
文章目录
前言
个人学习笔记,项目代码参考Bubbliiiing的yolov7-pytorch-master版
参考:
1、Pytorch搭建YoloV7目标检测平台 源码
2、最终版本YOLOv1-v7全系列大解析
3、三万字硬核详解:yolov1、yolov2、yolov3、yolov4、yolov5、yolov7
4、yolo系列的Neck模块
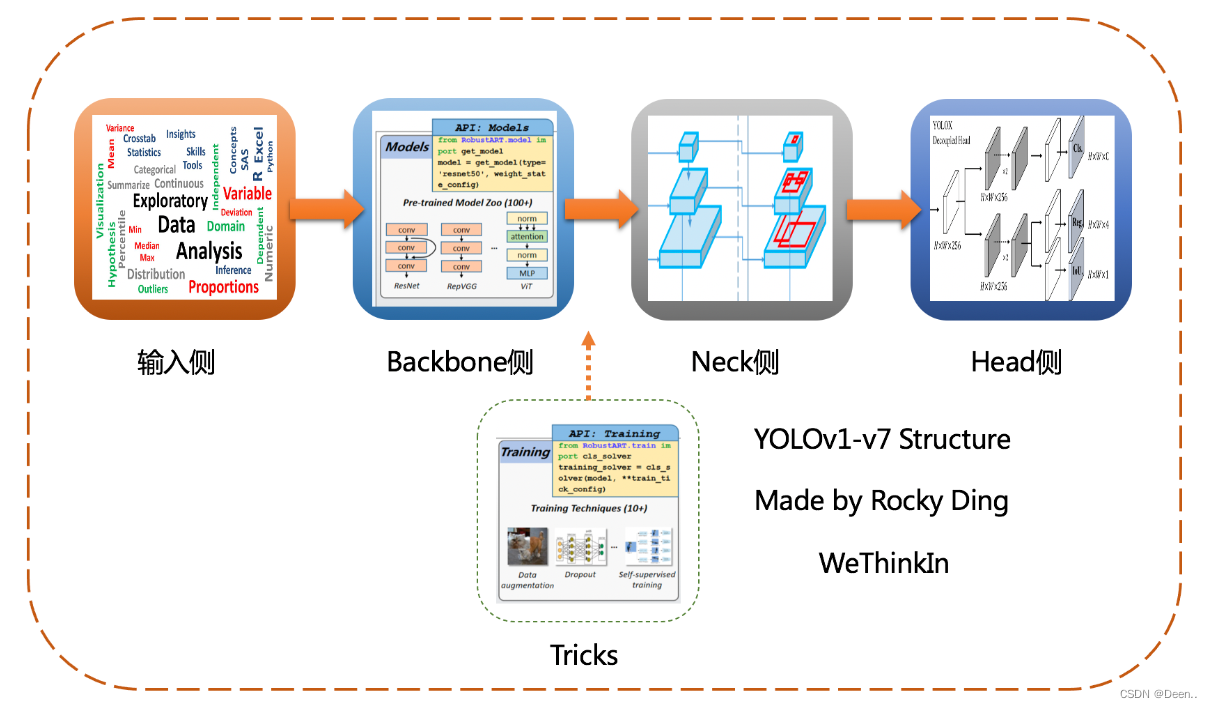 如图所示,yolo系类的结构主要由主干提取结构(Backbone)、特征强化结构(Neck)、检测头(Head)组成,其中各版本用到不同的Tricks,不同的损失函数,不同的锚框的匹配策略等等。
如图所示,yolo系类的结构主要由主干提取结构(Backbone)、特征强化结构(Neck)、检测头(Head)组成,其中各版本用到不同的Tricks,不同的损失函数,不同的锚框的匹配策略等等。
YOLOV7结构
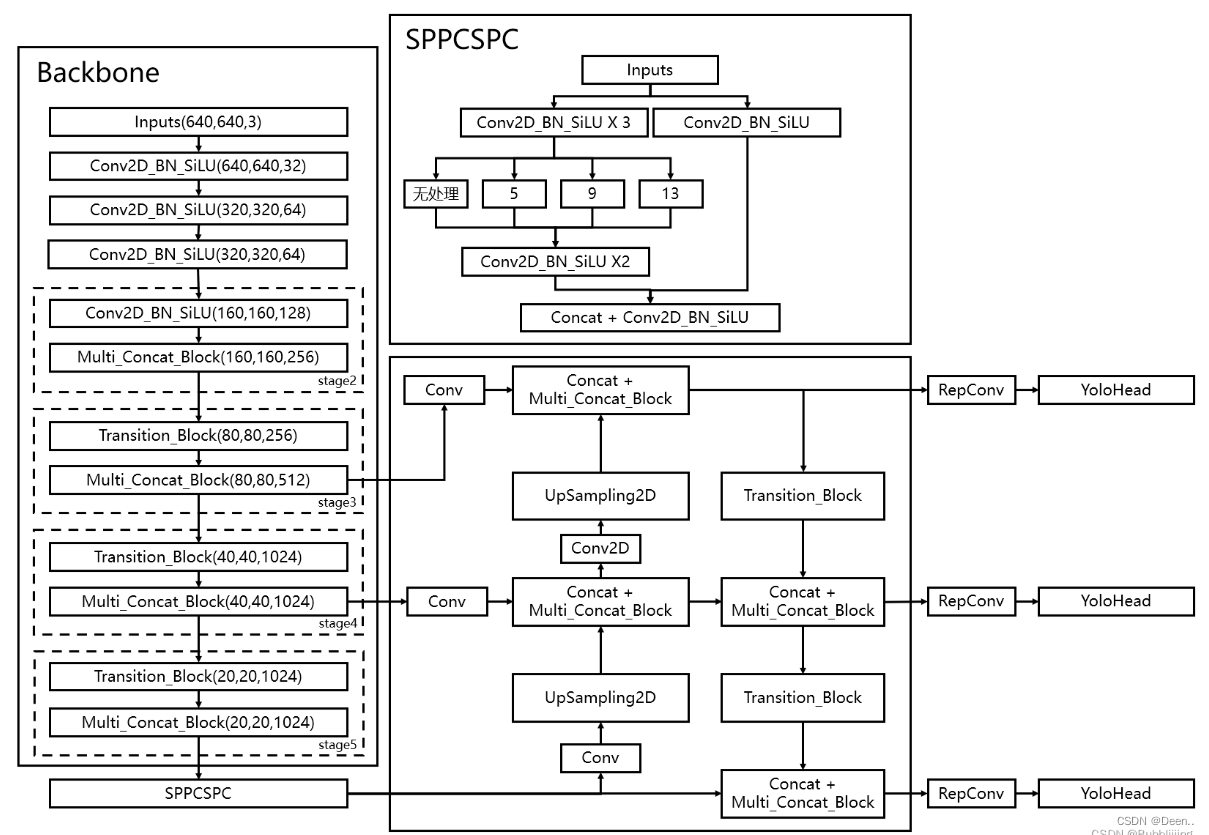 YOLOv7的Backbone结构在YOLOv5的基础上,设计了Multi_Concat_Block和Transition_Block结构
YOLOv7的Backbone结构在YOLOv5的基础上,设计了Multi_Concat_Block和Transition_Block结构
YOLOv7的Neck结构主要包含了SPPSCP模块和优化的PAN模块。
YOLOv7的Head结构使用了和YOLOv5一样的损失函数,引入RepVGG style改造了Head网络结构,并使用了辅助头(auxiliary Head)训练以及相应的正负样本匹配策略。
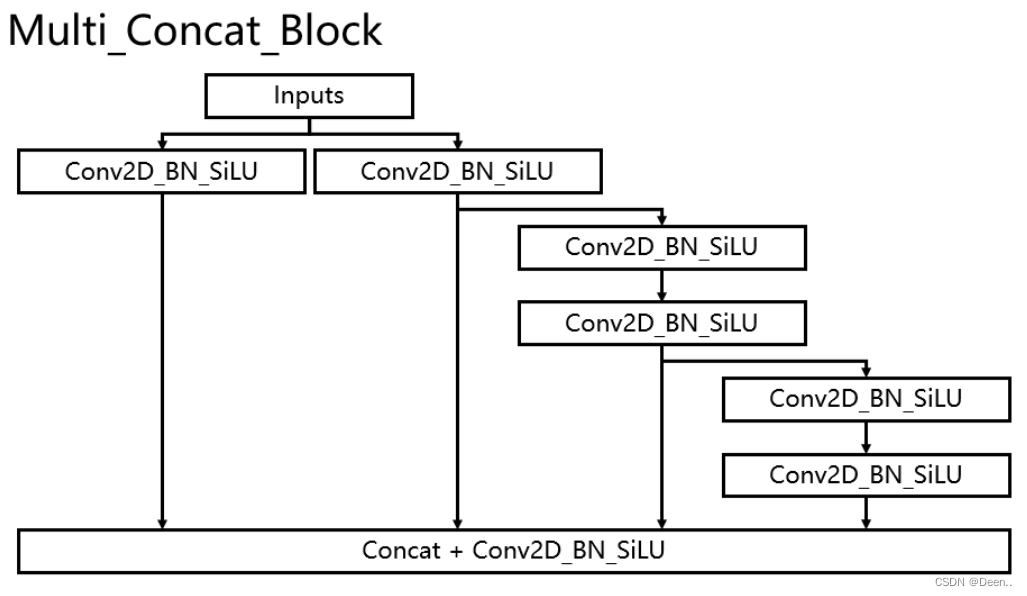
Multi_Concat_Block结构由多个卷积+BN+Silu组合传递。
直接引用参考文章1里的解释:
如此多的堆叠其实也对应了更密集的残差结构,残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。
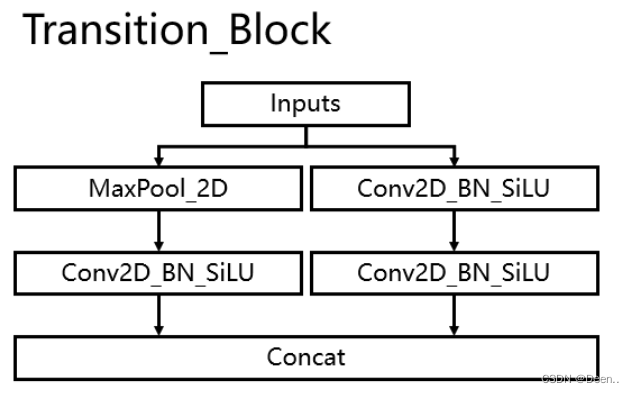
直接引用参考文章1里的解释:
使用创新的过渡模块Transition_Block来进行下采样,在卷积神经网络中,常见的用于下采样的过渡模块是一个卷积核大小为3x3、步长为2x2的卷积或者一个步长为2x2的最大池化。在YoloV7中,作者将两种过渡模块进行了集合,一个过渡模块存在两个分支,如图所示。左分支是一个步长为2x2的最大池化+一个1x1卷积,右分支是一个1x1卷积+一个卷积核大小为3x3、步长为2x2的卷积,两个分支的结果在输出时会进行堆叠。
Backbone
先来看Backbone中用到的几个小模块
Conv2D_BN_SiLU
向前传播时候 按次序经过:卷积+Batch Normalization+SiLU激活函数
classConv(nn.Module):def__init__(self, c1, c2, k=1, s=1, p=None, g=1, act=SiLU()):# ch_in, ch_out, kernel, stride, padding, groupssuper(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2, eps=0.001, momentum=0.03)
self.act = nn.LeakyReLU(0.1, inplace=True)if act isTrueelse(act ifisinstance(act, nn.Module)else nn.Identity())defforward(self, x):return self.act(self.bn(self.conv(x)))deffuseforward(self, x):return self.act(self.conv(x))
激活函数:SiLu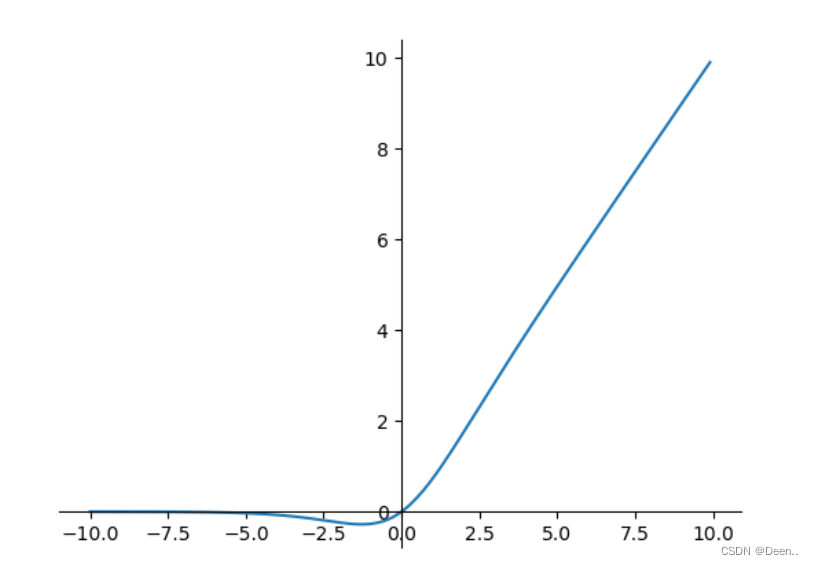
f
(
x
)
=
x
⋅
σ
(
x
)
f(x)=x⋅σ(x)
f(x)=x⋅σ(x)
f
′
(
x
)
=
f
(
x
)
+
σ
(
x
)
(
1
−
f
(
x
)
)
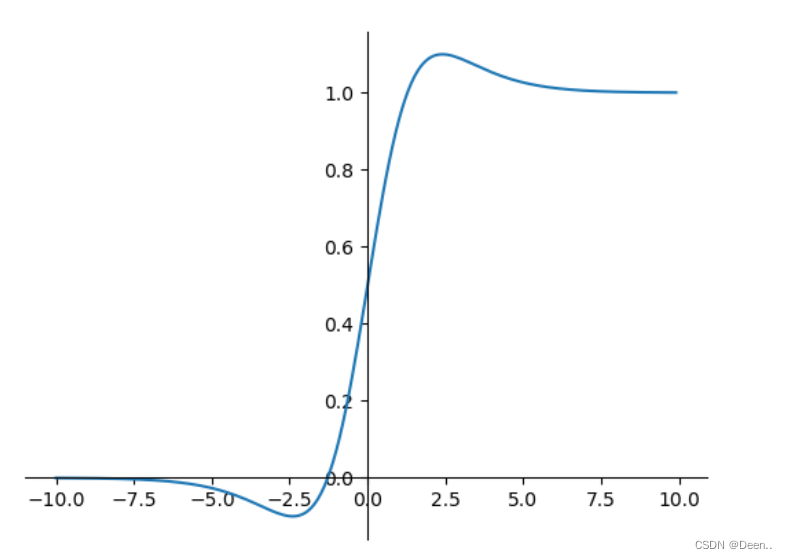
f^{'}(x)=f(x)+σ(x)(1−f(x))
f′(x)=f(x)+σ(x)(1−f(x))
classSiLU(nn.Module):@staticmethoddefforward(x):return x * torch.sigmoid(x)
Multi_Concat_Block
Multi_Concat_Block结构如下图所示:
在代码中,输入图像(input),经过Conv2D_BN_SiLu计算后用一个list全部装起来,然后通过索引ids去检索所需要的torch.cat的输出层。
ids ={'l':[-1,-3,-5,-6],'x':[-1,-3,-5,-7,-8],}[phi]classMulti_Concat_Block(nn.Module):def__init__(self, c1, c2, c3, n=4, e=1, ids=[0]):super(Multi_Concat_Block, self).__init__()
c_ =int(c2 * e)
self.ids = ids
self.cv1 = Conv(c1, c_,1,1)
self.cv2 = Conv(c1, c_,1,1)
self.cv3 = nn.ModuleList([Conv(c_ if i ==0else c2, c2,3,1)for i inrange(n)])
self.cv4 = Conv(c_ *2+ c2 *(len(ids)-2), c3,1,1)defforward(self, x):
x_1 = self.cv1(x)
x_2 = self.cv2(x)
x_all =[x_1, x_2]# [-1, -3, -5, -6] => [5, 3, 1, 0]for i inrange(len(self.cv3)):
x_2 = self.cv3[i](x_2)
x_all.append(x_2)
out = self.cv4(torch.cat([x_all[id]foridin self.ids],1))return out
Transition_Block
具体流程如图:
具体代码如下:
classTransition_Block(nn.Module):def__init__(self, c1, c2):super(Transition_Block, self).__init__()
self.cv1 = Conv(c1, c2,1,1)
self.cv2 = Conv(c1, c2,1,1)
self.cv3 = Conv(c2, c2,3,2)
self.mp = MP()defforward(self, x):# 160, 160, 256 => 80, 80, 256 => 80, 80, 128
x_1 = self.mp(x)
x_1 = self.cv1(x_1)# 160, 160, 256 => 160, 160, 128 => 80, 80, 128
x_2 = self.cv2(x)
x_2 = self.cv3(x_2)# 80, 80, 128 cat 80, 80, 128 => 80, 80, 256return torch.cat([x_2, x_1],1)
Backbone结构
在项目代码中Backbone用nn.Sequential一步一步的将每个细节存起来。
nn.Sequential是一个有序的容器,神经网络模块将按照在传入构造器的顺序依次被添加到计算图中执行,同时以神经网络模块为元素的有序字典也可以作为传入参数。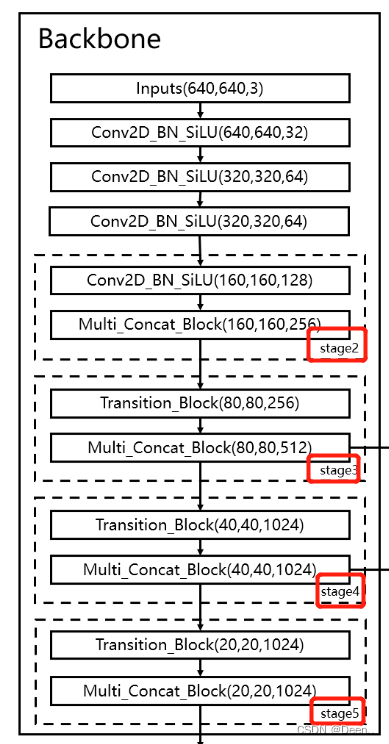
Backebone再返回3个特征层,用以和特征强化网络torch.cat,特征融合,这一部分像残差网络的操作,可以增强有效信息的提取,缓解梯度消失或爆炸问题,同时,渐层拥有大感受野,深层拥有更强的特征提取效果,结合在一起对于目标检测更加有效。
classBackbone(nn.Module):def__init__(self, transition_channels, block_channels, n, phi, pretrained=False):super().__init__()#-----------------------------------------------## 输入图片是640, 640, 3#-----------------------------------------------#
