
一:Numpy简介
NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
NumPy 是一个运行速度非常快的数学库,主要用于数组计算,包含:
一个强大的N维数组对象 ndarray(矩阵)
广播功能函数
整合 C/C++/Fortran 代码的工具
线性代数、傅里叶变换、随机数生成等功能
二:Numpy应用
NumPy 通常与 SciPy(Scientific Python)和 Matplotlib(绘图库)一起使用, 这种组合广泛用于替代 MatLab,是一个强大的科学计算环境,有助于我们通过 Python 学习数据科学或者机器学习。
SciPy 是一个开源的 Python 算法库和数学工具包。
SciPy 包含的模块有最优化、线性代数、积分、插值、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科学与工程中常用的计算。
Matplotlib 是 Python 编程语言及其数值数学扩展包 NumPy 的可视化操作界面。它为利用通用的图形用户界面工具包,如 Tkinter, wxPython, Qt 或 GTK+ 向应用程序嵌入式绘图提供了应用程序接口(API)。
三:Numpy安装
原生的Python安装:
在cmd里面输入pip install numpy在官网中下载相关版本安装
https://pypi.python.org/pypi/numpy
安装后,导入这个库
import numpy as np
并且查看版本:
np.version
Python3.7.4
Numpy 1.18.5
Pandas 1.0.5
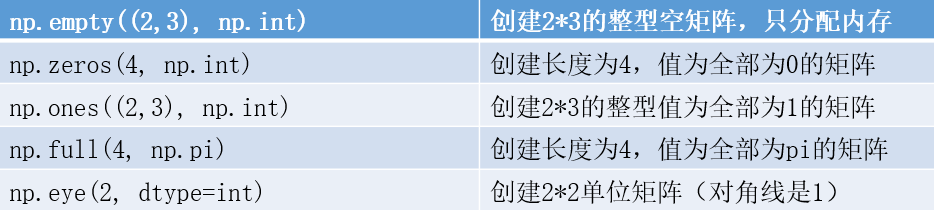
四:ndarray对象
ndarray的创建
ndarray的属性
ndarray的索引与切片
多维数组
五:ndarray的创建
Numpy中的核心对象是ndarray
ndarray可以看成数组,类似于R语言的向量或者矩阵
Numpy里面所有的函数都是围绕ndarry展开的。
# 通过python list创建 array >>> a = np.array([1,2,3,4]) >>> b = np.array([5,6,7,8]) >>> c = np.array([[1,2,3,4],[5,6,7,8]]) >>> print(b) # [5 6 7 8] >>> print(c) # [[1 2 3 4] [5 6 7 8]]ndarray对维数没有限制
[]从内到外分别是第0轴,第1轴,第2轴。
c第0轴长度为4,第1轴长度为2.
Numpy提供了专门用于生成ndarray的函数,提高创建ndarray的速度
# 通过arange方法产生数组 >>> a = np.arange(0,1,0.1) # start=0 end=1 step=0.1(间隔) [0.,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9] # 创建等差数列 >>> b = np.linspace(2.0, 3.0, num=5) array([ 2. , 2.25, 2.5 , 2.75, 3. ]) # 二维数组 >>> c = np.array([[1,2,3,4],[5,6,7,8]]) [[1 2 3 4] [5 6 7 8]] # 二维全0矩阵 >>> e = np.zeros([2,3]) [[0. 0. 0.] [0. 0. 0.]]
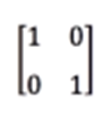
还可以自定义函数产生ndarray。
>>> def func(i): return i % 4 + 1 >>> np.fromfunction(func, (10,)) array([1., 2., 3., 4., 1., 2., 3., 4., 1., 2.])fromfunction第一个参数接收计算函数,第二个参数接收数组的形状。
六:ndarray的属性
- ndarray的元素具有相同的元素类型dtype。常用的有int(整型),float(浮点型),complex(复数型),
>>> a = np.array([1,2,3,4],dtype=float)
[1. 2. 3. 4.]
>>> print(a.dtype)
dtype('float64')
- ndarray的shape属性用来获得它的形状,也可以自己指定。
>>> c = np.array([[1,2,3,4],[5,6,7,8],[7,8,9,10]])
>>> print(c.shape)
(3, 4)
>>> a = np.array([1,2,3,4])
>>> d = a.reshape((2,2)) # 维度变换
>>> print(d)
[[1 2]
[3 4]]
- size元素个数
>>> a = np.array([[1,2,3,4],[5,6,7,8]])
>>> print(a.size)
8
- ndim 数组维度
>>> a = np.array([[1,2,3,4],[5,6,7,8]])
>>> print(a.nidm)
2
- itemsize属性每个元素的大小,以字节为单位 。
>>> c = np.array([[1,2,3,4],[5,6,7,8],[7,8,9,10]])
>>> print(c.itemsize)
4
七:切片索引
Numpy数组的切片索引,不会复制内部数组数据,仅创建原始数据的新视图,以引用方式访问数据。
切片索引的要点:
切片索引适用于有规律的查找指定位置的元素(元素位置位于等差序列);
当切片的数量少于数组维度时,缺失的维度索引被认为是一个完整切片,
省略与使用“:”或“…”等价;
八:一维数组的切片索引
- ndarray对象的内容可以通过索引或切片来访问和修改,和list是一样的。
>>> a = np.arange(10)
>>> a
array([0,1,2,3,4,5,6,7,8,9])
>>> a[::-1] # 逆序 [9,8,7,6,5,4,3,2,1,0]
>>> a[5] # 5
>>> a[3:5] # [3,4]
>>> a[:5] # 从索引0开始取5个元素 [0,1,2,3,4]
>>> a[:-1] # 从最后一个索引开始向前取所有的元素[0,1,2,3,4,5,6,7,8]
