
说到集合,就list接口,set接口和map接口
想了解他们几个,必不可少的得先了解他们的数据结构。
数据机构
我们先介绍几个数据结构:数组,链表,树
1.数组
Char[] sz =newChar[]{'S','H','U','Z','U'};Char[] sz1 =newChar[5];
cs1[0]='S';....
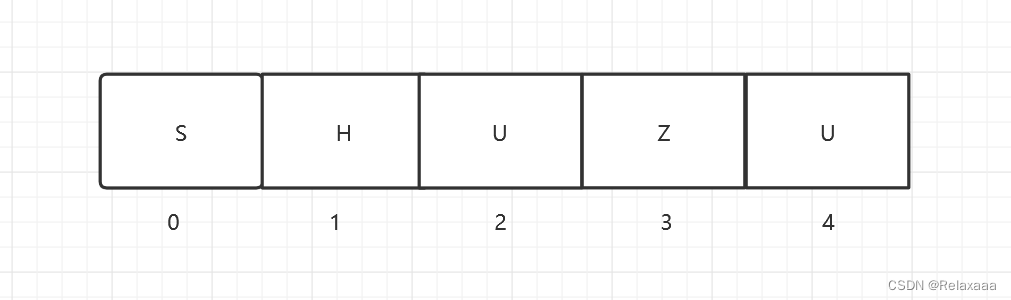 由图可见,这就是数组结构,看着图我们不难总结出几个特点:
由图可见,这就是数组结构,看着图我们不难总结出几个特点:
1.内存地址连续
2.可以通过下标访问的方式访问成员,所以查询效率高
3.增删操作会给系统带来性能消耗[保证数据下标越界的问题,需要动态扩容]
2.链表
privatestaticclassNode<E>{E item;// 节点的元素Node<E> next;// 下一个节点Node<E> prev;// 上一个节点Node(Node<E> prev,E element,Node<E> next){this.item = element;this.next = next;this.prev = prev;}}
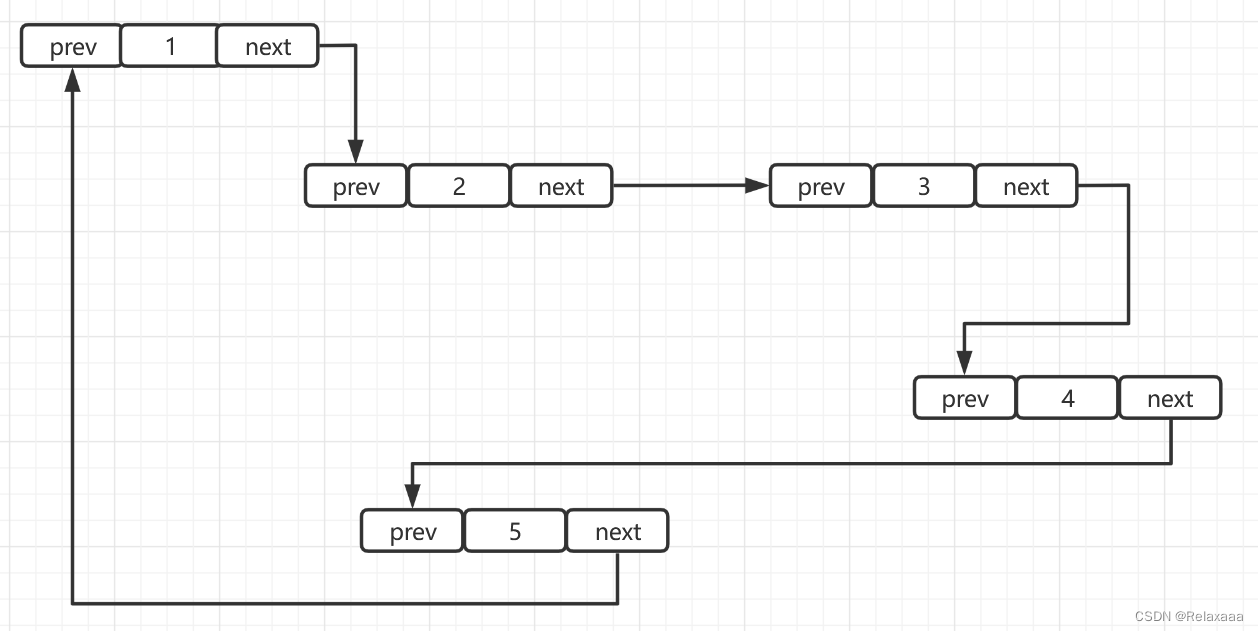
这是一个链表草图(请不要吐槽我hhhh),由图课件,链表是由节点存储的,每一个节点由(prev,数据,next)三部分组成,和数组对比链表空间更自由,也不要求连续。
添加节点
只需要将节点的next和下一个节点的prev连接起来即可。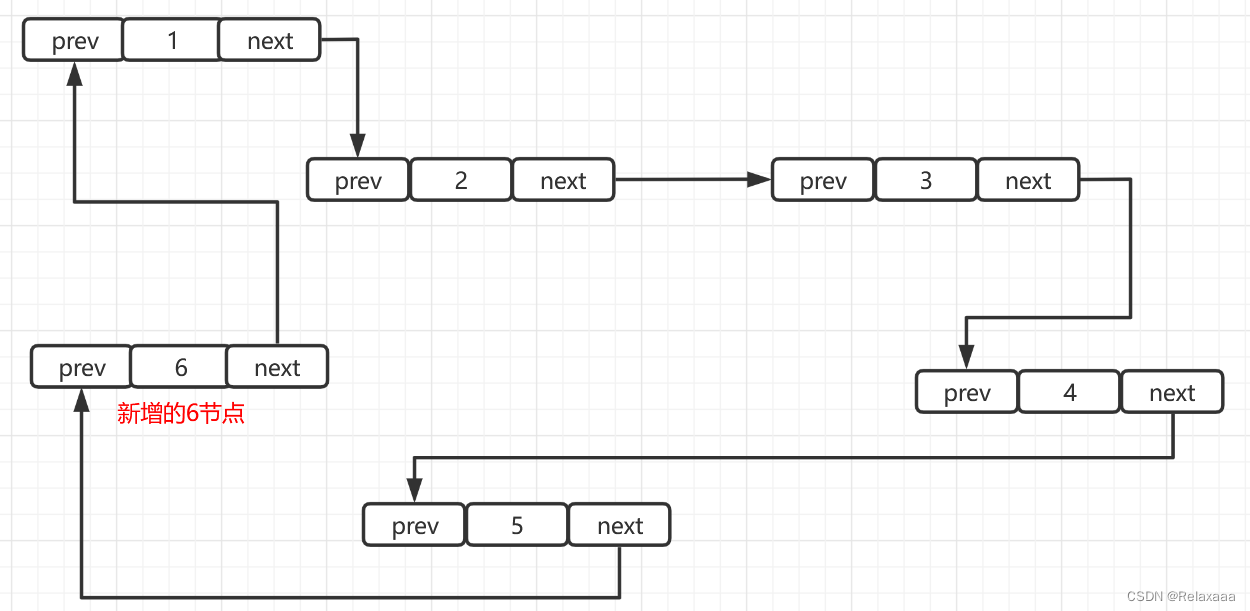 删除节点
