

一、使用交叉顶点数据
用一个数组交叉地保存顶点数据,而不是用独立的顶点数组保存不同的属性,会得到更好的性能,因为顶点数组具有更好的局部内存。例如,把顶点位置读入到变换前顶点缓存时,很可能会把该顶点的法线信息也读入到变换前的顶点缓存中,在需要时供顶点着色器使用。如下
var verticesColors = new Float32Array([
// 顶点坐标和颜色
0.0, 0.5, 1.0, 0.0, 0.0,
-0.5, -0.5, 0.0, 1.0, 0.0,
0.5, -0.5, 0.0, 0.0, 1.0,
]);
var n = 3; // 顶点数量
// 创建缓冲区对象
var vertexColorBuffer = gl.createBuffer();
gl.bindBuffer(gl.ARRAY_BUFFER, vertexColorBuffer);
gl.bufferData(gl.ARRAY_BUFFER, verticesColors, gl.STATIC_DRAW);
var FSIZE = verticesColors.BYTES_PER_ELEMENT;
// 获取a_Position的存储位置,分配缓冲区并开启
var a_Position = gl.getAttribLocation(gl.program, 'a_Position');
gl.vertexAttribPointer(a_Position, 2, gl.FLOAT, false, FSIZE * 5, 0);
gl.enableVertexAttribArray(a_Position);
// 获取a_Color的存储位置,分配缓冲区并开启
var a_Color = gl.getAttribLocation(gl.program, 'a_Color');
gl.vertexAttribPointer(a_Color, 3, gl.FLOAT, false, FSIZE * 5, FSIZE * 2);
gl.enableVertexAttribArray(a_Color);
二、使用gl.drawElements()的索引绘制(geometry.index)
宗旨:尽可能的减少顶点数量
const geometry = new THREE.BufferGeometry();
const vertices = new Float32Array([
0, 0, 0, //顶点1坐标
80, 0, 0, //顶点2坐标
80, 80, 0, //顶点3坐标
0, 80, 0, //顶点4坐标
]);
// 创建属性缓冲区对象
const attribue = new THREE.BufferAttribute(vertices, 3);
geometry.attributes.position = attribue;
// Uint16Array类型数组创建顶点索引数据
const indexes = new Uint16Array([
0, 1, 2, 0, 2, 3,
])
// BufferAttribute表示顶点索引属性的值
geometry.index = new THREE.BufferAttribute(indexes, 1); //1个为一组
三、LOD
细节层次LOD技术。当对象离开观察者的视线时可以降低模型的复杂度(随着相机距离增大,减少三角形的细分数)。实际上通常为模型创建不同的版本,在运行时进行改变。当然,在JavaScript代码中实现 LOD 逻辑会增加 CPU的工作量,因此存在这样的风险:如果不谨慎,可能会把瓶颈从 GPU 移到 CPU。