>>> a[1:-1:2] # 从索引1开始到最后一个结束,每2个取一个[1,3,5,7]
>>> a[5:1:-2] # [5,3]
>>> a[...] # 索引全部元素,与a[:]等价
- 可以通过切片的对ndarray中的元素进行更改。
>>> a[2:4] = 100,101
>>> a
[0 1 100 101 4 5 6 7 8 9]
- ndarray通过切片产生一个新的数组b,b和a共享同一块数据存储空间。
>>> a = np.array([0,1,100,101,4,5,6,7,8,9])
>>> b = a[3:7]
[101 4 5 6]
>>> b[2] = -10
[101 4 -10 6]
>>> a
[0 1 100 101 4 -10 6 7 8 9]
- 如果想改变这种情况,我们可以用整数数组索引对数组元素切片。
>>> b = a[[3,3,-3,8]]
array([100,101,7,8])
>>> b[2] = 100
array([100,101,100,8])
>>> a
[0 1 100 101 4 -10 6 7 8 9]
九:数组的轴(二维数组)
二维数组有2个轴,轴索引分别是0和1。
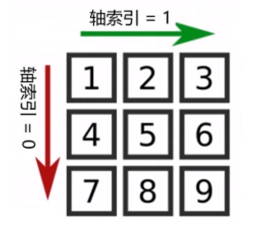
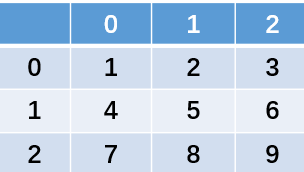
>>> a = np.array([[1,2,3], [4,5,6]])
>>> print(a[1][2], a[1,2])
6 6
>>> b = a.T # 数组转置
[[1 4]
[2 5]
[3 6]]
十:二维数组切片索引
- 多维数组同样适用上述索引提取方法。
>>> a = np.array([[1,2,3],[3,4,5],[4,5,6]])
[[1 2 3]
[3 4 5]
[4 5 6]]
>>> print(a[1:])
[[3 4 5]
[4 5 6]]
- 切片还可以包括省略号 …,来使选择元组的长度与数组的维度相同。 如果在行位置使用省略号,它将返回包含行中元素的 ndarray.
>>> a = np.array([[1,2,3],[3,4,5],[4,5,6]])
>>> print (a[...,1]) # 第2列元素
>>> print (a[1,...]) # 第2行元素
>>> print (a[...,1:]) # 第2列及剩下的所有元素
十一:高级索引
NumPy 比一般的 Python 序列提供更多的索引方式。除了用整数和切片的索引外,数组可以由整数数组索引、布尔索引及花式索引创立原数组的副本。
- 整数数组索引
>>> x = np.array([[1, 2], [3, 4], [5, 6]])
>>> y = x[[0,1,2], [0,1,0]]
>>> print (y)
[1 4 5] # 获取数组中(0,0),(1,1)和(2,0)位置处的元素
>>> a = np.array([[1,2,3], [4,5,6],[7,8,9]])
>>> b = a[1:3, 1:3]
c = a[1:3,[1,2]]
>>> d = a[...,1:]
>>> print(b) # [[5 6], [8,9]]
>>> print(c) # [[5 6], [8,9]]
>>> print(d) # [[1 2], [5 6], [8,9]]
- 布尔索引
布尔索引通过布尔运算(如:比较运算符)来获取符合指定条件的元素的数组
>>> x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
# 现在我们会打印出大于 5 的元素
>>> b = x[x > 5]
>>> print('大于5的元素是\n{}'.format(b))
大于 5 的元素是:
[ 6 7 8 9 10 11]
# 使用了 ~(取补运算符)来过滤 NaN。
>>> a = np.array([np.nan, 1,2,np.nan,3,4,5])
>>> print (a[~np.isnan(a)])
[ 1. 2. 3. 4. 5.]
- 花式索引
花式索引指的是利用整数数组进行索引。
花式索引根据索引数组的值作为目标数组的某个轴的下标来取值。对于使用一维整型数组作为索引,如果目标是一维数组,那么索引的结果就是对应位置的元素;如果目标是二维数组,那么就是对应下标的行。
花式索引跟切片不一样,它总是将数据复制到新数组中。
>>> x=np.arange(32).reshape((8,4)) # 传入倒序索引
>>> print (x[[4,2,1,7]]) >>> print (x[[-4,-2,-1,-7]])
[[16 17 18 19] [[16 17 18 19]
[ 8 9 10 11] [24 25 26 27]
[ 4 5 6 7] [28 29 30 31]
[28 29 30 31]] [ 4 5 6 7]]
>>> x=np.arange(32).reshape((8,4))
>>> print(x[np.ix_([1,5,7,2],[0,3,1,2])]) # 输出4*4矩阵
# 其元素分别是
# x[1,0] x[1,3] x[1,1] x[1,2]
# x[5,0] x[5,3] x[5,1] x[5,2]
# x[7,0] x[7,3] x[7,1] x[7,2]
# x[2,0] x[2,3] x[2,1] x[2,2]
# 相当于:
# y=np.array([[x[1,0], x[1,3], x[1,1], x[1,2]],\
[x[5,0], x[5,3], x[5,1],x[5,2]],\
[x[7,0] ,x[7,3], x[7,1], x[7,2]],\
[x[2,0], x[2,3], x[2,1], x[2,2]]])
[[ 4 7 5 6]
[20 23 21 22]
[28 31 29 30]
[ 8 11 9 10]]
十二:NumPy 广播
广播(Broadcast)是 numpy 对不同形状(shape)的数组进行数值计算的方式, 对数组的算术运算通常在相应的元素上进行。
如果两个数组 a 和 b 形状相同,即满足 a.shape == b.shape,那么 a*b 的结果就是 a 与 b 数组对应位相乘。这要求维数相同,且各维度的长度相同。
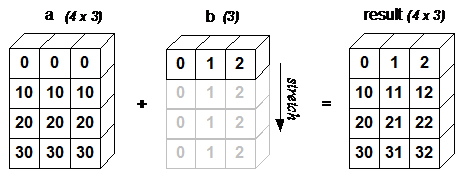