删除节点
原本的4的next会指向5的prev,我们要删除5,只需将4的next指向下一个节点即可,多出来的5会被GC掉。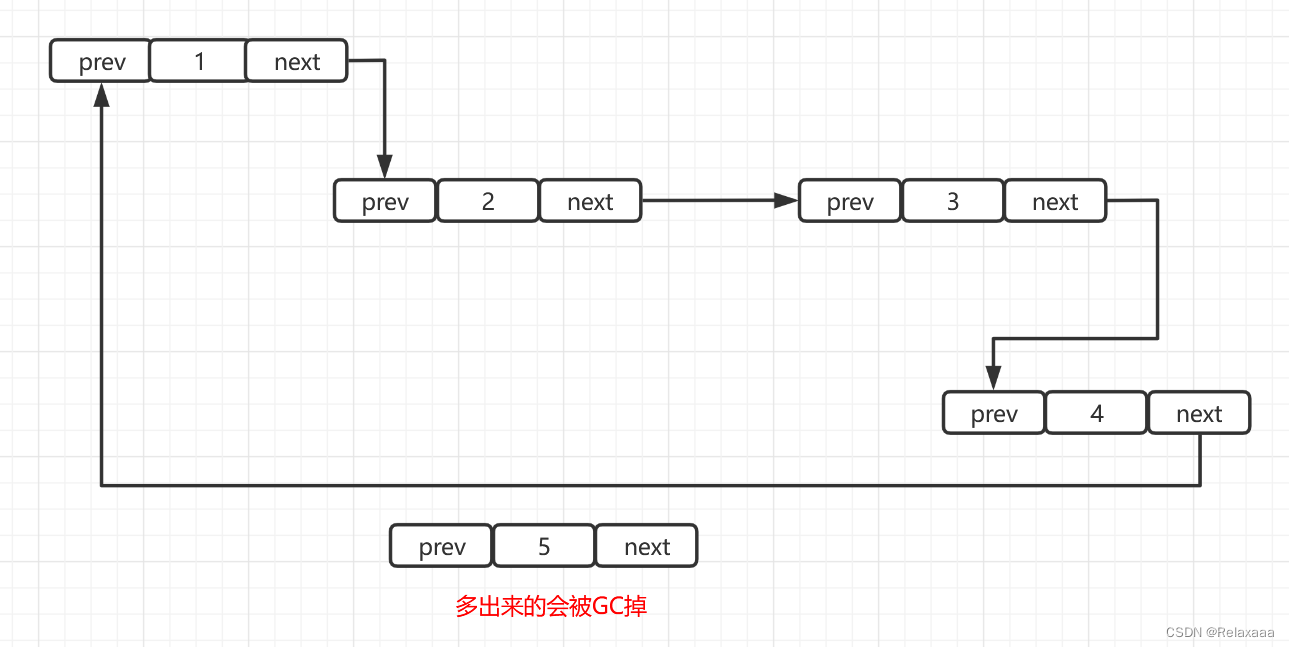 总结一下:
总结一下:
1.灵活的空间要求,存储空间不要求连续
2.不支持下标的访问,支持顺序遍历检索
3.针对增删效率会更高些,只和操作节点的前后节点有关系,无需移动元素。
3.树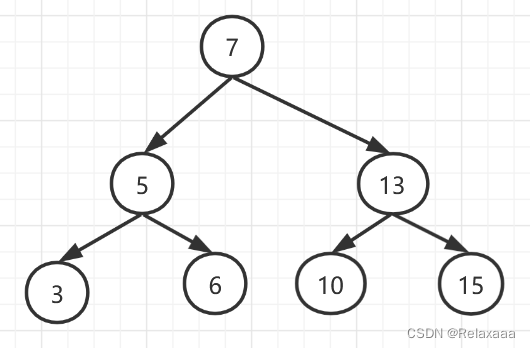 (这个图画出来真的蚌埠住了,手残画不好哇)
(这个图画出来真的蚌埠住了,手残画不好哇)
二叉树具有以下特点:
(1)某节点的左子树节点值仅包含小于该节点值
(2)某节点的右子树节点值仅包含大于该节点值
(3)左右子树每个也必须是二叉查找树
(4)顺序排列
通俗点讲就是两边都是二叉树且顺序排列,右边大于左边,如果新插进来一个,跟节点对比一下,比他大就往右边去,比它小就往左边去。
上图相当于是平衡二叉树,既然有平衡的,那肯定有不平衡的,比如这样的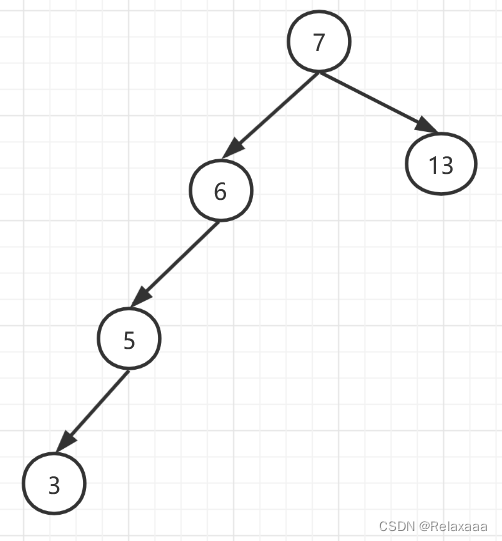 这样的查询效率不高,想要效率高肯定要平衡,红黑树就解决了这个问题,红黑树是一个自平衡二叉树。
这样的查询效率不高,想要效率高肯定要平衡,红黑树就解决了这个问题,红黑树是一个自平衡二叉树。
红黑树
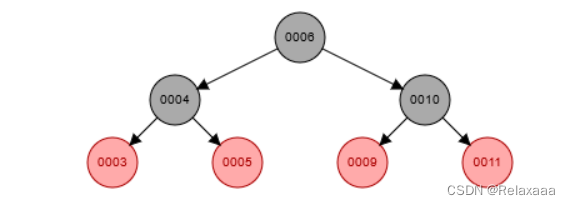
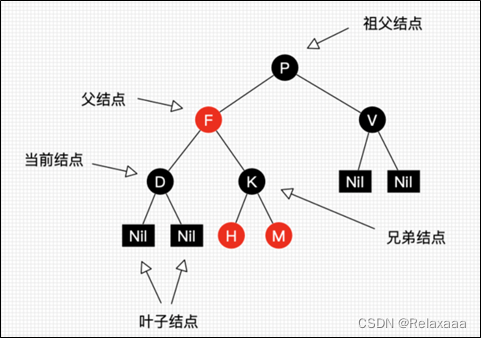
红黑树,Red-Black Tree [RBT] 是一个自平衡【不是绝对】的二叉查找树,树上的节点满足如下的规则