ids ={'l':[-1,-3,-5,-6],'x':[-1,-3,-5,-7,-8],}[phi]# 640, 640, 3 => 640, 640, 32 => 320, 320, 64
self.stem = nn.Sequential(
Conv(3, transition_channels,3,1),
Conv(transition_channels, transition_channels *2,3,2),
Conv(transition_channels *2, transition_channels *2,3,1),)# 320, 320, 64 => 160, 160, 128 => 160, 160, 256
self.dark2 = nn.Sequential(
Conv(transition_channels *2, transition_channels *4,3,2),
Multi_Concat_Block(transition_channels *4, block_channels *2, transition_channels *8, n=n, ids=ids),)# 160, 160, 256 => 80, 80, 256 => 80, 80, 512
self.dark3 = nn.Sequential(
Transition_Block(transition_channels *8, transition_channels *4),
Multi_Concat_Block(transition_channels *8, block_channels *4, transition_channels *16, n=n, ids=ids),)# 80, 80, 512 => 40, 40, 512 => 40, 40, 1024
self.dark4 = nn.Sequential(
Transition_Block(transition_channels *16, transition_channels *8),
Multi_Concat_Block(transition_channels *16, block_channels *8, transition_channels *32, n=n, ids=ids),)# 40, 40, 1024 => 20, 20, 1024 => 20, 20, 1024
self.dark5 = nn.Sequential(
Transition_Block(transition_channels *32, transition_channels *16),
Multi_Concat_Block(transition_channels *32, block_channels *8, transition_channels *32, n=n, ids=ids),defforward(self, x):
x = self.stem(x)
x = self.dark2(x)#-----------------------------------------------## dark3的输出为80, 80, 512,是一个有效特征层#-----------------------------------------------#
x = self.dark3(x)
feat1 = x
#-----------------------------------------------## dark4的输出为40, 40, 1024,是一个有效特征层#-----------------------------------------------#
x = self.dark4(x)
feat2 = x
#-----------------------------------------------## dark5的输出为20, 20, 1024,是一个有效特征层#-----------------------------------------------#
x = self.dark5(x)
feat3 = x
return feat1, feat2, feat3
)
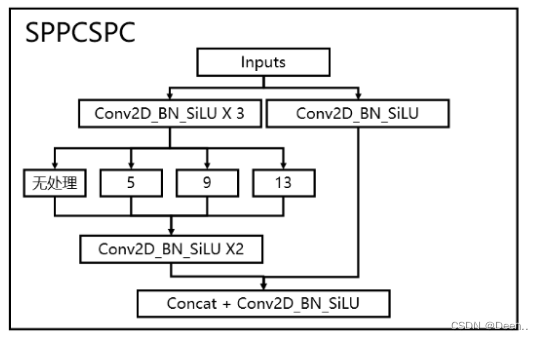
SPPCSPC
在Backbone特征提取后经过SPPCSPC进入特征强化网络,具体为将Backbone提出处理的数据经过3次Conv2D_BN_SiLU后,下一步单独进行3次池化: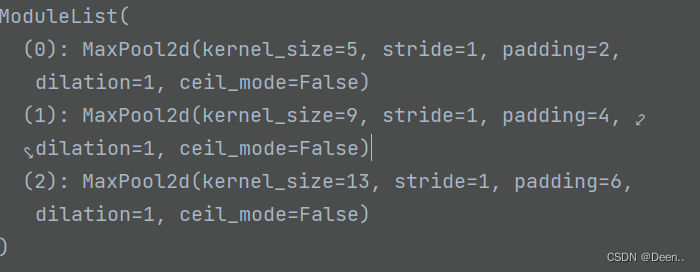
再将池化结构torch.cat合并到一起,再与Backbone输出图像仅通过一次Conv2D_BN_SiLU的结构torch.cat在一起,完成此步操作。
classSPPCSPC(nn.Module):# CSP https://github.com/WongKinYiu/CrossStagePartialNetworksdef__init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=(5,9,13)):super(SPPCSPC, self).__init__()
c_ =int(2* c2 * e)# hidden channels
self.cv1 = Conv(c1, c_,1,1)
self.cv2 = Conv(c1, c_,1,1)
self.cv3 = Conv(c_, c_,3,1)
self.cv4 = Conv(c_, c_,1,1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x //2)for x in k])
self.cv5 = Conv(4* c_, c_,1,1)
self.cv6 = Conv(c_, c_,3,1)# 输出通道数为c2
self.cv7 = Conv(2* c_, c2,1,1)defforward(self, x):
x1 = self.cv4(self.cv3(self.cv1(x)))
y1 = self.cv6(self.cv5(torch.cat([x1]+[m(x1)for m in self.m],1)))
y2 = self.cv2(x)return self.cv7(torch.cat((y1, y2), dim=1))
Neck(特征强化结构)
从下图可看出Neck网络由FPN跟PAN构成,以知乎江大白的示意图为例,YOLOv4开始应用了该技术。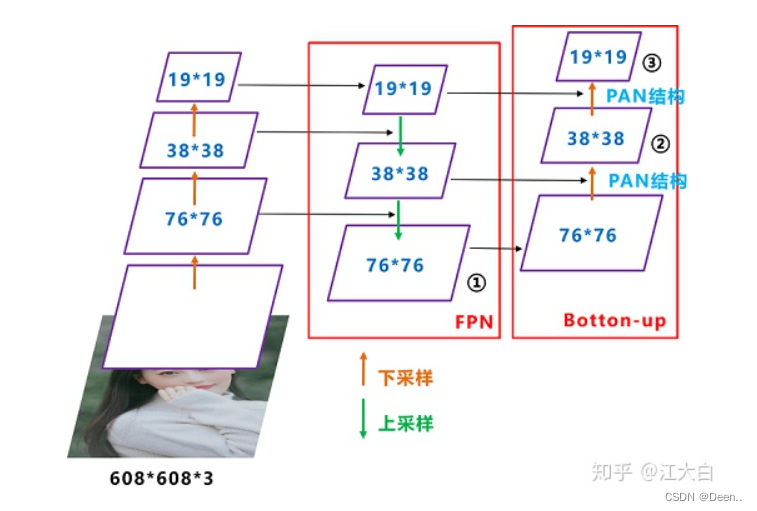
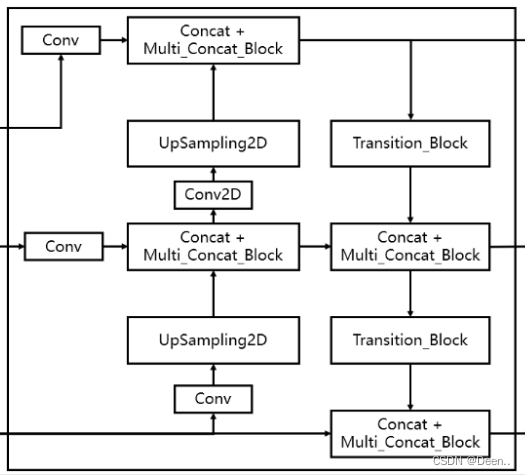
SPPCSPC输出后经过一次卷积一次上采样,再与backbone的返回的特征层进行融合,融合在进行同样的操作一次。完成FPN结构操作。PAN的下采样用的Transition_Block模块,如结构图所示,下采样后融合在卷积,再次下采用,再融合卷积。最后输出三个检测头。
# backbone
feat1, feat2, feat3 = self.backbone.forward(x)#------------------------加强特征提取网络------------------------# # 20, 20, 1024 => 20, 20, 512
P5 = self.sppcspc(feat3)# 20, 20, 512 => 20, 20, 256
P5_conv = self.conv_for_P5(P5)# 20, 20, 256 => 40, 40, 256
P5_upsample = self.upsample(P5_conv)# 40, 40, 256 cat 40, 40, 256 => 40, 40, 512
P4 = torch.cat([self.conv_for_feat2(feat2), P5_upsample],1)# 40, 40, 512 => 40, 40, 256
P4 = self.conv3_for_upsample1(P4)# 40, 40, 256 => 40, 40, 128
P4_conv = self.conv_for_P4(P4)# 40, 40, 128 => 80, 80, 128
P4_upsample = self.upsample(P4_conv)# 80, 80, 128 cat 80, 80, 128 => 80, 80, 256
P3 = torch.cat([self.conv_for_feat1(feat1), P4_upsample],1)# 80, 80, 256 => 80, 80, 128
