
目录
前言
深度学习一直作为一个“盲盒”被大家诟病,我们可以借助深度学习实现端到端的训练,简单,有效,但是我们并不了解神经网络的中间层到底在做什么,每一层卷积的关注点是什么。
我在之前的专题浅谈图像处理与深度学习中提到,我们在深度学习刚开始的时候,我们要实现一个任务,比如:把不清晰的图像变清晰,我们随意的搭建了三层网络,然后开始训练,发现效果比传统的图像处理方法好,而且简单有效,然后我们再随意的搭建四层网络,发现四层网络比三层网络效果还好,我们也许有一种感性的认识:随着网络层的增加,网络的参数的增加,网络能够学习到更多的特征。这个结论有一定道理,但是又不完全的有道理。
2015年,Resnet网络横空出世,该网络表明不断地堆叠网络,网络反而会出现“退化”的情况,我们我们可以从公式的角度来推断残差网络如何规避梯度消失,即使在梯度很小的时候,残差网络的反向传播也很难得到一个小的梯度(我们需要明白一个关键:神经网路参数的更新的原动力就是梯度,我们需要沿着梯度的负方向进行迭代,如果反向传播的时候没有梯度,那网络就会停止更新),所以,网络的层数并不是越多越好。
而感受野告诉我们:网络层越深,感受野越大(具体的我们接下来讲)。
根据这三个个结论:1.网络并不是越深越好 2.网络越深,感受野越大 3.我们需要在精度和性能两个方面做平衡 根据这三个结论,我们也许就能设计出自己的神经网络!
本专题主要参考B站UP启释科技,该UP对感受野的研究已经出神入化!
一、初识感受野
1.1猜一猜他是什么?





从左往右,图片越来越大,我们人眼看到的信息越来越多,我们在看第一幅图像的时候,我们也许识别不出他是蝴蝶,随着图像的增大,也就是我们人眼的视野越来越大,我们人眼接触到的信息越来越多,我们能够逐渐分辨出它的类别。
1.2人眼视觉系统下的感受野

“感受野”这个词一开始来源于人眼视觉系统,如上图所示(该图是摄像机拍摄的),我们人眼聚焦这幅图像的中心点位置,我们发现我们只能看清楚中心区域的物体,而边缘的物体是模糊的,人眼真实看到的图如下图所示。

1.当盯着某个点看,保持眼球不转动的前提下,此时只有该点区域是“清晰的”,而其他周围区域是模糊的。
2.只有不停转动眼球,才能连续看清不同的区域。
所以,我们总结了
人眼视觉系统感受野的三大特性:
A.视野大
**B.关注中心 **
C.周围模糊
1.3深度神经网络中的感受野
1.3.1感受野的性质
在深度卷积神经网络中,每个神经元节点都对应着输入图像的某个确定区域,仅该区域的图像内容能对应神经元的激活产生影响,那么这个区域称之为该神经元的感受野。
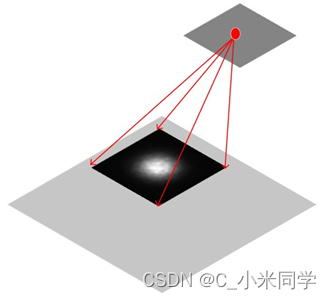
如上图所示:浅灰色为输入图像(下),深灰色为卷积之后的特诊图(上),深灰色(特征图)上红色点在浅灰色(输入图像)像上的感受野就如浅灰色上的黑色区域表示。也就是所,红色点能够“看到”黑色区域的大小,这个黑色区域称为红点的感受野,或者说,该黑色区域影响了红点的输出,其中黑色区域中心的白色区域表示对红点的输出起决定性作用,这也表明,神经网络中的节点也关注感受野的中心区域,或者说,神经网路对感受野的每个区域的关注程度是不同的。
1.3.2感受野的定义
A.越靠近感受野中心的区域越重要
这一点,和人眼的感受野特性一直。
B.各向同性
就是沿着中心对称的位置,感受野对神经元的输出的影响程度是相同的。
C.由中心向周围的重要性衰减速度可以通过网络结构控制
这一点比较难理解,但这一点也是最关键的,他是引出“有效感受野”的关键。我们知道,神经元节点最关注感受野的中心区域(也就是黑色区域中的白色区域),而中心区域的其他区域或许神经元节点也能够“看到”,但是,这部分区域对神经元的输出起不到什么作用,就像我们在一开始讲人眼视觉系统下的感受野的时候,我们也可以注意到中心区域外的模糊区域,但是我们很难通过这个模糊区域判断出物体类别。感受野由黑色区域(不重要区域)和白色区域(中心区域)组成,从白色区域到黑色区域的过程就叫重要性的衰减速度。感受野一样大的前提下,白色区域越大,衰减速度越慢,而重要性的衰减速度又可以通过网络结构来控制,也就是我们可以通过设计网络,来调整重要性的衰减速度!
