
系列文章,请多关注
推荐算法架构1:召回
推荐算法架构2:粗排
推荐算法架构3:精排
推荐算法架构4:重排
推荐算法架构5:全链路专项优化
推荐算法架构6:数据样本
推荐算法架构7:特征工程
1 概述
特征工程[1](Feature Engineering)是推荐算法的基础,它对收集到的原始数据进行解析和变换,从而提取出模型所需要的信息。通过挖掘丰富和高质量的特征,并对其进行合理的处理,可以提升模型预估准确度,从而提升推荐系统业务效果。特征工程是一项需要重点掌握的技术。
本文先讲解特征类目体系,分析推荐系统中一般会有哪些特征。然后讲解特征处理范式,分析如何对特征进行离散化、归一化、池化和缺失值填充等处理。最后讲解特征重要性评估,从而提升特征可解释性,并对其进行筛选,以及进一步挖掘更多高质量特征。特征工程的技术架构如图1所示。
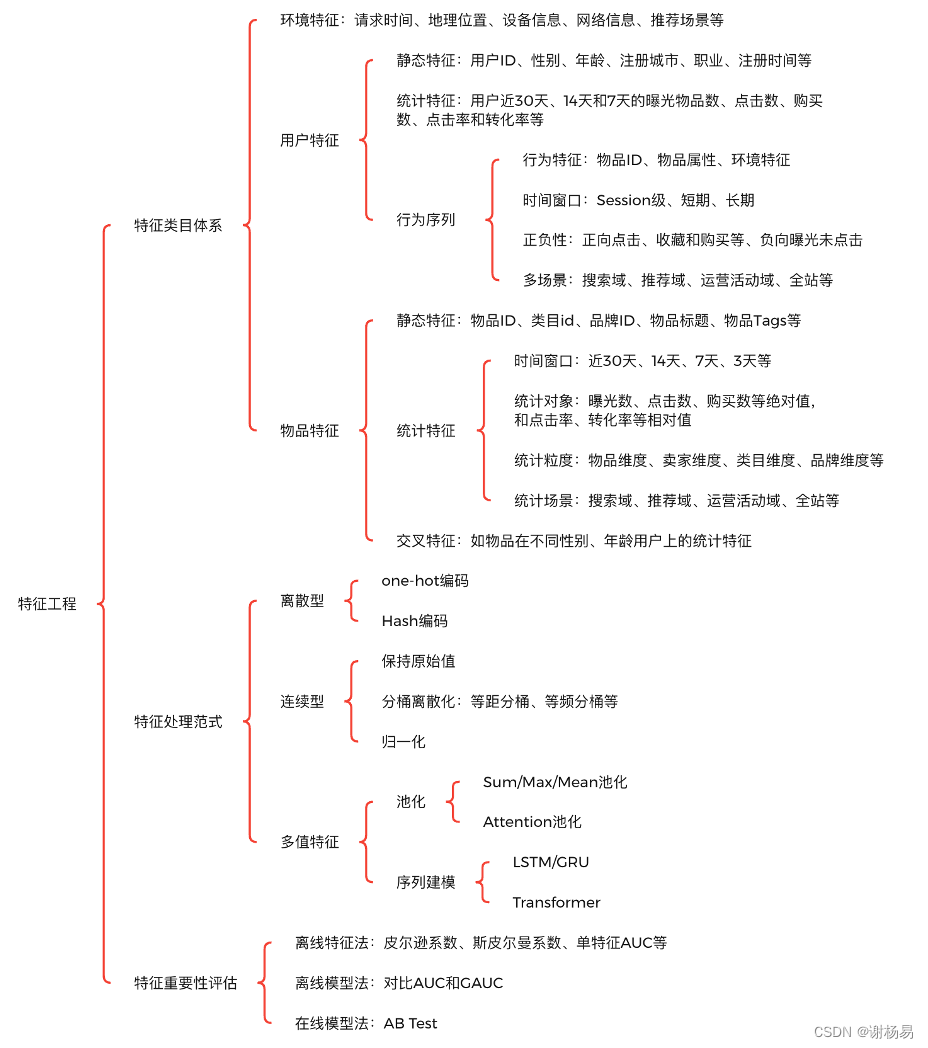
图1 特征工程技术架构
2 特征类目体系
掌握特征类目体系,有利于提升特征丰富度,完善特征工程体系。在具体的业务场景中,可以将自己想象为一个真实用户,思考哪些特征对用户点击和转化有比较大的影响。深度学习赋予了特征自动交叉的能力,降低了对领域知识的要求,但不代表不需要加强业务理解能力。
一般来说主要包括环境特征(Context Feature)、用户特征(User Feature)和物品特征(Item Feature)三大类。环境特征一般需要用户授权才能获取,不同业务场景所需的环境特征会有一定区别,可以枚举如下:
- 请求时间:如请求发生在周几,是否节假日,发生在几点,当前季节等。
- 地理位置:如用户当前所在的国家、省份、城市,以及当地天气和温度等。
- 设备信息:如手机机型、手机厂商、操作系统(Android/IOS)等。
- 网络信息:如运营商渠道、网络类型(WIFI/5G/4G)等。
- 客户端信息:如请求渠道(APP/小程序/H5/PC等)、APP版本号等
- 推荐场景:如首页推荐、相关推荐、详情页推荐等
用户特征通常也称用户画像,主要包括用户静态特征、统计特征和行为序列特征三大类,一般也需要用户授权才能获取和使用。用户特征有利于提高个性化分发能力,可以枚举如下:
- 静态特征:如用户ID、性别、年龄、注册城市、职业、注册时间、是否VIP、是否新用户、是否已婚,以及是否有小孩等。静态特征通常区分度很高,是推荐系统中的强信号。比如不同性别和年龄的用户,其兴趣差异会很大。是否有小孩,会直接决定用户是否对母婴类目商品有兴趣。静态特征一般很少变动,适用范围广,可以应用到多个不同业务场景中。其难点在于不好收集,需要用户主动提供且授权,才能使用。另外一般需要加密存储,防止用户隐私信息泄露。
- 统计特征:如用户近30天、14天和7天的曝光物品数、点击数、购买数、点击率和转化率等。统计特征包括绝对值和相对值两大类,绝对值用来刻画流量信息,相对值则可以刻画效率信息。相对值需要注意其置信度,例如“曝光数2次、点击数1次”,和“曝光数200次、点击数100次”两组特征,点击率虽然同为0.5,但前者置信度明显不足。统计特征大多为后验特征,经过了真实场景充分验证,对模型帮助很大。最后需要注意的是,统计特征容易出现数据穿越问题,生产时要小心。例如构造天级样本时,千万不要把当天的统计数据也计算进去了。
