
一.前言
上篇文章:YOLOv7(目标检测)入门教程详解---环境安装 我们将yolov7外部需要的环境已经全部安装完成,那么这篇文章我们直接进行yolov7的实战----检测,推理,训练。
二.yolov7源码下载
下载网址:GitHub - WongKinYiu/yolov7: Implementation of paper - YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
点击Code,Download ZIP 把yolov7的源码包下载下来
 下载好后打开yolov7源码包
下载好后打开yolov7源码包
在文件路径输入cmd进入终端
 之后在终端activate进入之前创建的环境,并且输入
之后在终端activate进入之前创建的环境,并且输入
pip install -r requirements.txt
强调:关掉电脑VPN

pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple,输入这个指令可能会更快一点
我是之前安装过后,所有再输入安装指令后就会显示全部满足,你们也可以通过这样查看自己是否安装成功
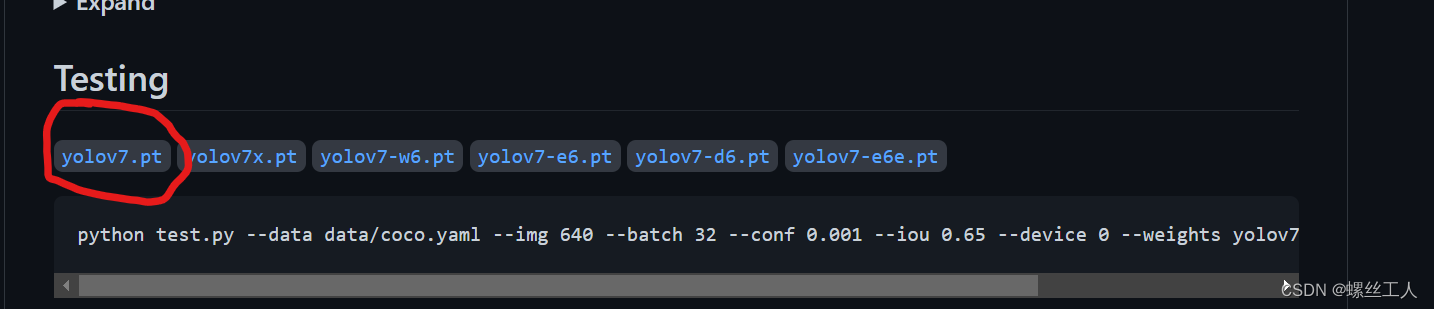
此时我们来到官网下载权重,一个是Test用的yolov7.pt
一个是之后 Train 用的yolov7_training.pt

在yolov7的文件夹路径下建一个weights文件夹,然后把刚刚下载好的两个权重放进去。
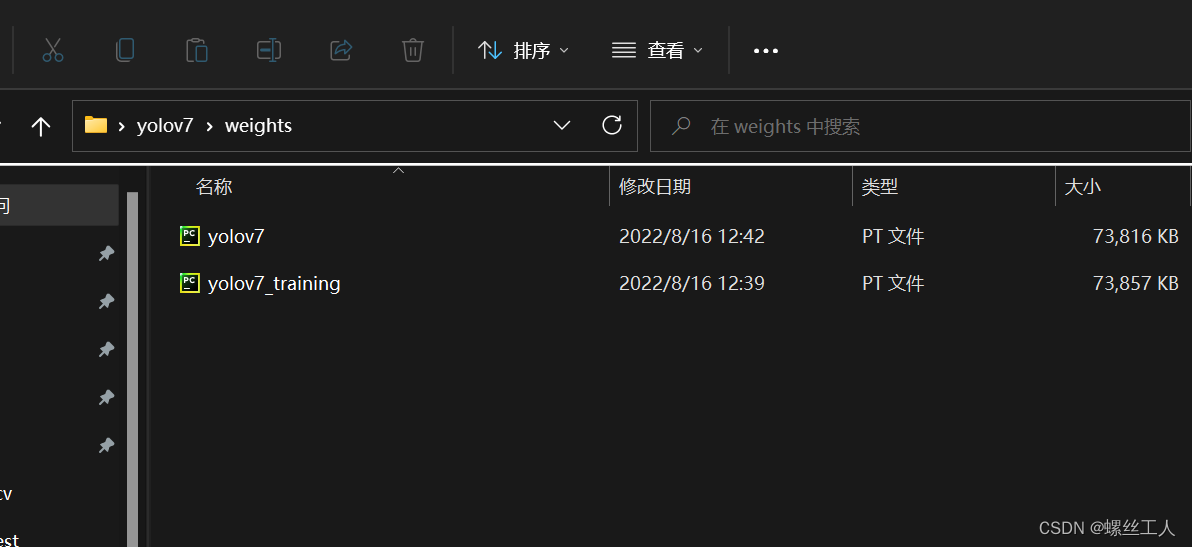
此刻基本需要的环境和文件都已经准备完成了,接下来我们就可以进行detect(检测了)
三.detect(检测)
进入虚拟环境,输入以下指令
python detect.py --weights weights/yolov7.pt --source inference/images
--weights 指令就是代表权重 --source 是照片存在的路径
检测过程如下
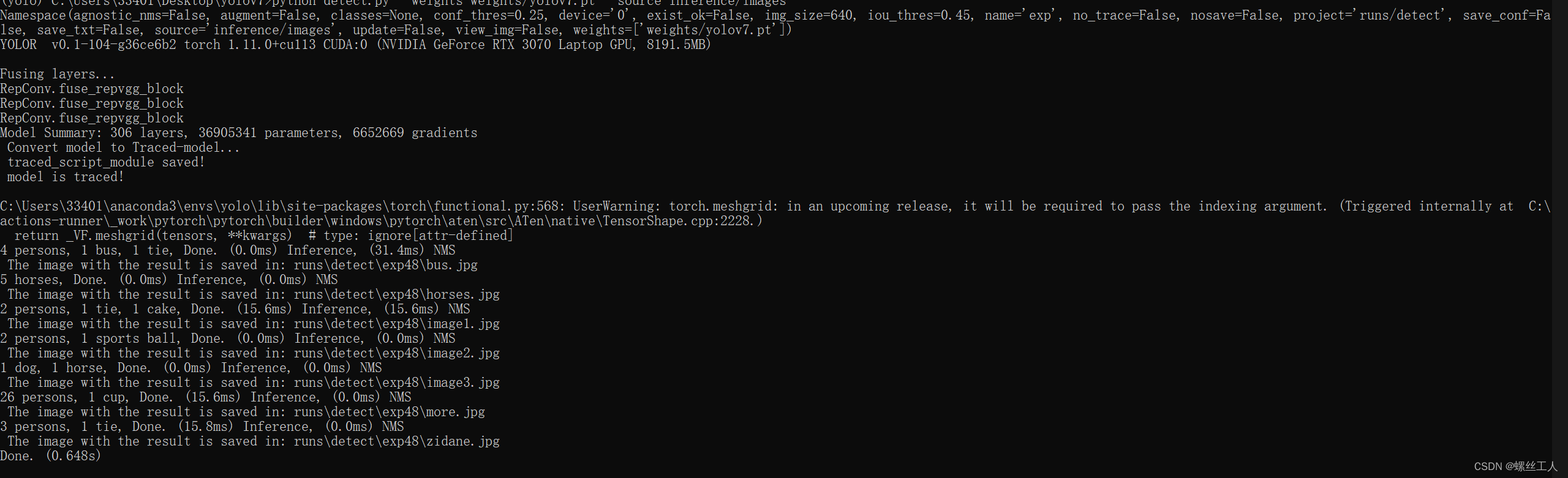
这里可以使用GPU和CPU两种方式进行检测,因为我们之前装了cuda和cudnn所以可以用GPU
只不过我们需要输入--device 0 这个指令,不输入则默认为CPU,我是改了detect源码里面的指令
