
SVM 支持向量机算法(Support Vector Machine )【Python机器学习系列(十四)】
文章目录
ʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞ


ʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞʚʕ̯•͡˔•̯᷅ʔɞ
大家好,我是侯小啾!
 今天分享的内容是支持向量机算法的逻辑,及其python实现。
今天分享的内容是支持向量机算法的逻辑,及其python实现。

1.SVM简介
在深度学习出现之前,支持向量机 被称为表现最好的算法。支持向量机算法适用于一些复杂数据的分类。现在更多用的是深度学习,深度学习的效果大于SVM。但是SVM作为经典算法,还是十分重要,是学习机器学习过程的必修内容。
SVM具有两个特点:1.适合小样本。2.数学逻辑优美。
支持向量机算法分为线性可分的支持向量机 和 非线性可分的支持向量机。
线性可分样本集:只要我们可以用一条直线可以把样本集的两类完全分开,就可以将其称为线性可分样本集。反之,称为非线性可分样本集。
支持向量机的超平面具有唯一性。可以分割样本数据的线(或超平面)存在有无数条,但是只有一条是最好的。找到这条线(或超平面),是支持向量机算法要做的。
SVM算法的目标即为:找到使分类间隔最小距离d 最大的超平面。
2. SVM 逻辑推导
2.1 Part1 化简限制条件
给定样本数据集,假设样本特征为X,样本标签为y。
每个样本的特征值可以展示为:
x
1
x_1
x1,
x
2
x_2
x2,
x
3
x_3
x3,…
x
n
x_n
xn。y 的取值只能有+1和-1.
欲将这些样本分为二类,则需要找到中间的超平面。该超平面表示为:
ω
T
x
+
b
=
0
\omega^Tx + b = 0
ωTx+b=0
其中
ω
\omega
ω 称为法向量,其决定了超平面的方向。
点到超平面的距离可以表示为
r
i
=
∣
ω
T
x
i
+
b
∣
∣
∣
ω
∣
∣
r_i = \frac{|\omega^Tx_i + b |}{||\omega||}
ri=∣∣ω∣∣∣ωTxi+b∣
这里的
x
i
x_i
xi指的不再是超平面上的点,而是样本点的向量。
以二维的情况中点与线的关系为例进行说明,假设有一个点 点A(m,n) 和一条线ax+by+c=0,则当点在线上时,直线的等号会刚好成立。当点分布于直线的两侧时,分别可写作am+bn+c>0,am+bn+c<0。多维情况下,也是同理。
再结合点到超平面的距离公式,
r
i
r_i
ri也可以写为:
r
i
=
ω
T
x
i
+
b
∣
∣
ω
∣
∣
y
i
r_i =\frac{\omega^Tx_i + b}{||\omega||}y_i
ri=∣∣ω∣∣ωTxi+byi
其中,位于超平面
ω
T
x
i
+
b
=
0
\omega^Tx_i + b = 0
ωTxi+b=0 左右的标签对应的y_i的正负不要设定反了,只有设定正确该公式才可以保证得到正值。不然的话保证得到的就会是负值。
然后就是要寻找 支持向量。支持向量是距离超平面最近的点的向量,分布在超平面的两边,所以这样的点至少有两个,即支持向量至少有两个。(至少左右各一个)。
我们下一步要做的,即:求
r
i
r_i
ri关于
x
i
x_i
xi的极小值,再求该极小值关于
ω
\omega
ω和
b
b
b的极大值。
对该距离公式的分子,
ω
T
x
i
+
b
\omega^Tx_i + b
ωTxi+b,即超平面的方程
ω
T
x
+
b
=
0
\omega^Tx + b = 0
ωTx+b=0 的一部分,考虑到超平立面的方程,就像二维的直线方程一样是可以放缩的(登号两边同乘以一个数),因此可以通过放缩,使得
ω
T
x
i
+
b
=
1
\omega^Tx_i + b =1
ωTxi+b=1成立。以此作为限制条件,这样就可以把分母消去了。
该约束条件可表示为
r
i
=
ω
T
x
i
+
b
∣
∣
ω
∣
∣
y
i
≥
1
∣
∣
ω
∣
∣