P3 = self.conv3_for_upsample2(P3)# 80, 80, 128 => 40, 40, 256
P3_downsample = self.down_sample1(P3)# 40, 40, 256 cat 40, 40, 256 => 40, 40, 512
P4 = torch.cat([P3_downsample, P4],1)# 40, 40, 512 => 40, 40, 256
P4 = self.conv3_for_downsample1(P4)# 40, 40, 256 => 20, 20, 512
P4_downsample = self.down_sample2(P4)# 20, 20, 512 cat 20, 20, 512 => 20, 20, 1024
P5 = torch.cat([P4_downsample, P5],1)# 20, 20, 1024 => 20, 20, 512
P5 = self.conv3_for_downsample2(P5)
Head(检测头)
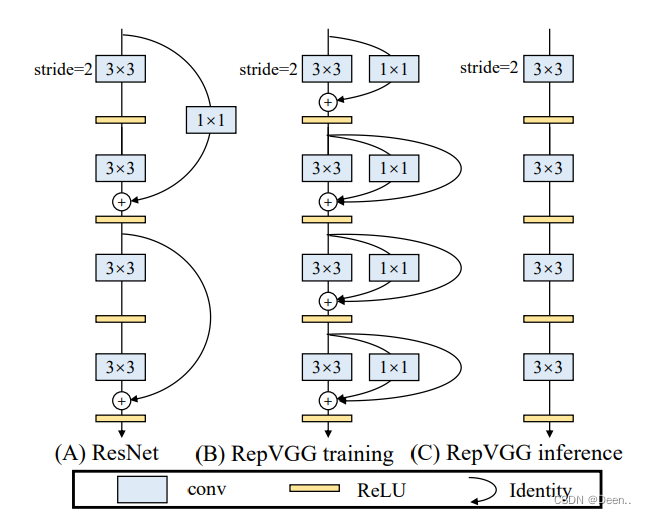
特征加强网络得到的特征层分别经过RepConv处理后,再按YoLo格式【len(anchors_mask[2]) * (5 + num_classes)】转换。
RepVGG style在训练过程中可以通过多路分支提升性能,推理可以通过结构重新参数化实现推理速度的加快。
YOLOV的时候首次将Rep-PAN引入PAN模块,RepBlock替换了YOLOv5中使用的CSP-Block,同时对整体Neck中的算子进行了调整,目的是在硬件上达到高效推理的同时,保持较好的多尺度特征融合能力。
YOLOV6:

RepBlock结构如图所示: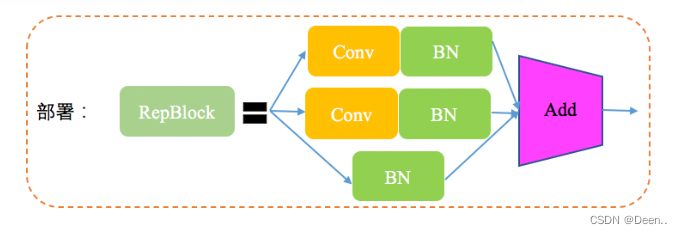
self.yolo_head_P3 = nn.Conv2d(transition_channels *8,len(anchors_mask[2])*(5+ num_classes),1)# 40, 40, 512 => 40, 40, 3 * 25 & 85
self.yolo_head_P4 = nn.Conv2d(transition_channels *16,len(anchors_mask[1])*(5+ num_classes),1)# 20, 20, 512 => 20, 20, 3 * 25 & 85
self.yolo_head_P5 = nn.Conv2d(transition_channels *32,len(anchors_mask[0])*(5+ num_classes),1)
P3 = self.rep_conv_1(P3)
P4 = self.rep_conv_2(P4)
P5 = self.rep_conv_3(P5)#---------------------------------------------------## 第三个特征层# y3=(batch_size, 75, 80, 80)#---------------------------------------------------#
out2 = self.yolo_head_P3(P3)#---------------------------------------------------## 第二个特征层# y2=(batch_size, 75, 40, 40)#---------------------------------------------------#
out1 = self.yolo_head_P4(P4)#---------------------------------------------------## 第一个特征层# y1=(batch_size, 75, 20, 20)#---------------------------------------------------#
out0 = self.yolo_head_P5(P5)return[out0, out1, out2]
再将输出结构返回,用以Loss计算,以及梯度下降,参数更新。
RepConv代码如下:
classRepConv(nn.Module):# Represented convolution# https://arxiv.org/abs/2101.03697def__init__(self, c1, c2, k=3, s=1, p=None, g=1, act=SiLU(), deploy=False):super(RepConv, self).__init__()
self.deploy = deploy
self.groups = g
self.in_channels = c1
self.out_channels = c2
assert k ==3assert autopad(k, p)==1
padding_11 = autopad(k, p)- k //2
self.act = nn.LeakyReLU(0.1, inplace=True)if act isTrueelse(act ifisinstance(act, nn.Module)else nn.Identity())if deploy:
self.rbr_reparam = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=True)else:
self.rbr_identity =(nn.BatchNorm2d(num_features=c1, eps=0.001, momentum=0.03)if c2 == c1 and s ==1elseNone)
self.rbr_dense = nn.Sequential(
nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False),
nn.BatchNorm2d(num_features=c2, eps=0.001, momentum=0.03),)
self.rbr_1x1 = nn.Sequential(
nn.Conv2d( c1, c2,1, s, padding_11, groups=g, bias=False),
nn.BatchNorm2d(num_features=c2, eps=0.001, momentum=0.03),)defforward(self, inputs):ifhasattr(self,"rbr_reparam"):return self.act(self.rbr_reparam(inputs))if self.rbr_identity isNone:
id_out =0else:
id_out = self.rbr_identity(inputs)return self.act(self.rbr_dense(inputs)+ self.rbr_1x1(inputs)+ id_out)defget_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)return(
kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1)+ kernelid,
bias3x3 + bias1x1 + biasid,)def_pad_1x1_to_3x3_tensor(self, kernel1x1):if kernel1x1 isNone:return0else:return nn.functional.pad(kernel1x1,[1,1,1,1])def_fuse_bn_tensor(self, branch):if branch isNone:return0,0ifisinstance(branch, nn.Sequential):
kernel = branch[0].weight
running_mean = branch[1].running_mean
running_var = branch[1].running_var
gamma = branch[1].weight
beta = branch[1].bias
eps = branch[1].eps
else:assertisinstance(branch, nn.BatchNorm2d)ifnothasattr(self,"id_tensor"):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim,3,3), dtype=np.float32
)for i inrange(self.in_channels):