# 当运算中的 2 个数组的形状不同时,numpy 将自动触发广播机制。
>>> a = np.array([1,2,3])
>>> b = np.array([[0, 0, 0], [10,10,10], [20,20,20], [30,30,30]])
>>> c = a + b
>>> print (c)
[[ 1 2 3]
[11 12 13]
[21 22 23]
[31 32 33]]
十三:ufunc函数
算术运算
比较运算与布尔运算
十四:ufunc简介
ufunc是universal function的简称,它是一种能对数组每个元素进行运算的函数。Numpy的许多ufunc函数都是用C实现的,因此它们的运算速度非常快。
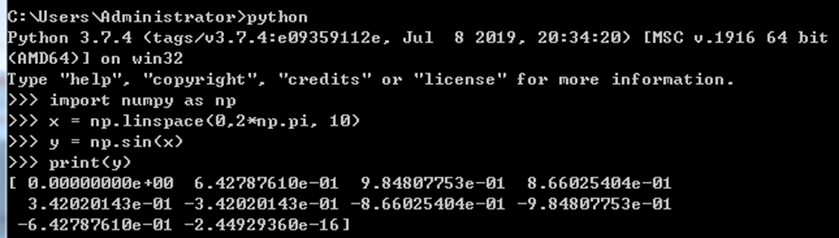
值得注意的是,对于等长度的ndarray,np.sin()比math.sin()要快,但是对于单个数值,math.sin()比较快
十五:算术运算
Numpy提供了的许多ufunc函数,它们和相应的的运算符运算结果相同。
>>> a = np.arange(0,4) # [0 1 2 3]
>>> b = np.arange(1,5) # [1 2 3 4]
>>> np.add(a,b)
[1 3 5 7]
>>> a+b
[1 3 5 7]
>>> np.substract(a,b) # 减法
>>> np.multiply(a,b) # 乘法
>>> np.divide(a,b) # 如果两个数字都为正数,则为整数除法
>>> np.power(a,b) # 乘方
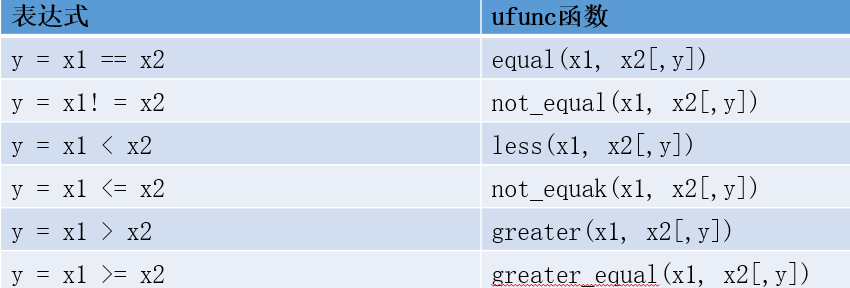
十六:比较运算
使用==,>对两个数组进行比较,会返回一个布尔数组,每一个元素都是对应元素的比较结果。
>>> a = np.array([1,2,3]) < np.array([3,2,1])
>>> print(a)
[True False False]
布尔运算在Numpy中也有对应的ufunc函数。
十七:Numpy的函数库
随机数
求和,平均值,方差
大小和排序
统计函数
操作多维数组
十八:随机数
Numpy提供了大量对于数组运算的函数。可以简化逻辑,提高运算速度。
Numpy产生随机数的模块在random里面,其中有大量的分布。
>>> from numpy import random as nr
>>> np.set_printoptions(precision=2) # 显示小数点后两位
>>> r1 = nr.rand(4,3) >>> r2 = nr.poisson(2.0,(4,3))
[[0.41 0.45 0.56] [[1 2 3]
[0.77 0.49 0.85] [5 3 0]
[0.18 0.88 0.62] [5 2 0]
[0.6 0. 0.89]] [3 1 1]]
十九:求和,平均值,方差
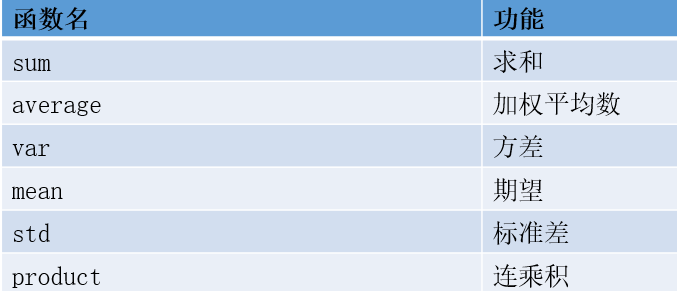
>>> np.random.seed(42)
>>> a = np.random.randint(0,10,size=(4,5))
>>> np.sum(a)
96
a np.sum(a,axis=1)行 np.sum(a,axis=0)列
____________ ___________________ ___________________
[[6,3,7,4,6], [26,28,24,18] [22,13,27,18,16]
[9,2,6,7,4],
[3,7,7,2,5],
[4,1,7,5,1]]
keepdims可以保持原来数组的维数。
np.sum(a,1,keepdims=True) np.sum(a,0,keepdims=True)
_________________________ ___________________
[[26], [22,13,27,18,16]
[28],
[24],
[18]]
二十:大小与排序
Numpy在排序等方面常用的函数如下:
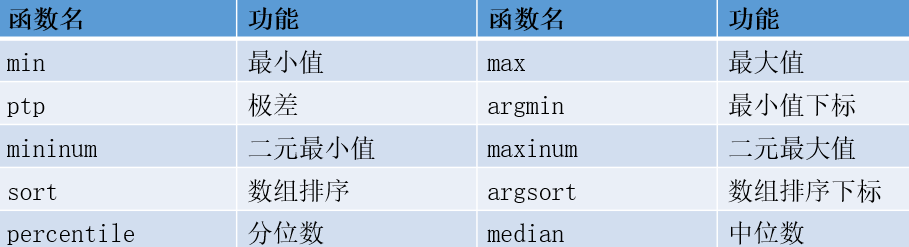
min,max都有axis,out,keepdims等参数,我们来看其他函数。
>>> a = np.array([1,3,5,7])
>>> b = np.array([2,4,6])
>>> np.maxinum(a[None,:],b[:,None]) # maxinum返回两组矩阵广播计算后的结果
[[2 3 5 7],
[4 4 5 7],
[6 6 6 7]]
sort()对数组进行排序会改变数组排序的内容,返回一个新的数组。axis的默认值是-1,即按最终轴进行排序。axis=0对每列上的值进行排序。
>>> a = np.array([
[4, 7, 4, 5],
[2, 7, 3, 5],
[6, 6, 6, 7]
])
>>> b = np.sort(a)
>>> print(b)
[[4 4 5 7]
[2 3 5 7]
[6 6 6 7]]
>>> a = np.array([
[4, 7, 4, 5],
[2, 7, 3, 5],
[6, 6, 6, 7]
])
>>> b = np.sort(a, axis=0)
>>> print(b)
[[2 6 3 5]
[4 7 4 5]
[6 7 6 7]]
二十一:Pandas简介
Pandas 是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。Pandas 的目标是成为 Python 数据分析实践与实战的必备高级工具,其长远目标是成为最强大、最灵活、可以支持任何语言的开源数据分析工具。经过多年不懈的努力,Pandas 离这个目标已经越来越近了。
Pandas 适用于处理以下类型的数据:
与 SQL 或 Excel 表类似的,含异构列的表格数据; 有序和无序(非固定频率)的时间序列数据; 带行列标签的矩阵数据,包括同构或异构型数据; 任意其它形式的观测、统计数据集, 数据转入 Pandas 数据结构时不必事先标记
安装:pip install pandas
二十二:Pandas数据结构

Pandas 里,轴的概念主要是为了给数据赋予更直观的语义,即用“更恰当”的方式表示数据集的方向。这样做可以让用户编写数据转换函数时,少费点脑子。