1.每个节点要么是红色,要么是黑色。
2.根节点必须是黑色
3.每个叶子节点【NIL】是黑色
4.每个红色节点的两个子节点必须是黑色
5.任意节点到每个叶子节点的路径包含相同数量的黑节点
黑平衡二叉树
1.recolor 重新标志节点为红色或者黑色
2.rotation 旋转 树达到平衡的关键
红黑树能自平衡,它靠的是什么?三种操作:左旋、右旋和变色
左旋:以某个结点作为支点(旋转结点),其右子结点变为旋转结点的父结点,
右子结点的左子结点变为旋转结点的右子结点,左子结点保持不变。
右旋:以某个结点作为支点(旋转结点),其左子结点变为旋转结点的父结点,
左子结点的右子结点变为旋转结点的左子结点,右子结点保持不变。
变色:结点的颜色由红变黑或由黑变红。
红黑树插入的场景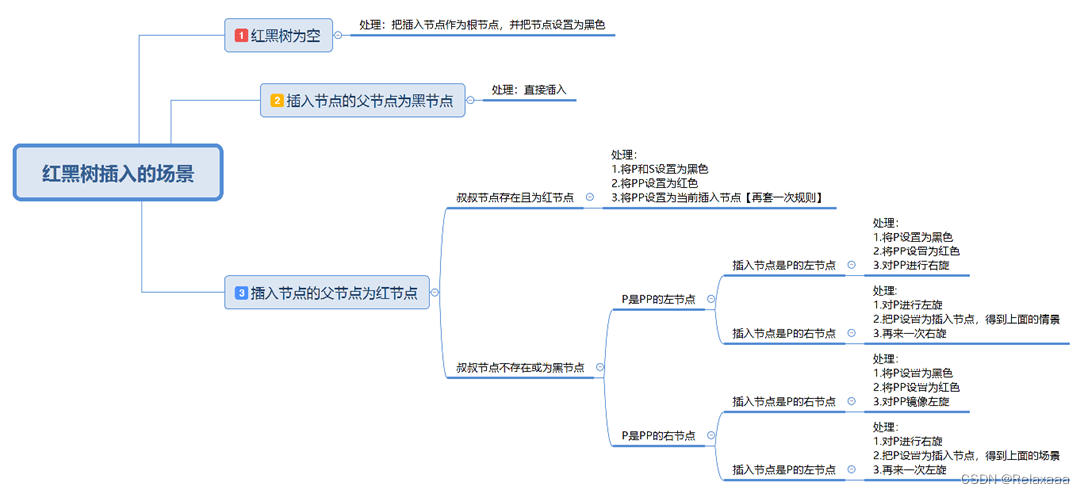 红黑树模拟
红黑树模拟
这个是红黑树模拟,我红黑树的第一张图也是这里模拟截的图,这些理论可能看着晦涩难懂,大家去玩几把就好理解一些。
二.集合
有了上面的几个数据机构打基础剩下的就好说了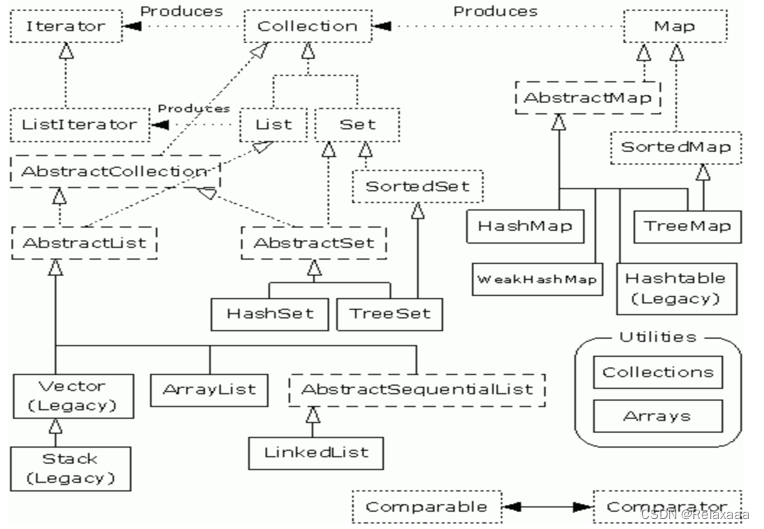 这张图肯定不会陌生,应该都见过hh。
这张图肯定不会陌生,应该都见过hh。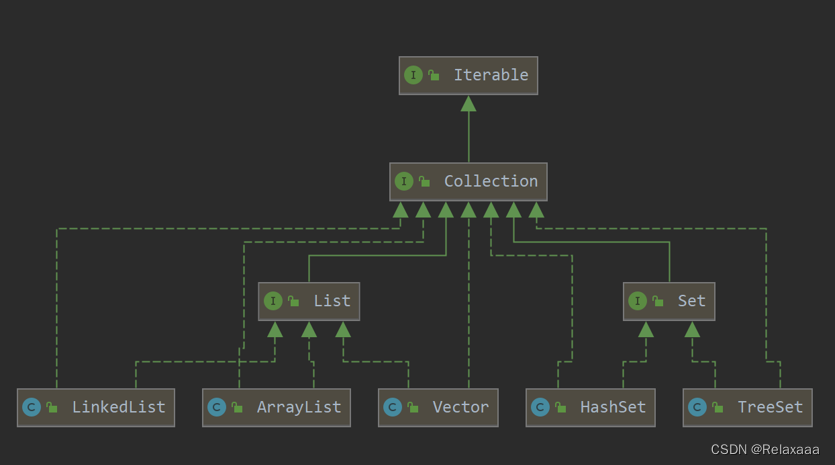
这是从idea截出来的collection接口
List接口
1.ArrayList
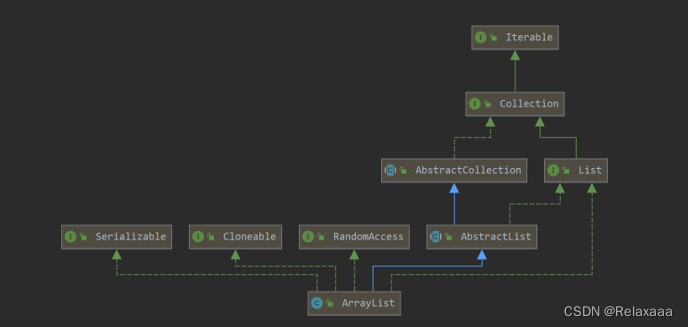
本质就是动态数组,动态扩容
/**
* Default initial capacity.
