
实验6:目标检测算法
一:实验目的与要求
1:了解两阶段目标检测模型 RCNN或Faster RCNN模型的原理和结构。
2:学习通过RCNN或Faster RCNN模型解决目标检测问题。
二:实验内容
常用的深度学习框架包括PyTorch和PaddlePaddle等,请选择一种深度学习框架,完成后续实验。
2.1 RCNN模型简介
区域卷积神经网络(RCNN)系列模型为两阶段目标检测器,包含对图像生成候选区域,提取特征,判别特征类别并修正候选框位置等几个步骤。 RCNN系列目前包含两个代表模型:Faster RCNN和Mask RCNN。
Faster RCNN 整体网络可以分为4个主要内容:
1、基础卷积层。作为一种卷积神经网络目标检测方法,Faster RCNN首先使用一组基础的卷积网络提取图像的特征图。特征图被后续 区域生成网络RPN层和全连接层共享。本示例采用ResNet-50作为基础卷积层。
2、区域生成网络(RPN)。RPN网络用于生成候选区域(proposals)。该层通过一组固定的尺寸和比例得到一组锚点(anchors), 通过softmax判断锚点属于前景或者背景,再利用区域回归修正锚点从而获得精确的候选区域。
3、RoI Align。该层收集输入的特征图和候选区域,将候选区域映射到特征图中并池化为统一大小的区域特征图,送入全连接层判定目标类别, 该层可选用RoIPool和RoIAlign两种方式,在config.py中设置roi_func。
4、检测层。利用区域特征图计算候选区域的类别,同时再次通过区域回归获得检测框最终的精确位置。
2.2 数据集
实验提供了昆虫数据集和螺丝螺母检测数据集供同学们在实验中使用,同学们也可以结合自身研究,使用其它真实数据集进行实验。

三:实验资源
1.Faster RCNN模型实验代码。
- 参考paddle版本代码:
Faster RCNN目标检测 - 飞桨AI Studio星河社区
3:螺丝螺母数据集和昆虫数据集。
四:实验要求
1、阅读目标检测算法的相关论文,理解两阶段目标检测的主要思想。
2、结合目标检测算法的相关论文https://arxiv.org/abs/1506.01497,补充完成参考代码(或自选框架实现),实现目标检测算法(Faster RCNN)。
3、通过昆虫数据集、螺丝螺母检测数据集或自选数据集验证模型效果,并进行对比分析。
4、根据上述要求,撰写实验报告。
五:实验环境
本实验所使用的环境条件如下表所示。
操作系统
Ubuntu(Linux)
程序语言
Python(3.11.4)
第三方依赖
numpy, matplotlib,pytorch,openmmlab等
六:算法流程
两阶段(two-stage)目标检测模型通常由两个阶段组成:区域提议(Region Proposal)和目标分类与定位(Object Classification and Localization)。
【1】区域提议
(1)步骤:
- 输入图像:将待检测的图像输入模型。
- 特征提取:使用预训练的卷积神经网络(CNN)对输入图像进行特征提取,例如VGG、ResNet等。
- 生成候选框:在提取的特征图上使用滑动窗口或者其他方法生成候选目标框,这些框是可能包含目标的区域。
(2)输出:生成的候选目标框
【2】目标分类与定位
(1)步骤:
- 候选框裁剪:对于每个候选目标框,从原始图像中提取相应的区域。
- 特征提取与调整:将提取的候选框区域输入到CNN中,进行特征提取,并进行必要的调整以适应分类和定位的任务。
- 目标分类:使用softmax分类器对提取的特征进行目标分类,确定候选框内是否包含目标物体。
- 边界框回归:对于被分类为目标的候选框,进一步使用回归器来调整其位置,以更准确地定位目标的边界框。
(2)输出:每个目标框的类别标签和边界框位置调整参数。
七:实验展示
本实验所用的数据集来源于URP《基于机器视觉的智慧选种研究》,数据集包括广泛种植在中国的6类大米的显微镜拍摄图像,共计约有30000张大米图像。
【1】Faster RCNN
训练过程中,各类参数的设置如下:batch_size为16,backbone为resnet,neck为fpn,optimizer为SGD,学习速率为0.02,动量为0.9,权重衰减为0.0001,迭代次数为12,计算目标定位的损失函数为平滑L1损失,计算目标分类的损失函数为交叉熵损失。
12次迭代的训练时间约为6小时,训练过程中的验证集mAP结果如下所示。
(1)平均精度(mAP),无检测框的置信度限制

(2)平均精度(mAP),限制检测框的置信度大于等于0.5

(3)平均精度(mAP),限制检测框的置信度大于等于0.75

(4)平均精度(mAP),目标的尺寸范围为大尺寸(large)

图(1)到图(4)的mAP数据如下图所示。

采用OOD数据集的测试结果如下图所示。

放大结果如下图所示。

【2】TridentNet
训练过程中,各类参数的设置类似Faster RCNN。
训练过程中的验证集mAP结果如下所示。
(1)平均精度(mAP),无检测框的置信度限制

(2)平均精度(mAP),限制检测框的置信度大于等于0.5

(3)平均精度(mAP),限制检测框的置信度大于等于0.75
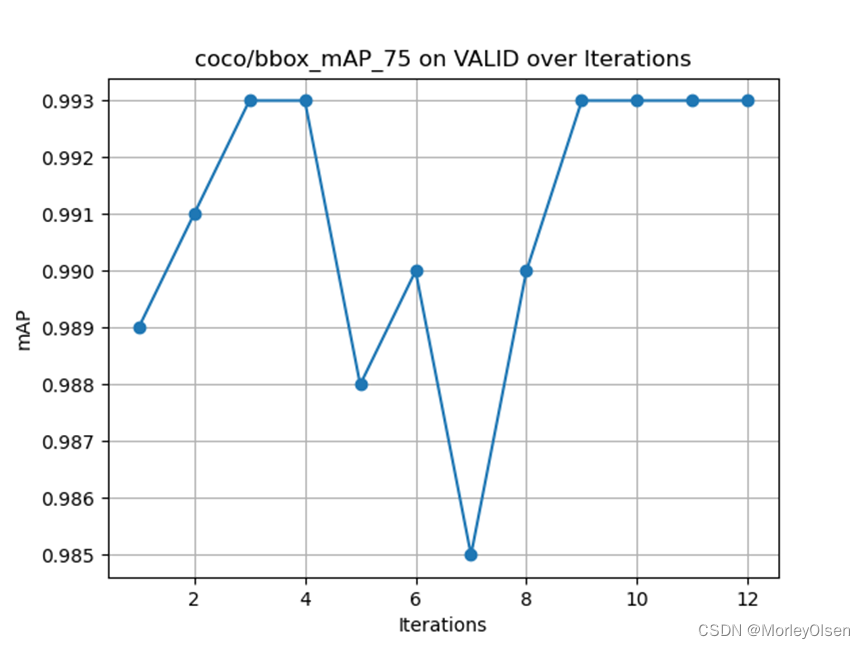
(4)平均精度(mAP),目标的尺寸范围为大尺寸(large)

图(1)到图(4)的mAP数据如下图所示。

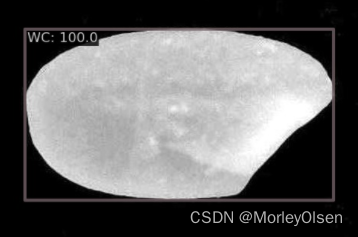
采用OOD数据集的测试结果如下图所示。

放大结果如下图所示。
八:实验结论与心得
1:两阶段目标检测模型主要具备以下几个特点:
(1)区域提议阶段:通过在图像上生成候选目标框,提高了效率,减少了需要处理的区域数量。
(2)目标分类与定位阶段:对提取的候选框进行分类和位置调整,以确定目标物体的类别并准确地定位其边界框。
(3)端到端训练:整个模型通常采用端到端的方式进行训练,通过联合优化区域提议和目标分类与定位的任务来学习模型参数。
2:在两阶段目标检测模型中,代表性的模型包括Faster R-CNN、R-CNN、Mask R-CNN等。