处理 DataFrame 等表格数据时,index(行)或 columns(列)比 axis 0 和 axis 1 更直观。用这种方式迭代 DataFrame 的列,代码更易读易懂:
for col in df.columns:
series = df[col]
Pandas 基础数据结构,包括各类对象的数据类型、索引、轴标记、对齐等基础操作。首先,导入 NumPy 和 Pandas:
import numpy as np
import pandas as pd
二十三:Pandas数据结构简介
Pandas 基础数据结构,包括各类对象的数据类型、索引、轴标记、对齐等基础操作。首先,导入 NumPy 和 Pandas:
import numpy as np
import pandas as pd
Series 是带标签的一维数组,可存储整数、浮点数、字符串、Python 对象等类型的数据。轴标签统称为索引。调用 pd.Series 函数即可创建 Series:
s = pd.Series(data, index=index)
上述代码中,data 支持以下数据类型:
Python 字典
多维数组
标量值(如,5)
二十四:Series
index 是轴标签列表。不同数据可分为以下几种情况:
data 是多维数组时,index 长度必须与 data 长度一致。没有指定 index 参数时,创建数值型索引,即 [0, ..., len(data) - 1]。
>>> s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
>>> print(s)
a 0.469112
b -0.282863
c -1.509059
d -1.135632
e 1.212112
dtype: float64
>>> print(s.index)
>>> Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
二十五:字典生成Series
- Series 可以用字典实例化:
>>> d = {'b': 1, 'a': 0, 'c': 2}
>>> print( pd.Series(d))
b 1
a 0
c 2
dtype: int64
- 如果设置了 index 参数,则按索引标签提取 data 里对应的值。
>>> d = {'a': 0., 'b': 1., 'c': 2.}
>>> print( pd.Series(d))
a 0.0
b 1.0
c 2.0
dtype: float64
- 如果设置了 index 参数,则按索引标签提取 data 里对应的值。
>>> d = {'a': 0., 'b': 1., 'c': 2.}
>>> print( pd.Series(d))
a 0.0
b 1.0
c 2.0
dtype: float64
>>> print(pd.Series(d, index=['b', 'c', 'd', 'a']))
b 1.0
c 2.0
d NaN
a 0.0
dtype: float64
二十六:标量值生成Series
data 是标量值时,必须提供索引。Series 按索引长度重复该标量值。
>>> d = pd.Series(5., index=['a', 'b', 'c', 'd', 'e'])
>>> print(d)
a 5.0
b 5.0
c 5.0
d 5.0
e 5.0
dtype: float64
二十七:Series类似多维数组
- Series 操作与 ndarray 类似,支持大多数 NumPy 函数,还支持索引切片。
>>> s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
>>> print(s[0])
0.4691122999071863
>>> print(s[:3])
b 5.0
c 5.0
d 5.0
e 5.0
dtype: float64
>>> print(s[s > s.median()])
a 0.469112
e 1.212112
dtype: float64
>>> s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
>>> print(s[[4, 3, 1]])
e 1.212112
d -1.135632
b -0.282863
dtype: float64
>>> print(np.exp(s))
a 1.598575
b 0.753623
c 0.221118
d 0.321219
e 3.360575
dtype: float64
>>> print(s.dtype) # Series 的数据类型一般是 NumPy 数据类型
dtype('float64')
- Series.array 用于提取 Series 数组。
>>> s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
>>> print(s.array)
<PandasArray>
[ 0.4691122999071863, -0.2828633443286633, -1.5090585031735124,
-1.1356323710171934, 1.2121120250208506]
Length: 5, dtype: float64
- 执行不用索引的操作时,如禁用自动对齐,访问数组非常有用。Series.array 一般是扩展数组。简单说,扩展数组是把 N 个 numpy.ndarray 包在一起的打包器。Pandas 知道怎么把扩展数组存储到 Series 或 DataFrame 的列里。
>>> s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
>>> print(s.to_numpy())
# Series 只是类似于多维数组,提取真正的多维数组,要用 Series.to_numpy()。
>>> array([ 0.4691, -0.2829, -1.5091, -1.1356, 1.2121])
二十八:Series类似字典
- Series 类似固定大小的字典,可以用索引标签提取值或设置值:
>>> s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
>>> print(s['a'])
0.4691122999071863
>>> s['e'] = 12.