还有更多操作,我们可以打开detect.py进行查看
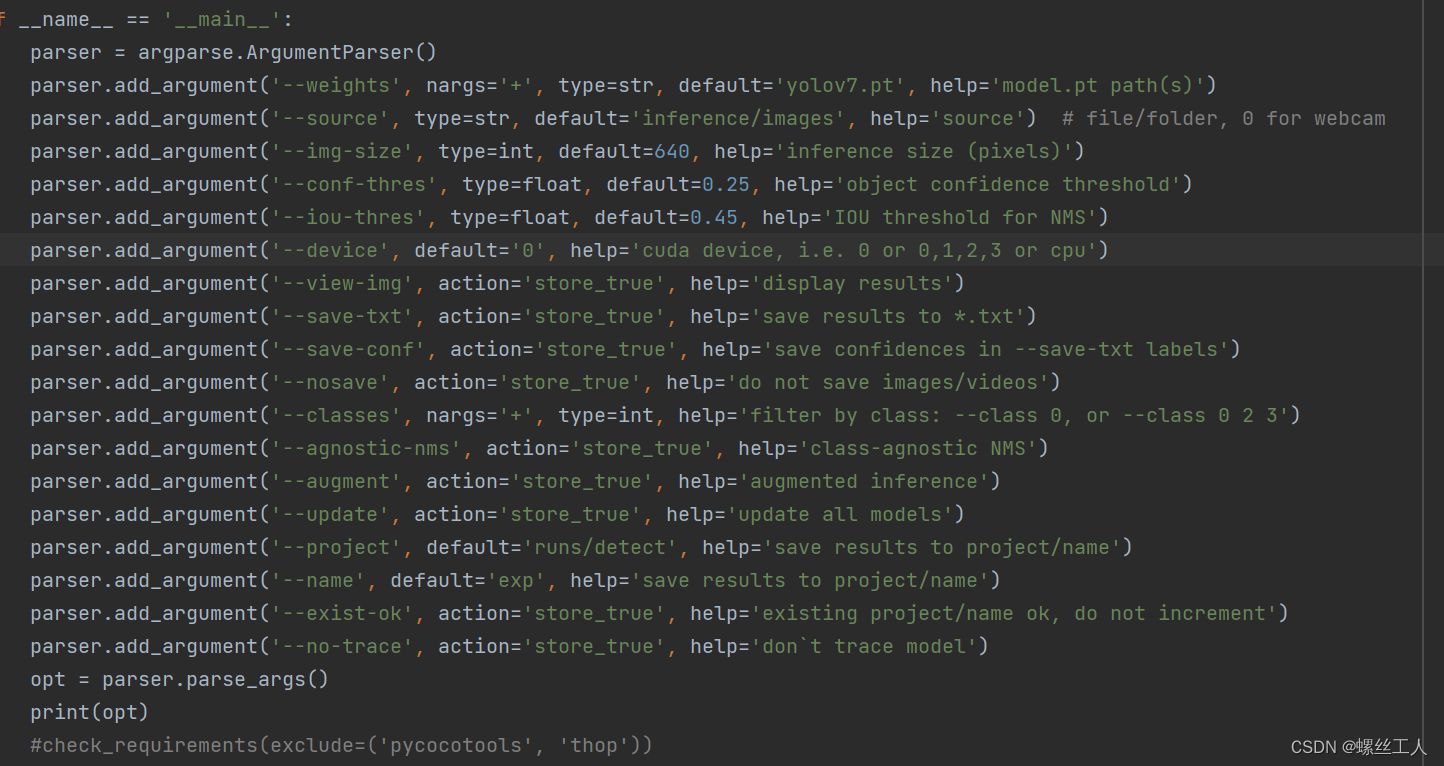
如果你只有cpu就默认cpu,如果是一个gpu就选择--device 0 两块cpu就--deivce 1,以此类推。
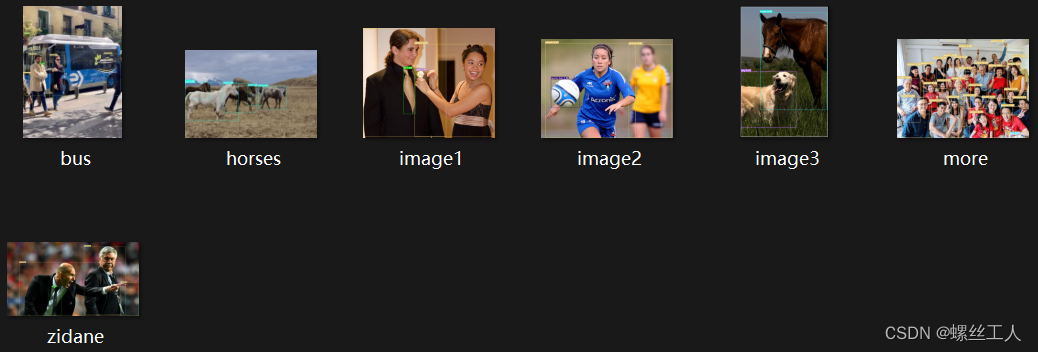
我们来看看我们训练之后的结果,进入runs-->detect-->exp 里面有所有预测好的照片

四.Train(训练)
参考博客:【小白教学】如何用YOLOv7训练自己的数据集 - 知乎
数据准备:
我们生成
/datasets/
文件夹,把数据都放进这个文件夹里进行统一管理。训练数据用的是yolo数据格式,不过多了两个
.txt
文件,这两个文件存放的,是每个图片的路径,后面会具体介绍。
那么接下来yolo数据集的整体格式如下:
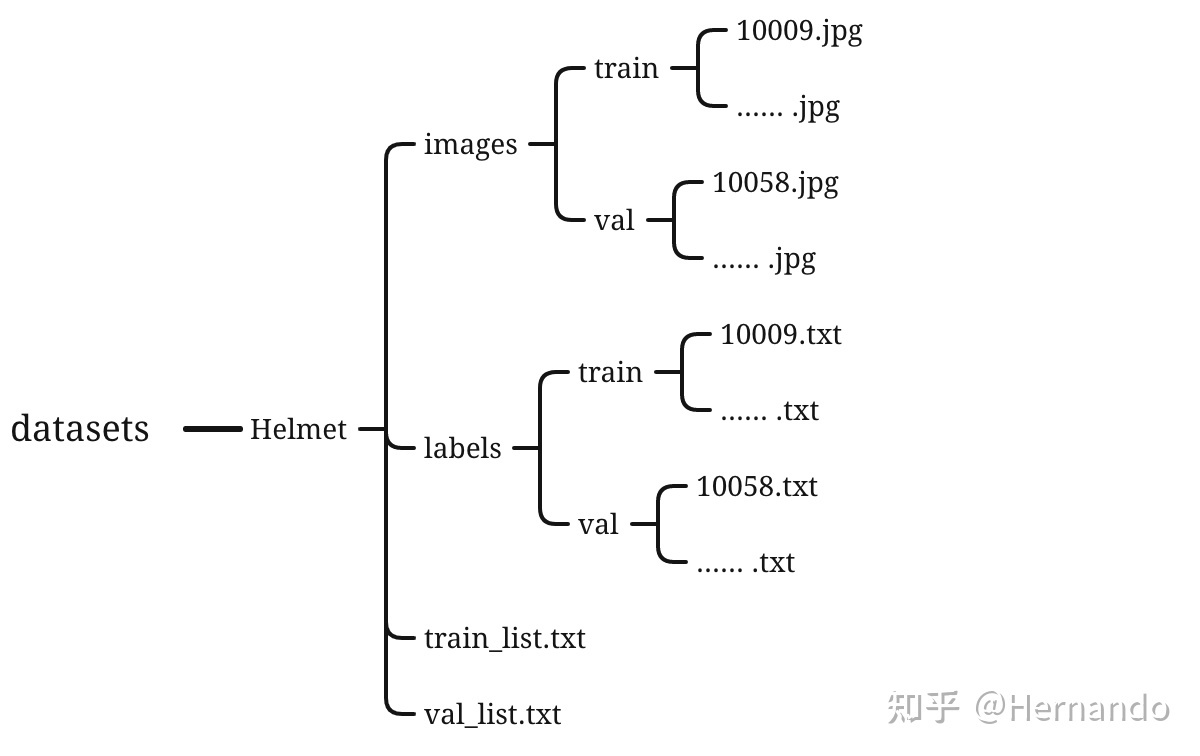
Helmet是你想检测的东西名称,我检测的是圆环所以命名为circle

进入circle文件夹之后,会看到有images 和labels的文件夹,一个是拿来放图片的,一个是拿来存images文件夹中处理jpg图片之后的txt数据