r_i =\frac{\omega^Tx_i + b}{||\omega||}y_i≥\frac{1}{||\omega||}
ri=∣∣ω∣∣ωTxi+byi≥∣∣ω∣∣1
提示:这里的限制条件只用了一个表达式表示,实际上有m个(m也是样本点的个数)。每个样本点对应一个限制条件。
当且仅目标当样本
x
i
x_i
xi为支持向量时,等号成立,取得点到超平面的最小距离
1
∣
∣
ω
∣
∣
\frac{1}{||\omega||}
∣∣ω∣∣1。
目标函数,即点到超平面的最小距离
1
∣
∣
ω
∣
∣
\frac{1}{||\omega||}
∣∣ω∣∣1。要使该最小距离最大化,即
∣
∣
ω
∣
∣
||\omega||
∣∣ω∣∣最小,为了后边计算方便,进一步将研究问题及表达式转化为,求
1
2
∣
∣
ω
∣
∣
2
\frac{1}{2}||\omega||^2
21∣∣ω∣∣2关于
ω
\omega
ω和
b
b
b的最小值。
目标函数即:
m
i
n
ω
,
b
1
2
∣
∣
ω
∣
∣
2
min_{\omega,b}\frac{1}{2}||\omega||^2
minω,b21∣∣ω∣∣2
进一步,限制条件可再转化为:
(
ω
T
x
i
+
b
)
y
i
−
1
≥
0
(\omega^Tx_i + b)y_i-1 ≥ 0
(ωTxi+b)yi−1≥0
2.2 Part2 SVM拉格朗日乘子法求解
现在我们已经得到了目标函数表达式与限制条件的表达式,可以使用拉格朗日乘子法对其进行求解。
构建拉格朗日函数表达式如下:
L
(
ω
,
b
,
λ
)
=
1
2
∣
∣
ω
∣
∣
2
+
∑
i
=
1
m
λ
i
[
1
−
(
ω
T
x
i
+
b
)
y
i
]
L(\omega,b,\lambda)=\frac{1}{2}||\omega||^2+\sum_{i=1}^{m}{\lambda_i}{[1-(\omega^Tx_i+b)y_i]}
L(ω,b,λ)=21∣∣ω∣∣2+∑i=1mλi[1−(ωTxi+b)yi]
=
1
2
ω
T
ω
+
∑
i
=
1
m
λ
i
[
1
−
(
ω
T
x
i
+
b
)
y
i
]
=\frac{1}{2}\omega^T \omega+\sum_{i=1}^{m}{\lambda_i}{[1-(\omega^Tx_i+b)y_i]}
=21ωTω+∑i=1mλi[1−(ωTxi+b)yi]
目标问题是一个凸二次规划问题:目标函数是二次型函数,且约束函数是仿射函数。所以该问题有全局最小值。
其中,
λ
\lambda
λ是拉格朗日乘子,这里的m是样本的个数,每个样本对应一个拉格朗日算子,共计m个拉格朗日算子,对应m个限制条件。
对
F
(
ω
,
b
,
λ
)
对F(\omega,b,\lambda)
对F(ω,b,λ)求关于
ω
\omega
ω 和
b
b
b的偏导,并令其为0,再求解:
∂
L
(
ω
,
b
,
λ
)
∂
ω
=
ω
−
∑
i
=
1
m
λ
i
y
i
x
i
=
0
\frac{∂L(\omega,b,\lambda)}{∂\omega}=\omega-\sum_{i=1}^{m}\lambda_iy_ix_i=0
∂ω∂L(ω,b,λ)=ω−∑i=1mλiyixi=0
∂
L
(
ω
,
b
,
λ
)
∂
b
=
−
∑
i
=
1
m
λ
i
y
i
=
0
\frac{∂L(\omega,b,\lambda)}{∂b}=-\sum_{i=1}^{m}\lambda_iy_i=0
∂b∂L(ω,b,λ)=−∑i=1mλiyi=0
解得
ω
=
∑
i
=
1
m
λ
i
y
i
x
i
\omega=\sum_{i=1}^{m}\lambda_iy_ix_i
ω=∑i=1mλiyixi
0
=
∑
i
=
1
m
λ
i
y
i
0=\sum_{i=1}^{m}\lambda_iy_i
0=∑i=1mλiyi
将求解结果带回原
L
(
ω
,
b
,
λ
)
L(\omega,b,\lambda)
L(ω,b,λ),并进一步化简得:
L
(
ω
,
b
,
λ
)
=
1
2
ω
T
ω
+
∑
i
=
1
m
λ
i
−
ω
T
∑