3:在目标检测中,评估目标检测模型的性能包括准确率、召回率、平均精确度(mAP)等指标。
4:TridentNet最初由微软亚洲研究院提出,是一种两阶段的目标检测模型,其设计旨在提高检测器对小目标和长尾类别的检测性能。
5:TridentNet模型主要具备以下几个特点:
(1)多尺度检测:引入了三个并行的检测分支,每个分支专注于检测不同尺度的目标,使得在检测小目标和大目标时都能保持高效性。
(2)语义上下文信息:引入了一种新的上下文引导模块(Context Guided Module),用于利用图像语义上下文信息来增强目标检测。
(3)级联检测:级联检测器由一系列级联的子检测器组成,每个子检测器在前一个阶段的基础上进一步筛选和优化目标框,从而提高最终的检测精度。
6:mAP 表示平均精度,它是在不同类别上的平均准确率(Precision)值。通常情况下,这个值是在所有目标尺寸范围内计算的平均精度。
7:在coco/bbox_mAP_s、coco/bbox_mAP_m、coco/bbox_mAP_l中,s、m、l 分别代表小尺寸(small)、中尺寸(medium)、大尺寸(large)目标。这些指标用于衡量模型在不同尺寸范围内目标的检测性能。
九:主要代码
绘图
打开文本文件
root = '/home/ubuntu/mmdetection-main/work_dirs/faster_rcnn_r50_fpn_1x_coco/20240421_074656/20240421_074656.log'
withopen(root, 'r') asfile:
lines = file.readlines()
初始化存储数值的列表
map1 = [] # coco/bbox_mAP
map2 = [] # coco/bbox_mAP_50
map3 = [] # coco/bbox_mAP_75
map4 = [] # coco/bbox_mAP_l
遍历每一行文本,提取数值
forlineinlines:
if'coco/bbox_mAP'inline:
values = line.split('coco/bbox_mAP: ') # 使用split方法分割字符串,并获取数值部分
iflen(values) > 1:
value_str = values[1].strip().split()[0]
map1.append(float(value_str)) # 将数值转换为浮点数并添加到列表中
values = line.split('coco/bbox_mAP_50: ') # 使用split方法分割字符串,并获取数值部分
iflen(values) > 1:
value_str = values[1].strip().split()[0]
map2.append(float(value_str)) # 将数值转换为浮点数并添加到列表中
values = line.split('coco/bbox_mAP_75: ') # 使用split方法分割字符串,并获取数值部分
iflen(values) > 1:
value_str = values[1].strip().split()[0]
map3.append(float(value_str)) # 将数值转换为浮点数并添加到列表中
values = line.split('coco/bbox_mAP_l: ') # 使用split方法分割字符串,并获取数值部分
iflen(values) > 1:
value_str = values[1].strip().split()[0]
map4.append(float(value_str)) # 将数值转换为浮点数并添加到列表中
print(map1)
print(map2)
print(map3)
print(map4)
importmatplotlib.pyplotasplt
获取模型迭代次数(假设为每迭代一次记录一次)
iterations = range(1, len(map1) + 1)
绘制图像
plt.plot(iterations, map1, marker='o')
plt.xlabel('Iterations')
plt.ylabel('mAP')
plt.title('coco/bbox_mAP on VALID over Iterations')
plt.grid(True)
plt.savefig('map1.png')
plt.close()
plt.plot(iterations, map2, marker='o')
plt.xlabel('Iterations')
plt.ylabel('mAP')
plt.title('coco/bbox_mAP_50 on VALID over Iterations')
plt.grid(True)
plt.savefig('map2.png')
plt.close()
plt.plot(iterations, map3, marker='o')
plt.xlabel('Iterations')
plt.ylabel('mAP')
plt.title('coco/bbox_mAP_75 on VALID over Iterations')
plt.grid(True)
plt.savefig('map3.png')
plt.close()
plt.plot(iterations, map4, marker='o')
plt.xlabel('Iterations')
plt.ylabel('mAP')
plt.title('coco/bbox_mAP_l on VALID over Iterations')
plt.grid(True)
plt.savefig('map4.png')
plt.close()
"""
map1 = [] # coco/bbox_mAP
map2 = [] # coco/bbox_mAP_50
map3 = [] # coco/bbox_mAP_75
map4 = [] # coco/bbox_mAP_l
"""
Backbone:ResNet
Copyright (c) OpenMMLab. All rights reserved.