默认的数组的长度
*/privatestaticfinalint DEFAULT_CAPACITY =10;/**
* Shared empty array instance used for empty instances.
空数组
*/privatestaticfinalObject[] EMPTY_ELEMENTDATA ={};/**
* Shared empty array instance used for default sized empty instances. We
* distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when
* first element is added.
*/privatestaticfinalObject[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA ={};/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
集合中存储数据的 数组对象
*/transientObject[] elementData;// non-private to simplify nested class access/**
* The size of the ArrayList (the number of elements it contains).
* 集合中元素的个数
* @serial
*/privateint size;
初始操作
无参构造
publicArrayList(){this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;// this.elementData = {}}
有参构造
publicArrayList(int initialCapacity){if(initialCapacity >0){// 初始长度大于0 就创建一个指定大小的数组this.elementData =newObject[initialCapacity];}elseif(initialCapacity ==0){// {}数组赋值给 this.elementDatathis.elementData = EMPTY_ELEMENTDATA;}else{thrownewIllegalArgumentException("Illegal Capacity: "+
initialCapacity);}}
add方法
初始无参构造器
第一次添加
publicbooleanadd(E e){// 确定容量 动态扩容 size 初始 0ensureCapacityInternal(size +1);// Increments modCount!!// 将要添加的元素 添加到数组中 elementData[0] = 1 --> size = 1
elementData[size++]= e;returntrue;}
privatevoidensureCapacityInternal(int minCapacity){// ensureExplicitCapacity(10)ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));}
/**
* elementData {}
minCapacity 1
*/privatestaticintcalculateCapacity(Object[] elementData,int minCapacity){if(elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA){// 10 1 return 10returnMath.max(DEFAULT_CAPACITY, minCapacity);}// 5return minCapacity;}
privatevoidensureExplicitCapacity(int minCapacity){
modCount++;// 增长 操作次数// minCapacity 10if(minCapacity - elementData.length >0)grow(minCapacity);}
privatevoidgrow(int minCapacity){// 10// overflow-conscious codeint oldCapacity = elementData.length;// 0// newCapacity = 0int newCapacity = oldCapacity +(oldCapacity >>1);if(newCapacity - minCapacity <0)// newCapacity = 10
newCapacity = minCapacity;if(newCapacity - MAX_ARRAY_SIZE >0)
newCapacity =hugeCapacity(minCapacity);// {} {,,,,,,,,,} 返回一个新的数组 长度为10
elementData =Arrays.copyOf(elementData, newCapacity);}
第二次添加
elementData ={1,,,,,,,,,};
size =1;
publicbooleanadd(E e){// 2ensureCapacityInternal(size +1);// Increments modCount!!
elementData[size++]= e;// elementData[1] = 2 size = 2returntrue;}
privatestaticintcalculateCapacity(Object[] elementData,int minCapacity){if(elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA){returnMath.max(DEFAULT_CAPACITY, minCapacity);}// 2return minCapacity;}
privatevoidensureExplicitCapacity(int minCapacity){
modCount++;// overflow-conscious code 2 - 10if(minCapacity - elementData.length >0)grow(minCapacity);}
第十一次添加
elementData ={1,2,3,4,5,6,7,8,9,10};
size =10;
publicbooleanadd(E e){ensureCapacityInternal(size +1);// Increments modCount!!
elementData[size++]= e;returntrue;}
privatevoidensureCapacityInternal(int minCapacity){// ensureExplicitCapacity(11)ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));}
privatevoidensureExplicitCapacity(int minCapacity){