打开images文件夹,我们又要建两个文件夹:train 和 val,并且把想要训练的照片放进去,两个都放差不多数量
 打开labels文件夹,同样建两个文件train和val,然后就ok了
打开labels文件夹,同样建两个文件train和val,然后就ok了
接下来我们就要用到一个软件去处理我们的图片,将其转化为yolo格式
labellmg:
参考博客:labelImg使用教程_G果的博客-CSDN博客_labelimg
进入终端,输入指令进行下载
输入labellmg打开软件
 然后我们使用labellmg进行对图片的处理,首先open dir选择图片路径,我们先选择刚刚创建的datasets/circle/images/train 然后change save dir选择datasets/circle/labels/train,这样我们对image的每张图片的处理都会储存进label中 之后val也是同理。
然后我们使用labellmg进行对图片的处理,首先open dir选择图片路径,我们先选择刚刚创建的datasets/circle/images/train 然后change save dir选择datasets/circle/labels/train,这样我们对image的每张图片的处理都会储存进label中 之后val也是同理。
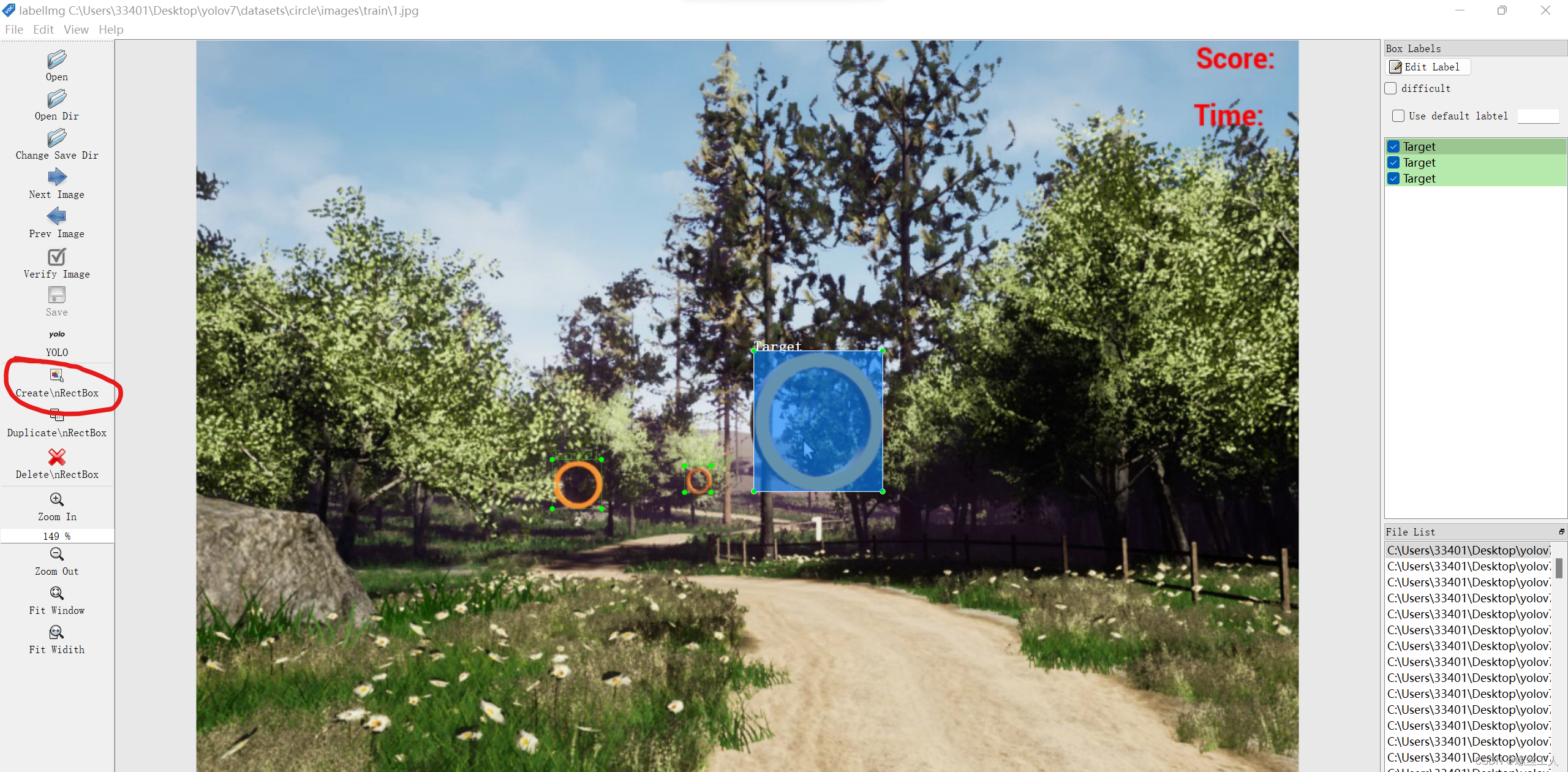
之后就把每一个你想训练的目标给框出来然后进行命名,但是必须要改成YOLO格式
之后打开我们的labels就能发现里面储存了images中每张图片对应的txt文件
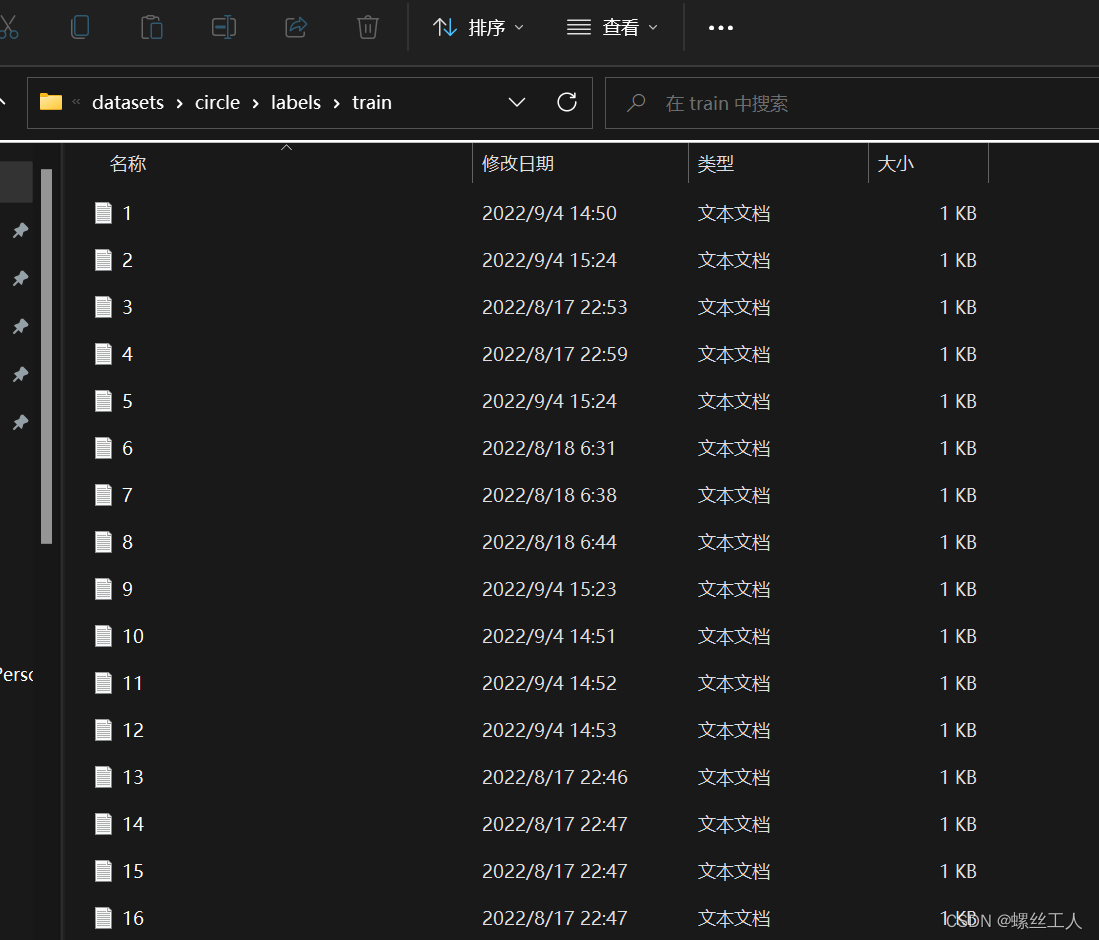
然后我们进入datasets/circle文件夹下面,建立两个txt文件,train.txt val.txt,这两个文件分为写入所有images中train和val中的照片路径
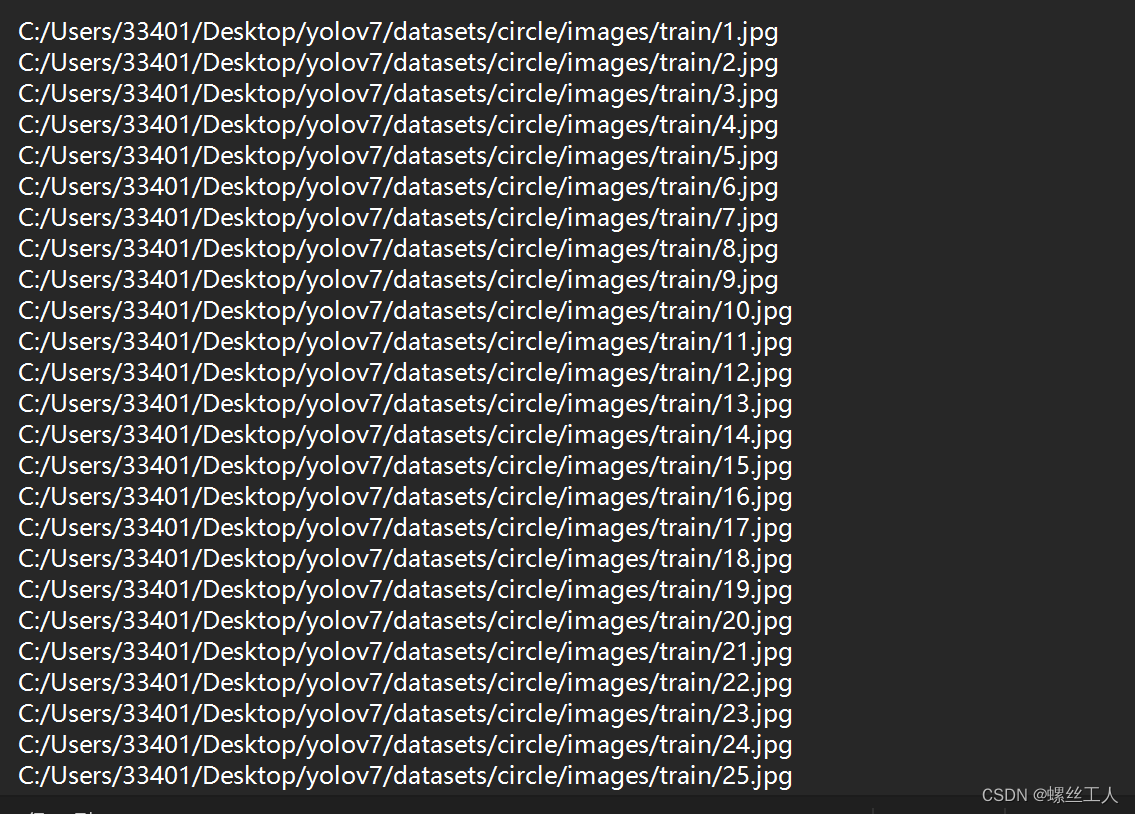
配置训练的相关文件
总共有两个文件需要配置,一个是
/yolov7/cfg/training/yolov7.yaml
,这个文件是有关模型的配置文件;一个是
/yolov7/data/coco.yaml
,这个是数据集的配置文件。
第一步,复制
yolov7.yaml
文件到相同的路径下,然后重命名,我们重命名为
