
经常使用Stable Diffusion WebUI的同学可能都被显存的问题困扰过,其运行时需要巨大的显存空间,跑着跑着显存可能就爆了,不得不重新启动。不过现在这个问题解决了,因为Stable Diffusion WebUI Forge来了。
Forge的优势
相较于原版的SD WebUI(针对1024像素分辨率下的SDXL图片生成),可以获取以下性能提升:
- 对于8GB显存GPU,生成速度可以有大约30%至45%的提升,GPU内存峰值下降约700MB至1.3GB,最大扩散分辨率将提升约2到3倍,同时最大扩散批次大小将增加约4到6倍。
- 对于6GB显存GPU,生成速度预计可提升约60%至75%,GPU内存峰值会降低约800MB至1.5GB,最大扩散分辨率将提升约3倍,最大扩散批次大小将增加约4倍。
- 对于24GB显存的4090 GPU,生成速度预计可提升约3%至6%,GPU内存峰值将下降约1GB至1.4GB,最大扩散分辨率将提升约1.6倍,而最大扩散批次大小将增加约2倍。
- 另外对于SDXL,SDXL+ControlNet的速度将提升约30%至45%。
Forge后端移除了原版WebUI中与资源管理相关的所有代码,并对其进行了重构。不需要任何特殊设置,Forge即可支持在4GB显存下运行SDXL以及在2GB显存下运行SD1.5。