kernel_value[i, i % input_dim,1,1]=1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std =(running_var + eps).sqrt()
t =(gamma / std).reshape(-1,1,1,1)return kernel * t, beta - running_mean * gamma / std
defrepvgg_convert(self):
kernel, bias = self.get_equivalent_kernel_bias()return(
kernel.detach().cpu().numpy(),
bias.detach().cpu().numpy(),)deffuse_conv_bn(self, conv, bn):
std =(bn.running_var + bn.eps).sqrt()
bias = bn.bias - bn.running_mean * bn.weight / std
t =(bn.weight / std).reshape(-1,1,1,1)
weights = conv.weight * t
bn = nn.Identity()
conv = nn.Conv2d(in_channels = conv.in_channels,
out_channels = conv.out_channels,
kernel_size = conv.kernel_size,
stride=conv.stride,
padding = conv.padding,
dilation = conv.dilation,
groups = conv.groups,
bias =True,
padding_mode = conv.padding_mode)
conv.weight = torch.nn.Parameter(weights)
conv.bias = torch.nn.Parameter(bias)return conv
deffuse_repvgg_block(self):if self.deploy:returnprint(f"RepConv.fuse_repvgg_block")
self.rbr_dense = self.fuse_conv_bn(self.rbr_dense[0], self.rbr_dense[1])
self.rbr_1x1 = self.fuse_conv_bn(self.rbr_1x1[0], self.rbr_1x1[1])
rbr_1x1_bias = self.rbr_1x1.bias
weight_1x1_expanded = torch.nn.functional.pad(self.rbr_1x1.weight,[1,1,1,1])# Fuse self.rbr_identityif(isinstance(self.rbr_identity, nn.BatchNorm2d)orisinstance(self.rbr_identity, nn.modules.batchnorm.SyncBatchNorm)):
identity_conv_1x1 = nn.Conv2d(
in_channels=self.in_channels,
out_channels=self.out_channels,
kernel_size=1,
stride=1,
padding=0,
groups=self.groups,
bias=False)
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.to(self.rbr_1x1.weight.data.device)
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.squeeze().squeeze()
identity_conv_1x1.weight.data.fill_(0.0)
identity_conv_1x1.weight.data.fill_diagonal_(1.0)
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.unsqueeze(2).unsqueeze(3)
identity_conv_1x1 = self.fuse_conv_bn(identity_conv_1x1, self.rbr_identity)
bias_identity_expanded = identity_conv_1x1.bias
weight_identity_expanded = torch.nn.functional.pad(identity_conv_1x1.weight,[1,1,1,1])else:
bias_identity_expanded = torch.nn.Parameter( torch.zeros_like(rbr_1x1_bias))
weight_identity_expanded = torch.nn.Parameter( torch.zeros_like(weight_1x1_expanded))
self.rbr_dense.weight = torch.nn.Parameter(self.rbr_dense.weight + weight_1x1_expanded + weight_identity_expanded)
self.rbr_dense.bias = torch.nn.Parameter(self.rbr_dense.bias + rbr_1x1_bias + bias_identity_expanded)
self.rbr_reparam = self.rbr_dense
self.deploy =Trueif self.rbr_identity isnotNone:del self.rbr_identity
self.rbr_identity =Noneif self.rbr_1x1 isnotNone:del self.rbr_1x1
self.rbr_1x1 =Noneif self.rbr_dense isnotNone:del self.rbr_dense
self.rbr_dense =None
全部代码:
yolo模型代码
import numpy as np
import torch
import torch.nn as nn
from nets.backbone import Backbone, Multi_Concat_Block, Conv, SiLU, Transition_Block, autopad
classSPPCSPC(nn.Module):# CSP https://github.com/WongKinYiu/CrossStagePartialNetworksdef__init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=(5,9,13)):super(SPPCSPC, self).__init__()
c_ =int(2* c2 * e)# hidden channels
self.cv1 = Conv(c1, c_,1,1)
self.cv2 = Conv(c1, c_,1,1)
self.cv3 = Conv(c_, c_,3,1)
self.cv4 = Conv(c_, c_,1,1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x //2)for x in k])
self.cv5 = Conv(4* c_, c_,1,1)
self.cv6 = Conv(c_, c_,3,1)# 输出通道数为c2
self.cv7 = Conv(2* c_, c2,1,1)defforward(self, x):
x1 = self.cv4(self.cv3(self.cv1(x)))
y1 = self.cv6(self.cv5(torch.cat([x1]+[m(x1)for m in self.m],1)))
y2 = self.cv2(x)return self.cv7(torch.cat((y1, y2), dim=1))classRepConv(nn.Module):# Represented convolution# https://arxiv.org/abs/2101.03697def__init__(self, c1, c2, k=3, s=1, p=None, g=1, act=SiLU(), deploy=False):super(RepConv, self).__init__()
