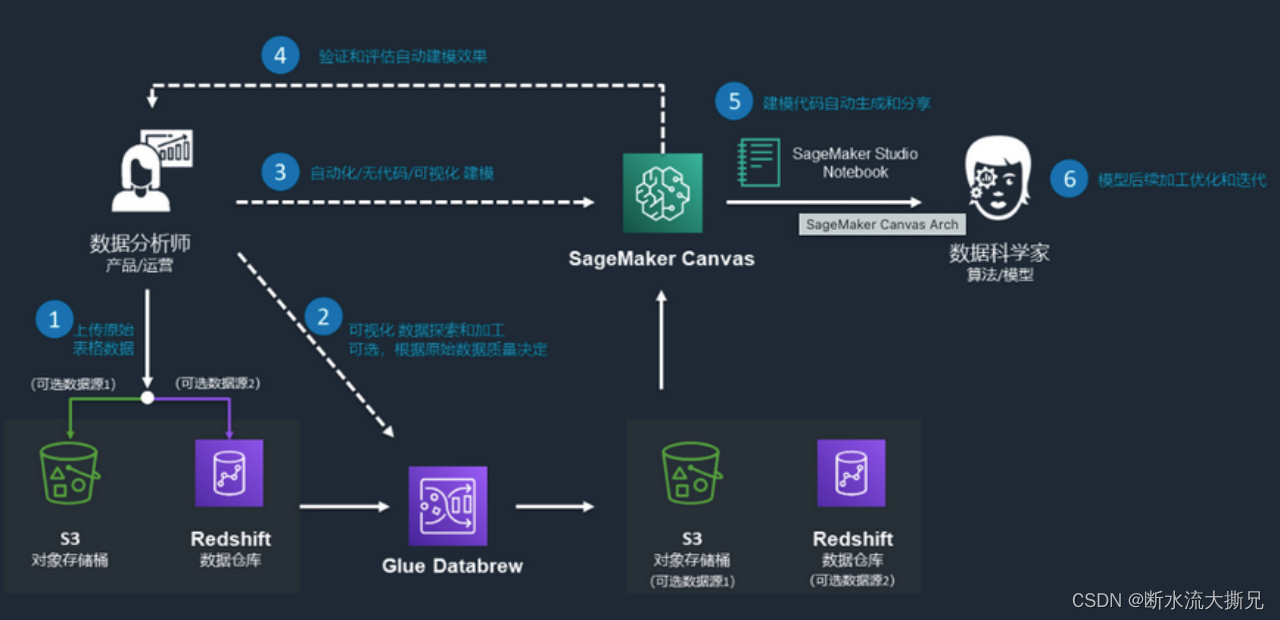
虽然用也非常好用,但是整体下来的感觉就是比较繁琐,各种配置,各种关联产品的配置与权限、策略的设置。
其次我们来看看TableAgent 的使用步骤大概如下:
1、选择或上传自定义数据集
2、提问相关数据分析诉求
3、呈现预测结果
直观来看就是这样的。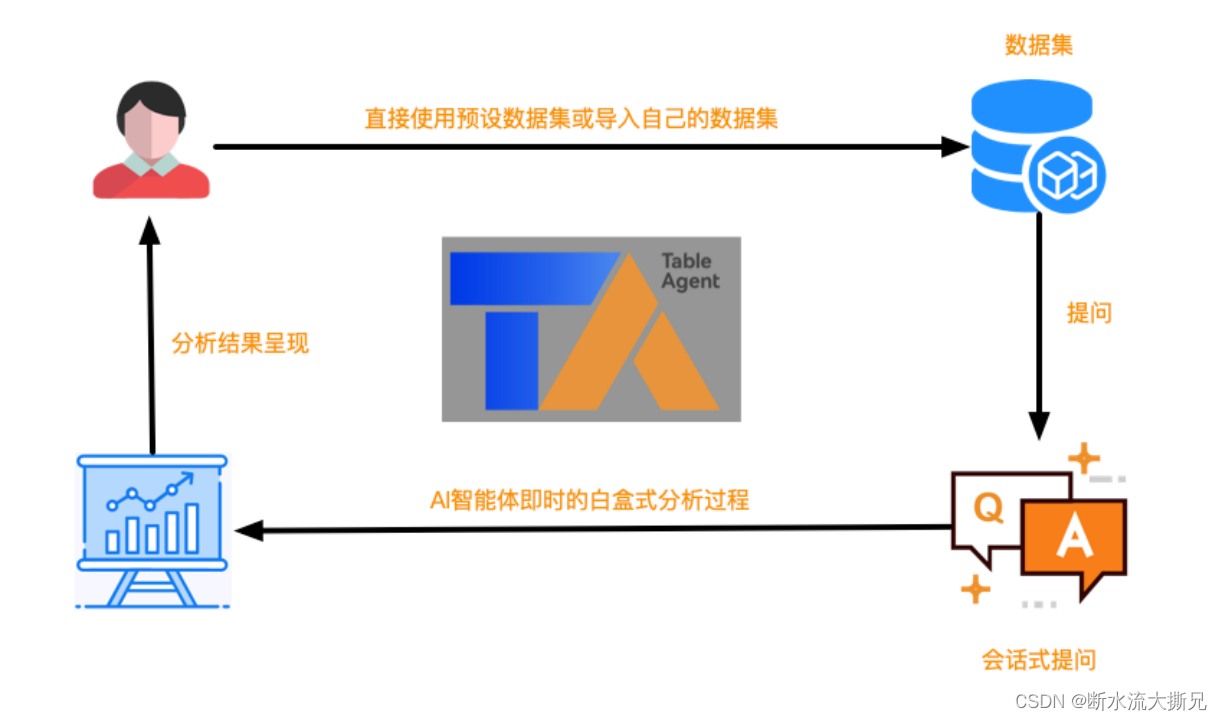
所以单纯就操作门槛和操作简介程度上来说,肯定是
TableAgent
更胜一筹,整体感受上也更加人性化,并且从产品架构上来说
TableAgent
也是创新化的在数据分析产品中融入了AI智能体,这一创新理念,也让
TableAgent
在数据分析垂直领域占据了不少优势。
所以,就我个人感受
TableAgent
和
Amazon SageMaker Canvas
后,
TableAgent
优势有一下几点:
1、AI智能体在数据分析产品领域的融入,让产品各方面能力都得到了非常大的增强,让数据分析形成了互动方式;
2、超便捷的使用方式,没有各种复杂的环境配置、权限配置准备工作,上手门槛极低,真正的做到人人都可做数据分析师;
3、透明化的分析过程呈现,让人可以一目了然了解整个数据预测/分析的过程来源是怎么样的;
4、企业担心数据安全风险支持私有化部署,个人用户每天都有免费的使用次数,各方面都考虑得毕竟充足。
站在客观层面来看,并不是说
Amazon SageMaker Canvas
有多么不好,只不过是
TableAgent
相比较它是新时代的产物,结合了更多的先进技术,成就了它出世即不凡,即超越了非常多的老牌数据分析产品,这也是新产品的优势所在。相信大家通过我横向和纵向的对比也对
TableAgent
有了一个基本的认识了吧,如果读到这里,你也可以去试试 TableAgent 。