1.3.3举一个例子
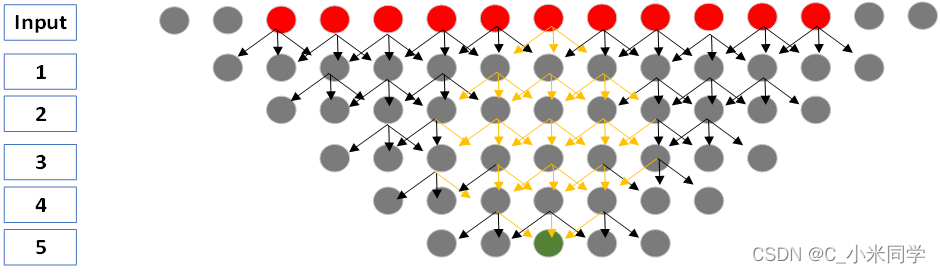
如上图所示,这一个以卷积过程,不是一个全连接,大家要注意。
我们有15个输入节点,通过四层卷积运算,得到最后5个输出节点,其中,中间的绿色节点的感受野为11(红色节点)。这里我提一个问题:绿色节点的感受野是11个红色节点,那这11个红色节点对绿色节点的输出的影响程度是一样的吗?
显然是不一样的,我们根据之前的结论,中间的节点对神经元的输出起决定性作用。那么,我们如何计算或者如何描述11个节点对绿色节点的重要程度?我们可以用边数来表示,边数就是卷积的次数,我们有理由相信,卷积次数越多,对神经元的影响越大。我们一次计算这11个节点到绿色节点的边数。
输入点重要程度定义为:影响后续卷积计算的次数
如上图:感受野大小为11(最后的绿色输出有11个红色输入决定),其中每个节点重要程度依次为(11个节点与绿色输出形成的边):5-13-24-31-36-37(中间)-36-31-24-13-5。
通过重要程度的计算,我们也可以进一步验证感受野的几个特性,中间节点确实是最重要的,中间对称的位置的重要程度确实是一样的!
1.3.4以VGG网络为例
如右图所示,我们输入图像的大小为224x224,VGG13的感受野为348x348......
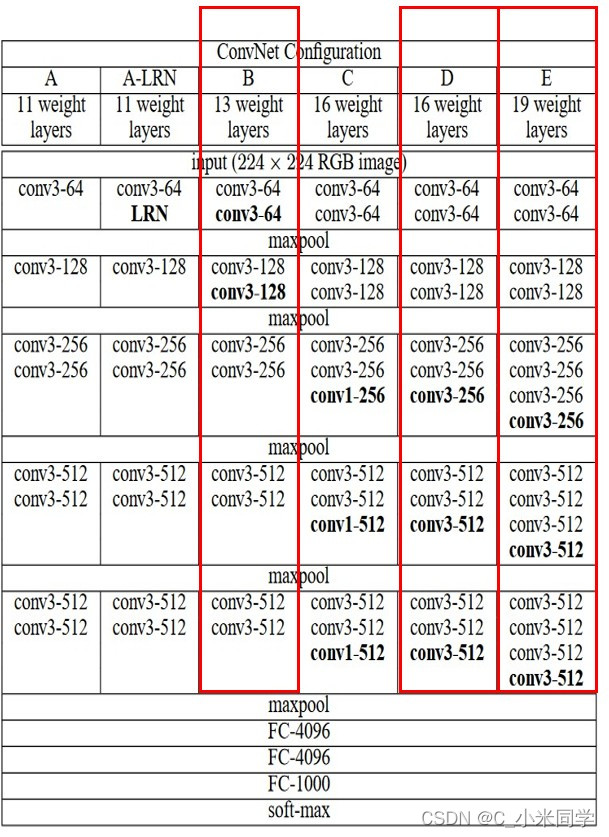

A.以VGG13(B)/VGG16(D)/VGG19(E)为例,计算分类前一层的神经元感受野大小。
B.分类准确率:VGG16要明显好于VGG13,而VGG19只是比VGG16高一点。
这里我提两个问题:
1.VGG13-19的感受野的大小都要大于输入图像(224x224),为什么?