Forge做了什么
Stable Diffusion WebUI Forge是Stable Diffusion WebUI的优化版本,和原版WebUI的功能基本保持一致,但是大幅简化了开发流程,优化了资源管理,并加快了推理速度。为什么不直接改WebUI呢?因为WebUI有很多的历史包袱,不好直接大幅度重构,开发者之间协调起来也很麻烦。
“Forge”这个名字来源于“我的世界(Minecraft)的Forge”,这个项目的目标是成为SD WebUI的Forge。在“我的世界”中,Forge解决了模组之间的兼容性问题,确保多个模组可以在同一环境中协同工作,而不会因为互相冲突而导致游戏崩溃或其他不可预见的问题。
与此类似,WebUI Forge也带来的一项重大的革新,这就是Unet Patcher技术。借助这个工具,原本复杂的技术如自注意力引导、Kohya高清修复方案、FreeU、StyleAlign以及Hypertile等,如今通过仅仅约100行代码就能够轻松实现集成,大大简化了开发过程。
有了Unet Patcher,WebUI Forge平台也得以支持和便捷实现一系列创新功能与特性。无论是SVD、Z123、带蒙版的ControlNet系统,还是用于照片生成的照片制作工具(PhotoMaker)等,都变得触手可及。开发者再也不必费尽心思对UNet做复杂的临时性修补,同时也消除了与其他扩展相互干扰的风险,使得整个开发环境更加和谐稳定。
Forge能力介绍
Forge的能力和原版WebUI的能力差不多,界面也基本上是一样的。下边我将主要介绍下 Stable Diffusion WebUI Forge 带来的三个主要新能力。
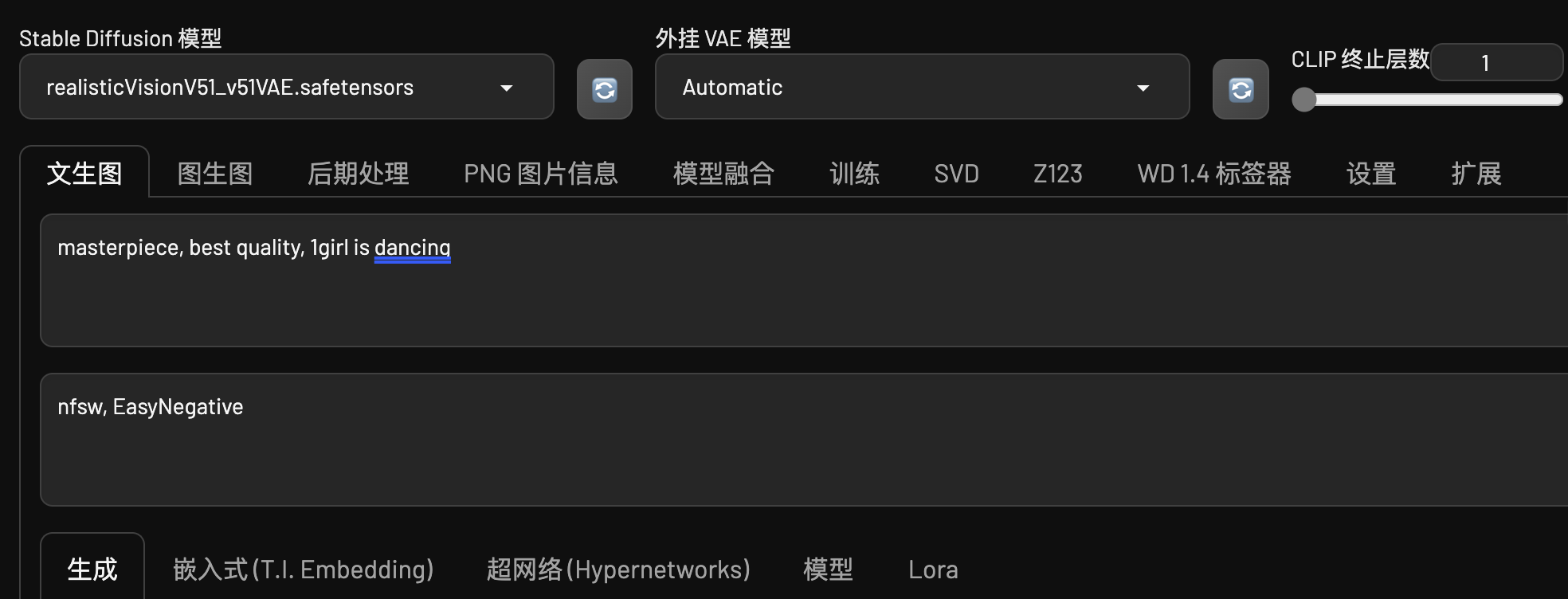
SVD
Stable Video Diffusion是Stability AI公司研发的一款先进的图片生成视频模型,这个模型基于Stable Diffusion模型进行了拓展,在SD的基础上引入了时间维度,能够捕捉并生成动态场景,主要用于将静态图像转化为连续流畅的视频内容。
模型采用了潜在扩散模型(Latent Diffusion Model, LDM)架构,并针对视频数据集进行了优化。通过添加时间层,模型能够理解和预测视频序列中每一帧的变化,从而生成连贯的视频片段。
Stable Video Diffusion可以以每秒3至30帧的可定制帧率生成14帧或25帧长度的视频,并且在外部评估中显示出了优于某些闭源模型的性能。