yolov7-Helmet.yaml
。
第二步,打开
yolov7-circle.yaml
文件,进行如下图所示的修改,这里修改的地方只有一处,就是把nc修改为我们数据集的目标总数即可。然后保存。

配置数据集文件
第一步,复制
coco.yaml
文件到相同的路径下,然后重命名,我们命名为circle
.yaml
。
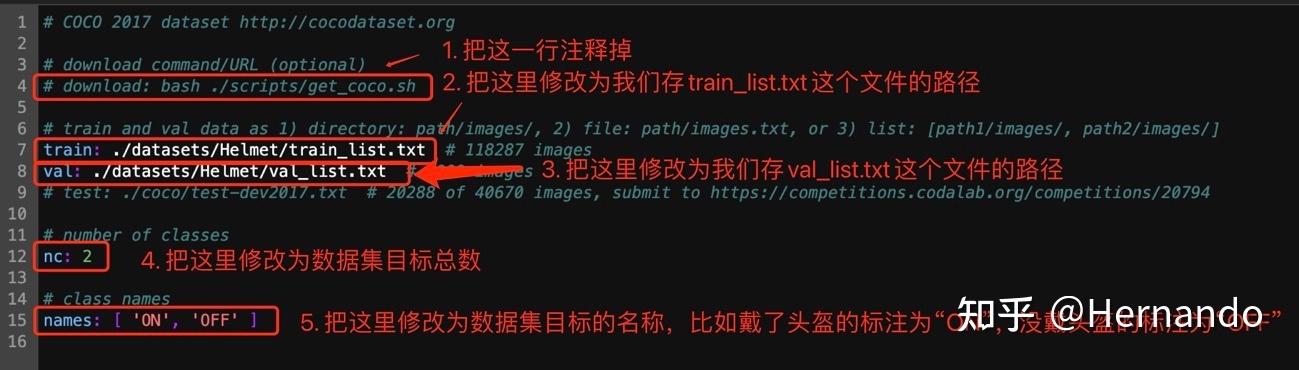
第二步,打开circle
.yaml
文件,进行如下所示的修改,需要修改的地方为5处。第一处:把代码自动下载COCO数据集的命令注释掉,以防代码自动下载数据集占用内存;第二处:修改train的位置为
train.txt
的路径;第三处:修改val的位置为
val.txt
的路径;第四处:修改nc为数据集目标总数;第五处:修改names为数据集所有目标的名称。然后保存。
我的参照上图改好如下
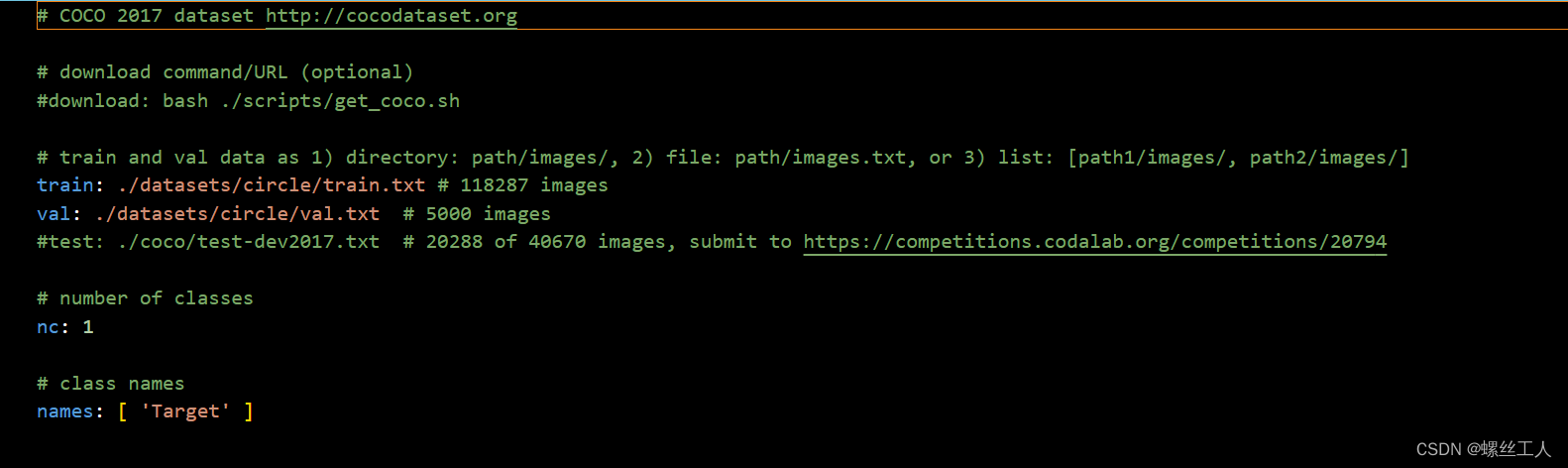
之后我们就可以进行训练了!!!
正式训练:
此时我们在yolov7文件夹路径下cmd,并且进入虚拟环境,输入指令