神经网络的感受野和人眼一样,我们刚刚提到,我们一看到图像的部分信息的时候(如下图),我们很难判断他是什么,神经网络也是,我们要准确的判断图像的物体的时候,我们是不是要观察整幅图像?我们通过局部信息就来判断物体始终是不准确的。所以,神经网络的感受野起码要大于原图。

2.感受野是不是越大越好?
对于这个问题,等介绍了有效感受野之后再解释。
二、感受野的计算
2.1 哪些操作能够改变感受野?
A.卷积
B.反卷积
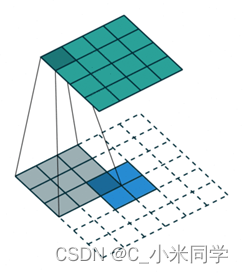
C.空洞卷积
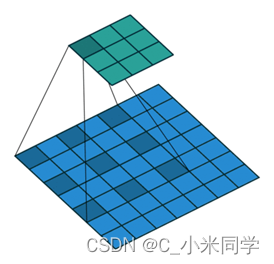
D.池化
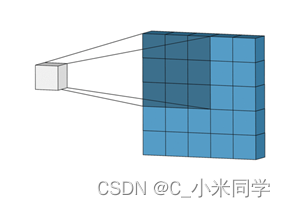
上面几个操作很好理解,下面两个操作我认为是容易被忽略的:
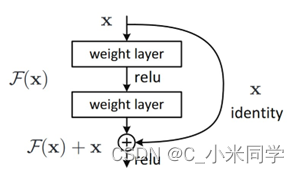
E.残差结构
F.Concat操作
2.2 感受野的计算公式

通过这个公式,我们可以发现:感受野的大小主要和卷积的步长有关!
感受野的增速,是直接和步长的累乘相关,想要网络更快速的达到某个感受野尺度,可以让步长大于1的卷积核更靠前,这样做还有一个好处就是大大增加了网络的推理速度,因为特征图的分辨率会迅速变小。
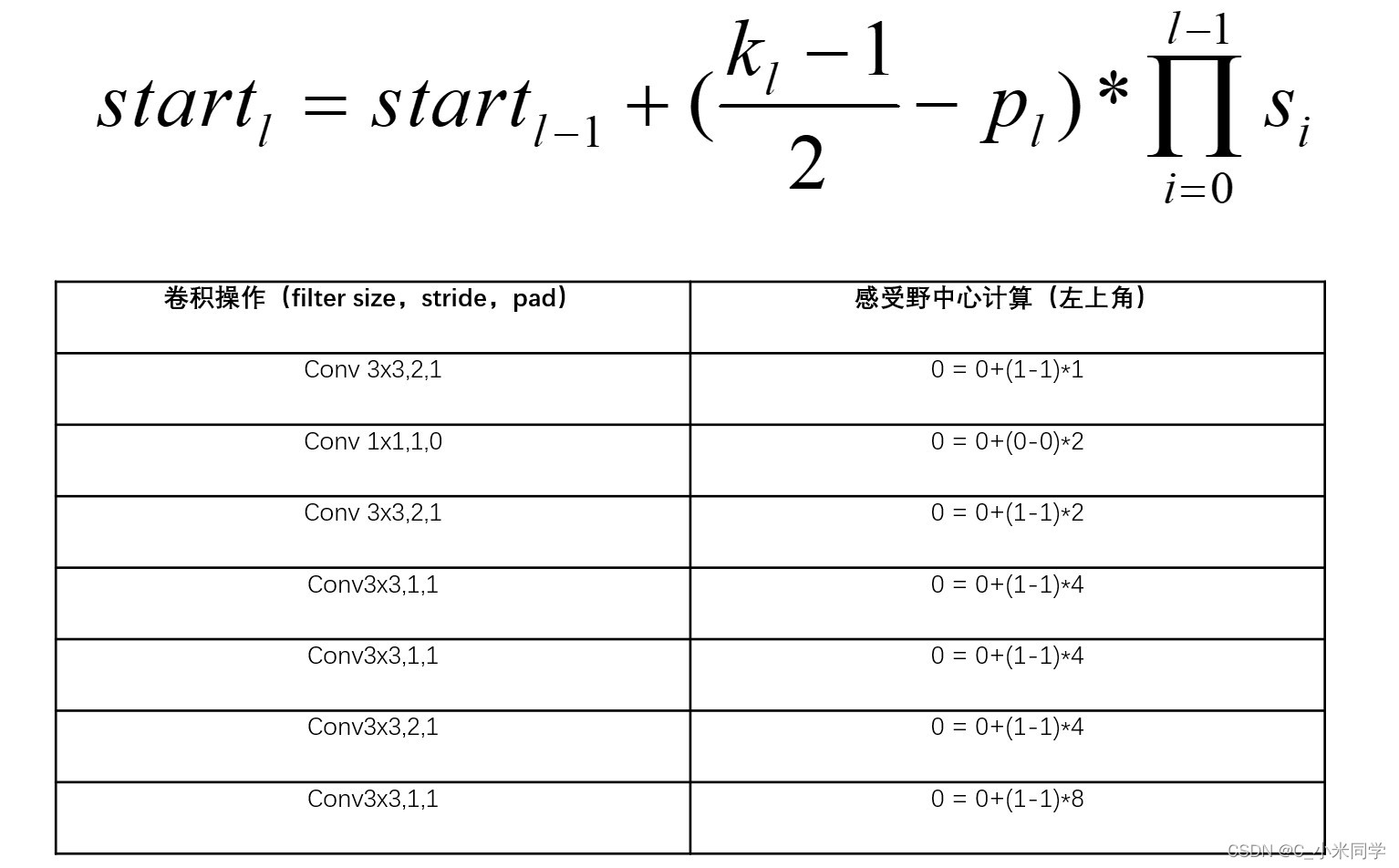
2.3 感受野的中心位置计算

刚刚计算了感受野的大小,我们还要确定感受野的坐标。比如,我么确定了感受野的大小,我们再来确定该感受野上,左上角的坐标。
2.4 感受野中心计算示例
三、有效感受野
3.1有效感受野的概念
1.有效感受野指的是一种现象:
感受野(RF,Receptive Field)中的每个位置均会对相应神经元的激活产生影响,但并不是所有位置的贡献都相等。这种位置‘歧视’现象就是有效感受野(ERF,Effective Receptive
Field)的主要内涵。
