
文章目录
在大数据时代,人们比以往任何时候更能收集到更丰富的数据。但是如果不能对这些数据进行有序、有结构地分类组织和存储,如果不能有效利用并发掘它,继而产生价值,那么它同时也成为一场“灾难”。无序、无结构的数据犹如堆积如山的垃圾,给企业带来的是令人咋舌的高额成本,给数据采集、存储和计算都带来了极大的挑战。
如何有效地满足来自员工、商家、合作伙伴等多样化的需求 ,提高他们对数据使用的满意度,是数据服务和数据产品需要面对的挑战。
以下是阿里巴巴的大数据系统体系架构图,他们企业的大数据架构可分为四层——数据采集、数据计算、数据服务和数据应用。
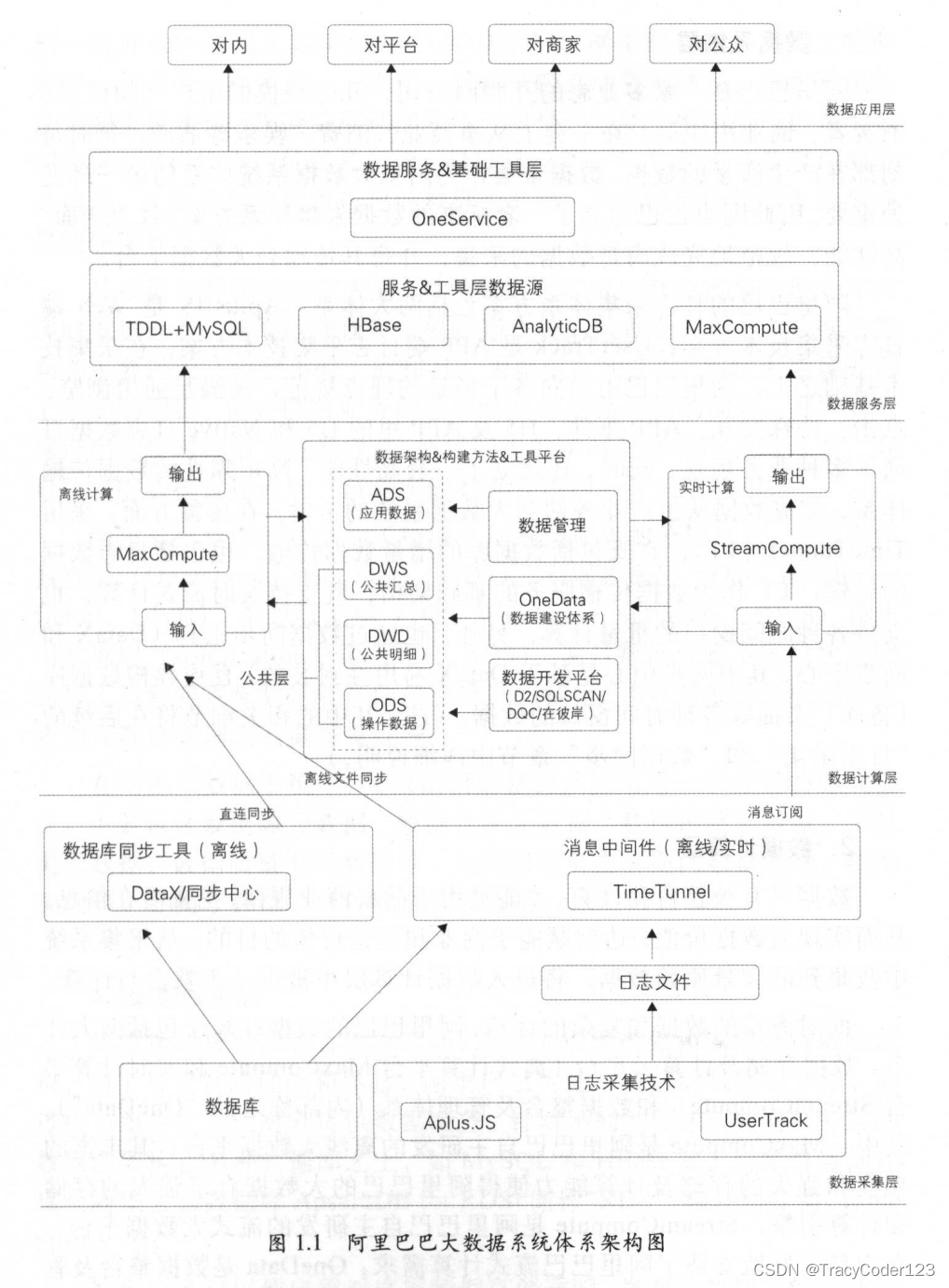
1.数据采集层
阿里巴巴的日志采集体系方案包括两大体系:Aplus.JS Web日志采集技术方案; UserTrack APP 端日志采集技术方案。在采集技术基础之上,阿里巴巴用面向各个场景的埋点规范,来满足通用浏览、点击、特殊交互、 APP 事件、 H5 APP 里的 H5 Native 日志数据打通等多种业务场景。同时,还建立了一套高性能、高可靠性的数据传输体系,完成数据从生产业务端到大数据系统的传输。在传输方面,采用TimeTunnel (TT ),它既包括数据库的增量数据传输,也包括日志数据的传输; TT 作为数据传输服务的基础架构,既支持实时流式计算,也支持各种时间窗口的批量计算。另外,也通过数据同步工具( DataX同步中心,其中同步中心是基于 DataX 易用性封装的)直连异构数据库(备库)来抽取各种时间窗口的数据。
2.数据计算层
从采集系统中收集到的大量原始数据,将进入数据计算层中被进一步整合与计算。
面对海量的数据和复杂的计算,网里巴巴的数据计算层包括两大体系:数据存储及计算云平台(离线计算平台 MaxCompute 和实时计算Strea Compute )和数据整合及管理体系(内部称之为“OneData ”)。其中, Max Compute 是阿里巴巴自主研发的离线大数据平台 ,其丰富的功能和强大的存储及计算能力使得阿里巴巴的大数据有了强大的存储和计算引擎; StreamCompute 是网里巴巴自主研发的流式大数据平台,在内部较好地支持了阿里巴巴流式计算需求: OneData 是数据整合及管理的方法体系和工具,阿里巴巴的大数据工程师在这一体系下,构建统一、规范、可共享的全域数据体系 ,避免数据的冗余和重复建设 ,规避数据烟囱和不一致性,充分发挥间里巴巴在大数据海量、多样性方面的独特优势。