python train.py --weights weights/yolov7_training.pt --cfg cfg/training/yolov7-circlr.yaml --data data/circlr.yaml --device 0 --batch-size 8 --epoch 300
这里对里面的参数进行解释
--cfg 接受模型配置的参数
--data 接收数据配置的参数
--device 0 训练类型,我是一块GPU 所以用0
--batch-size 8 GPU内存大小决定
--epoch 训练次数,建议300
--weights 训练的权重
训练到最后我们就会得到一个last 和best的pt文件,那么我们直接把best.pt拿出来使用就ok了
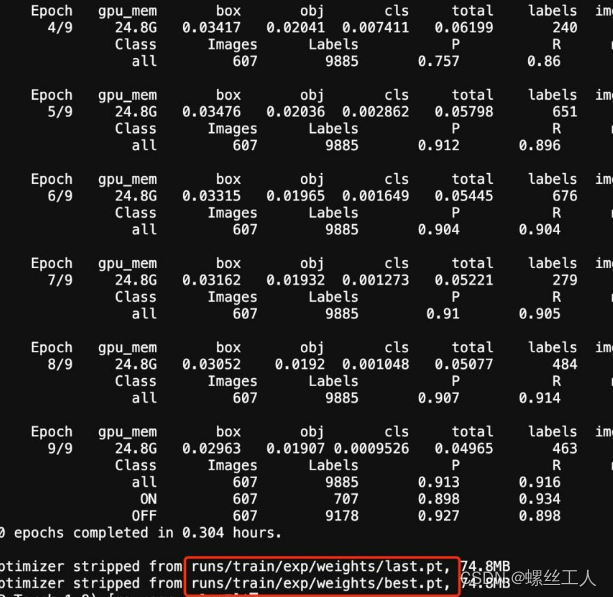
推理:
我们已经获得了自己训练出来的权重了,那么这个时候推理,其实跟之前检测的道理是一样的,唯一变换的就是我们的权重文件和自己检测的照片 。
这个时候我们在datasets文件夹下面建立一个textimages文件夹和textvideo文件夹,分别用来储存要被检测的图片和视频
跟detect一样,进入虚拟环境输入权重路径和图片路径就ok了,指令如下