i
=
1
m
λ
i
y
i
x
i
−
b
∑
i
=
1
m
λ
i
y
i
L(\omega,b,\lambda)=\frac{1}{2}\omega^T \omega+\sum_{i=1}^{m}\lambda_i -\omega^T\sum_{i=1}^{m}\lambda_iy_ix_i-b\sum_{i=1}^{m}\lambda_iy_i
L(ω,b,λ)=21ωTω+∑i=1mλi−ωT∑i=1mλiyixi−b∑i=1mλiyi
=
∑
i
=
1
m
λ
i
−
1
2
ω
T
ω
=\sum_{i=1}^{m}\lambda_i-\frac{1}{2}\omega^T\omega
=∑i=1mλi−21ωTω
=
∑
i
=
1
m
λ
i
−
1
2
(
∑
i
=
1
m
λ
i
y
i
x
i
)
T
(
∑
i
=
1
m
λ
i
y
i
x
i
)
=\sum_{i=1}^{m}\lambda_i - \frac{1}{2}( \sum_{i=1}^{m}\lambda_iy_ix_i)^T (\sum_{i=1}^{m}\lambda_iy_ix_i)
=∑i=1mλi−21(∑i=1mλiyixi)T(∑i=1mλiyixi)
=
∑
i
=
1
m
λ
i
−
1
2
∑
i
=
1
m
∑
j
=
1
m
λ
i
λ
j
y
i
y
j
x
i
T
x
j
=\sum_{i=1}^{m}\lambda_i-\frac{1}{2}\sum_{i=1}^{m}\sum_{j=1}^{m}\lambda_i\lambda_jy_iy_jx_i^Tx_j
=∑i=1mλi−21∑i=1m∑j=1mλiλjyiyjxiTxj
上边已经说到,将这两个表达式带入
L
(
ω
,
b
,
λ
)
L(\omega,b,\lambda)
L(ω,b,λ)后,我们得到的新的表达式中已经没有了
ω
\omega
ω和
b
b
b,只剩下的参数为
λ
\lambda
λ,这个新表达式的限制条件即为我们带入的两个式子,这两个式子表示该表达式关于
ω
\omega
ω和
b
b
b的极小值。
进而求关于
λ
\lambda
λ的极值,到此要求解的函数已经转化为:
∑
i
=
1
m
λ
i
−
1
2
∑
i
=
1
m
∑
j
=
1
m
λ
i
λ
j
y
i
y
j
x
i
T
x
j
\sum_{i=1}^{m}\lambda_i-\frac{1}{2}\sum_{i=1}^{m}\sum_{j=1}^{m}\lambda_i\lambda_jy_iy_jx_i^Tx_j
∑i=1mλi−21∑i=1m∑j=1mλiλjyiyjxiTxj
要求解的是该式关于
λ
\lambda
λ的极大值,所以也即求解
1
2
∑
i
=
1
m
∑
j
=
1
m
λ
i
λ
j
y
i
y
j
x
i
T
x
j
−
∑
i
=
1
m
λ
i
\frac{1}{2}\sum_{i=1}^{m}\sum_{j=1}^{m}\lambda_i\lambda_jy_iy_jx_i^Tx_j-\sum_{i=1}^{m}\lambda_i
21∑i=1m∑j=1mλiλjyiyjxiTxj−∑i=1mλi
的极小值。
限制条件为:
s
.
t
.
s.t.
s.t.
∑
i
=
1
m
λ
i
y
i
=
0
\sum_{i=1}^{m}\lambda_iy_i=0
∑i=1mλiyi=0
λ
i
≥
0
\lambda_i≥0
λi≥0, i=1,2,…,m
2.3 Part3 求解超平面
目标函数:
m
i
n
ω
,
b
min_{\omega,b}
minω,b
1
2
∑
i
=
1
m
∑
j
=
1
m
λ
i
λ
j
y
i
y
j
x
i
T
x
j
−
∑
i
=
1
m
λ
i
\frac{1}{2}\sum_{i=1}^{m}\sum_{j=1}^{m}\lambda_i\lambda_jy_iy_jx_i^Tx_j-\sum_{i=1}^{m}\lambda_i
21∑i=1m∑j=1mλiλjyiyjxiTxj−∑i=1mλi
限制条件:
s
.
t
.
s.t.
s.t.