2.有效感受野是神经网络的能在属性,当网络结构确定,有效感受野的相关特性即确定。
3.即使感受野大小一样的情况下,因网络结构的不同,其有效感受野的特性也会有所不同
如下图所示,有效感受野其实就是白色区域,在下面两幅图中,我们发现,即使两个网络不同,但是他们的感受野是一样大的,最主要的区别就是他们的有效感受野不同,而有效感受野决定了神经元的输出,在分类、检测、分割任务中,有效感受野越大,网络捕获的信息越大,识别的精度越大,所以右图的网络的识别精度是要好于左边的。

W. Luo, Y. Li, R. Urtasun, and R. Zemel, “Understanding the effective receptive field in deep convolutional neural networks,” in Proc. 30th Int. Conf. Neural Inf. Process. Syst., 2016, pp. 4905–4913.
3.2有效感受野的计算
1.有效感受野是一种现象,其本身是无法被计算的,但是感受野中的每个位置的重要程度是可以被计算的,所有位置的重要程度能够反映有效感受野的存在。
2.目前,比较主流的做法是(图论):把CNN的整个计算看成一个3D的有向图,从低层节点指向高层节点。计算RF中某个输入节点对于高层某个神经元节点的贡献度:
A.计算输入节点到神经元节点的所有路径
B.统计所有路径包含的边,去掉重复的边
C.边的条数即为该输入节点的贡献度
这种图论的方法就是之前计算过得,数他的“边数”。
3.3感受野每个位置的贡献度
将每个感受野中位置的贡献画出来,就会呈现出一个类似二元高斯函数的三维图像。
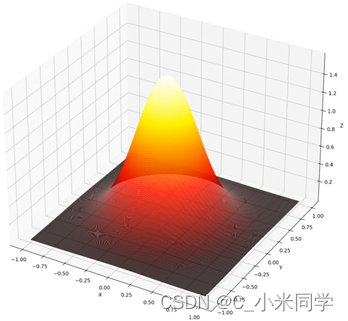
我们通过该图,我们也可以验证,感受野的三个特性:
A.中间贡献度最大
B.各向同性
C.向四周逐渐衰减
3.4有效感受野为什么重要?