- 数仓分层:
阿里数据仓库的数据加工链路也是遵循业界的分层理念,包括操作数据层( Operational Data Store, ODS )、明细数据层( Data Warehouse Detail , DWD )、汇总数据层( Data Warehouse Summary, DWS )和应用数据层( Application Data Store, ADS )。通过数据仓库不同层次之间的加工过程实现从数据资产向信息资产的转化,并且对整个过程进行有效的元数据管理及数据质量处理。
- 元数据管理:
在阿里大数据系统中,元数据模型整合及应用是一个重要的组成部分,主要包含数据源元数据、数据仓库元数据 、数据链路元数据、工
类元数据 数据质量类元数据等。元数据应 主要面向数据发现、数据管理等 ,如用于存储、计算和成本管理等。
3.数据服务层
当数据已被整合和计算好之后, 需要提供给产品和应用进行数据消费。为了有更好的性能和体验,阿里巴巴构建了自己的数据服务层,通过接口服务化方式对外提供数据服务。针对不同的需求,数据服务层的数据源架构在多种数据库之上,如 MySQL HBase 等。后续将逐渐迁移至阿里云云数据库 ApsaraDB for RDS (简称“ RDS ”)和表格存储( TableStore )等。
数据服务可以使应用对底层数据存储透明,将海量数据方便高效地开放给集团内部各应用使用。
数据服务层对外提供数据服务主要是通过统一的数据服务平台(为方便阅读,简称为“OneService ”)。 One Service 以数据仓库整合计算好的数据作为数据源,对外通过接口的方式提供数据服务,主要提供简单数据查询服务、复杂数据查询服务(承接集团用户识别、用户画像等复杂数据查询服务)和实时数据推送服务 三大特色数据服务。
4.数据应用层
数据已经准备好,需要通过合适的应用提供给用户,让数据最大化地发挥价值。阿里对数据的应用表现在各个方面,如搜索、推荐、广告、金融、信用、保险、文娱、物流等。商家 ,阿里内部的搜索、推荐、广告、金融等平台 ,阿里内部的运营和管理人员等,都是数据应用方; ISV研究机构和社会组织等也可以利用阿里开放的数据能力和技术。
版权归原作者 TracyCoder123 所有, 如有侵权,请联系我们删除。