modCount++;// 11 - 10 > 0if(minCapacity - elementData.length >0)//这个就是扩容方法grow(minCapacity);}
grow扩容方法
privatevoidgrow(int minCapacity){// 11// 10(记录原来的容量)int oldCapacity = elementData.length;// 15 newCapacity 是oldCapacity的1.5倍// 计算新的容量 新容量为 老容量的1.5倍 第一次为0int newCapacity = oldCapacity +(oldCapacity >>1);if(newCapacity - minCapacity <0)
newCapacity = minCapacity;if(newCapacity - MAX_ARRAY_SIZE >0)
newCapacity =hugeCapacity(minCapacity);// minCapacity is usually close to size, so this is a win:// {1,2,3,4,5,6,7,8,9,10} -- > {1,2,3,4,5,6,7,8,9,10,,,,,}// 把原来数组中的内容拷贝到一个新建的指定容量为newCapacity的数组中,扩容
elementData =Arrays.copyOf(elementData, newCapacity);}
get方法
publicEget(int index){// 检查下标是否合法rangeCheck(index);// 通过下标获取数组对应的元素returnelementData(index);}
set方法
publicEset(int index,E element){rangeCheck(index);// 检查下标// 获取下标原来的值E oldValue =elementData(index);
elementData[index]= element;return oldValue;}
remove方法
publicEremove(int index){rangeCheck(index);
modCount++;E oldValue =elementData(index);// 获取要移动的元素的个数 {1,2,3,4,5,6,7,8,9} // 3 size=9 index=3// {1,2,3,5,6,7,8,9,null}int numMoved = size - index -1;// 5if(numMoved >0)// 源数组 开始下标 目标数组 开始下标 长度System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size]=null;// clear to let GC do its work// 删除的节点对应的信息return oldValue;}
2.LinkedList
我们把上面的图再拿过来用一下hhhh。
LinkedList是通过双向链表去实现的,他的数据结构具有双向链表的优缺点,既然是双向链表,那么的它的顺序访问效率会非常高,而随机访问的效率会比较低,它包含一个非常重要的私有内部静态类:Node
privatestaticclassNode<E>{E item;// 节点的元素Node<E> next;// 下一个节点Node<E> prev;// 上一个节点Node(Node<E> prev,E element,Node<E> next){this.item = element;this.next = next;this.prev = prev;}}
get方法:本质上还是遍历链表中的数据
Node<E>node(int index){// assert isElementIndex(index);// index 和 长度的一半比较if(index <(size >>1)){Node<E> x = first;// 从头开始循环for(int i =0; i < index; i++)
x = x.next;return x;}else{Node<E> x = last;// 从尾部开始循环for(int i = size -1; i > index; i--)
x = x.prev;return x;}}
set方法
publicEset(int index,E element){checkElementIndex(index);// 检查下标是否合法Node<E> x =node(index);// 根据下标获取对应的node对象E oldVal = x.item;// 记录原来的值
x.item = element;// 赋予新的值return oldVal;// 返回修改之前的值}
3.Vector
和ArrayList很类似,都是以动态数组的形式来存储数据
Vector线程安全的
每个操作方法都加的有synchronized关键字,针对性能来说会比较大的影响,慢慢就被放弃了
Collections
可以增加代码的灵活度,在我们需要同步是时候就通过如下代码实现
List syncList =Collections.synchronizedList(list);
本质上
publicEget(int index){synchronized(mutex){return list.get(index);}}publicEset(int index,E element){synchronized(mutex){return list.set(index, element);}}publicvoidadd(int index,E element){synchronized(mutex){list.add(index, element);}}publicEremove(int index){synchronized(mutex){return list.remove(index);}}
它将我们所以的方法加上了synchronized 。。
Set接口
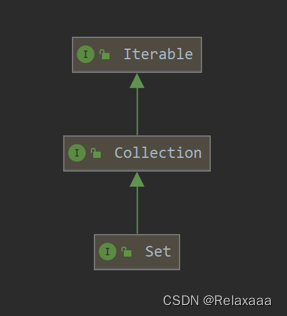
1.HashSet
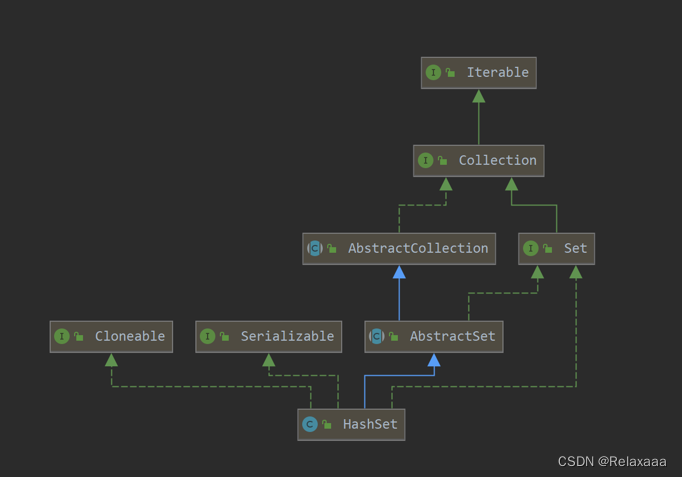
概述
HashSet实现Set接口,由哈希表支持,它不保证set的迭代顺序,特别是它不保证该顺序永久不变,运行使用null。
publicHashSet(){
map =newHashMap<>();}
add方法
publicbooleanadd(E e){return map.put(e, PRESENT)==null;}
本质上是将数据保持在 HashMap中 key就是我们添加的内容,value就是我们定义的一个Object对象
特点
底层数据结构是哈希表,HashSet的本质是一个"没有重复元素"的集合,他是通过
HashMap
实现的.HashSet中含有一个HashMap类型的成员变量
map
.在HashSet中操作函数,实际上都是通过map实现的。所以了解了HashMap就了解了HashSet。
2.TreeSet
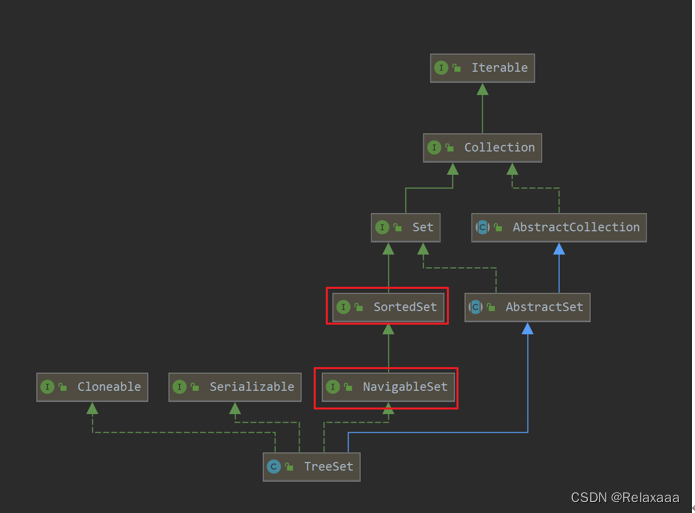
概述
基于TreeMap的 NavigableSet实现。使用元素的自然顺序对元素进行排序,或者根据创建 set 时提供的 Comparator进行排序,具体取决于使用的构造方法。
publicTreeSet(){this(newTreeMap<E,Object>());}
