
在数据驱动的时代,人工智能生成的内容变得越来越普遍。对于内容创作者和分析师来说,区分AI生成的内容与人类生成的内容变得尤为重要。在这篇文章中,我们将介绍一个项目,该项目使用 Flask 和 Requests 库来模拟对 writer.com 的 AI 内容检测功能的访问。
效果演示
地址:https://nice.chuanchuan.cloud/
界面如下,一秒钟即可查出AI生成比例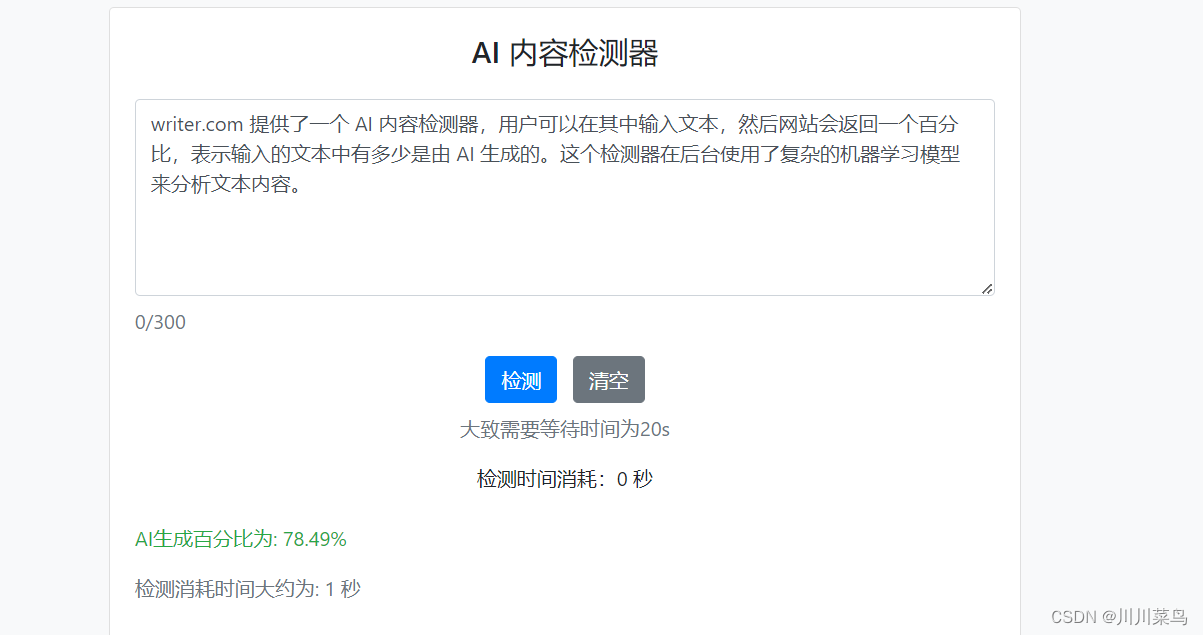
1. 项目背景
writer.com 提供了一个 AI 内容检测器,用户可以在其中输入文本,然后网站会返回一个百分比,表示输入的文本中有多少是由 AI 生成的。这个检测器在后台使用了复杂的机器学习模型来分析文本内容。
2. Selenium实现
最初,我们使用了 Selenium 来模拟浏览器的行为。通过这种方法,我们可以模拟用户在网页上输入文本、点击按钮等操作。但这种方法相对较慢,因为它需要启动浏览器、加载页面和执行 JavaScript。
代码见下方。
3. 优化:使用 Requests 和 BeautifulSoup
3.1 为什么选择 Requests 和 BeautifulSoup?
尽管 Selenium 是一个强大的工具,能够模拟真实的浏览器操作,但它也有其缺点。首先&
本文转载自: https://blog.csdn.net/weixin_46211269/article/details/134194689
版权归原作者 川川菜鸟 所有, 如有侵权,请联系我们删除。
版权归原作者 川川菜鸟 所有, 如有侵权,请联系我们删除。