>>> print(s)
a 0.469112
b -0.282863
c -1.509059
d -1.135632
e 12.000000
dtype: float64
>>> print('e' in s)
True
>>> print('f' in s)
False
- 引用 Series 里没有的标签会触发异常:
>>> s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
>>> print(s['f'])
KeyError: 'f'
- 引用 Series 里没有的标签会触发异常:
>>> s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
>>> print(s.get('f'))
>>> s.get('f', np.nan)
nan
二十九:矢量操作与对齐 Series 标签
Series 和 NumPy 数组一样,都不用循环每个值,而且 Series 支持大多数 NumPy 多维数组的方法。
>>> s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
>>> print(s + s)
a 0.938225
b -0.565727
c -3.018117
d -2.271265
e 24.000000
dtype: float64
>>> print(s * 2)
a 0.938225
b -0.565727
c -3.018117
d -2.271265
e 24.000000
dtype: float64
三十:名称属性
Series 支持 name 属性:
>>> s = pd.Series(np.random.randn(5), name='something')
>>> print(s)
0 -0.494929
1 1.071804
2 0.721555
3 -0.706771
4 -1.039575
Name: something, dtype: float64
>>> print(s.name)
'something'
>>> s2 = s.rename("different")
>>> print(s2.name)
'different'
三十一:DataFrame
DataFrame 是由多种类型的列构成的二维标签数据结构,类似于 Excel 、SQL 表,或 Series 对象构成的字典。DataFrame 是最常用的 Pandas 对象,与 Series 一样,DataFrame 支持多种类型的输入数据:
一维 ndarray、列表、字典、Series 字典
二维 numpy.ndarray
结构多维数组或记录多维数组
Series
DataFrame
除了数据,还可以有选择地传递 index(行标签)和 columns(列标签)参数。传递了索引或列,就可以确保生成的 DataFrame 里包含索引或列。Series 字典加上指定索引时,会丢弃与传递的索引不匹配的所有数据。
三十二:用 Series 字典或字典生成 DataFrame
生成的索引是每个 Series 索引的并集。先把嵌套字典转换为 Series。如果没有指定列,DataFrame 的列就是字典键的有序列表。
>>> d = {'one': pd.Series([1., 2., 3.], index=['a', 'b', 'c']),
'two': pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
>>> df = pd.DataFrame(d)
>>> print(df)
one two
a 1.0 1.0
b 2.0 2.0
c 3.0 3.0
d NaN 4.0
>>> pd.DataFrame(d, index=['d', 'b', 'a'])
one two
d NaN 4.0
b 2.0 2.0
a 1.0 1.0
>>> print(s2.name)
'different'
>>> print(pd.DataFrame(d, index=['d', 'b', 'a'], columns=['two', 'three']))
two three
d 4.0 NaN
b 2.0 NaN
a 1.0 NaN
>>> print(df.index)
Index(['a', 'b', 'c', 'd'], dtype='object')
>>> print(df.columns)
Index(['one', 'two'], dtype='object')