本质是将数据保存在TreeMap中,key是我们添加的内容,value是定义的一个Object对象。
特点
- TreeSet 是一个有序的并且可排序的集合,它继承于AbstractSet抽象类,实现了NavigableSet, Cloneable, java.io.Serializable接口。
- TreeSet是基于TreeMap实现的。TreeSet中的元素支持2种排序方式:自然排序 或者 根据创建TreeSet 时提供的 Comparator 进行排序。这取决于使用的构造方法。同样的了解了TreeMap就了解了TreeSet。
Map接口
Map集合的特点
1.能够存储唯一的列的数据(唯一,不可重复) Set
2.能够存储可以重复的数据(可重复) List
3.值的顺序取决于键的顺序
4.键和值都是可以存储null元素的
TreeMap
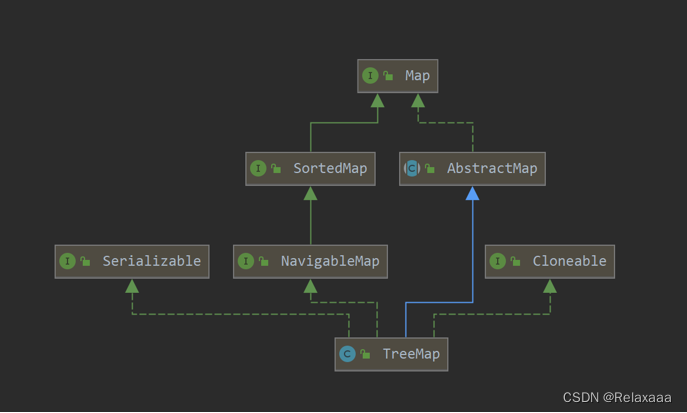
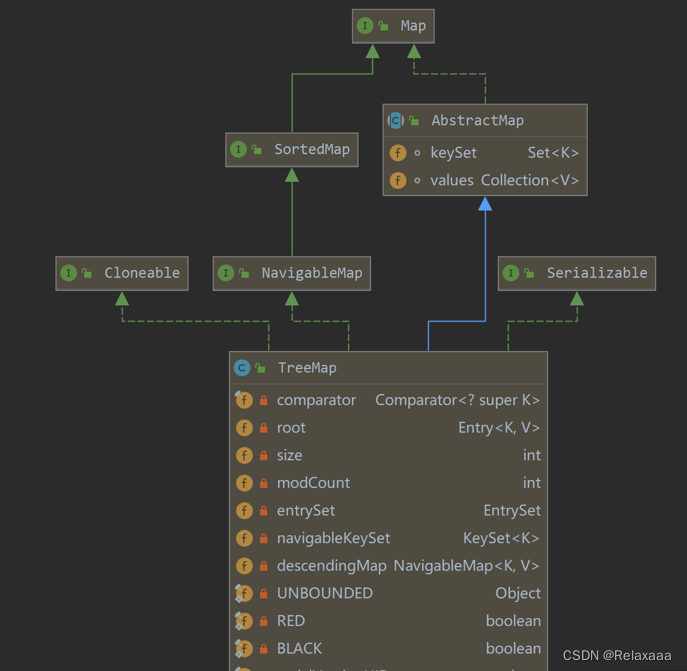
本质上就是
红黑树
的实现
1.每个节点要么是红色,要么是黑色。
2.根节点必须是黑色
3.每个叶子节点【NIL】是黑色
4.每个红色节点的两个子节点必须是黑色
5.任意节点到每个叶子节点的路径包含相同数量的黑节点
privatefinalComparator<?superK> comparator;// 比较器privatetransientEntry<K,V> root;// 根节点/**
* The number of entries in the tree
*/privatetransientint size =0;// map中元素的个数/**
* The number of structural modifications to the tree.
*/privatetransientint modCount =0;// 记录修改的次数
K key;// keyV value;// 值Entry<K,V> left;// 左子节点Entry<K,V> right;// 右子节点Entry<K,V> parent;// 父节点boolean color = BLACK;// 节点的颜色 默认是黑色
put为例
publicVput(K key,V value){// 将root赋值给局部变量 nullEntry<K,V> t = root;if(t ==null){// 初始操作// 检查key是否为空compare(key, key);// type (and possibly null) check// 将要添加的key、 value封装为一个Entry对象 并赋值给root
root =newEntry<>(key, value,null);
size =1;
modCount++;returnnull;}int cmp;Entry<K,V> parent;// 父节点// split comparator and comparable pathsComparator<?superK> cpr = comparator;// 获取比较器if(cpr !=null){// 一直找到插入节点的父节点do{// 将root赋值给了parent
parent = t;// 和root节点比较值得大小
cmp = cpr.compare(key, t.key);if(cmp <0)// 将父节点的左子节点付给了t
t = t.left;elseif(cmp >0)
t = t.right;// 将父节点的右节点付给了telse// 直接和父节点的key相等,直接修改值return t.setValue(value);}while(t !=null);}else{if(key ==null)thrownewNullPointerException();@SuppressWarnings("unchecked")Comparable<?superK> k =(Comparable<?superK>) key;do{
parent = t;
cmp = k.compareTo(t.key);if(cmp <0)
t = t.left;elseif(cmp >0)
t = t.right;elsereturn t.setValue(value);}while(t !=null);}// t 就是我们要插入节点的父节点 parent// 将我们要插入的key value 封装成了一个Entry对象Entry<K,V> e =newEntry<>(key, value, parent);if(cmp <0)
parent.left = e;// 插入的节点在parent节点的左侧else
parent.right = e;// 插入的节点在parent节点的右侧fixAfterInsertion(e);// 实现红黑树的平衡
size++;
modCount++;returnnull;}
/** From CLR */privatevoidfixAfterInsertion(Entry<K,V> x){// 设置添加节点的颜色为 红色
x.color = RED;// 循环的条件 添加的节点不为空 不是root节点 父节点的颜色为红色while(x !=null&& x != root && x.parent.color == RED){// 父节点是否是 祖父节点的左侧节点if(parentOf(x)==leftOf(parentOf(parentOf(x)))){// 获取父节点的 兄弟节点 叔叔节点Entry<K,V> y =rightOf(parentOf(parentOf(x)));if(colorOf(y)== RED){// 叔叔节点是红色// 变色setColor(parentOf(x), BLACK);// 设置 父节点的颜色为黑色setColor(y, BLACK);// 设置叔叔节点的颜色为 黑色setColor(parentOf(parentOf(x)), RED);// 设置 祖父节点的颜色是 红色// 将祖父节点设置为 插入节点
x =parentOf(parentOf(x));}else{// 叔叔节点是黑色if(x ==rightOf(parentOf(x))){// 判断插入节点是否是 父节点的右侧节点
x =parentOf(x);// 将父节点作为插入节点rotateLeft(x);// 左旋}setColor(parentOf(x), BLACK);setColor(parentOf(parentOf(x)), RED);rotateRight(parentOf(parentOf(x)));// 右旋}}else{// 父节点是祖父节点的右侧子节点// 获取叔叔节点Entry<K,V> y =leftOf(parentOf(parentOf(x)));if(colorOf(y)== RED){// 叔叔节点为红色// recolor 变色setColor(parentOf(x), BLACK);setColor(y, BLACK);setColor(parentOf(parentOf(x)), RED);
x =parentOf(parentOf(x));}else{// 插入节点在父节点的右侧if(x ==leftOf(parentOf(x))){