importwarnings
importtorch.nnasnn
importtorch.utils.checkpointascp
from mmcv.cnn import build_conv_layer, build_norm_layer, build_plugin_layer
frommmengine.modelimportBaseModule
fromtorch.nn.modules.batchnormimport_BatchNorm
frommmdet.registryimportMODELS
from ..layersimportResLayer
classBasicBlock(BaseModule):
expansion = 1
def__init__(self,
inplanes,
planes,
stride=1,
dilation=1,
downsample=None,
style='pytorch',
with_cp=False,
conv_cfg=None,
norm_cfg=dict(type='BN'),
dcn=None,
plugins=None,
init_cfg=None):
super(BasicBlock, self).__init__(init_cfg)
assertdcnisNone, 'Not implemented yet.'
assertpluginsisNone, 'Not implemented yet.'
self.norm1_name, norm1 = build_norm_layer(norm_cfg, planes, postfix=1)
self.norm2_name, norm2 = build_norm_layer(norm_cfg, planes, postfix=2)
self.conv1 = build_conv_layer(
conv_cfg,
inplanes,
planes,
3,
stride=stride,
padding=dilation,
dilation=dilation,
bias=False)
self.add_module(self.norm1_name, norm1)
self.conv2 = build_conv_layer(
conv_cfg, planes, planes, 3, padding=1, bias=False)
self.add_module(self.norm2_name, norm2)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
self.dilation = dilation
self.with_cp = with_cp
@property
defnorm1(self):
"""nn.Module: normalization layer after the first convolution layer"""
returngetattr(self, self.norm1_name)
@property
defnorm2(self):
"""nn.Module: normalization layer after the second convolution layer"""
returngetattr(self, self.norm2_name)
defforward(self, x):
"""Forward function."""
def_inner_forward(x):
identity = x
out = self.conv1(x)
out = self.norm1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.norm2(out)
ifself.downsampleisnotNone:
identity = self.downsample(x)
out += identity
returnout
ifself.with_cpandx.requires_grad:
out = cp.checkpoint(_inner_forward, x)
else:
out = _inner_forward(x)
out = self.relu(out)
returnout
classBottleneck(BaseModule):
expansion = 4
def__init__(self,
inplanes,
planes,
stride=1,
dilation=1,
downsample=None,
style='pytorch',
with_cp=False,
conv_cfg=None,
norm_cfg=dict(type='BN'),
dcn=None,
plugins=None,
init_cfg=None):
"""Bottleneck block for ResNet.
If style is "pytorch", the stride-two layer is the 3x3 conv layer, if
it is "caffe", the stride-two layer is the first 1x1 conv layer.
"""
super(Bottleneck, self).__init__(init_cfg)
assertstylein ['pytorch', 'caffe']
assertdcnisNoneorisinstance(dcn, dict)
assertpluginsisNoneorisinstance(plugins, list)
ifpluginsisnotNone:
allowed_position = ['after_conv1', 'after_conv2', 'after_conv3']
assertall(p['position'] inallowed_positionforpinplugins)
self.inplanes = inplanes
self.planes = planes
self.stride = stride
self.dilation = dilation
self.style = style
self.with_cp = with_cp
self.conv_cfg = conv_cfg
self.norm_cfg = norm_cfg
self.dcn = dcn
self.with_dcn = dcnisnotNone
self.plugins = plugins
self.with_plugins = pluginsisnotNone
ifself.with_plugins:
# collect plugins for conv1/conv2/conv3
self.after_conv1_plugins = [
plugin['cfg'] forplugininplugins
ifplugin['position'] == 'after_conv1'
]
self.after_conv2_plugins = [
plugin['cfg'] forplugininplugins
ifplugin['position'] == 'after_conv2'
]
self.after_conv3_plugins = [
plugin['cfg'] forplugininplugins
ifplugin['position'] == 'after_conv3'
]
ifself.style == 'pytorch':
self.conv1_stride = 1
self.conv2_stride = stride
else:
self.conv1_stride = stride
self.conv2_stride = 1
self.norm1_name, norm1 = build_norm_layer(norm_cfg, planes, postfix=1)
self.norm2_name, norm2 = build_norm_layer(norm_cfg, planes, postfix=2)
self.norm3_name, norm3 = build_norm_layer(
norm_cfg, planes * self.expansion, postfix=3)
self.conv1 = build_conv_layer(
conv_cfg,
inplanes,
planes,
kernel_size=1,
stride=self.conv1_stride,
bias=False)
self.add_module(self.norm1_name, norm1)
fallback_on_stride = False
ifself.with_dcn:
fallback_on_stride = dcn.pop('fallback_on_stride', False)
ifnotself.with_dcnorfallback_on_stride:
self.conv2 = build_conv_layer(
conv_cfg,
planes,
planes,
kernel_size=3,
stride=self.conv2_stride,
padding=dilation,
dilation=dilation,
bias=False)
else:
assertself.conv_cfgisNone, 'conv_cfg must be None for DCN'
self.conv2 = build_conv_layer(
dcn,
planes,
planes,
kernel_size=3,
stride=self.conv2_stride,
padding=dilation,
dilation=dilation,
bias=False)
self.add_module(self.norm2_name, norm2)
self.conv3 = build_conv_layer(
conv_cfg,
planes,
planes * self.expansion,
kernel_size=1,
bias=False)
self.add_module(self.norm3_name, norm3)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
ifself.with_plugins:
self.after_conv1_plugin_names = self.make_block_plugins(
planes, self.after_conv1_plugins)
self.after_conv2_plugin_names = self.make_block_plugins(
planes, self.after_conv2_plugins)
self.after_conv3_plugin_names = self.make_block_plugins(
planes * self.expansion, self.after_conv3_plugins)
defmake_block_plugins(self, in_channels, plugins):
"""make plugins for block.
Args:
in_channels (int): Input channels of plugin.
plugins (list[dict]): List of plugins cfg to build.
Returns:
list[str]: List of the names of plugin.