- 行为序列特征:目前,针对用户行为序列特征的研究很多,它是当前算法模型效果提升的关键。一个历史行为,可以包括被行为(如被点击)物品的ID,还可以包括其类目ID、品牌ID和卖家ID等物品属性特征,以及历史行为距离当前时间间隔等环境特征。按时间窗口划分,有Session级行为序列、短期行为序列和长期行为序列。按用户反馈正负性划分,有点击、购买和收藏等正反馈序列,和曝光未点击等负反馈序列。构建全面而丰富的用户行为序列,可以充分挖掘用户兴趣,有利于提升模型效果和用户体验。
物品特征主要包括物品静态特征、统计特征和交叉特征三大类。物品是推荐这一行为的实体,充分挖掘其特征有助于筛选出高质量,且用户喜欢的物品。物品特征可以枚举如下:
- 静态特征:如物品ID、类目ID、品牌ID、卖家ID、价格、标题和上架时间等。其在不同场景下有一定的区别,比如电商场景和短视频场景。这些特征可由机器识别、运营标注和卖家(或创作者)填写等多种方式产出。
- 统计特征:如物品近30天、14天和7天的曝光数、点击数、购买数、点击率和转化率等。统计特征可以表征物品的热度、质量和转化效率等信息,重要性很高。按时间窗口划分,有近30天、近14天、近7天和近3天等构造方法。按统计对象划分,有曝光数、点击数、购买数等绝对值,和点击率、转化率等相对值。按统计粒度划分,既可以统计物品本身数据,还可以统计物品的卖家、对应类目、对应品牌的各项数据。按统计场景划分,可以对推荐、搜索、运营活动和全站等多个场景分别统计。跟用户侧一样,物品统计特征也要注意数据穿越问题。
- 交叉特征:物品与用户交叉特征,比如物品在不同性别、年龄用户上的统计特征。有利于挖掘物品在不同人群上的流量和效率表现情况,缓解“辛普森悖论”问题,从而让个性化分发更准确。虽然深度模型可以实现自动特征交叉,但交叉不一定充分。另外交叉特征是强信号特征,可以降低模型学习难度,从而让它将精力用在其他更需要学习的地方。因此,手工构造关键的交叉特征,目前仍然有重要意义。一般来说,用户特征与物品特征间交叉,比用户特征之间,或物品特征之间交叉,更为重要。
3 特征处理范式
收集到原始特征后,还需要进一步进行离散化、归一化、池化和缺失值填充等处理,才能输入到模型中。特征处理有助于让模型学习更高效,更鲁棒,因此同样十分重要。针对不同类型的特征,会有不同的处理方法。特征类型主要有离散型、连续型和多值特征三大类。
离散型特征,一般也称为类别型特征,如物品ID、类目ID和品牌ID等。类别型特征枚举值多,区分度高,是推荐系统中的强信号。而且大多是静态特征,不需要后验数据,冷启动效果好。离散型特征主要有如下处理方法:
- one-hot编码:每个类别为一个二进制向量,向量中每个维度代表一个类别取值,只有一个维度的值为1,其余均为0。one-hot编码简单易用,是机器学习中经常采用的编码方法。但当特征类别值较多时,会遇到“维度灾难”问题。
- Hash编码:利用Hash函数,对原始值进行变换和降维。有较强的压缩能力,特别适合于类别值很多的特征。同时其计算速度很快,额外开销小。但有一定概率会将不同原始值Hash为同一值,存在Hash冲突问题,可能影响算法准确度。另外Hash编码会导致原始值难以识别,可解释性降低。
连续型特征,如用户侧和物品侧的各项统计特征。它可以有效表征用户活跃度、物品质量、物品转化效率等信息,因此十分重要。另外很多连续型特征同时也是后验特征,经过了大量真实用户检验,可以提升模型预估准确性。连续型特征主要有如下处理方法:
- 保持原始值:可以将连续型特征,直接与类别型特征的Embedding编码向量,拼接起来,然后输入到模型中。DeepCrossing[2]等早期深度模型通常采用这一方案。它操作简单,容易实现,但泛化能力差,且容易受异常值影响。
- 分桶离散化:目前常用的方法,利用预先定义的分桶边界值,将连续值归入对应桶内。这种方法有利于提升模型泛化能力,降低过拟合问题,同时对异常值不敏感,因此应用十分广泛。有等距分桶和等频分桶等多种具体实现方式,一般来说正样本等频分桶效果较好。分桶法的缺点是位于分桶边界附近的数值,即使差距很小,也有可能会被归入不同的桶内。最后,分桶法需要注意尽量让每个桶内都有充足样本,且样本不要集中于个别桶内。
- 归一化:有最大最小值归一化、对数函数转换、区间缩放法等多种方法。归一化有利于降低个别特征的主导地位,让模型学习更平稳,并加快收敛速度。
多值特征,最典型的就是用户行为序列,以及用户Tag、物品Tag和物品标题等特征。推荐系统中,绝大多数的特征都是单值的,比如用户性别和年龄。但有部分特征是数组等多值形式,比如物品标题由多个字组成,用户行为序列由多个历史行为组成等。多值特征的数组长度不固定,无法直接输入到模型中,因此需要转换为固定长度,主要方法有:
- 池化:如最大值池化、求和池化和平均池化等方法。先利用离散型特征或连续型特征的处理方法,对多值特征中的每个特征值进行转换,并进行Embedding编码。然后对它们求最大值、求和或求平均,将其压缩为一个单值Embedding向量。这种方法比较简单,计算耗时低,但没有考虑不同特征值之间的重要性差别。为了解决这一问题,Attention[3]池化被提出。它先计算每个特征值的权重,然后再加权求和。目前物品标题等普通多值特征常使用平均池化,而用户行为序列则可以使用Attention池化。
- 序列建模:常用在用户行为序列特征的处理中。它利用LSTM[4]或GRU[5]等循环神经网络,或Transformer[6]网络进行信息抽取,并将不定长的原始序列转换为一个定长向量,然后再输入到模型上层网络中。Transformer表达能力强,并行计算快,目前已经成为了行为序列建模的主流方案。
特征工程中,还经常碰到缺失值和异常值问题。对于缺失值,可以用平均值、固定值、中位数或近邻值进行填充,也可以看做一种普通数值而不填充。对于异常值,可以做最值截断、平滑或直接去除等操作。
4 特征重要性评估
特征重要性评估,一方面可以用来做特征筛选,精简不必要的特征,从而减少离线和在线计算和存储压力。另一方面可以提高算法可解释性,帮助卖家(或创作者)高效运营。另外还可以为特征挖掘寻找方向,方便后续构造出更多重要特征。
特征重要性评估,有离线特征法、离线模型法和在线模型法三大类。
离线特征法,计算待评估特征与标签(如点击、购买)间的相关性,从而衡量是否是强特征。计算方法有皮尔逊系数、斯皮尔曼系数、单特征AUC[7]等。AUC常用来衡量模型排序能力,应用最多。离线特征法不用训练模型,简单易用,但无法刻画特征经过交叉后的重要性,故准确率不高。
离线模型法,可以训练待评估特征剔除前和剔除后两个模型,然后对比它们的AUC和GAUC[8]等指标。剔除特征后,离线指标下降越多,则说明该特征越重要。离线模型法可以充分考虑待评估特征与其他特征交叉后的重要性,其准确性较高。