self.deploy = deploy
self.groups = g
self.in_channels = c1
self.out_channels = c2
assert k ==3assert autopad(k, p)==1
padding_11 = autopad(k, p)- k //2
self.act = nn.LeakyReLU(0.1, inplace=True)if act isTrueelse(act ifisinstance(act, nn.Module)else nn.Identity())if deploy:
self.rbr_reparam = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=True)else:
self.rbr_identity =(nn.BatchNorm2d(num_features=c1, eps=0.001, momentum=0.03)if c2 == c1 and s ==1elseNone)
self.rbr_dense = nn.Sequential(
nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False),
nn.BatchNorm2d(num_features=c2, eps=0.001, momentum=0.03),)
self.rbr_1x1 = nn.Sequential(
nn.Conv2d( c1, c2,1, s, padding_11, groups=g, bias=False),
nn.BatchNorm2d(num_features=c2, eps=0.001, momentum=0.03),)defforward(self, inputs):ifhasattr(self,"rbr_reparam"):return self.act(self.rbr_reparam(inputs))if self.rbr_identity isNone:
id_out =0else:
id_out = self.rbr_identity(inputs)return self.act(self.rbr_dense(inputs)+ self.rbr_1x1(inputs)+ id_out)defget_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)return(
kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1)+ kernelid,
bias3x3 + bias1x1 + biasid,)def_pad_1x1_to_3x3_tensor(self, kernel1x1):if kernel1x1 isNone:return0else:return nn.functional.pad(kernel1x1,[1,1,1,1])def_fuse_bn_tensor(self, branch):if branch isNone:return0,0ifisinstance(branch, nn.Sequential):
kernel = branch[0].weight
running_mean = branch[1].running_mean
running_var = branch[1].running_var
gamma = branch[1].weight
beta = branch[1].bias
eps = branch[1].eps
else:assertisinstance(branch, nn.BatchNorm2d)ifnothasattr(self,"id_tensor"):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim,3,3), dtype=np.float32
)for i inrange(self.in_channels):
kernel_value[i, i % input_dim,1,1]=1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std =(running_var + eps).sqrt()
t =(gamma / std).reshape(-1,1,1,1)return kernel * t, beta - running_mean * gamma / std
defrepvgg_convert(self):
kernel, bias = self.get_equivalent_kernel_bias()return(
kernel.detach().cpu().numpy(),
bias.detach().cpu().numpy(),)deffuse_conv_bn(self, conv, bn):
std =(bn.running_var + bn.eps).sqrt()
bias = bn.bias - bn.running_mean * bn.weight / std
t =(bn.weight / std).reshape(-1,1,1,1)
weights = conv.weight * t
bn = nn.Identity()
conv = nn.Conv2d(in_channels = conv.in_channels,
out_channels = conv.out_channels,
kernel_size = conv.kernel_size,
stride=conv.stride,
padding = conv.padding,
dilation = conv.dilation,
groups = conv.groups,
bias =True,
padding_mode = conv.padding_mode)
conv.weight = torch.nn.Parameter(weights)
conv.bias = torch.nn.Parameter(bias)return conv
deffuse_repvgg_block(self):if self.deploy:returnprint(f"RepConv.fuse_repvgg_block")
self.rbr_dense = self.fuse_conv_bn(self.rbr_dense[0], self.rbr_dense[1])
self.rbr_1x1 = self.fuse_conv_bn(self.rbr_1x1[0], self.rbr_1x1[1])
rbr_1x1_bias = self.rbr_1x1.bias
weight_1x1_expanded = torch.nn.functional.pad(self.rbr_1x1.weight,[1,1,1,1])# Fuse self.rbr_identityif(isinstance(self.rbr_identity, nn.BatchNorm2d)orisinstance(self.rbr_identity, nn.modules.batchnorm.SyncBatchNorm)):
identity_conv_1x1 = nn.Conv2d(
in_channels=self.in_channels,
out_channels=self.out_channels,
kernel_size=1,
stride=1,
padding=0,
groups=self.groups,
bias=False)
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.to(self.rbr_1x1.weight.data.device)
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.squeeze().squeeze()
identity_conv_1x1.weight.data.fill_(0.0)
identity_conv_1x1.weight.data.fill_diagonal_(1.0)
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.unsqueeze(2).unsqueeze(3)
identity_conv_1x1 = self.fuse_conv_bn(identity_conv_1x1, self.rbr_identity)
bias_identity_expanded = identity_conv_1x1.bias