在这个功能中我们可以使用其最新发布的1.1版本,还有很多参数可以自己控制调整。
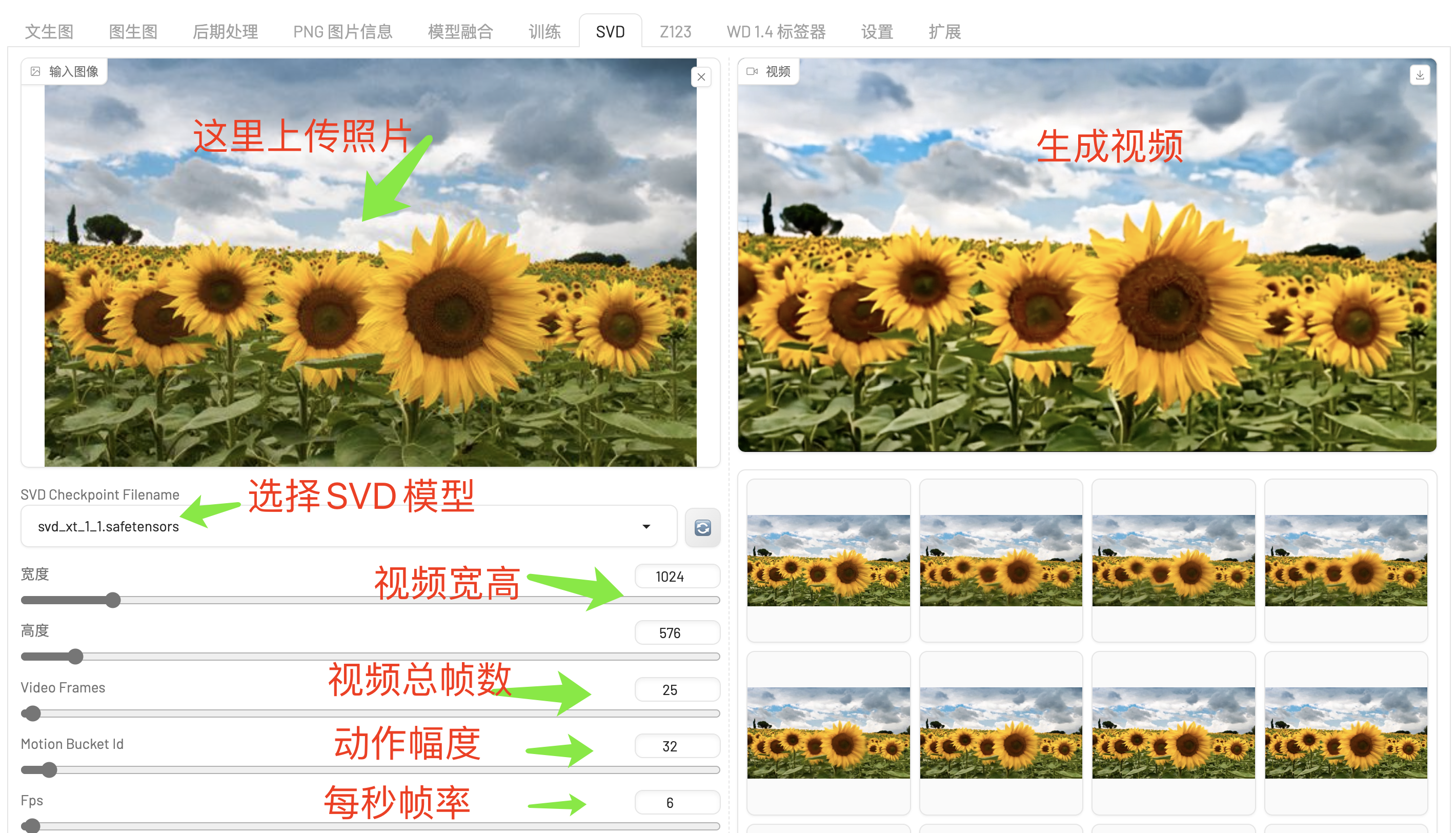
Z123
Z123是Zero123的缩写,Zero123是一种能从单张2D图像生成高质量3D模型的技术,它运用了深度学习的扩散模型原理,允许模型理解并推测出输入图像中物体的3D结构和空间信息,进而生成多视角下的连续且一致的图像或直接构建3D模型。
在Stable Diffusion WebUI Forge中我们需要自己下载部署Zero123模型,这里我部署了stable_zero123.ckpt 模型。Stable Zero123是Zero123模型的一个增强版本,它进一步提升了模型性能,在质量和准确性上有所突破,尤其在处理从单张图像生成3D对象方面表现出色。
这个功能有一些参数可以设置,比如宽度、高度等,重点是海拔和角度,这就可以生成不同的视角的图片。

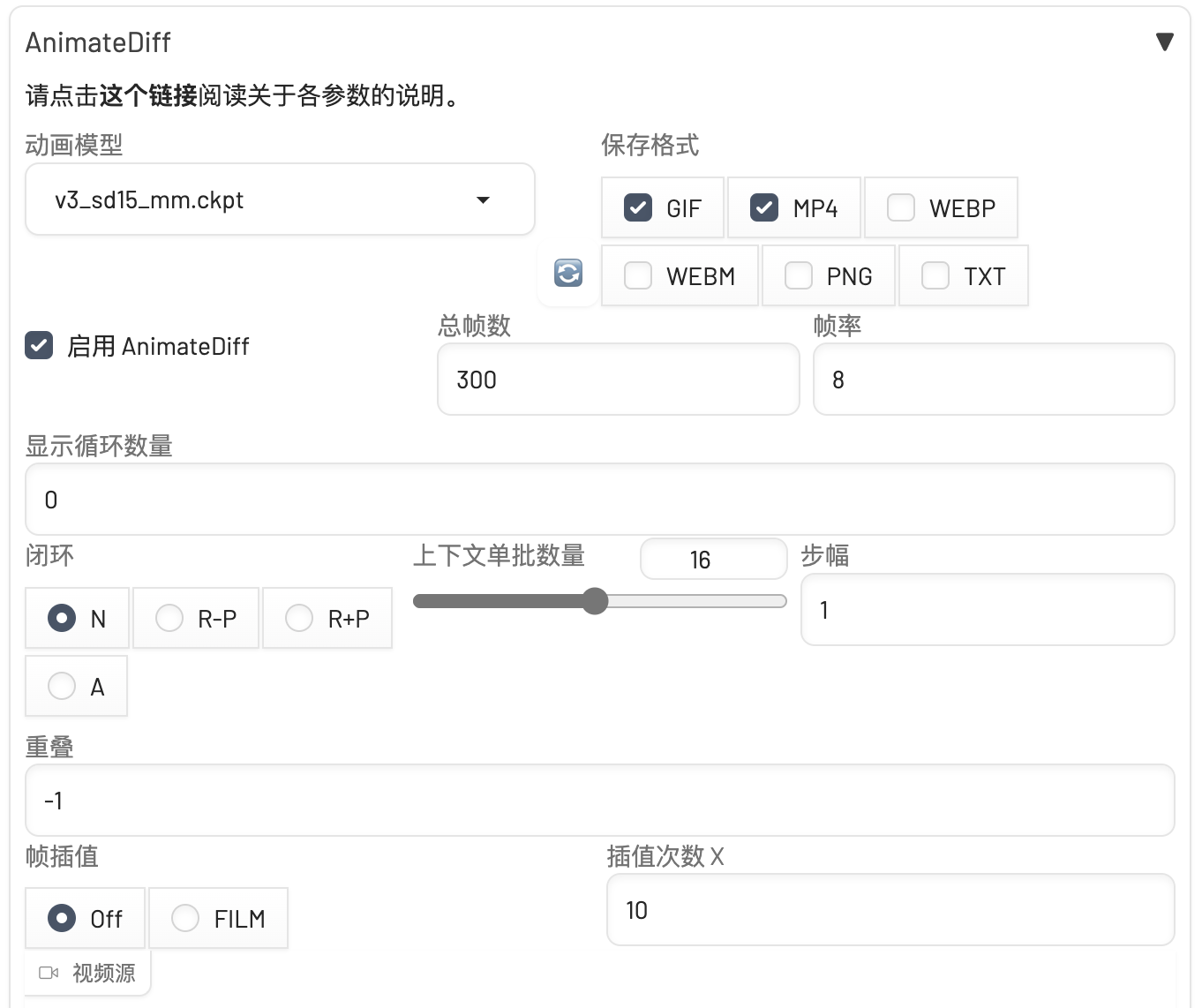
AnimateDiff
AnimateDiff 在WebUI中是个插件,主要用于为 Stable Diffusion 添加动态元素,使其能够生成流畅且连续的动画视频,网络上流行的“女孩的一生”就是用这个工具生成的。因其生成动画的平滑、稳定而受到广泛欢迎,被认为是Stable Diffusion生态中生成动画视频效果最为出色的一款插件。