1.通过有效感受野,可以知道神经网络到底在关注哪里,有多关注!
2.知道分类、检测、分割网络的设计(多深)->在性能和精度上做平衡!
3.一个进一步探索网络可解释性的有效手段
神经网络一直被大家诟病是一个黑盒,输入到结果中间完全不可知。有效感受野有可能是一把钥匙,帮助我们去理解神经网络的行为
3.5感受野越大越好?
这是前面遗留下来的问题,我们之前提到,当神经网络能够看到整幅图像的时候,识别能力是最准确的,即使VGG13-19网络的感受野都大于了原图,但是,他们的有效感受野并不一定大于原图。我们知道,有效感受野才决定了神经元节点的输出,所以,感受野越大越好,我们不断增大感受野,才能相对增大有效感受野,当有效感受野能够覆盖全图的时候,神经网络的识别能力才是最强的!
四、用感受野来解释深度学习的基本任务
4.1分类网络
4.1.1分类网络的发展

** Resnet网络其本质就是增大特征图的感受野!**
4.1.2 感受野如何影响分类网络(Resnet为例)
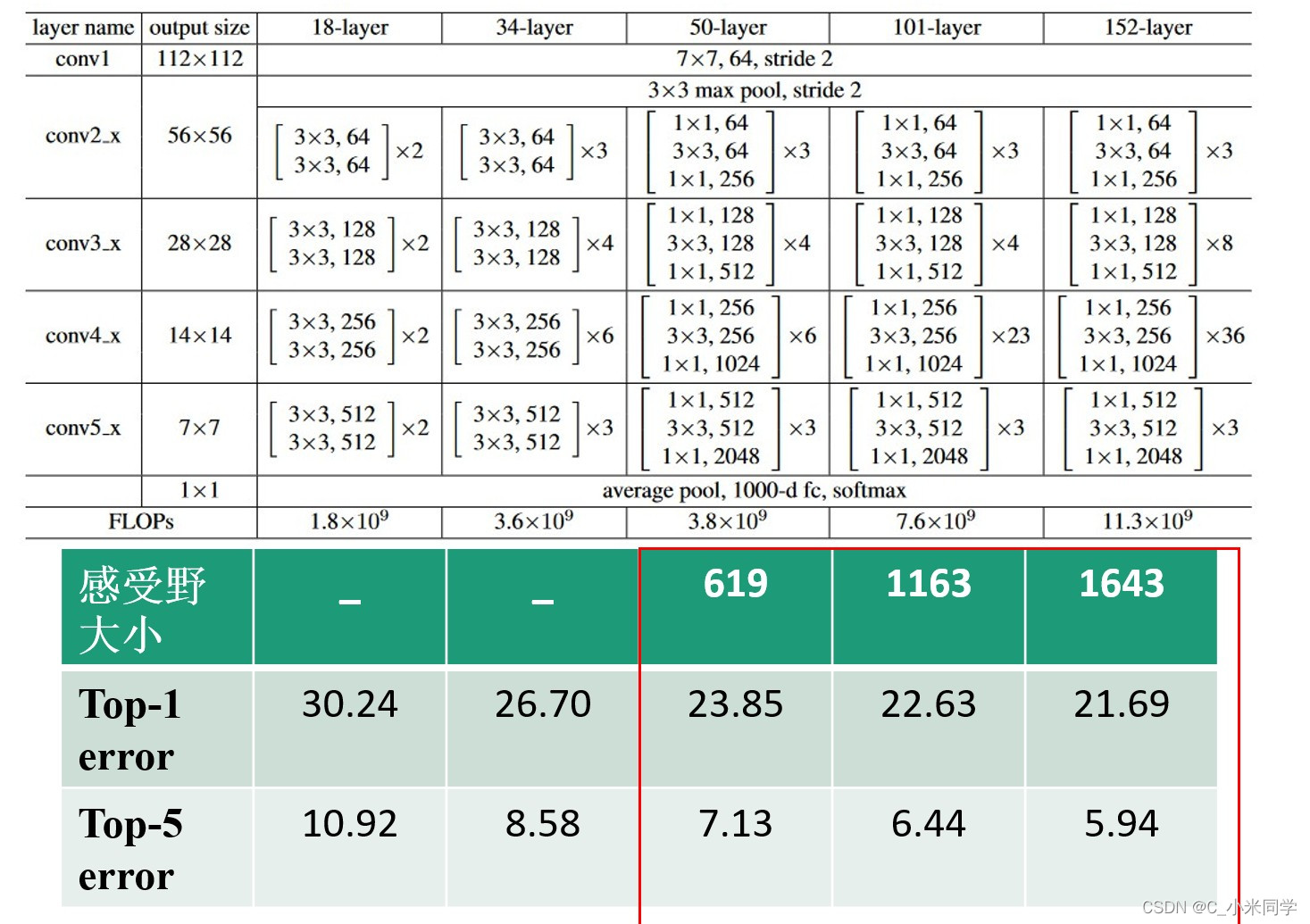
我们可以发现:随着网络层数增多,感受野增大,识别误差减小!
