
前言

一年一度的中秋节就快到了,平台也有各种各样的中秋发文活动,正在翻阅时偶然间我看到了这篇文章:《兔饼大作战》:吃月饼、见月亮,还能咬自己?| 欢庆中秋特制版 - 掘金 (juejin.cn)
大家肯定比较熟悉了,这个游戏的内核就是贪吃蛇,作者也是对玩法做了很多调整,趣味性十足,同时加入兔饼、月亮等元素增加节日氛围,可以说创意性十足
于是我就想可不可以针对这个游戏进行其他方面的创新,比如针对贪吃蛇 AI 算法进行探索和改进,下面就是算法训练的最终效果
注:博主能力有限,因此本文剔除掉了上面文章中添加的难度提升、增添元素等游戏设置,只保留贪吃蛇最基本的游戏架构,后期可能会调整
深度强化学习
前言
我们可以使用深度强化学习(Deep Reinforcement Learning,Deep RL)算法,也可以使用贝叶斯优化(Bayesian Optimization)来优化深度强化学习算法
强化学习:机器学习的分支,相较于机器学习经典的有监督学习、无监督学习问题,强化学习最大的特点是在交互中学习(Learning from Interaction)。Agent 在与环境的交互中根据获得的奖励或惩罚不断的学习知识,更加适应环境。RL学习的范式非常类似于我们人类学习知识的过程,也正因此,RL 被视为实现通用 AI 重要途径。
贝叶斯优化:用于优化黑盒函数的方法,它通过在搜索空间中选择最有可能包含全局最优解的点来逐步改进模型。核心思想是结合贝叶斯统计和高斯过程回归
我们所熟知的 AlphaGo 就是基于深度强化学习进行训练的,核心过程是使用蒙特卡洛树搜索(Monte Carlo tree search),借助估值网络(value network)与走棋网络(policy network)这两种深度神经网络,通过估值网络来评估大量选点,并通过走棋网络选择落点。其余的算法应用包括广告推荐、对话系统、机器人工程等,此处不赘述
形式化定义强化学习问题最常用的表示方式是马尔科夫决策过程。这就引出我们的最终游戏 AI 算法 —— Deep Q-Learning(DQN)算法,DQN 是深度强化学习的一种具体实现方式
游戏定义

snake 是一条线,当吃到食物时会增加得分以及 snake 的长度,当 snake 撞墙或撞到自己时,游戏结束。得分就是游戏者所吃食物的数量,因为 snake 的大小会随着所吃食物的增加而边长,因此到后期游戏会越来越难,玩家的目标是在不结束游戏的情况下让蛇吃尽可能多的食物。
环境与状态空间
snake 游戏的环境可以用
n×n
的矩阵表示。矩阵中的每个
cell
可用
l×l
表示,为此状态空间的维度为
s∈(n×n×l×l)
,为了使游戏简单,直接忽略
l×l
,为此状态空间可用
s∈n×n
表示(仍然是指数增长)。
动作空间
对于 snake,只能采取四种动作:
up, down, left, right
。
为了加速训练以及减少向后碰撞,可以将动作简化为:
straight, clockwise turn, counter-clockwise turn
。
这种方式表示动作是有益的,因为当 agent “探索”并随机选择一个动作时,它不会180度地改变自己。
正负奖励
游戏的主要奖励是当 snake 吃了食物并增加它的分数。因此,奖励直接与游戏的最终分数挂钩,这与人类判断奖励的方式类似。
有了其他积极的奖励,智能体可能会无限循环,或者学会完全避免食物以最小化 snake 长度。