x =parentOf(x);rotateRight(x);// 右旋}setColor(parentOf(x), BLACK);setColor(parentOf(parentOf(x)), RED);rotateLeft(parentOf(parentOf(x)));// 左旋}}}// 根节点的颜色为黑色
root.color = BLACK;}
HashMap
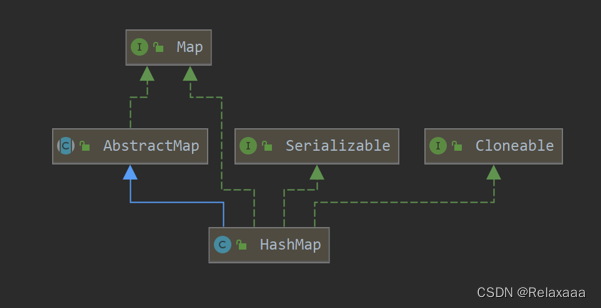
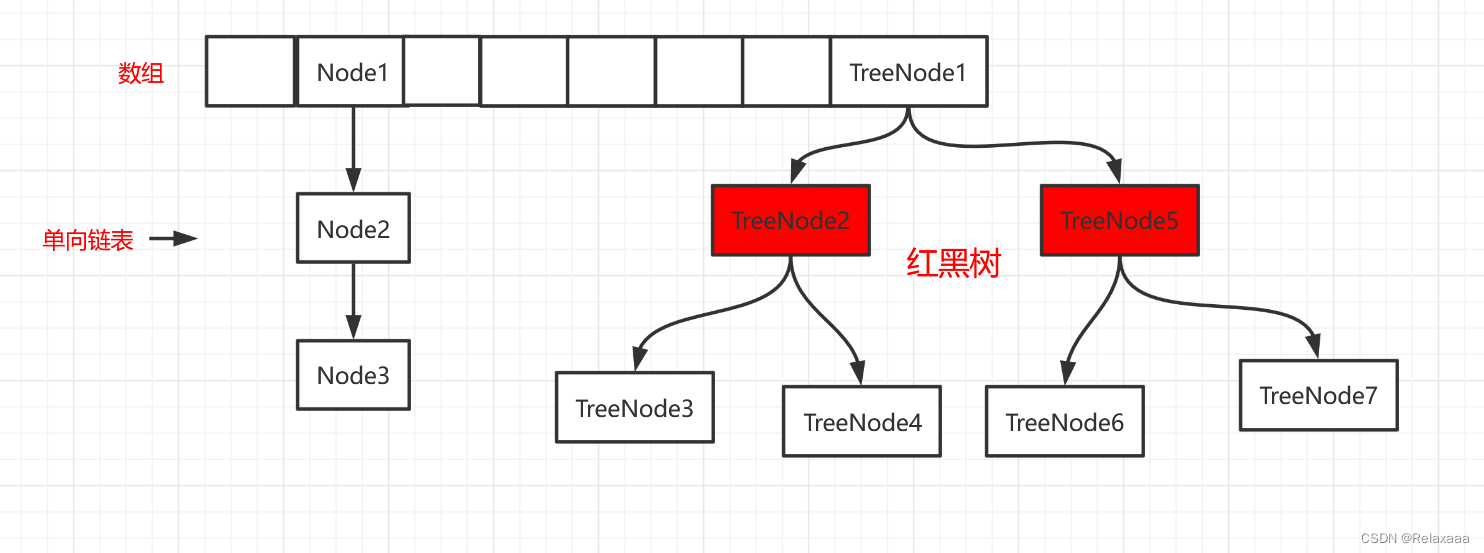
HashMap底层结构
Jdk1.7及以前是采用数组+链表
Jdk1.8之后 采用数组+链表 或者 数组+红黑树方式进行元素的存储
存储在hashMap集合中的元素都将是一个Map.Entry的内部接口的实现
// The default initial capacity - MUST be a power of two. //数组的容量 初始是16 必须是2的幂次方staticfinalint DEFAULT_INITIAL_CAPACITY =1<<4;// aka 16// HashMap中的数组的最大容量 staticfinalint MAXIMUM_CAPACITY =1<<30;// 默认的扩容的平衡因子staticfinalfloat DEFAULT_LOAD_FACTOR =0.75f;// 链表转红黑树的 临界值staticfinalint TREEIFY_THRESHOLD =8;// 红黑树转链表的 临界值staticfinalint UNTREEIFY_THRESHOLD =6// 链表转红黑树的数组长度的临界值 staticfinalint MIN_TREEIFY_CAPACITY =64;// HashMap中的数组结构transientNode<K,V>[] table;// HashMap中的元素个数transientint size;// 对HashMap操作的次数transientint modCount;// 扩容的临界值int threshold;// 实际的扩容值finalfloat loadFactor;
put方法原理分析
publicVput(K key,V value){returnputVal(hash(key), key, value,false,true);}
hash(key):获取key对应的hash值
staticfinalinthash(Object key){int h;// key.hashCode() 32长度的二进制的值return(key ==null)?0:(h = key.hashCode())^(h >>>16);}
为什么要右移16位?
A:1000010001110001000001111000000
B:0111011100111000101000010100000
A 和 B 对 15 11111&预算 得到的都是 0 相同,会造成散列分布不均匀
插入
finalVputVal(int hash,K key,V value,boolean onlyIfAbsent,boolean evict){Node<K,V>[] tab;Node<K,V> p;int n, i;if((tab = table)==null||(n = tab.length)==0)// 初始的判断// resize() 初始数组 扩容 初始的时候 获取了一个容量为16的数组
n =(tab =resize()).length;// n 数组长度// 确定插入的key在数组中的下标 15 11111// 100001000111000// 1111// 1000 = 8if((p = tab[i =(n -1)& hash])==null)// 通过hash值找到的数组的下标 里面没有内容就直接赋值
tab[i]=newNode(hash, key, value,null);else{Node<K,V> e;K k;if(p.hash == hash // hash值相同&& // key也相同((k = p.key)== key ||(key !=null&& key.equals(k))))// 插入的值的key 和 数组当前位置的 key是同一个 那么直接修改里面内容
e = p;elseif(p instanceofTreeNode)// 表示 数组中存放的节点是一个 红黑树节点
e =((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else{// 表示节点就是普通的链表for(int binCount =0;;++binCount){if((e = p.next)==null){// 到了链表的尾部
p.next =newNode(hash, key, value,null);// 将新的节点添加到了链表的尾部// 判断是否满足 链表转红黑树的条件if(binCount >= TREEIFY_THRESHOLD -1)// -1 for 1st// 转红黑树treeifyBin(tab, hash);break;}if(e.hash == hash &&((k = e.key)== key ||(key !=null&& key.equals(k))))break;
p = e;}}if(e !=null){// existing mapping for keyV oldValue = e.value;if(!onlyIfAbsent || oldValue ==null)
e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if(++size > threshold)resize();afterNodeInsertion(evict);returnnull;}
第一次resize()第一次执行时 创建了一个 Node[16] 扩容的临界值(12)
finalNode<K,V>[]resize(){// table = nullNode<K,V>[] oldTab = table;// oldCap = 0int oldCap =(oldTab ==null)?0: oldTab.length;// 原来的扩容因子 0int oldThr = threshold;// 新的容量和新的扩容因子int newCap, newThr =0;if(oldCap >0){// 初始不执行 0if(oldCap >= MAXIMUM_CAPACITY){
threshold =Integer.MAX_VALUE;return oldTab;}elseif((newCap = oldCap <<1)< MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr <<1;// double threshold}// 初始为0elseif(oldThr >0)// initial capacity was placed in threshold
newCap = oldThr;else{// 新的数组容量 16
newCap = DEFAULT_INITIAL_CAPACITY;// 新的扩容因子 0.75 * 16 = 12
newThr =(int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}if(newThr ==0){float ft =(float)newCap * loadFactor;