AnimateDiff 在现有扩散模型的基础上增加了一个运动建模模块,这一模块通过学习大规模视频数据集,能够捕捉并合成合理的时间序列变化,将静止的二次元或三维图像转换为动态的动画。
这个插件也能够用在原版的WebUI中,不过开发者为Forge也维护了一个单独的版本,结合ControlNet的能力也更为强大一些,插件地址:https://github.com/continue-revolution/sd-forge-animatediff
如果你对使用 AnimateDiff 生成视频感兴趣,可以看我这篇文章:
使用Forge
使用镜像
我在AutoDL(AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL)上制作了一个镜像,解决了各种程序包和模型的问题,Z123、SVD、AnimateDiff这三个功能也都准备好了,可以直接使用。
租用实例时,镜像选择“社区镜像”,输入 yinghuoai 就可以找到:
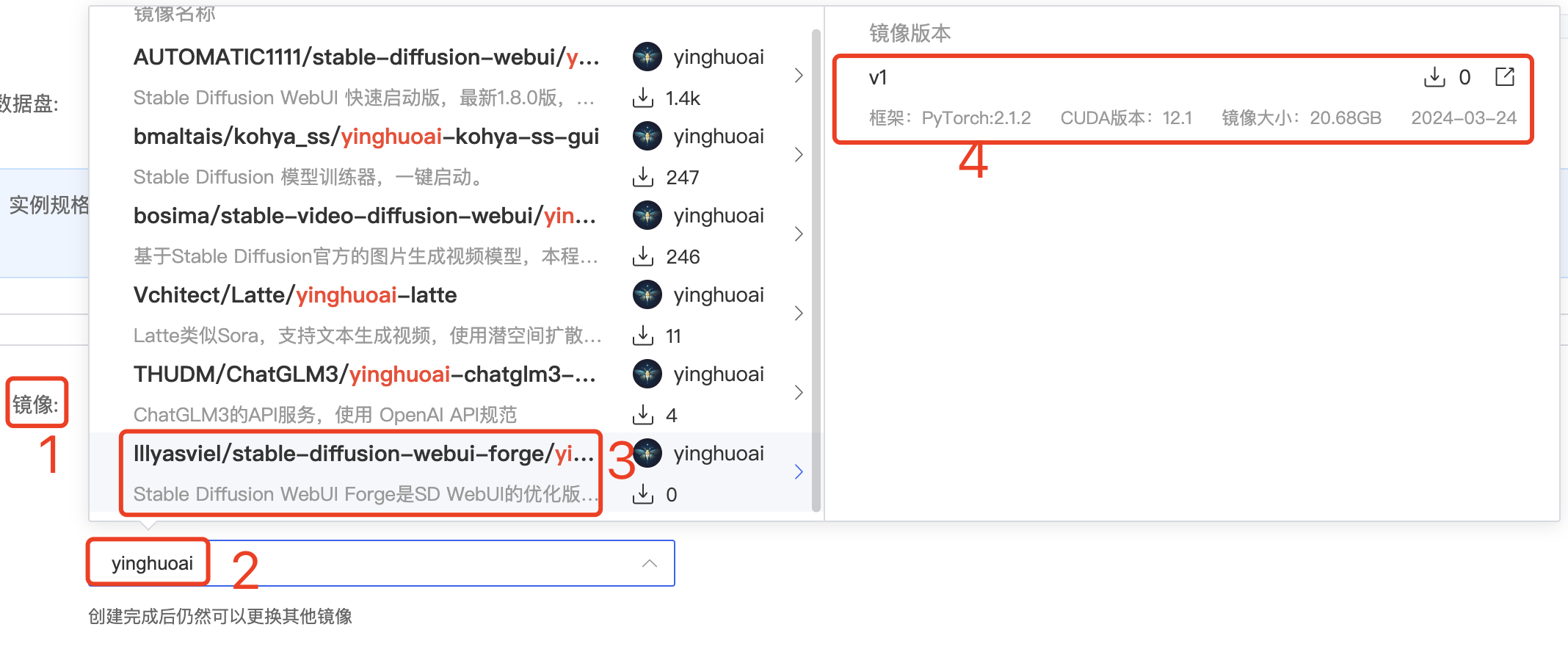