weight_identity_expanded = torch.nn.functional.pad(identity_conv_1x1.weight,[1,1,1,1])else:
bias_identity_expanded = torch.nn.Parameter( torch.zeros_like(rbr_1x1_bias))
weight_identity_expanded = torch.nn.Parameter( torch.zeros_like(weight_1x1_expanded))
self.rbr_dense.weight = torch.nn.Parameter(self.rbr_dense.weight + weight_1x1_expanded + weight_identity_expanded)
self.rbr_dense.bias = torch.nn.Parameter(self.rbr_dense.bias + rbr_1x1_bias + bias_identity_expanded)
self.rbr_reparam = self.rbr_dense
self.deploy =Trueif self.rbr_identity isnotNone:del self.rbr_identity
self.rbr_identity =Noneif self.rbr_1x1 isnotNone:del self.rbr_1x1
self.rbr_1x1 =Noneif self.rbr_dense isnotNone:del self.rbr_dense
self.rbr_dense =Nonedeffuse_conv_and_bn(conv, bn):
fusedconv = nn.Conv2d(conv.in_channels,
conv.out_channels,
kernel_size=conv.kernel_size,
stride=conv.stride,
padding=conv.padding,
groups=conv.groups,
bias=True).requires_grad_(False).to(conv.weight.device)
w_conv = conv.weight.clone().view(conv.out_channels,-1)
w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps + bn.running_var)))# fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.shape))
fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.shape).detach())
b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device)if conv.bias isNoneelse conv.bias
b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))# fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn)
fusedconv.bias.copy_((torch.mm(w_bn, b_conv.reshape(-1,1)).reshape(-1)+ b_bn).detach())return fusedconv
#---------------------------------------------------## yolo_body#---------------------------------------------------#classYoloBody(nn.Module):def__init__(self, anchors_mask, num_classes, phi, pretrained=False):super(YoloBody, self).__init__()#-----------------------------------------------## 定义了不同yolov7版本的参数#-----------------------------------------------#
transition_channels ={'l':32,'x':40}[phi]
block_channels =32
panet_channels ={'l':32,'x':64}[phi]
e ={'l':2,'x':1}[phi]
n ={'l':4,'x':6}[phi]
ids ={'l':[-1,-2,-3,-4,-5,-6],'x':[-1,-3,-5,-7,-8]}[phi]
conv ={'l': RepConv,'x': Conv}[phi]#-----------------------------------------------## 输入图片是640, 640, 3#-----------------------------------------------##---------------------------------------------------# # 生成主干模型# 获得三个有效特征层,他们的shape分别是:# 80, 80, 512# 40, 40, 1024# 20, 20, 1024#---------------------------------------------------#
self.backbone = Backbone(transition_channels, block_channels, n, phi, pretrained=pretrained)#------------------------加强特征提取网络------------------------#
self.upsample = nn.Upsample(scale_factor=2, mode="nearest")# 20, 20, 1024 => 20, 20, 512
self.sppcspc = SPPCSPC(transition_channels *32, transition_channels *16)# 20, 20, 512 => 20, 20, 256 => 40, 40, 256
self.conv_for_P5 = Conv(transition_channels *16, transition_channels *8)# 40, 40, 1024 => 40, 40, 256
self.conv_for_feat2 = Conv(transition_channels *32, transition_channels *8)# 40, 40, 512 => 40, 40, 256
self.conv3_for_upsample1 = Multi_Concat_Block(transition_channels *16, panet_channels *4, transition_channels *8, e=e, n=n, ids=ids)# 40, 40, 256 => 40, 40, 128 => 80, 80, 128
self.conv_for_P4 = Conv(transition_channels *8, transition_channels *4)# 80, 80, 512 => 80, 80, 128
self.conv_for_feat1 = Conv(transition_channels *16, transition_channels *4)# 80, 80, 256 => 80, 80, 128
self.conv3_for_upsample2 = Multi_Concat_Block(transition_channels *8, panet_channels *2, transition_channels *4, e=e, n=n, ids=ids)# 80, 80, 128 => 40, 40, 256
self.down_sample1 = Transition_Block(transition_channels *4, transition_channels *4)# 40, 40, 512 => 40, 40, 256
self.conv3_for_downsample1 = Multi_Concat_Block(transition_channels *16, panet_channels *4, transition_channels *8, e=e, n=n, ids=ids)# 40, 40, 256 => 20, 20, 512