4.1.3感受野是不是越大越好
这里系统说一下:

A.当有效感受野的区域能够覆盖全图时,这时候神经网络的表征能力是最强的。
B.感受野的大小并不完全决定性能,而是和有效感受野相关,而有效感受野的特性由网络结构决定。
C.有效感受野和网络的结构有关,网络结构确定,有效感受野便确定了,所以提高结构的优越性比单纯增加感受野更感受野更加有效。
4.2检测网络
4.2.1检测网络的发展

4.2.2感受野如何影响检测网络
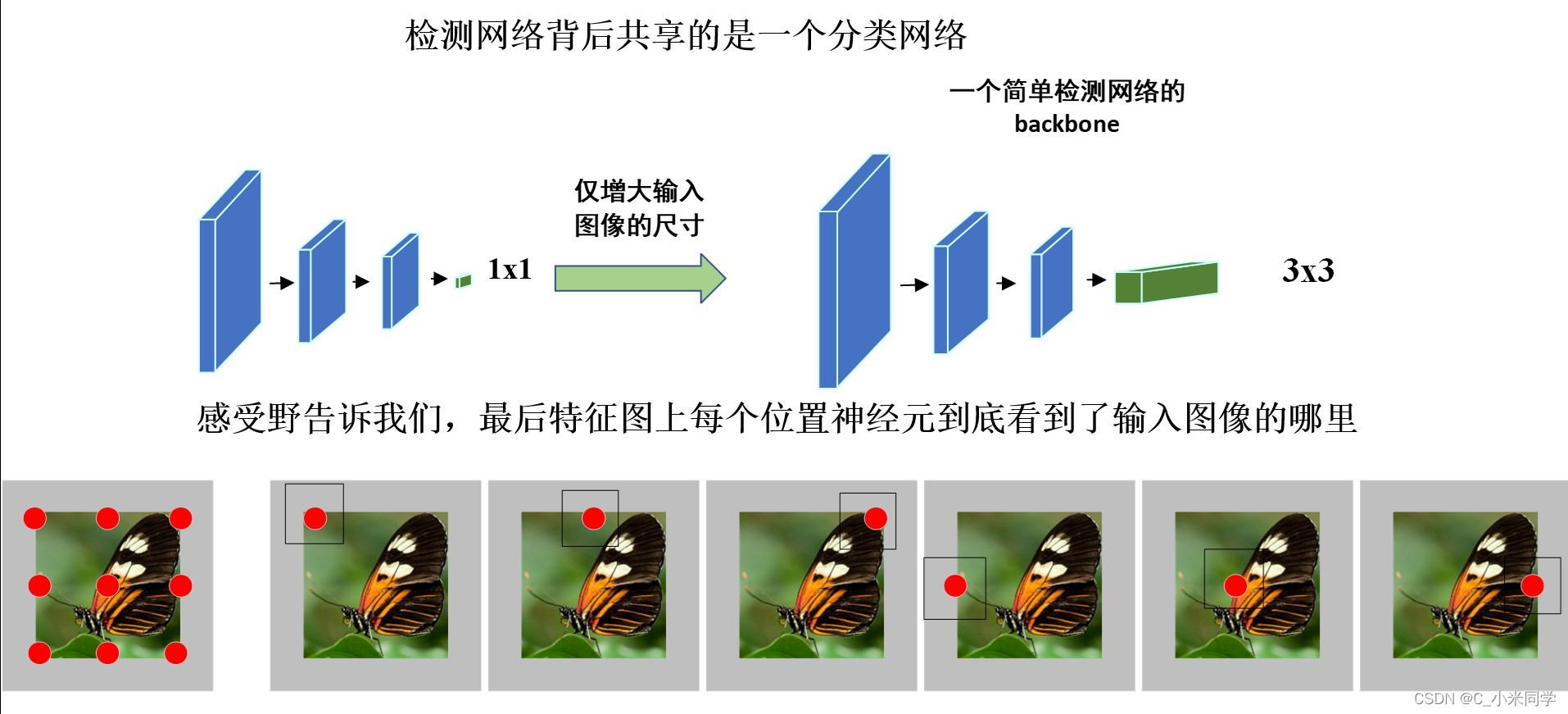
分类网络的输出是一个值,检测网络的输出是多个值(3x3=9个值)。这3x3的输出代表什么?它对应了9个位置的感受野,如上图所示,上面的特征图(蝴蝶),下面是原图(灰色矩形),红色的9个点就是3x3的输出,每个红点对应了原图上的一个区域,这个区域就是感受野。
检测网络的训练,可以视为一种高效率的分类网络训练,框的回归可视为附带干的事情。每个感受野对应一幅输入图像,每个用于预测的神经元节点都会有一个类别标签所有的输入图像都共享着同样一个分类网络。
那么“高效”体现在哪里?
9个值对应9个区域的感受野,就可以识别9个区域的类别。相比图像识别,我们一幅图只能输出一个值,也就是一个类别。
4.3分割网络
4.3.1分割网络的发展

4.3.2你如何设计分割网络