四、将CPU执行的操作移到GPU
充分发挥GPU的本领,避免CPU干的蒙圈,GPU一旁看着干捉急
如果只绘制少数几个对象,这并不很重要,因为JavaScript 引擎速度已经足够快。但是如果在每帧中需要绘制几千个对象,每个对象需要执行几次矩阵相乘运算,在用户属于CPU 受限的情况下,则这会很快使帧的速率恶化。
五、减少绘制调用的次数
任何对 WebGL API的调用都会带来开销。每个调用都会要求 CPU 进行额外的处理和数据复制,这会占用时间并要求 CPU做一些额外工作。通常,如果GPU接收到大批可并行处理的数据,运行效率会提高许多。
提高 WebGL性能的一个最重要建议是在每帧处理期间使调用gl.drawArays0和gl.drawElementsO的次数最少。例如,某个场景的一部分需要绘制 1000 个三角形,则调用两次gldrawArrays()或gl.drawElements()每次绘制 500个三角形,比调用100次每次绘制10个三角形更好。
六、避免绘制时从GPU读回数据或状态
最典型的就是 gl.readPixels()!!!获取颜色值!因为GPU中的流水线经常需要刷新,从 GPU 读回数据是一个相对较慢的操作,会消耗大量的时间和资源。特别是在每帧都需要读回数据时,会导致渲染性能急剧下降。另,将数据从 GPU 传输到 CPU 需要通过总线传输,这会消耗大量的带宽。频繁地读取数据将增加对内存和总线带宽的需求
/**
* @param {*} gl webgl
* @param {*} startPosition 开始点的坐标
* @param {*} rectangle 长宽的范围
* @returns
*/
function readPixelReturnInt(gl,startPosition,rectangle) {
//像素容器
let pixel = new Uint8Array(rectangle[0]* rectangle[1] * 4);
//抓取像素
gl.readPixels(
startPosition[0], startPosition[1], rectangle[0], rectangle[1], gl.RGBA, gl.UNSIGNED_BYTE, pixel
)
return pixel;
}
七、Merge合并几何体
当有大量的几何体需要渲染时,可以将它们合并为一个几何体来减少渲染调用,从而提高性能。合并后的几何体将会生成一个大的缓冲区,包含了所有合并的几何体的数据,这样在渲染时只需一次性加载这个大缓冲区即可,减少了渲染调用和资源占用。
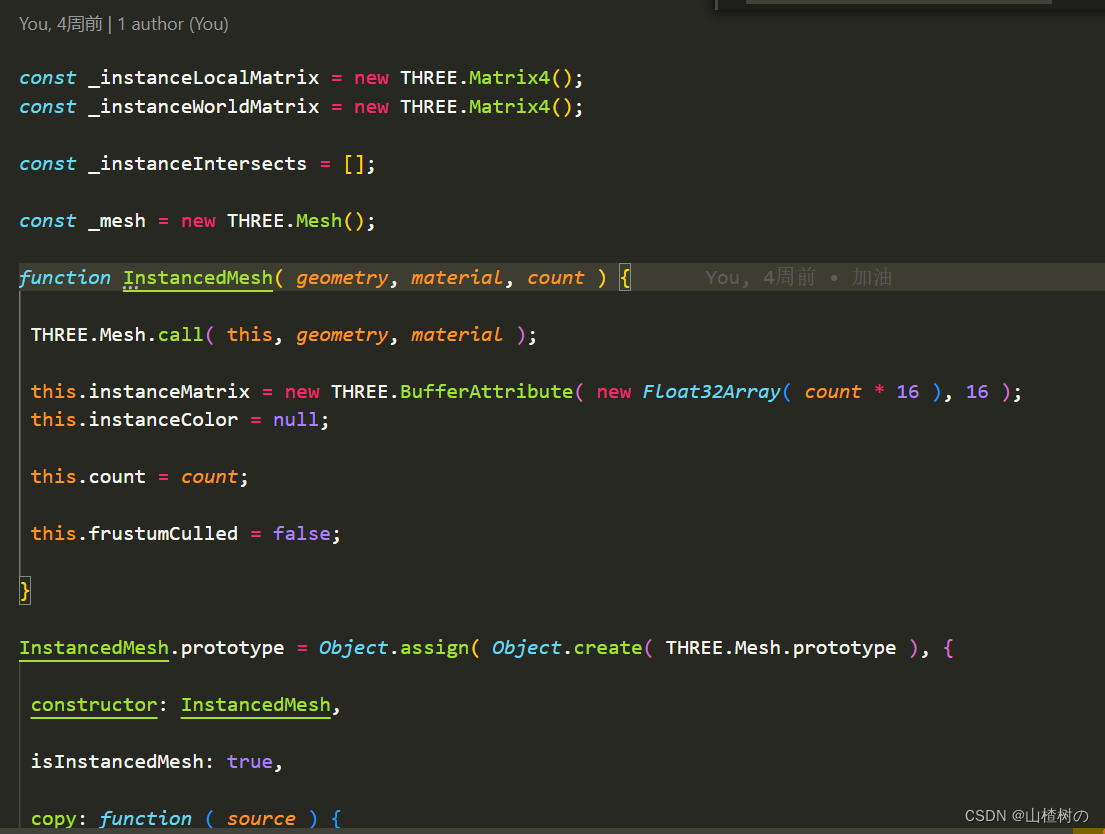
八、InstanceMesh多实例
instanceMesh
是使用InstancedMesh类来创建实例化的几何体。它适用于当需要大量重复的几何体时,但是每个实例之间有不同的变换属性(如位置、旋转、缩放等)。极大节省内存,只会存储一个geometry的顶点数据
两种合并方式比较
Instance实例化几何体Merge合并几何体Material相同相同Geometry相同✔ 不同单个控制✔ 使用索引,轻松实现着色器实现生成时间✔ 快速缓慢渲染性能较优✔ 更优内存占用✔ 极少较多
版权归原作者 山楂树の 所有, 如有侵权,请联系我们删除。