四、Alaya开源项目
另外值得一提的是,九章云极 DataCanvas 公司除了在发布会上发布了商用的
TableAgent
以外,还开源了“白盒”模型
Alaya
以及
LMS
模型运行工具、
LMPM
提示词管理工具。国内目前开源且支持商用的大模型好像比较出名的就是清华大学大模型,目前现在又多了一个非常Nice的大模型开源产品了,而且通过查看开源项目的开源协议我们可以看到是
Apache-2.0 license
,也许很多朋友还不清楚
Apache-2.0 license
支持哪些?总之它是一个非常包容和自由的协议,一会展示一个以前整理的开源笔记的图你们就知道了。(有空了一定要部署试试!)
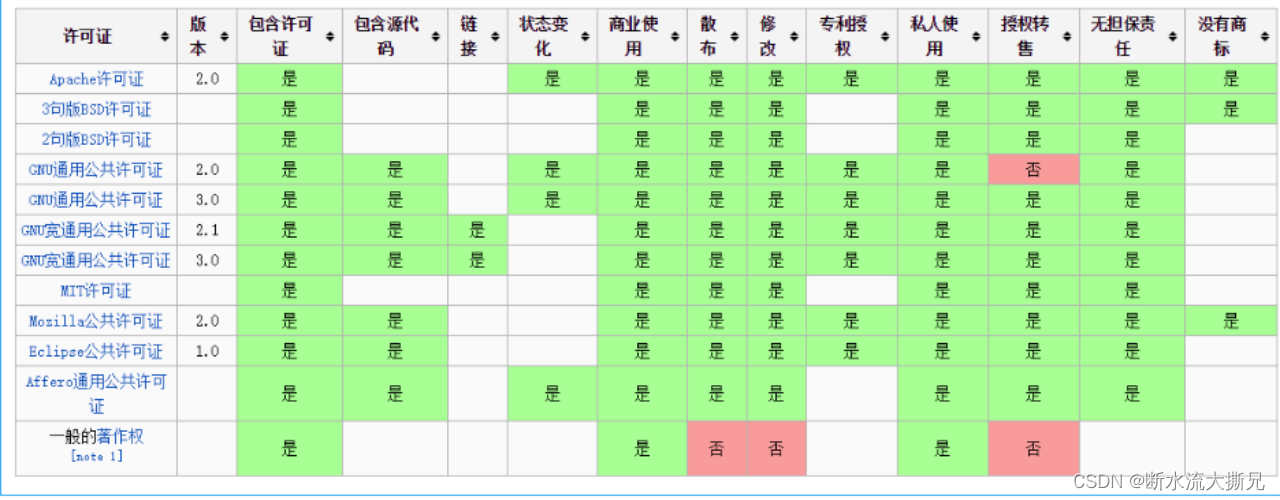
下面是开源协议毕竟直观的一个展示。(有兴趣的可以收藏)
五、个人总结
整体体验下来还是非常棒的,作为一个刚刚发布的产品,已经做得比较优秀了,而且技术团队和公司的开源精神非常值得我们技术人学习。
TableAgent 的优势:
1、结合AI大模型的接入,顺带的这种会话式的交互,脱离了原有的数据分析交互方式,是一个比较创新的想法。
2、使用门槛是真的低,不用各种配置、各种设置,确实做到了是一个人人可用的数据分析产品。
3、透明化数据分析过程与审计监督让过程可追溯,结果信任度更高。
个人建议:
一方面是数据集类型以及大小的支持希望可以进一步支持,另一方面是希望后续的迭代版中有有Win&Mac应用版。
【补充说明】
TableAgent 可以免费体验,注册后可以免费使用5次,次数使用完了,可以认证申请增加次数(每天15次)
【TableAgent公测地址】https://tableagent.DataCanvas.com
版权归原作者 断水流大撕兄 所有, 如有侵权,请联系我们删除。