"""
assertisinstance(plugins, list)
plugin_names = []
forplugininplugins:
plugin = plugin.copy()
name, layer = build_plugin_layer(
plugin,
in_channels=in_channels,
postfix=plugin.pop('postfix', ''))
assertnothasattr(self, name), f'duplicate plugin {name}'
self.add_module(name, layer)
plugin_names.append(name)
returnplugin_names
defforward_plugin(self, x, plugin_names):
out = x
fornameinplugin_names:
out = getattr(self, name)(out)
returnout
@property
defnorm1(self):
"""nn.Module: normalization layer after the first convolution layer"""
returngetattr(self, self.norm1_name)
@property
defnorm2(self):
"""nn.Module: normalization layer after the second convolution layer"""
returngetattr(self, self.norm2_name)
@property
defnorm3(self):
"""nn.Module: normalization layer after the third convolution layer"""
returngetattr(self, self.norm3_name)
defforward(self, x):
"""Forward function."""
def_inner_forward(x):
identity = x
out = self.conv1(x)
out = self.norm1(out)
out = self.relu(out)
ifself.with_plugins:
out = self.forward_plugin(out, self.after_conv1_plugin_names)
out = self.conv2(out)
out = self.norm2(out)
out = self.relu(out)
ifself.with_plugins:
out = self.forward_plugin(out, self.after_conv2_plugin_names)
out = self.conv3(out)
out = self.norm3(out)
ifself.with_plugins:
out = self.forward_plugin(out, self.after_conv3_plugin_names)
ifself.downsampleisnotNone:
identity = self.downsample(x)
out += identity
returnout
ifself.with_cpandx.requires_grad:
out = cp.checkpoint(_inner_forward, x)
else:
out = _inner_forward(x)
out = self.relu(out)
returnout
@MODELS.register_module()
classResNet(BaseModule):
"""ResNet backbone.
Args:
depth (int): Depth of resnet, from {18, 34, 50, 101, 152}.
stem_channels (int | None): Number of stem channels. If not specified,
it will be the same as `base_channels`. Default: None.
base_channels (int): Number of base channels of res layer. Default: 64.
in_channels (int): Number of input image channels. Default: 3.
num_stages (int): Resnet stages. Default: 4.
strides (Sequence[int]): Strides of the first block of each stage.
dilations (Sequence[int]): Dilation of each stage.
out_indices (Sequence[int]): Output from which stages.
style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
layer is the 3x3 conv layer, otherwise the stride-two layer is
the first 1x1 conv layer.
deep_stem (bool): Replace 7x7 conv in input stem with 3 3x3 conv
avg_down (bool): Use AvgPool instead of stride conv when
downsampling in the bottleneck.
frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
-1 means not freezing any parameters.
norm_cfg (dict): Dictionary to construct and config norm layer.
norm_eval (bool): Whether to set norm layers to eval mode, namely,
freeze running stats (mean and var). Note: Effect on Batch Norm
and its variants only.
plugins (list[dict]): List of plugins for stages, each dict contains:
- cfg (dict, required): Cfg dict to build plugin.
- position (str, required): Position inside block to insert
plugin, options are 'after_conv1', 'after_conv2', 'after_conv3'.
- stages (tuple[bool], optional): Stages to apply plugin, length
should be same as 'num_stages'.
with_cp (bool): Use checkpoint or not. Using checkpoint will save some
memory while slowing down the training speed.
zero_init_residual (bool): Whether to use zero init for last norm layer
in resblocks to let them behave as identity.
pretrained (str, optional): model pretrained path. Default: None
init_cfg (dict or list[dict], optional): Initialization config dict.
Default: None
Example:
>>> from mmdet.models import ResNet
>>> import torch
>>> self = ResNet(depth=18)
>>> self.eval()
>>> inputs = torch.rand(1, 3, 32, 32)
>>> level_outputs = self.forward(inputs)
>>> for level_out in level_outputs:
... print(tuple(level_out.shape))
(1, 64, 8, 8)
(1, 128, 4, 4)
(1, 256, 2, 2)
(1, 512, 1, 1)
"""
arch_settings = {
18: (BasicBlock, (2, 2, 2, 2)),
34: (BasicBlock, (3, 4, 6, 3)),
50: (Bottleneck, (3, 4, 6, 3)),
101: (Bottleneck, (3, 4, 23, 3)),
152: (Bottleneck, (3, 8, 36, 3))
}
def__init__(self,
depth,
in_channels=3,
stem_channels=None,
base_channels=64,
num_stages=4,
strides=(1, 2, 2, 2),
dilations=(1, 1, 1, 1),
out_indices=(0, 1, 2, 3),
style='pytorch',
deep_stem=False,
avg_down=False,
frozen_stages=-1,
conv_cfg=None,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
dcn=None,
stage_with_dcn=(False, False, False, False),
plugins=None,
with_cp=False,
zero_init_residual=True,
pretrained=None,
init_cfg=None):
super(ResNet, self).__init__(init_cfg)
self.zero_init_residual = zero_init_residual
ifdepthnotinself.arch_settings:
raiseKeyError(f'invalid depth {depth} for resnet')
block_init_cfg = None
assertnot (init_cfgandpretrained), \
'init_cfg and pretrained cannot be specified at the same time'
ifisinstance(pretrained, str):
warnings.warn('DeprecationWarning: pretrained is deprecated, '
'please use "init_cfg" instead')
self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
elifpretrainedisNone:
ifinit_cfgisNone:
self.init_cfg = [
dict(type='Kaiming', layer='Conv2d'),
dict(
type='Constant',
val=1,
layer=['_BatchNorm', 'GroupNorm'])
]
block = self.arch_settings[depth][0]
ifself.zero_init_residual:
ifblockisBasicBlock:
block_init_cfg = dict(
type='Constant',
val=0,
override=dict(name='norm2'))
elifblockisBottleneck:
block_init_cfg = dict(
type='Constant',
val=0,
override=dict(name='norm3'))
else:
raiseTypeError('pretrained must be a str or None')
self.depth = depth
ifstem_channelsisNone:
stem_channels = base_channels
self.stem_channels = stem_channels
self.base_channels = base_channels
self.num_stages = num_stages
assertnum_stages >= 1andnum_stages <= 4
self.strides = strides
self.dilations = dilations
assertlen(strides) == len(dilations) == num_stages
self.out_indices = out_indices
assertmax(out_indices) < num_stages
self.style = style
self.deep_stem = deep_stem
self.avg_down = avg_down
self.frozen_stages = frozen_stages
self.conv_cfg = conv_cfg
self.norm_cfg = norm_cfg
self.with_cp = with_cp
self.norm_eval = norm_eval
self.dcn = dcn
self.stage_with_dcn = stage_with_dcn
ifdcnisnotNone:
assertlen(stage_with_dcn) == num_stages
self.plugins = plugins
self.block, stage_blocks = self.arch_settings[depth]
self.stage_blocks = stage_blocks[:num_stages]
self.inplanes = stem_channels
self._make_stem_layer(in_channels, stem_channels)
self.res_layers = []
fori, num_blocksinenumerate(self.stage_blocks):
stride = strides[i]
dilation = dilations[i]
dcn = self.dcnifself.stage_with_dcn[i] elseNone
ifpluginsisnotNone:
stage_plugins = self.make_stage_plugins(plugins, i)
else:
stage_plugins = None
planes = base_channels * 2**i
res_layer = self.make_res_layer(
block=self.block,
inplanes=self.inplanes,
planes=planes,
num_blocks=num_blocks,
stride=stride,
dilation=dilation,
style=self.style,
avg_down=self.avg_down,
with_cp=with_cp,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
dcn=dcn,
plugins=stage_plugins,
init_cfg=block_init_cfg)
self.inplanes = planes * self.block.expansion
layer_name = f'layer{i + 1}'
self.add_module(layer_name, res_layer)
self.res_layers.append(layer_name)
self._freeze_stages()
self.feat_dim = self.block.expansion * base_channels * 2**(
len(self.stage_blocks) - 1)
defmake_stage_plugins(self, plugins, stage_idx):
"""Make plugins for ResNet ``stage_idx`` th stage.