∑
i
=
1
m
λ
i
y
i
=
0
\sum_{i=1}^{m}\lambda_iy_i=0
∑i=1mλiyi=0
λ
i
≥
0
\lambda_i≥0
λi≥0, i=1,2,…,m
然后接下来,不难发现这是一个二次规划问题,将每个样本点的
x
i
x_i
xi、
y
i
y_i
yi替换为样本值数字,然后求目标函数关于
λ
1
\lambda_1
λ1,
λ
2
\lambda_2
λ2,… ,
λ
n
\lambda_n
λn的偏导数,并令其等于0,从而得到m个等式,联立这 m 个等式,以及
∑
i
=
1
m
λ
i
y
i
=
0
\sum_{i=1}^{m}\lambda_iy_i=0
∑i=1mλiyi=0进行求解。理论上即可以求出
λ
1
\lambda_1
λ1,
λ
2
\lambda_2
λ2,… ,
λ
n
\lambda_n
λn的值。
再将这些值代入表达式
ω
∗
=
∑
i
=
1
m
λ
i
y
i
x
i
\omega^*=\sum_{i=1}^{m}\lambda_iy_ix_i
ω∗=∑i=1mλiyixi 即可求解出
ω
∗
\omega^*
ω∗。(
ω
1
\omega_1
ω1,
ω
2
\omega_2
ω2, … ,
ω
n
\omega_n
ωn)
再由公式
b
∗
=
y
−
∑
i
=
1
m
λ
i
y
i
x
i
T
x
i
b^* =y-\sum_{i=1}^{m}\lambda_iy_ix_i^Tx_i
b∗=y−∑i=1mλiyixiTxi
代入支持向量,即可求得参数b的值。这是一种解方程的思路。但是这种方法过于繁琐,只是理论上可行。
在解决这个问题方面,先辈们提出了很多高效的算法,比如
SMO算法
(Sequential Minimal Optimization)。
使用梯度下降法,也可以如愿求得超平面的方程。
最后,根据下式(符号函数sgn)即可对样本数据进行分类:
f
(
x
)
=
s
g
n
(
ω
∗
T
x
+
b
∗
)
f(x)=sgn(\omega^{*T}x+b^*)
f(x)=sgn(ω∗Tx+b∗)
3.核函数
到此我们已经完整地实现了线性可分的支持向量机。但是现实中目标数据未必一直是线性可分的。面对这样的情况,我们可以使用 核函数 对原始目标数据进行“升维”操作。
如果原始数据是有限维的,那么一定会存在一个更高维的特征空间使得样本线性可分。
用
ϕ
(
x
)
\phi(x)
ϕ(x)表示
x
x
x经过映射后的特征向量,则核函数可以表示为
k
(
x
i
,
x
j
)
=
<
ϕ
(
x
i
)
,
ϕ
(
x
j
)
>
=
ϕ
(
x
i
)
T
ϕ
(
x
j
)
k(x_i,x_j)=<\phi(x_i),\phi(x_j)>=\phi(x_i)^T\phi(x_j)
k(xi,xj)=<ϕ(xi),ϕ(xj)>=ϕ(xi)Tϕ(xj)
核函数的具体形式我们通常是不知道的。
但是
核函数定理
表明,只要一个对称函数(
k
(
x
i
,
x
i
)
k(x_i,x_i)
k(xi,xi))对应的核矩阵半正定,它就能作为核函数使用。
几种常用的核函数如下:
核函数描述参数线性核
k
(
x
i
,
x
j
)
=
x
i
T
x
j
k(x_i,x_j)=x_i^Tx_j
k(xi,xj)=xiTxj无多项式核
k
(
x
i
,
x
j
)
=
(
x
i
T
x
j
)
d
k(x_i,x_j)=(x_i^Tx_j)^d
k(xi,xj)=(xiTxj)d
d
≥
1
d≥1
d≥1,表示多项式的次数高斯核
k
(
x
i
,
x
j
)
=
e
x
p
(
−
∣
∣
x
i
−
x
j
∣
∣
2
2
σ
2
)
k(x_i,x_j)=exp(-\frac{||x_i-x_j||^2}{2\sigma^2})
k(xi,xj)=exp(−2σ2∣∣xi−xj∣∣2)
σ
>
0
\sigma>0
σ>0,为高斯核的带宽(width)拉普拉斯核
k
(
x
i
,
x
j
)
=
e
x
p
(
−
∣
∣
x
i
−
x
j
∣
∣
σ
)
k(x_i,x_j)=exp(-\frac{||x_i-x_j||}{\sigma})
k(xi,xj)=exp(−σ∣∣xi−xj∣∣)
σ
>