** 我要去确定该该像素的类别,我们怎么做?**
一个像素没有其他的关联信息,很难做出判断,所以我们要以该像素为中心,裁剪出不同大小的图像,然后针对不同大小图像设置单独的分类器(图像的尺寸会影响最后全连接层的设计),最后进行集成(非常耗时,而且效率低,准确率低)。
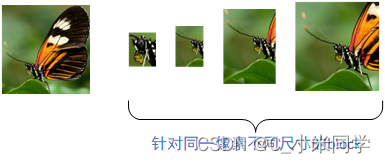
方法****1:针对不同尺寸的block训练单独的分类器,然后将所有的block的分类结果进行集成。
方法1就是上面提到的传统的做法。
方法****2:设计一种网络结构,能够同时耦合不同block的特征表示,然后直接在耦合特征图上进行分类。
我们同时耦合不同的block其实就是耦合不同的感受野,那我们之前提到,什么结构可以耦合不同的感受野?
一种固定大小的感受野就可视为一种尺寸的block,耦合不同大小感受野的特征
A:使用空洞卷积(不同的rate可以获取不同的感受野大小)或直接用Pyramid Pooling,然后跳连或者拼接
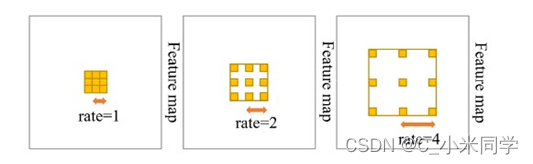
**我们可以控制空洞卷积的rate,来融合不同大小的感受野! **
B:使用encode-decode结构,将encode阶段的特征图拼接至decode阶段的特诊图上。
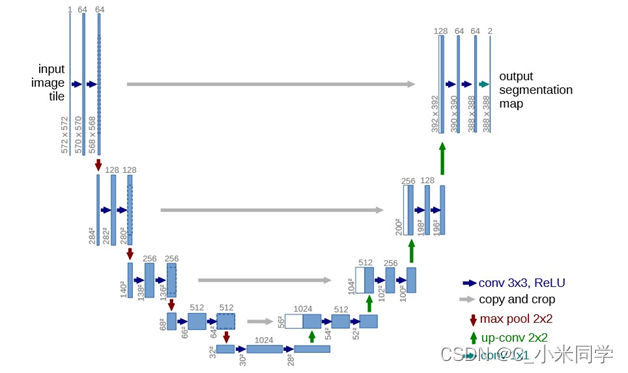
如何高效耦合更多尺寸感受野特征是分割网络考虑的重点
版权归原作者 C_小米同学 所有, 如有侵权,请联系我们删除。