Currently we support to insert ``context_block``,
``empirical_attention_block``, ``nonlocal_block`` into the backbone
like ResNet/ResNeXt. They could be inserted after conv1/conv2/conv3 of
Bottleneck.
An example of plugins format could be:
Examples:
>>> plugins=[
... dict(cfg=dict(type='xxx', arg1='xxx'),
... stages=(False, True, True, True),
... position='after_conv2'),
... dict(cfg=dict(type='yyy'),
... stages=(True, True, True, True),
... position='after_conv3'),
... dict(cfg=dict(type='zzz', postfix='1'),
... stages=(True, True, True, True),
... position='after_conv3'),
... dict(cfg=dict(type='zzz', postfix='2'),
... stages=(True, True, True, True),
... position='after_conv3')
... ]
>>> self = ResNet(depth=18)
>>> stage_plugins = self.make_stage_plugins(plugins, 0)
>>> assert len(stage_plugins) == 3
Suppose ``stage_idx=0``, the structure of blocks in the stage would be:
.. code-block:: none
conv1-> conv2->conv3->yyy->zzz1->zzz2
Suppose 'stage_idx=1', the structure of blocks in the stage would be:
.. code-block:: none
conv1-> conv2->xxx->conv3->yyy->zzz1->zzz2
If stages is missing, the plugin would be applied to all stages.
Args:
plugins (list[dict]): List of plugins cfg to build. The postfix is
required if multiple same type plugins are inserted.
stage_idx (int): Index of stage to build
Returns:
list[dict]: Plugins for current stage
"""
stage_plugins = []
forplugininplugins:
plugin = plugin.copy()
stages = plugin.pop('stages', None)
assertstagesisNoneorlen(stages) == self.num_stages
# whether to insert plugin into current stage
ifstagesisNoneorstages[stage_idx]:
stage_plugins.append(plugin)
returnstage_plugins
defmake_res_layer(self, **kwargs):
"""Pack all blocks in a stage into a ``ResLayer``."""
returnResLayer(**kwargs)
@property
defnorm1(self):
"""nn.Module: the normalization layer named "norm1" """
returngetattr(self, self.norm1_name)
def_make_stem_layer(self, in_channels, stem_channels):
ifself.deep_stem:
self.stem = nn.Sequential(
build_conv_layer(
self.conv_cfg,
in_channels,
stem_channels // 2,
kernel_size=3,
stride=2,
padding=1,
bias=False),
build_norm_layer(self.norm_cfg, stem_channels // 2)[1],
nn.ReLU(inplace=True),
build_conv_layer(
self.conv_cfg,
stem_channels // 2,
stem_channels // 2,
kernel_size=3,
stride=1,
padding=1,
bias=False),
build_norm_layer(self.norm_cfg, stem_channels // 2)[1],
nn.ReLU(inplace=True),
build_conv_layer(
self.conv_cfg,
stem_channels // 2,
stem_channels,
kernel_size=3,
stride=1,
padding=1,
bias=False),
build_norm_layer(self.norm_cfg, stem_channels)[1],
nn.ReLU(inplace=True))
else:
self.conv1 = build_conv_layer(
self.conv_cfg,
in_channels,
stem_channels,
kernel_size=7,
stride=2,
padding=3,
bias=False)
self.norm1_name, norm1 = build_norm_layer(
self.norm_cfg, stem_channels, postfix=1)
self.add_module(self.norm1_name, norm1)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
def_freeze_stages(self):
ifself.frozen_stages >= 0:
ifself.deep_stem:
self.stem.eval()
forparaminself.stem.parameters():
param.requires_grad = False
else:
self.norm1.eval()
formin [self.conv1, self.norm1]:
forparaminm.parameters():
param.requires_grad = False
foriinrange(1, self.frozen_stages + 1):
m = getattr(self, f'layer{i}')
m.eval()
forparaminm.parameters():
param.requires_grad = False
defforward(self, x):
"""Forward function."""
ifself.deep_stem:
x = self.stem(x)
else:
x = self.conv1(x)
x = self.norm1(x)
x = self.relu(x)
x = self.maxpool(x)
outs = []
fori, layer_nameinenumerate(self.res_layers):
res_layer = getattr(self, layer_name)
x = res_layer(x)
ifiinself.out_indices:
outs.append(x)
returntuple(outs)
deftrain(self, mode=True):
"""Convert the model into training mode while keep normalization layer
freezed."""
super(ResNet, self).train(mode)
self._freeze_stages()
ifmodeandself.norm_eval:
forminself.modules():
# trick: eval have effect on BatchNorm only
ifisinstance(m, _BatchNorm):
m.eval()
@MODELS.register_module()
classResNetV1d(ResNet):
r"""ResNetV1d variant described in `Bag of Tricks
<https://arxiv.org/pdf/1812.01187.pdf>`_.
Compared with default ResNet(ResNetV1b), ResNetV1d replaces the 7x7 conv in
the input stem with three 3x3 convs. And in the downsampling block, a 2x2
avg_pool with stride 2 is added before conv, whose stride is changed to 1.
"""
def__init__(self, **kwargs):
super(ResNetV1d, self).__init__(
deep_stem=True, avg_down=True, **kwargs)
Neck:fpn
Copyright (c) OpenMMLab. All rights reserved.
fromtypingimportList, Tuple, Union
importtorch.nnasnn
importtorch.nn.functionalasF
from mmcv.cnn import ConvModule
frommmengine.modelimportBaseModule
fromtorchimportTensor
frommmdet.registryimportMODELS
frommmdet.utilsimportConfigType, MultiConfig, OptConfigType
@MODELS.register_module()
classFPN(BaseModule):
r"""Feature Pyramid Network.