我是把best.pt直接拉到了yolov7文件夹路径下面,你们刚刚训练出来的在runs/train/circle/weights/best.pt
python detect.py --weights best.pt --source datasets/textimages --device 0
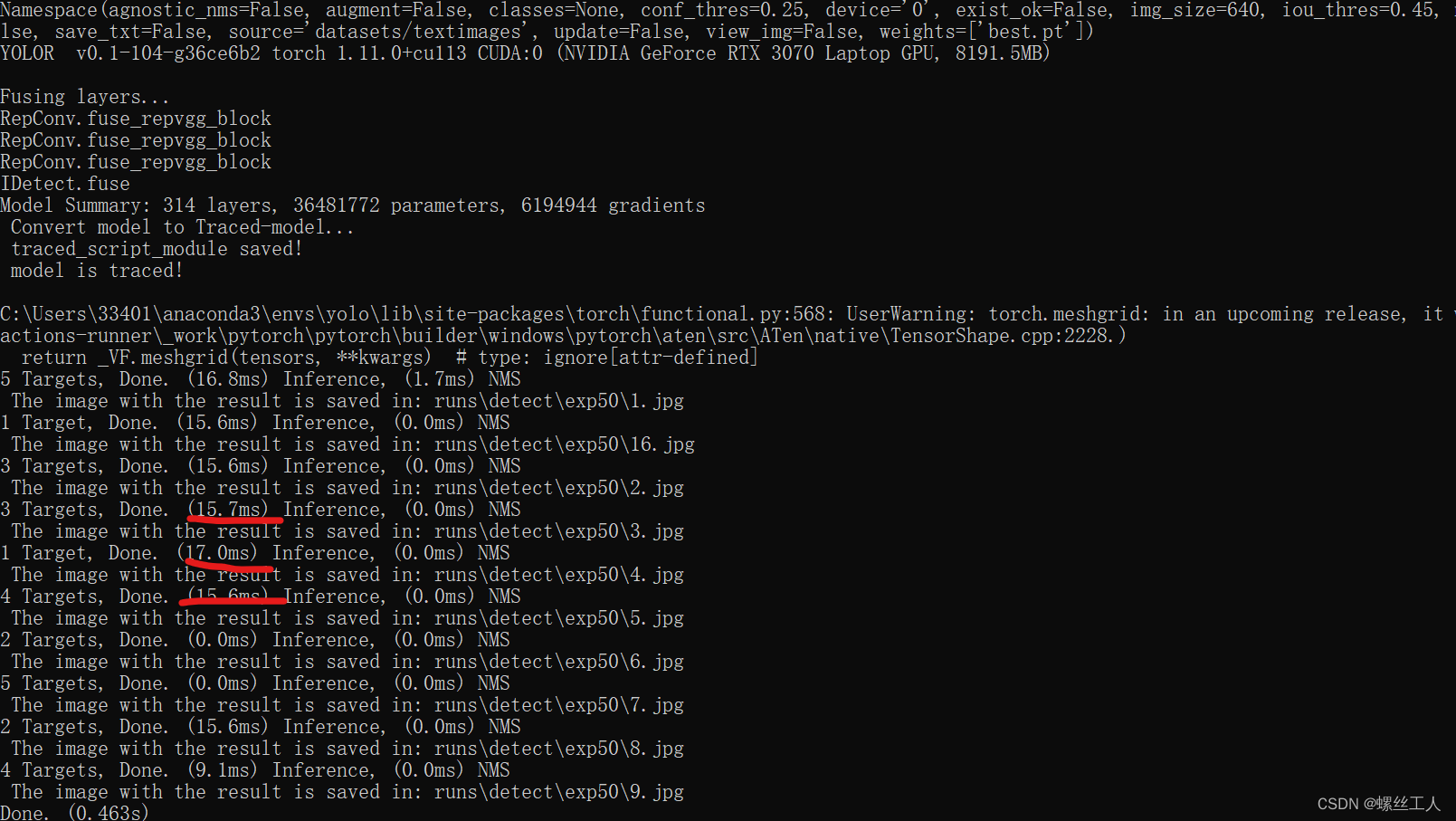
可以看到用gpu训练的yolov7是相当的快,我显卡是3070的,大概一张照片15ms左右的样子,如果用CPU的话,速度要慢十倍左右
推理效果:
我打开runs/detect/exp查看我们的训练效果


可以说效果是非常好的,方框上面的数值就是置信度了,只要训练的好,yolov7的处理能力非常的强大。
五.总结
那么yolov7的检测,训练,推理的全部流程都已经可以实现了,但是这个是基于python环境下的,如果有特殊的需求需要在c++环境下去进行yolo检测的话,那就又另有一方折腾了,我会在之后的博客中说到如何在c++中去使用yolov7检测。
有相关问题可以私信我进行讨论
版权归原作者 螺丝工人 所有, 如有侵权,请联系我们删除。