在线模型法,则将特征剔除前和剔除后两个模型,进行在线AB测试。其准确性最高,但同时成本也最高。另外由于需要用到真实流量,因此一定要谨慎操作。
5 参考文献
[1] Turner, C.R., Fuggetta, A., Lavazza, L., Wolf, A.L.: A conceptual basis for feature engineering. Journal of Systems and Software 49(1), 3–15 (1999)
[2] Ying Shan, T Ryan Hoens, et al. 2016. Deep crossing: Web-scale modeling without manually crafted combinatorial features. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 255–262.
[3] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2015. Neural machine translation by jointly learning to align and translate. In Proceedings of the 3rd International Conference on Learning Representations (ICLR’15)
[4] Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long short-term memory. Neural Comput. 9, 8 (1997), 1735–1780.
[5] Kyunghyun Cho, Bart van Merrienboer, C¸ aglar Gulc¸ehre, ¨ Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proc. of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014.
[6] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems. 5998–6008.
[7] T. Fawcett, ‘‘An introduction to ROC analysis,’’ Pattern Recognit. Lett., vol. 27, no. 8, pp. 861–874, Jun. 2006.
[8] Guorui Zhou, Xiaoqiang Zhu, et al. 2018. Deep Interest Network for Click-Through Rate Prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 1059–1068.
系列文章,请多关注
推荐算法架构1:召回
推荐算法架构2:粗排
推荐算法架构3:精排
推荐算法架构4:重排
推荐算法架构5:全链路专项优化
推荐算法架构6:数据样本
推荐算法架构7:特征工程
版权归原作者 谢杨易 所有, 如有侵权,请联系我们删除。