0
\sigma>0
σ>0Sigmoid核
k
(
x
i
,
x
j
)
=
t
a
n
h
(
β
x
i
T
+
θ
)
k(x_i,x_j)=tanh(\beta x_i^T+\theta)
k(xi,xj)=tanh(βxiT+θ)tanh是双曲正切函数,
β
>
0
,
θ
<
0
\beta>0,\theta<0
β>0,θ<0
其中,高斯核函数,也称径向基函数(Radial Basis Function 简称RBF)。
此外,核函数也可以通过多个核函数与正数的线性组合得到,如
a
k
1
+
b
k
2
ak_1+bk_2
ak1+bk2;
也可以通过两个核函数的直积得到:
k
1
(
x
,
z
)
k
2
(
x
,
z
)
k_1(x,z)k_2(x,z)
k1(x,z)k2(x,z);
也可以通过任意函数g(x)得到:
g
(
x
)
k
1
(
x
,
z
)
g
(
z
)
g(x)k1(x,z)g(z)
g(x)k1(x,z)g(z)。
4. 软间隔支持向量机
线性可分支持向量机中的约束条件要求所有的样本都必须划分正确,这个间隔称为“硬间隔”。这也导致线性可分的支持向量机可能带来过拟合的问题,为了缓解这个问题,可以通过使用 软间隔 来允许支持向量机在对少数样本分类时出错。
于是,经过优化的目标函数可以写为:
m
i
n
ω
,
b
min_{\omega,b}
minω,b
1
2
∣
∣
ω
∣
∣
2
+
C
∑
i
=
1
m
φ
0
/
1
(
y
i
(
ω
T
x
i
+
b
)
−
1
)
\frac{1}{2}||\omega||^2+C\sum_{i=1}^{m}\varphi_{0/1}(y_i(\omega^Tx_i+b)-1)
21∣∣ω∣∣2+C∑i=1mφ0/1(yi(ωTxi+b)−1)
其中,C>0,C是一个常数。C越大,则分类的准确性就会越高,但是会因为过拟合导致,泛化能力会变差
C越小则分类的准确性会越低。
φ
0
/
1
\varphi_{0/1}
φ0/1是损失函数:
φ
0
/
1
(
z
)
=
{
1
,
i
f
z
<
0
;
0
,
o
t
h
e
r
w
i
s
e
\varphi_{0/1}(z)=\left\{ \begin{aligned} 1 &,& if\quad z<0; \\ 0&,&otherwise \end{aligned} \right.
φ0/1(z)={10,,ifz<0;otherwise
然而这个损失函数的性质不太好导致后续不易求解,所以可以使用“替代损失”函数,
三种常用的替代损失函数如下:
hinge损失:
φ
h
i
n
g
e
(
z
)
=
m
a
x
(
0
,
1
−
z
)
\varphi_{hinge}(z)=max(0,1-z)
φhinge(z)=max(0,1−z)
指数损失
φ
e
x
p
o
n
e
n
t
i
a
l
l
o
s
s
=
e
x
p
(
−
z
)
\varphi_{exponential loss}=exp(-z)
φexponentialloss=exp(−z)
对率损失
φ
l
o
g
i
s
t
i
c
l
o
s
s
=
l
o
g
(
1
+
e
x
p
(
−
z
)
)
\varphi_{logistic loss}=log(1+exp(-z))
φlogisticloss=log(1+exp(−z))
5. 支持向量回归 SVR
线性可分的支持向量机SVM通过求解出的超平面对数据进行分类,因此该算法不仅仅可以分类,也可以稍作迁移,当作回归算法来使用。求解超平面的过程,也即求解回归方程的过程,该过程被称为支持向量回归(SVR)。
显然,支持向量回归不同于传统的回归过程,传统的回归过程会计算所有回归值与真实值之间的损失,但是SVR则会假设一个
ϵ
\epsilon
ϵ作为一个偏差值,只有当真实值与回归值的差别绝对值大于
ϵ
\epsilon
ϵ时,才会计算损失。(即形成了一条“隔离带”,在隔离带外的点才计算损失)
6.python实现支持向量机
6.1 方法详解
sklearn.svm中提供了SVC, SVR,LinearSVC, LinearSVR, NuSVC, NuSVR, OneClassSVM, l1_min_c一系列类。