self.down_sample2 = Transition_Block(transition_channels *8, transition_channels *8)# 20, 20, 1024 => 20, 20, 512
self.conv3_for_downsample2 = Multi_Concat_Block(transition_channels *32, panet_channels *8, transition_channels *16, e=e, n=n, ids=ids)#------------------------加强特征提取网络------------------------# # 80, 80, 128 => 80, 80, 256
self.rep_conv_1 = conv(transition_channels *4, transition_channels *8,3,1)# 40, 40, 256 => 40, 40, 512
self.rep_conv_2 = conv(transition_channels *8, transition_channels *16,3,1)# 20, 20, 512 => 20, 20, 1024
self.rep_conv_3 = conv(transition_channels *16, transition_channels *32,3,1)# 4 + 1 + num_classes# 80, 80, 256 => 80, 80, 3 * 25 (4 + 1 + 20) & 85 (4 + 1 + 80)
self.yolo_head_P3 = nn.Conv2d(transition_channels *8,len(anchors_mask[2])*(5+ num_classes),1)# 40, 40, 512 => 40, 40, 3 * 25 & 85
self.yolo_head_P4 = nn.Conv2d(transition_channels *16,len(anchors_mask[1])*(5+ num_classes),1)# 20, 20, 512 => 20, 20, 3 * 25 & 85
self.yolo_head_P5 = nn.Conv2d(transition_channels *32,len(anchors_mask[0])*(5+ num_classes),1)
self.reviseleakyrulu_list =[]deffuse(self):print('Fusing layers... ')for m in self.modules():ifisinstance(m, RepConv):
m.fuse_repvgg_block()eliftype(m)is Conv andhasattr(m,'bn'):
m.conv = fuse_conv_and_bn(m.conv, m.bn)delattr(m,'bn')
m.forward = m.fuseforward
return self
defforward(self, x):# backbone
feat1, feat2, feat3 = self.backbone.forward(x)#------------------------加强特征提取网络------------------------# # 20, 20, 1024 => 20, 20, 512
P5 = self.sppcspc(feat3)# 20, 20, 512 => 20, 20, 256
P5_conv = self.conv_for_P5(P5)# 20, 20, 256 => 40, 40, 256
P5_upsample = self.upsample(P5_conv)# 40, 40, 256 cat 40, 40, 256 => 40, 40, 512
P4 = torch.cat([self.conv_for_feat2(feat2), P5_upsample],1)# 40, 40, 512 => 40, 40, 256
P4 = self.conv3_for_upsample1(P4)# 40, 40, 256 => 40, 40, 128
P4_conv = self.conv_for_P4(P4)# 40, 40, 128 => 80, 80, 128
P4_upsample = self.upsample(P4_conv)# 80, 80, 128 cat 80, 80, 128 => 80, 80, 256
P3 = torch.cat([self.conv_for_feat1(feat1), P4_upsample],1)# 80, 80, 256 => 80, 80, 128
P3 = self.conv3_for_upsample2(P3)# 80, 80, 128 => 40, 40, 256
P3_downsample = self.down_sample1(P3)# 40, 40, 256 cat 40, 40, 256 => 40, 40, 512
P4 = torch.cat([P3_downsample, P4],1)# 40, 40, 512 => 40, 40, 256
P4 = self.conv3_for_downsample1(P4)# 40, 40, 256 => 20, 20, 512
P4_downsample = self.down_sample2(P4)# 20, 20, 512 cat 20, 20, 512 => 20, 20, 1024
P5 = torch.cat([P4_downsample, P5],1)# 20, 20, 1024 => 20, 20, 512
P5 = self.conv3_for_downsample2(P5)#------------------------加强特征提取网络------------------------# # P3 80, 80, 128 # P4 40, 40, 256# P5 20, 20, 512
P3 = self.rep_conv_1(P3)
P4 = self.rep_conv_2(P4)
P5 = self.rep_conv_3(P5)#---------------------------------------------------## 第三个特征层# y3=(batch_size, 75, 80, 80)#---------------------------------------------------#
out2 = self.yolo_head_P3(P3)#---------------------------------------------------## 第二个特征层# y2=(batch_size, 75, 40, 40)#---------------------------------------------------#
out1 = self.yolo_head_P4(P4)#---------------------------------------------------## 第一个特征层# y1=(batch_size, 75, 20, 20)#---------------------------------------------------#
out0 = self.yolo_head_P5(P5)return[out0, out1, out2]if __name__ =="__main__":
anchors_mask=[[6,7,8],[3,4,5],[0,1,2]]
net = YoloBody(anchors_mask,20,'l')print(net)
x = torch.randn(2,3,640,640)
out0, out1, out2 = net(x)for i in out0:print(i.shape)
backbone代码:
import torch
import torch.nn as nn
defautopad(k, p=None):if p isNone:
p = k //2ifisinstance(k,int)else[x //2for x in k]return p
classSiLU(nn.Module):@staticmethoddefforward(x):return x * torch.sigmoid(x)classConv(nn.Module):def__init__(self, c1, c2, k=1, s=1, p=None, g=1, act=SiLU()):# ch_in, ch_out, kernel, stride, padding, groupssuper(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2, eps=0.001, momentum=0.03)