This is an implementation of paper `Feature Pyramid Networks for Object
Detection <https://arxiv.org/abs/1612.03144>`_.
Args:
in_channels (list[int]): Number of input channels per scale.
out_channels (int): Number of output channels (used at each scale).
num_outs (int): Number of output scales.
start_level (int): Index of the start input backbone level used to
build the feature pyramid. Defaults to 0.
end_level (int): Index of the end input backbone level (exclusive) to
build the feature pyramid. Defaults to -1, which means the
last level.
add_extra_convs (bool | str): If bool, it decides whether to add conv
layers on top of the original feature maps. Defaults to False.
If True, it is equivalent to `add_extra_convs='on_input'`.
If str, it specifies the source feature map of the extra convs.
Only the following options are allowed
- 'on_input': Last feat map of neck inputs (i.e. backbone feature).
- 'on_lateral': Last feature map after lateral convs.
- 'on_output': The last output feature map after fpn convs.
relu_before_extra_convs (bool): Whether to apply relu before the extra
conv. Defaults to False.
no_norm_on_lateral (bool): Whether to apply norm on lateral.
Defaults to False.
conv_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
convolution layer. Defaults to None.
norm_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
normalization layer. Defaults to None.
act_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
activation layer in ConvModule. Defaults to None.
upsample_cfg (:obj:`ConfigDict` or dict, optional): Config dict
for interpolate layer. Defaults to dict(mode='nearest').
init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
dict]): Initialization config dict.
Example:
>>> import torch
>>> in_channels = [2, 3, 5, 7]
>>> scales = [340, 170, 84, 43]
>>> inputs = [torch.rand(1, c, s, s)
... for c, s in zip(in_channels, scales)]
>>> self = FPN(in_channels, 11, len(in_channels)).eval()
>>> outputs = self.forward(inputs)
>>> for i in range(len(outputs)):
... print(f'outputs[{i}].shape = {outputs[i].shape}')
outputs[0].shape = torch.Size([1, 11, 340, 340])
outputs[1].shape = torch.Size([1, 11, 170, 170])
outputs[2].shape = torch.Size([1, 11, 84, 84])
outputs[3].shape = torch.Size([1, 11, 43, 43])
"""
def__init__(
self,
in_channels: List[int],
out_channels: int,
num_outs: int,
start_level: int = 0,
end_level: int = -1,
add_extra_convs: Union[bool, str] = False,
relu_before_extra_convs: bool = False,
no_norm_on_lateral: bool = False,
conv_cfg: OptConfigType = None,
norm_cfg: OptConfigType = None,
act_cfg: OptConfigType = None,
upsample_cfg: ConfigType = dict(mode='nearest'),
init_cfg: MultiConfig = dict(
type='Xavier', layer='Conv2d', distribution='uniform')
) -> None:
super().__init__(init_cfg=init_cfg)
assertisinstance(in_channels, list)
self.in_channels = in_channels
self.out_channels = out_channels
self.num_ins = len(in_channels)
self.num_outs = num_outs
self.relu_before_extra_convs = relu_before_extra_convs
self.no_norm_on_lateral = no_norm_on_lateral
self.fp16_enabled = False
self.upsample_cfg = upsample_cfg.copy()
ifend_level == -1orend_level == self.num_ins - 1:
self.backbone_end_level = self.num_ins
assertnum_outs >= self.num_ins - start_level
else:
# if end_level is not the last level, no extra level is allowed
self.backbone_end_level = end_level + 1
assertend_level < self.num_ins
assertnum_outs == end_level - start_level + 1
self.start_level = start_level
self.end_level = end_level
self.add_extra_convs = add_extra_convs
assertisinstance(add_extra_convs, (str, bool))
ifisinstance(add_extra_convs, str):
# Extra_convs_source choices: 'on_input', 'on_lateral', 'on_output'
assertadd_extra_convsin ('on_input', 'on_lateral', 'on_output')
elifadd_extra_convs: # True
self.add_extra_convs = 'on_input'
self.lateral_convs = nn.ModuleList()
self.fpn_convs = nn.ModuleList()
foriinrange(self.start_level, self.backbone_end_level):
l_conv = ConvModule(
in_channels[i],
out_channels,
1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfgifnotself.no_norm_on_lateralelseNone,
act_cfg=act_cfg,
inplace=False)
fpn_conv = ConvModule(
out_channels,
out_channels,
3,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg,
inplace=False)
self.lateral_convs.append(l_conv)
self.fpn_convs.append(fpn_conv)
# add extra conv layers (e.g., RetinaNet)
extra_levels = num_outs - self.backbone_end_level + self.start_level
ifself.add_extra_convsandextra_levels >= 1:
foriinrange(extra_levels):
ifi == 0andself.add_extra_convs == 'on_input':
in_channels = self.in_channels[self.backbone_end_level - 1]
else:
in_channels = out_channels
extra_fpn_conv = ConvModule(
in_channels,
out_channels,
3,
stride=2,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg,
inplace=False)
self.fpn_convs.append(extra_fpn_conv)
defforward(self, inputs: Tuple[Tensor]) -> tuple:
"""Forward function.
Args:
inputs (tuple[Tensor]): Features from the upstream network, each
is a 4D-tensor.
Returns:
tuple: Feature maps, each is a 4D-tensor.