此外,加入了负面奖励,让 snake 获得更多关于其状态的信息:**碰撞检测(与自身或墙壁),循环(不鼓励无限循环),empty cell,以及离食物 close/mid/far/very_far (鼓励通往食物)**。
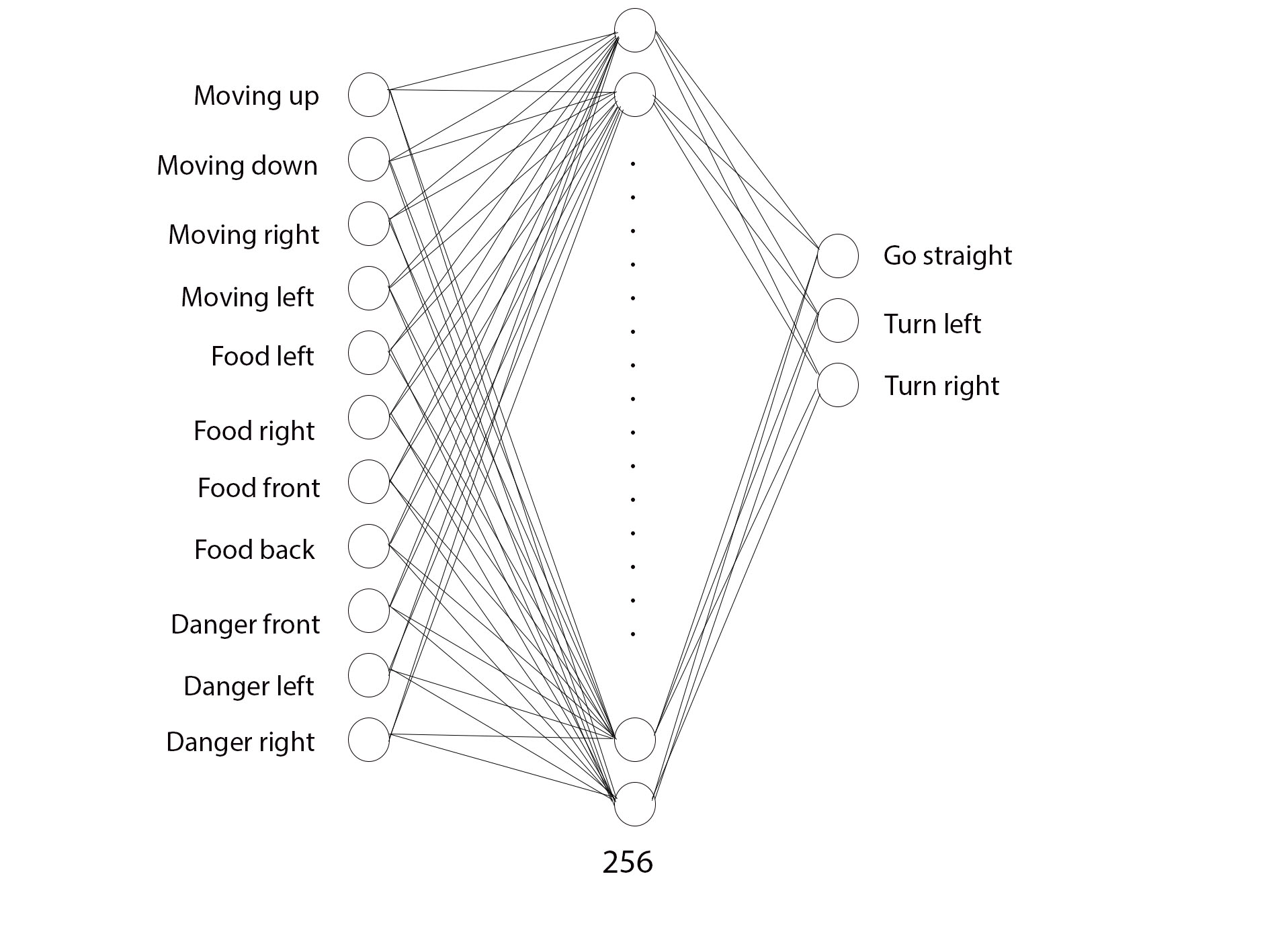
DQN网络定义
定义一个网络,其中输入层大小为11,用于定义 snake 的当前状态,隐藏层大小为256个节点,输出层大小为3,用于确定采取何种操作。下图是网络的一个可视化表示。
由于游戏是离散时间步长(帧),能够为游戏的每个新帧计算一个新状态。
将状态参数定义为11个布尔值,这些值基于 snake 的移动方向,将危险的位置定义为下一帧中可能发生的碰撞,以及相对于 snake 的食物位置。
3个动作是 snake 相对于它面对的方向移动的方向:
forward, left, right
。注意这里网络的输出是3个动作的Q估计值。
每个时间步的状态被传递给Q-Learning网络,网络对它认为的最佳行动做出预测。这些信息会同时保存在短期记忆和长期记忆中。从之前的状态中学到的所有信息都可以从记忆中提取出来,并传递给网络以继续训练过程。
消融实验
Robert Long对消融研究(或消融实验)定义:通常用于神经网络,尤其是相对复杂的神经网络,如R-CNN。通过删除部分网络并研究网络的性能来了解网络。
“消融”的原始含义是手术切除身体组织。“消融研究”这一术语的根源于20世纪60年代和70年代的实验心理学领域,其中动物的大脑部分被移除以研究其对其行为的影响。在机器学习,特别是复杂的深度神经网络的背景下,已经采用“消融研究”来描述去除网络的某些部分的过程,以便更好地理解网络的行为。
可以简单理解为控制变量法。
参考项目
maurock/snake-ga: AI Agent that learns how to play Snake with Deep Q-Learning (github.com)
sourenaKhanzadeh/snakeAi: Reinforcement Learning with the classic snake game (github.com)
这两个项目均是采用 DQN 算法,但是第一个仓库安装依赖有些问题,同时操作系统也不同,故采用第二个仓库(如果大家感兴趣的话也可以尝试下第一个项目)
# 创建环境
conda create -n snk-ai-py3.7 python=3.7
# 拉取代码
git clone [email protected]:sourenaKhanzadeh/snakeAi.git
# 安装依赖
pip install -r requirements.txt
最后运行代码
python python main.py
注意:博主使用的服务器是没有桌面的,直接使用的 SSH 连接,对于如何使用 SSH 连接来传输 GUI 画面可以参考博主往期文章(VSCode『SSH』连接服务器『GUI界面』传输)
遗传算法
参考项目:Ackeraa/snake: Snake AI with Genetic algorithm and Neural network (github.com)
注:父级参考项目:Chrispresso/SnakeAI (github.com)
两个项目差别不大,可以直接使用父级参考项目,本次使用子项目演示,原理是使用遗传算法和简单神经网络的方式实现贪吃蛇寻路算法