self.act = nn.LeakyReLU(0.1, inplace=True)if act isTrueelse(act ifisinstance(act, nn.Module)else nn.Identity())defforward(self, x):return self.act(self.bn(self.conv(x)))deffuseforward(self, x):return self.act(self.conv(x))classMulti_Concat_Block(nn.Module):# e = {'l': 2, 'x': 1}[phi]# n = {'l': 4, 'x': 6}[phi]# conv = {'l': RepConv, 'x': Conv}[phi]# ids = {'l': [-1, -2, -3, -4, -5, -6], 'x': [-1, -3, -5, -7, -8]}[phi]def__init__(self, c1, c2, c3, n=4, e=1, ids=[0]):super(Multi_Concat_Block, self).__init__()
c_ =int(c2 * e)
self.ids = ids
self.cv1 = Conv(c1, c_,1,1)
self.cv2 = Conv(c1, c_,1,1)
self.cv3 = nn.ModuleList([Conv(c_ if i ==0else c2, c2,3,1)for i inrange(n)])
self.cv4 = Conv(c_ *2+ c2 *(len(ids)-2), c3,1,1)defforward(self, x):
x_1 = self.cv1(x)
x_2 = self.cv2(x)
x_all =[x_1, x_2]# [-1, -3, -5, -6] => [5, 3, 1, 0]for i inrange(len(self.cv3)):
x_2 = self.cv3[i](x_2)
x_all.append(x_2)
out = self.cv4(torch.cat([x_all[id]foridin self.ids],1))return out
classMP(nn.Module):def__init__(self, k=2):super(MP, self).__init__()
self.m = nn.MaxPool2d(kernel_size=k, stride=k)defforward(self, x):return self.m(x)classTransition_Block(nn.Module):def__init__(self, c1, c2):super(Transition_Block, self).__init__()
self.cv1 = Conv(c1, c2,1,1)
self.cv2 = Conv(c1, c2,1,1)
self.cv3 = Conv(c2, c2,3,2)
self.mp = MP()defforward(self, x):# 160, 160, 256 => 80, 80, 256 => 80, 80, 128
x_1 = self.mp(x)
x_1 = self.cv1(x_1)# 160, 160, 256 => 160, 160, 128 => 80, 80, 128
x_2 = self.cv2(x)
x_2 = self.cv3(x_2)# 80, 80, 128 cat 80, 80, 128 => 80, 80, 256return torch.cat([x_2, x_1],1)classBackbone(nn.Module):def__init__(self, transition_channels, block_channels, n, phi, pretrained=False):super().__init__()#-----------------------------------------------## 输入图片是640, 640, 3#-----------------------------------------------#
ids ={'l':[-1,-3,-5,-6],'x':[-1,-3,-5,-7,-8],}[phi]# 640, 640, 3 => 640, 640, 32 => 320, 320, 64
self.stem = nn.Sequential(
Conv(3, transition_channels,3,1),
Conv(transition_channels, transition_channels *2,3,2),
Conv(transition_channels *2, transition_channels *2,3,1),)# 320, 320, 64 => 160, 160, 128 => 160, 160, 256
self.dark2 = nn.Sequential(
Conv(transition_channels *2, transition_channels *4,3,2),
Multi_Concat_Block(transition_channels *4, block_channels *2, transition_channels *8, n=n, ids=ids),)# 160, 160, 256 => 80, 80, 256 => 80, 80, 512
self.dark3 = nn.Sequential(
Transition_Block(transition_channels *8, transition_channels *4),
Multi_Concat_Block(transition_channels *8, block_channels *4, transition_channels *16, n=n, ids=ids),)# 80, 80, 512 => 40, 40, 512 => 40, 40, 1024
self.dark4 = nn.Sequential(
Transition_Block(transition_channels *16, transition_channels *8),
Multi_Concat_Block(transition_channels *16, block_channels *8, transition_channels *32, n=n, ids=ids),)# 40, 40, 1024 => 20, 20, 1024 => 20, 20, 1024
self.dark5 = nn.Sequential(
Transition_Block(transition_channels *32, transition_channels *16),
Multi_Concat_Block(transition_channels *32, block_channels *8, transition_channels *32, n=n, ids=ids),)defforward(self, x):
x = self.stem(x)
x = self.dark2(x)#-----------------------------------------------## dark3的输出为80, 80, 512,是一个有效特征层#-----------------------------------------------#
x = self.dark3(x)
feat1 = x
#-----------------------------------------------## dark4的输出为40, 40, 1024,是一个有效特征层#-----------------------------------------------#
x = self.dark4(x)
feat2 = x
#-----------------------------------------------## dark5的输出为20, 20, 1024,是一个有效特征层#-----------------------------------------------#
x = self.dark5(x)
feat3 = x
return feat1, feat2, feat3
版权归原作者 Deen.. 所有, 如有侵权,请联系我们删除。