
背景:
最近用mmdet的时候发现一个问题,在pipeline里进行一些随机操作(例如随机裁剪)的时候,设定一个随机种子random seed,理论上每次随机操作的结果都不同,但是实际上发现会有2张图的操作结果是一样的。
本来以为是batch_size的问题,就去修改了sampers_per_gpu 。结果发现实际上是workers_per_gpu的问题。因此就来好好研究下这俩个参数的作用和意义。
实际上科班的应该对进程比较熟悉,但是也考虑到有很多像我一样非科班的小白,可能对进程workers不是很理解,故此记录下,也欢迎大佬交流指正
这俩个参数具体出现在configs文件里
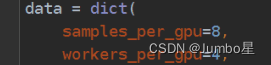
sampers_per_gpu
这个参数会传入在mmdet/datasets/builder.py里
if dist:
# When model is :obj:`DistributedDataParallel`,
# `batch_size` of :obj:`dataloader` is the
# number of training samples on each GPU.
batch_size = samples_per_gpu
num_workers = workers_per_gpu
else:
# When model is obj:`DataParallel`
# the batch size is samples on all the GPUS
batch_size = num_gpus * samples_per_gpu
num_workers = num_gpus * workers_per_gpu
可以看到sampers_per_gpu就是控制batch_size的,决定了dataloader一次从dataset里取几个样本(几张图)。
注意这里单卡和多卡不一样,简单说sampers_per_gpu是决定每张卡取多少sampers,总的batch_size要乘以你用的gpu显卡数目
workers_per_gpu
这个参数决定读取数据时每个gpu分配的线程数 。
数据加载时每个 GPU 使用的子进程(subprocess)数目。
因此如果workers=2,那就会把一个相同的随机种子seed同时作用于两个samper,因此就会导致出现两个分支(进程),就会产生不同组的图做的随机操作完全一样的情况。
本文转载自: https://blog.csdn.net/jiangqixing0728/article/details/127405269
版权归原作者 Jumbo星 所有, 如有侵权,请联系我们删除。
版权归原作者 Jumbo星 所有, 如有侵权,请联系我们删除。