其中,SVC和SVR分别对应着通用的 支持向量机 和 支持向量回归,可以通过改变其参数来灵活应用。默认使用高斯核函数(即默认参数 kernel=“rbf”)。参数C即正则化常数,默认为1且大于0,正则化的程度与C成反比,C越大,则算法区域迫使所有样本满足约束,以至于可能导致过拟合;C取有限制时则会允许一些样本不满足约束。
其中,使用核函数时,参数kernel可用的值汇总如下:
参数值描述‘rbf’高斯核函数,也称径向基函数,是默认值‘linear’线性核函数‘poly’多项式核函数‘sigmoid’Sigmoid核函数‘precomputed’自定义核
LinearSVC, LinearSVR即为线性支持向量机,和线性支持向量回归,相当于是指定使用线性核的SVC和SVR。所以没有kernel参数,不能指定核函数。
NuSVC支持向量机,NuSVR支持向量回归,与SCV和SCR不同的是,NuSVC支持向量机和NuSVR支持向量回归没有参数C,但是有一个nu参数。
参数nu代表训练集训练的错误率的上限,或者说是支持向量的百分比下限,取值范围为(0,1],默认为0.5.它和惩罚系数C类似,都可以控制惩罚的力度。nu可以理解为是C的再参数化,在数学上是等效的。
此外,其默认也是使用rbf核函数(高斯核函数)。
类OneClassSVM实现了一个用于离群点检测的类;l1_min_c是用于计算C的下界,以便获得非“空”(所有特征权重为零)模型的。这里在这方面不做过多深入。
6.2 案例展示
使用支持向量机对葡萄酒数据进行分类为例,过程中使用线性核函数,且指定正则化常数C为2(默认为1)。算法的逻辑虽然有些复杂,但是代码非常简单。
from sklearn.svm import SVC
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
wine = load_wine()
x_data = wine.data
y_data = wine.target
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, random_state=1)
model = SVC(C=2, kernel='linear')
model.fit(x_train, y_train)
test_score = model.score(x_test,y_test)
pred = model.predict(x_test)print('模型得分:{:.3f}'.format(model.score(x_test, y_test)))print(pred)
模型得分与预测结果如下图所示: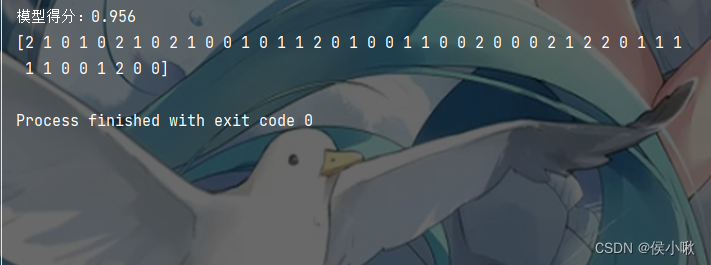
本次分享就到这里,小啾感谢您的关注与支持!
🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ
本专栏更多好文欢迎点击下方连接:
1.初识机器学习前导内容_你需要知道的基本概念罗列_以PY为工具 【Python机器学习系列(一)】
2.sklearn库数据标准预处理合集_【Python机器学习系列(二)】
3.K_近邻算法_分类Ionosphere电离层数据【python机器学习系列(三)】
4.python机器学习 一元线性回归 梯度下降法的实现 【Python机器学习系列(四)】
5.sklearn实现一元线性回归 【Python机器学习系列(五)】
6.多元线性回归_梯度下降法实现【Python机器学习系列(六)】
7.sklearn实现多元线性回归 【Python机器学习系列(七)】
8.sklearn实现多项式线性回归_一元/多元 【Python机器学习系列(八)】
9.逻辑回归原理梳理_以python为工具 【Python机器学习系列(九)】
10.sklearn实现逻辑回归_以python为工具【Python机器学习系列(十)】
11.决策树专题_以python为工具【Python机器学习系列(十一)】
12.文本特征提取专题_以python为工具【Python机器学习系列(十二)】
13.朴素贝叶斯分类器_以python为工具【Python机器学习系列(十三)】
版权归原作者 侯小啾 所有, 如有侵权,请联系我们删除。