"""
assertlen(inputs) == len(self.in_channels)
# build laterals
laterals = [
lateral_conv(inputs[i + self.start_level])
fori, lateral_convinenumerate(self.lateral_convs)
]
# build top-down path
used_backbone_levels = len(laterals)
foriinrange(used_backbone_levels - 1, 0, -1):
# In some cases, fixing `scale factor` (e.g. 2) is preferred, but
# it cannot co-exist with `size` in `F.interpolate`.
if'scale_factor'inself.upsample_cfg:
# fix runtime error of "+=" inplace operation in PyTorch 1.10
laterals[i - 1] = laterals[i - 1] + F.interpolate(
laterals[i], **self.upsample_cfg)
else:
prev_shape = laterals[i - 1].shape[2:]
laterals[i - 1] = laterals[i - 1] + F.interpolate(
laterals[i], size=prev_shape, **self.upsample_cfg)
# build outputs
# part 1: from original levels
outs = [
self.fpn_convs[i](laterals[i]) foriinrange(used_backbone_levels)
]
# part 2: add extra levels
ifself.num_outs > len(outs):
# use max pool to get more levels on top of outputs
# (e.g., Faster R-CNN, Mask R-CNN)
ifnotself.add_extra_convs:
foriinrange(self.num_outs - used_backbone_levels):
outs.append(F.max_pool2d(outs[-1], 1, stride=2))
# add conv layers on top of original feature maps (RetinaNet)
else:
ifself.add_extra_convs == 'on_input':
extra_source = inputs[self.backbone_end_level - 1]
elifself.add_extra_convs == 'on_lateral':
extra_source = laterals[-1]
elifself.add_extra_convs == 'on_output':
extra_source = outs[-1]
else:
raiseNotImplementedError
outs.append(self.fpn_convs[used_backbone_levels](extra_source))
foriinrange(used_backbone_levels + 1, self.num_outs):
ifself.relu_before_extra_convs:
outs.append(self.fpn_convs[i](F.relu(outs[-1])))
else:
outs.append(self.fpn_convs[i](outs[-1]))
returntuple(outs)
参数文件
auto_scale_lr = dict(base_batch_size=16, enable=False)
backend_args = None
data_root = 'data/coco/'
dataset_type = 'mmdet.datasets.CocoDataset'
default_hooks = dict(
checkpoint=dict(interval=1, type='mmengine.hooks.CheckpointHook'),
logger=dict(interval=50, type='mmengine.hooks.LoggerHook'),
param_scheduler=dict(type='mmengine.hooks.ParamSchedulerHook'),
sampler_seed=dict(type='mmengine.hooks.DistSamplerSeedHook'),
timer=dict(type='mmengine.hooks.IterTimerHook'),
visualization=dict(type='mmdet.engine.hooks.DetVisualizationHook'))
default_scope = None
env_cfg = dict(
cudnn_benchmark=False,
dist_cfg=dict(backend='nccl'),
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0))
launcher = 'none'
load_from = None
log_level = 'INFO'
log_processor = dict(
by_epoch=True, type='mmengine.runner.LogProcessor', window_size=50)
model = dict(
backbone=dict(
depth=50,
frozen_stages=1,
init_cfg=dict(checkpoint='torchvision://resnet50', type='Pretrained'),
norm_cfg=dict(requires_grad=True, type='torch.nn.BatchNorm2d'),
norm_eval=True,
num_stages=4,
out_indices=(
0,
1,
2,
3,
),
style='pytorch',
type='mmdet.models.backbones.resnet.ResNet'),
data_preprocessor=dict(
bgr_to_rgb=True,
mean=[
123.675,
116.28,
103.53,
],
pad_size_divisor=32,
std=[
58.395,
57.12,
57.375,
],
type=
'mmdet.models.data_preprocessors.data_preprocessor.DetDataPreprocessor'
),
neck=dict(
in_channels=[
256,
512,
1024,
2048,
],
num_outs=5,
out_channels=256,
type='mmdet.models.necks.fpn.FPN'),
roi_head=dict(
bbox_head=dict(
bbox_coder=dict(
target_means=[
0.0,
0.0,
0.0,
0.0,
],
target_stds=[
0.1,
0.1,
0.2,
0.2,
],
type=
'mmdet.models.task_modules.coders.delta_xywh_bbox_coder.DeltaXYWHBBoxCoder'
),
fc_out_channels=1024,
in_channels=256,
loss_bbox=dict(
loss_weight=1.0,
type='mmdet.models.losses.smooth_l1_loss.L1Loss'),
loss_cls=dict(
loss_weight=1.0,
type='mmdet.models.losses.cross_entropy_loss.CrossEntropyLoss',
use_sigmoid=False),
num_classes=80,
reg_class_agnostic=False,
roi_feat_size=7,
type=
'mmdet.models.roi_heads.bbox_heads.convfc_bbox_head.Shared2FCBBoxHead'
),
bbox_roi_extractor=dict(
featmap_strides=[
4,
8,
16,
32,
],
out_channels=256,
roi_layer=dict(
output_size=7, sampling_ratio=0, type='mmcv.ops.RoIAlign'),
type=
'mmdet.models.roi_heads.roi_extractors.single_level_roi_extractor.SingleRoIExtractor'
),
type='mmdet.models.roi_heads.standard_roi_head.StandardRoIHead'),
rpn_head=dict(
anchor_generator=dict(
ratios=[
0.5,
1.0,
2.0,
],
scales=[
8,
],
strides=[
4,
8,
16,
32,
64,
],
type=
'mmdet.models.task_modules.prior_generators.anchor_generator.AnchorGenerator'
),
bbox_coder=dict(
target_means=[
0.0,
0.0,
0.0,
0.0,
],
target_stds=[
1.0,
1.0,
1.0,
1.0,
],
type=
'mmdet.models.task_modules.coders.delta_xywh_bbox_coder.DeltaXYWHBBoxCoder'
),
feat_channels=256,
in_channels=256,
loss_bbox=dict(
loss_weight=1.0, type='mmdet.models.losses.smooth_l1_loss.L1Loss'),
loss_cls=dict(
loss_weight=1.0,
type='mmdet.models.losses.cross_entropy_loss.CrossEntropyLoss',
use_sigmoid=True),
type='mmdet.models.dense_heads.rpn_head.RPNHead'),
test_cfg=dict(
rcnn=dict(
max_per_img=100,
nms=dict(iou_threshold=0.5, type='mmcv.ops.nms'),
score_thr=0.05),
rpn=dict(
max_per_img=1000,
min_bbox_size=0,
nms=dict(iou_threshold=0.7, type='mmcv.ops.nms'),
nms_pre=1000)),
train_cfg=dict(
rcnn=dict(
assigner=dict(
ignore_iof_thr=-1,
match_low_quality=False,
min_pos_iou=0.5,
neg_iou_thr=0.5,
pos_iou_thr=0.5,
type=
'mmdet.models.task_modules.assigners.max_iou_assigner.MaxIoUAssigner'