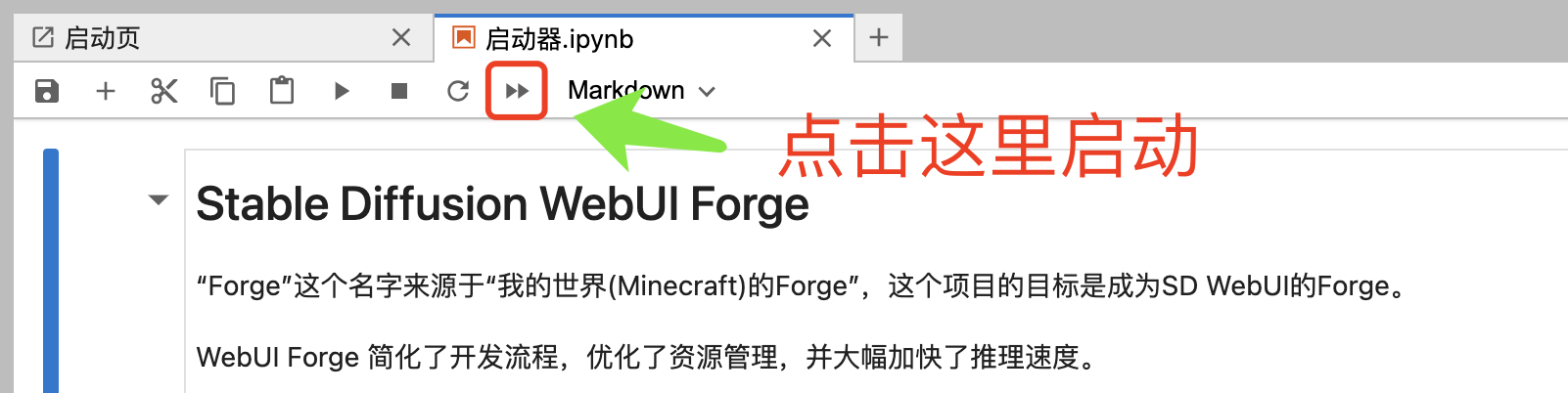
镜像内置了一个简单的启动器,点击即可启动整个 WebUI Forge 程序。
启动后就可以通过 AutoDL 提供的“自定义服务”在浏览器中访问WebUI Forge了。

手动安装
和原版WebUI的安装方法差不多,首先下载代码到本地,然后执行启动脚本(Windows:webui-user.bat,Linux:webui.sh),就可以自动安装部署。
Forge另外提供了一个一键安装包,有兴趣的可以试试:
只是使用时可能会遇到一些缺少包或者模型的问题,需要手动下载或安装。如有问题,欢迎交流沟通。
资源下载
文章中使用的SD模型、Lora模型、SD插件、示例图片等,都已经上传到我整理的 Stable Diffusion 绘画资源中;另外我整理了自己输出的关于 Stable Diffusion 的所有教程,包括基础篇、ControlNet、插件、实战、模型训练等多个方面,比较全面、体系化,特别适合新手和想要系统化学习使用Stable Diffusion WebUI的同学。最新下载地址请发消息:SD 到公众号 yinghuo6ai ,即可获取。

使用中遇到问题,欢迎向我反馈!
版权归原作者 萤火架构 所有, 如有侵权,请联系我们删除。