三十三:用多维数组字典、列表字典生成 DataFrame
多维数组的长度必须相同。如果传递了索引参数,index 的长度必须与数组一致。如果没有传递索引参数,生成的结果是 range(n),n 为数组长度。
>>> d = {'one': [1., 2., 3., 4.],
'two': [4., 3., 2., 1.]}
>>> print(pd.DataFrame(d))
one two
0 1.0 4.0
1 2.0 3.0
2 3.0 2.0
3 4.0 1.0
>>> pd.DataFrame(d, index=['a', 'b', 'c', 'd'])
one two
a 1.0 4.0
b 2.0 3.0
c 3.0 2.0
d 4.0 1.0
三十四:用结构多维数组或记录多维数组生成 DataFrame
与数组字典的操作方式相同。
>>> data = np.zeros((2, ), dtype=[('A', 'i4'), ('B', 'f4'), ('C', 'a10')])
>>> data[:] = [(1, 2., 'Hello'), (2, 3., "World")]
>>> res = pd.DataFrame(data)
>>> print(res)
A B C
0 1 2.0 b'Hello'
1 2 3.0 b'World'
>>> res1 = pd.DataFrame(data, index=['first', 'second'])
A B C
first 1 2.0 b'Hello'
second 2 3.0 b'World'
>>> pd.DataFrame(data, columns=['C', 'A', 'B'])
C A B
0 b'Hello' 1 2.0
1 b'World' 2 3.0
三十五:用列表字典生成 DataFrame
与数组字典的操作方式相同。
>>> data2 = [{'a': 1, 'b': 2}, {'a': 5, 'b': 10, 'c': 20}]
>>> res = pd.DataFrame(data2)
>>> print(res)
a b c
0 1 2 NaN
1 5 10 20.0
>>> res1 = pd.DataFrame(data2, index=['first', 'second'])
a b c
first 1 2 NaN
second 5 10 20.0
>>> res2 = pd.DataFrame(data2, columns=['a', 'b'])
a b
0 1 2
1 5 10
三十六:用元组字典生成 DataFrame
元组字典可以自动创建多层索引 DataFrame。
>>> res = pd.DataFrame({('a', 'b'): {('A', 'B'): 1, ('A', 'C'): 2},
('a', 'a'): {('A', 'C'): 3, ('A', 'B'): 4},
('a', 'c'): {('A', 'B'): 5, ('A', 'C'): 6},
('b', 'a'): {('A', 'C'): 7, ('A', 'B'): 8},
('b', 'b'): {('A', 'D'): 9, ('A', 'B'): 10}})
>>> print(res)
a b
b a c a b
A B 1.0 4.0 5.0 8.0 10.0
C 2.0 3.0 6.0 7.0 NaN
D NaN NaN NaN NaN 9.0
三十七:用Series字典对象生成 DataFrame
>>> df2 = pd.DataFrame({'A': 1.,
'B': pd.Timestamp('20130102'),
'C': pd.Series(1, index=list(range(4)), dtype='float32'),
'D': np.array([3] * 4, dtype='int32'),
'E': pd.Categorical(["test", "train", "test", "train"]),
'F': 'foo'})
A B C D E F
0 1.0 2013-01-02 1.0 3 test foo
1 1.0 2013-01-02 1.0 3 train foo
2 1.0 2013-01-02 1.0 3 test foo
3 1.0 2013-01-02 1.0 3 train foo
>>> print(df2.dtypes )
A float64
B datetime64[ns]
C float32
D int32