),
debug=False,
pos_weight=-1,
sampler=dict(
add_gt_as_proposals=True,
neg_pos_ub=-1,
num=512,
pos_fraction=0.25,
type=
'mmdet.models.task_modules.samplers.random_sampler.RandomSampler'
)),
rpn=dict(
allowed_border=-1,
assigner=dict(
ignore_iof_thr=-1,
match_low_quality=True,
min_pos_iou=0.3,
neg_iou_thr=0.3,
pos_iou_thr=0.7,
type=
'mmdet.models.task_modules.assigners.max_iou_assigner.MaxIoUAssigner'
),
debug=False,
pos_weight=-1,
sampler=dict(
add_gt_as_proposals=False,
neg_pos_ub=-1,
num=256,
pos_fraction=0.5,
type=
'mmdet.models.task_modules.samplers.random_sampler.RandomSampler'
)),
rpn_proposal=dict(
max_per_img=1000,
min_bbox_size=0,
nms=dict(iou_threshold=0.7, type='mmcv.ops.nms'),
nms_pre=2000)),
type='mmdet.models.detectors.faster_rcnn.FasterRCNN')
optim_wrapper = dict(
optimizer=dict(
lr=0.02, momentum=0.9, type='torch.optim.sgd.SGD',
weight_decay=0.0001),
type='mmengine.optim.optimizer.optimizer_wrapper.OptimWrapper')
param_scheduler = [
dict(
begin=0,
by_epoch=False,
end=500,
start_factor=0.001,
type='mmengine.optim.scheduler.lr_scheduler.LinearLR'),
dict(
begin=0,
by_epoch=True,
end=12,
gamma=0.1,
milestones=[
8,
11,
],
type='mmengine.optim.scheduler.lr_scheduler.MultiStepLR'),
]
resume = False
test_cfg = dict(type='mmengine.runner.loops.TestLoop')
test_dataloader = dict(
batch_size=1,
dataset=dict(
ann_file='annotations/instances_val2017.json',
backend_args=None,
data_prefix=dict(img='val2017/'),
data_root='data/coco/',
pipeline=[
dict(backend_args=None, type='mmcv.transforms.LoadImageFromFile'),
dict(
keep_ratio=True,
scale=(
1333,
800,
),
type='mmdet.datasets.transforms.Resize'),
dict(
type='mmdet.datasets.transforms.LoadAnnotations',
with_bbox=True),
dict(
meta_keys=(
'img_id',
'img_path',
'ori_shape',
'img_shape',
'scale_factor',
),
type='mmdet.datasets.transforms.PackDetInputs'),
],
test_mode=True,
type='mmdet.datasets.CocoDataset'),
drop_last=False,
num_workers=2,
persistent_workers=True,
sampler=dict(
shuffle=False, type='mmengine.dataset.sampler.DefaultSampler'))
test_evaluator = dict(
ann_file='data/coco/annotations/instances_val2017.json',
backend_args=None,
format_only=False,
metric='bbox',
type='mmdet.evaluation.CocoMetric')
test_pipeline = [
dict(backend_args=None, type='mmcv.transforms.LoadImageFromFile'),
dict(
keep_ratio=True,
scale=(
1333,
800,
),
type='mmdet.datasets.transforms.Resize'),
dict(type='mmdet.datasets.transforms.LoadAnnotations', with_bbox=True),
dict(
meta_keys=(
'img_id',
'img_path',
'ori_shape',
'img_shape',
'scale_factor',
),
type='mmdet.datasets.transforms.PackDetInputs'),
]
train_cfg = dict(
max_epochs=12,
type='mmengine.runner.loops.EpochBasedTrainLoop',
val_interval=1)
train_dataloader = dict(
batch_sampler=dict(type='mmdet.datasets.AspectRatioBatchSampler'),
batch_size=2,
dataset=dict(
ann_file='annotations/instances_train2017.json',
backend_args=None,
data_prefix=dict(img='train2017/'),
data_root='data/coco/',
filter_cfg=dict(filter_empty_gt=True, min_size=32),
pipeline=[
dict(backend_args=None, type='mmcv.transforms.LoadImageFromFile'),
dict(
type='mmdet.datasets.transforms.LoadAnnotations',
with_bbox=True),
dict(
keep_ratio=True,
scale=(
1333,
800,
),
type='mmdet.datasets.transforms.Resize'),
dict(prob=0.5, type='mmdet.datasets.transforms.RandomFlip'),
dict(type='mmdet.datasets.transforms.PackDetInputs'),
],
type='mmdet.datasets.CocoDataset'),
num_workers=2,
persistent_workers=True,
sampler=dict(shuffle=True, type='mmengine.dataset.sampler.DefaultSampler'))
train_pipeline = [
dict(backend_args=None, type='mmcv.transforms.LoadImageFromFile'),
dict(type='mmdet.datasets.transforms.LoadAnnotations', with_bbox=True),
dict(
keep_ratio=True,
scale=(
1333,
800,
),
type='mmdet.datasets.transforms.Resize'),
dict(prob=0.5, type='mmdet.datasets.transforms.RandomFlip'),
dict(type='mmdet.datasets.transforms.PackDetInputs'),
]
val_cfg = dict(type='mmengine.runner.loops.ValLoop')
val_dataloader = dict(
batch_size=1,
dataset=dict(
ann_file='annotations/instances_val2017.json',
backend_args=None,
data_prefix=dict(img='val2017/'),
data_root='data/coco/',
pipeline=[
dict(backend_args=None, type='mmcv.transforms.LoadImageFromFile'),
dict(
keep_ratio=True,
scale=(
1333,
800,
),
type='mmdet.datasets.transforms.Resize'),
dict(
type='mmdet.datasets.transforms.LoadAnnotations',
with_bbox=True),
dict(
meta_keys=(
'img_id',
'img_path',
'ori_shape',
'img_shape',
'scale_factor',
),
type='mmdet.datasets.transforms.PackDetInputs'),
],
test_mode=True,
type='mmdet.datasets.CocoDataset'),
drop_last=False,
num_workers=2,
persistent_workers=True,
sampler=dict(
shuffle=False, type='mmengine.dataset.sampler.DefaultSampler'))
val_evaluator = dict(
ann_file='data/coco/annotations/instances_val2017.json',
backend_args=None,
format_only=False,
metric='bbox',
type='mmdet.evaluation.CocoMetric')
vis_backends = [
dict(type='mmengine.visualization.LocalVisBackend'),
]
visualizer = dict(
name='visualizer',
type='mmdet.visualization.DetLocalVisualizer',
vis_backends=[
dict(type='mmengine.visualization.LocalVisBackend'),
])
work_dir = './work_dirs/faster_rcnn_r50_fpn_1x_coco'
版权归原作者 MorleyOlsen 所有, 如有侵权,请联系我们删除。