快速开始
git clone [email protected]:Ackeraa/snake.git
pip install -r requirements.txt
# 无画面训练(推荐)
python main.py
# 有画面训练
python main.py -s
可以直接调节
settings.py
中的参数,其中
FPS
训练时可以调大,训练更快,展示的时候调小,便于展示
# 训练
FPS = 1000
# 展示
FPS = 8
这里不浪费时间从头训练,而是直接使用训练好的 genes ,方便展示
python main.py -i -s
如果您想要从头训练,需要先执行如下命令删除权重文件再训练
rm -rf genes/best/*
rm -rf genes/best/*
rm -rf seed/*
效果演示
最后补充
作者能力有限,没法讲解所有算法,这里提供一些仓库(亲测可用),大家可自行探索
哈密尔顿 / 贪心
仓库地址:chuyangliu/snake: Artificial intelligence for the Snake game. (github.com)
仓库简介:主要使用 Hamilton(哈密尔顿算法),Greedy(贪心算法),DQN 算法(实验性功能),同时实现了用户友好的GUI和算法实现的简单性
多层感知机 / 卷积神经网络
仓库地址:snake-ai/README_CN.md at master · linyiLYi/snake-ai (github.com)
仓库简介:本项目为林亦大佬开发,B 站上也有介绍视频,有兴趣的小伙伴可以跳转到此,本项目是经典游戏《贪吃蛇》的程序脚本以及可以自动进行游戏的人工智能代理。该智能代理基于深度强化学习进行训练,包括两个版本:基于多层感知机(Multi-Layer Perceptron)的代理和基于卷积神经网络(Convolution Neural Network)的代理,其中后者的平均游戏分数更高。
注意:林亦大佬的这个项目适配 Windows 和 Mac 系统,请注意使用
神经网络 + 遗传算法
仓库地址:greerviau/SnakeAI: Train a Neural Network to play Snake using a Genetic Algorithm (github.com)
参考链接
greerviau/SnakeAI: Train a Neural Network to play Snake using a Genetic Algorithm (github.com)
snake-ai/README_CN.md at master · linyiLYi/snake-ai (github.com)
chuyangliu/snake: Artificial intelligence for the Snake game. (github.com)
maurock/snake-ga: AI Agent that learns how to play Snake with Deep Q-Learning (github.com)
深度学习与CV教程(17) | 深度强化学习 (马尔可夫决策过程,Q-Learning,DQN) (showmeai.tech)
【强化学习】基于DQN实现贪吃蛇(pytorch版) - 知乎 (zhihu.com)
版权归原作者 ReturnTmp 所有, 如有侵权,请联系我们删除。