E category
F object
dtype: object
三十八:数据输入 / 输出
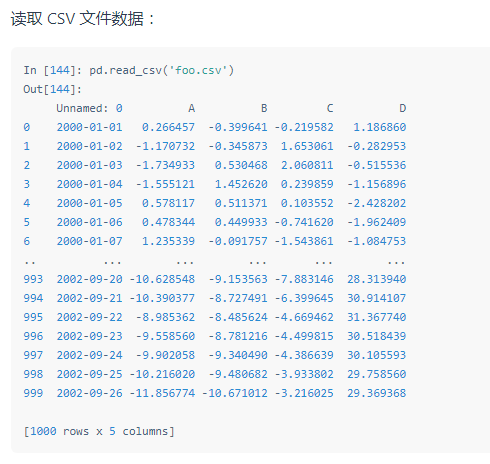
写入CVS:
df.to_csv('foo.csv')
三十九:查看数据
查看 DataFrame 头部和尾部数据:
>>> df.head()
A B C D
2013-01-01 0.469112 -0.282863 -1.509059 -1.135632
2013-01-02 1.212112 -0.173215 0.119209 -1.044236
2013-01-03 -0.861849 -2.104569 -0.494929 1.071804
2013-01-04 0.721555 -0.706771 -1.039575 0.271860
2013-01-05 -0.424972 0.567020 0.276232 -1.087401
>>> df.tail(3)
A B C D
2013-01-04 0.721555 -0.706771 -1.039575 0.271860
2013-01-05 -0.424972 0.567020 0.276232 -1.087401
2013-01-06 -0.673690 0.113648 -1.478427 0.524988
显示索引与列名:
>>> df.index
DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04',
'2013-01-05', '2013-01-06'],
dtype='datetime64[ns]', freq='D')
>>> df.columns
Index(['A', 'B', 'C', 'D'], dtype='object')
# DataFrame.to_numpy()
输出底层数据的 NumPy 对象
DataFrame 的列由多种数据类型组成时,该操作耗费系统资源较大,这也是 Pandas 和 NumPy 的本质区别:NumPy 数组只有一种数据类型,DataFrame 每列的数据类型各不相同。
DataFrame.to_numpy() 的输出不包含行索引和列标签。
describe() 可以快速查看数据的统计摘要:
>>> print(df.describe())
A B C D
count 6.000000 6.000000 6.000000 6.000000
mean 0.073711 -0.431125 -0.687758 -0.233103
std 0.843157 0.922818 0.779887 0.973118
min -0.861849 -2.104569 -1.509059 -1.135632
25% -0.611510 -0.600794 -1.368714 -1.076610
50% 0.022070 -0.228039 -0.767252 -0.386188
75% 0.658444 0.041933 -0.034326 0.461706
max 1.212112 0.567020 0.276232 1.071804
数据转置:
>>> print(df.T)
A B C D
2013-01-01 2013-01-02 2013-01-03 2013-01-04 2013-01-05 2013-01-06
A 0.469112 1.212112 -0.861849 0.721555 -0.424972 -0.673690
B -0.282863 -0.173215 -2.104569 -0.706771 0.567020 0.113648
C -1.509059 0.119209 -0.494929 -1.039575 0.276232 -1.478427
D -1.135632 -1.044236 1.071804 0.271860 -1.087401 0.524988
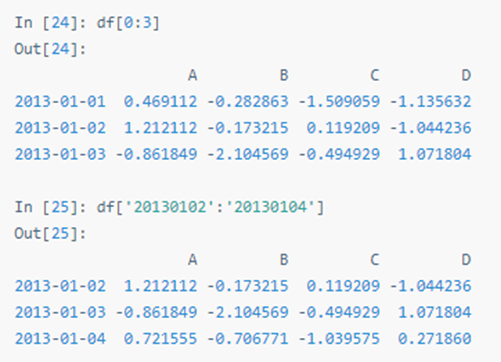
四十:获取数据
选择单列,产生 Series,与 df.A 等效:
>>> print(df['A'])
2013-01-01 0.469112
2013-01-02 1.212112
2013-01-03 -0.861849
2013-01-04 0.721555
2013-01-05 -0.424972
2013-01-06 -0.673690
Freq: D, Name: A, dtype: float64
用 [ ] 切片行:
四十一:按标签选择
用标签提取一行数据:
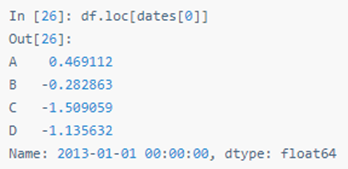
用标签选择多列数据:
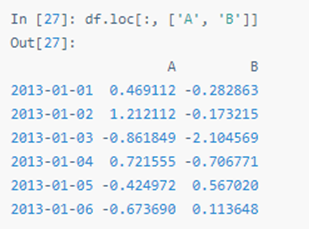
用标签切片,包含行与列结束点:
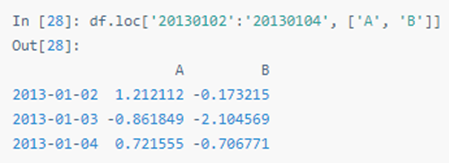
返回对象降维:
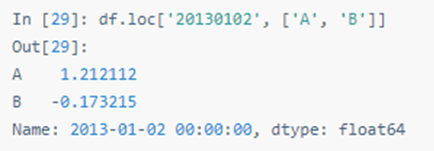
快速访问标量
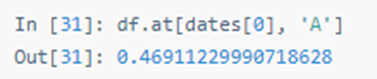
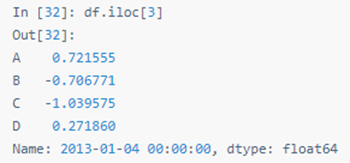
四十二:按位置选择
用整数位置选择:
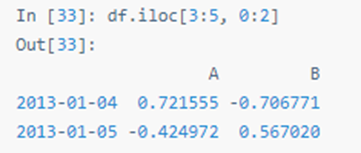
类似NumPy/Python,用整数切片:
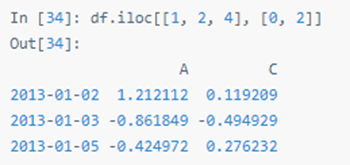
类似 NumPy / Python,用整数列表按位置切片:
显式整行切片:
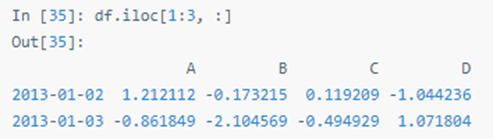
显式整列切片:

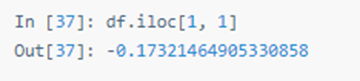
显式提取值:
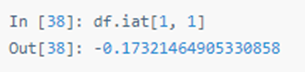
快速访问标量,与上述方法等效:
四十三:布尔索引
用单列的值选择数据:
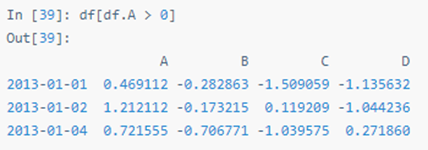
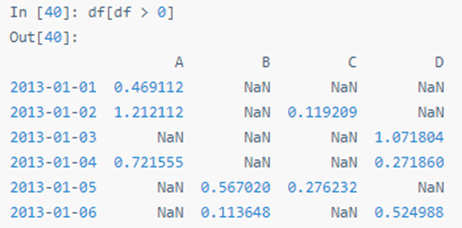
选择 DataFrame 里满足条件的值:
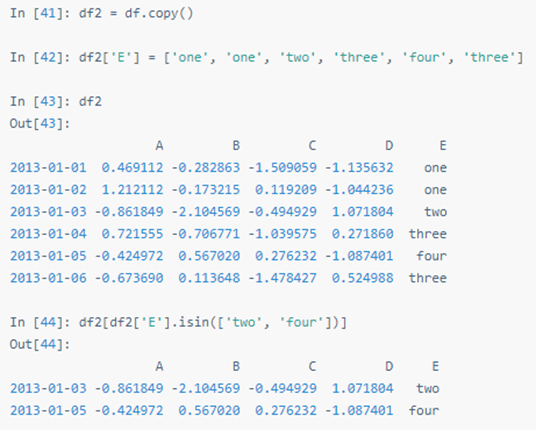
用isin()筛选:
四十四:赋值
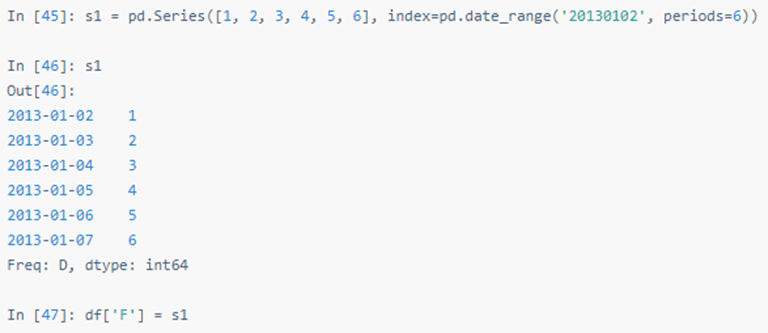
用索引自动对齐新增列的数据:
按NumPy数组赋值:
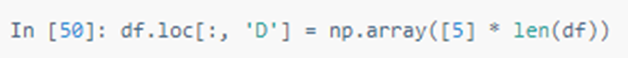
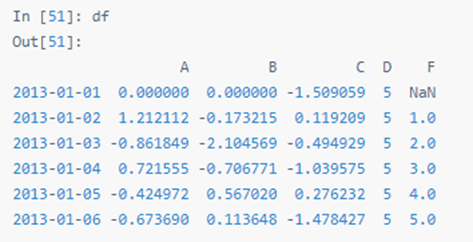
按标签赋值:

按位置赋值:

四十五:缺失值
Pandas 主要用 np.nan 表示缺失数据。 计算时,默认不包含空值。详见缺失数据。
重建索引(reindex)可以更改、添加、删除指定轴的索引,并返回数据副本,即不更改原数据。
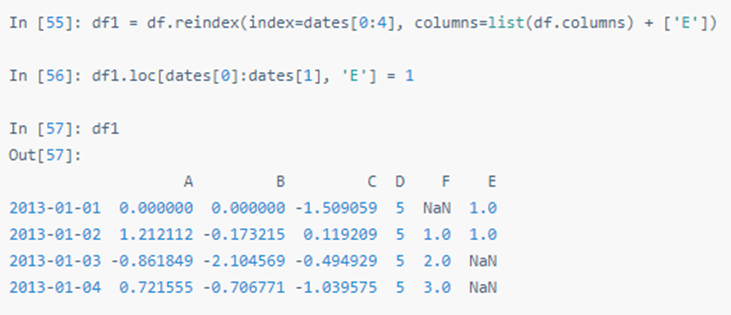
删除所有含缺失值的行:
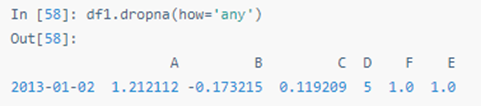
填充缺失值:
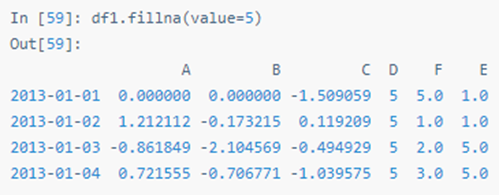
提取 nan 值的布尔掩码:
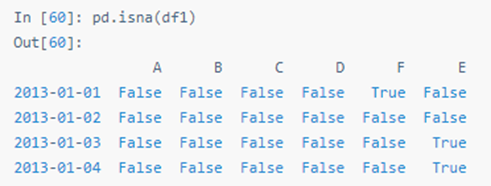
四十六:合并(Merge)
结合(Concat)
Pandas 提供了多种将 Series、DataFrame 对象组合在一起的功能,用索引与关联代数功能的多种设置逻辑可执行连接(join)与合并(merge)操作。

四十七:连接(join)
SQL 风格的合并

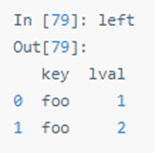
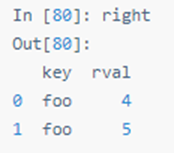
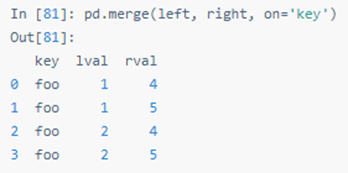
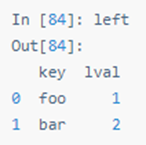
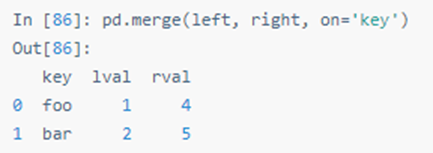
SQL 风格的合并


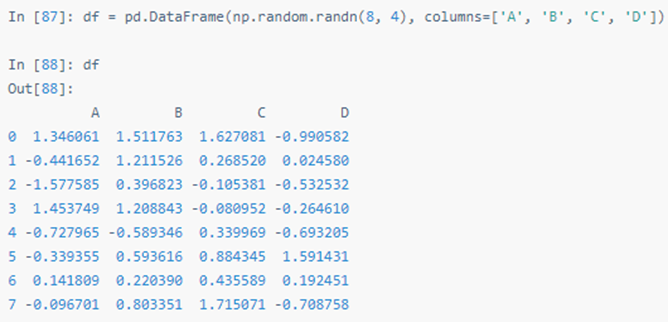
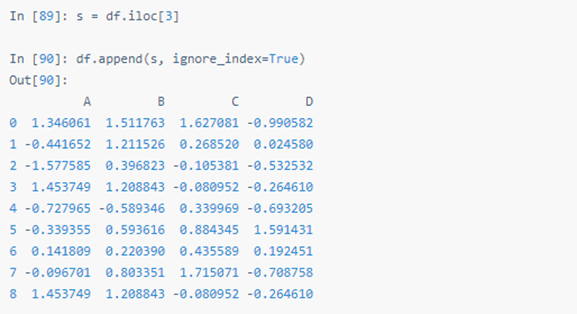
四十八:追加(Append)
为 DataFrame 追加行。
四十九:分组(Grouping)
“group by” 指的是涵盖下列一项或多项步骤的处理流程:
分割:按条件把数据分割成多组;
应用:为每组单独应用函数;
组合:将处理结果组合成一个数据结构。
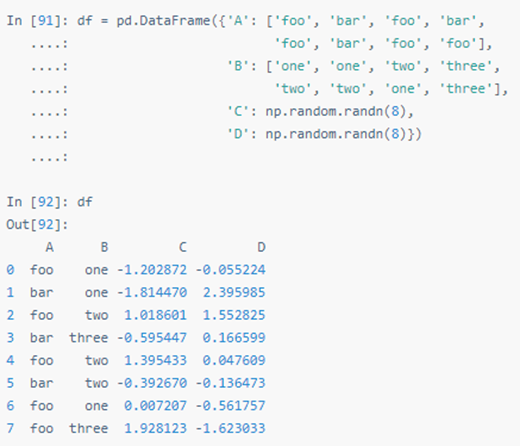
先分组,再用 sum()函数计算每组的汇总数据:
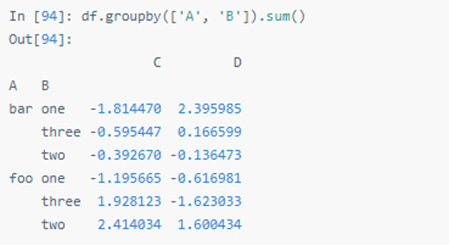
多列分组后,生成多层索引,也可以应用 sum 函数:
版权归原作者 顾城沐心 所有, 如有侵权,请联系我们删除。