newThr =(newCap < MAXIMUM_CAPACITY && ft <(float)MAXIMUM_CAPACITY ?(int)ft :Integer.MAX_VALUE);}// 更新了 扩容的临界值 12
threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})// 创建了一个容量为16的Node数组Node<K,V>[] newTab =(Node<K,V>[])newNode[newCap];
table = newTab;// 更新了tableif(oldTab !=null){for(int j =0; j < oldCap;++j){Node<K,V> e;if((e = oldTab[j])!=null){
oldTab[j]=null;if(e.next ==null)
newTab[e.hash &(newCap -1)]= e;elseif(e instanceofTreeNode)((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else{// preserve orderNode<K,V> loHead =null, loTail =null;Node<K,V> hiHead =null, hiTail =null;Node<K,V> next;do{
next = e.next;if((e.hash & oldCap)==0){if(loTail ==null)
loHead = e;else
loTail.next = e;
loTail = e;}else{if(hiTail ==null)
hiHead = e;else
hiTail.next = e;
hiTail = e;}}while((e = next)!=null);if(loTail !=null){
loTail.next =null;
newTab[j]= loHead;}if(hiTail !=null){
hiTail.next =null;
newTab[j + oldCap]= hiHead;}}}}}return newTab;}
treeifyBin方法 如果数组的长度没有达到64 那么就尝试扩容 并不会转换为红黑树
finalvoidtreeifyBin(Node<K,V>[] tab,int hash){int n, index;Node<K,V> e;// tab为空 或者 数组的长度小于64if(tab ==null||(n = tab.length)< MIN_TREEIFY_CAPACITY)resize();// 扩容elseif((e = tab[index =(n -1)& hash])!=null){// 链表转红黑树的逻辑TreeNode<K,V> hd =null, tl =null;do{TreeNode<K,V> p =replacementTreeNode(e,null);if(tl ==null)
hd = p;else{
p.prev = tl;
tl.next = p;}
tl = p;}while((e = e.next)!=null);if((tab[index]= hd)!=null)
hd.treeify(tab);}}
动态扩容
finalNode<K,V>[]resize(){// [1,2,3,4,5,6,7,8,9,10,11,,,,]Node<K,V>[] oldTab = table;// 16int oldCap =(oldTab ==null)?0: oldTab.length;// 12int oldThr = threshold;int newCap, newThr =0;if(oldCap >0){if(oldCap >= MAXIMUM_CAPACITY){
threshold =Integer.MAX_VALUE;return oldTab;}// 新的容量是 原来容量的两倍elseif((newCap = oldCap <<1)< MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)// 扩容的临界值 原来的两倍 24
newThr = oldThr <<1;// double threshold}elseif(oldThr >0)// initial capacity was placed in threshold
newCap = oldThr;else{// zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr =(int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}if(newThr ==0){float ft =(float)newCap * loadFactor;
newThr =(newCap < MAXIMUM_CAPACITY && ft <(float)MAXIMUM_CAPACITY ?(int)ft :Integer.MAX_VALUE);}
threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})// 创建的数组的长度是32Node<K,V>[] newTab =(Node<K,V>[])newNode[newCap];
table = newTab;if(oldTab !=null){// 初始的时候是不需要复制的for(int j =0; j < oldCap;++j){Node<K,V> e;if((e = oldTab[j])!=null){
oldTab[j]=null;if(e.next ==null)// 数组中的元素就一个 找到元素在新的数组中的位置 赋值
newTab[e.hash &(newCap -1)]= e;elseif(e instanceofTreeNode)// 移动红黑树节点((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else{// preserve order// 普通的链表的移动Node<K,V> loHead =null, loTail =null;Node<K,V> hiHead =null, hiTail =null;Node<K,V> next;do{
next = e.next;if((e.hash & oldCap)==0){if(loTail ==null)
loHead = e;else
loTail.next = e;
loTail = e;}else{if(hiTail ==null)
hiHead = e;else
hiTail.next = e;
hiTail = e;}}while((e = next)!=null);if(loTail !=null){
loTail.next =null;
newTab[j]= loHead;}if(hiTail !=null){
hiTail.next =null;
newTab[j + oldCap]= hiHead;}}}}}return newTab;}
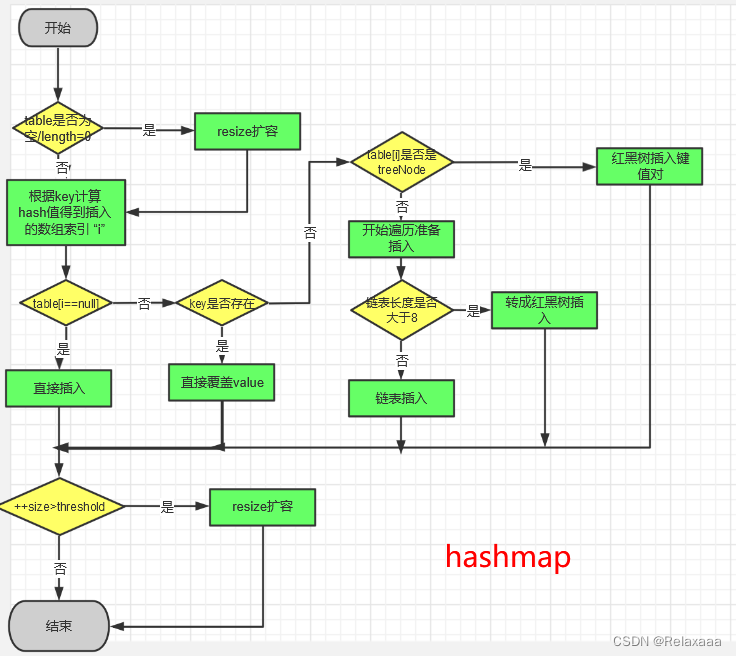
最后附图一张,方便理解。
如有错误请各位多多指正!
版权归原作者 Relaxaaa 所有, 如有侵权,请联系我们删除。