
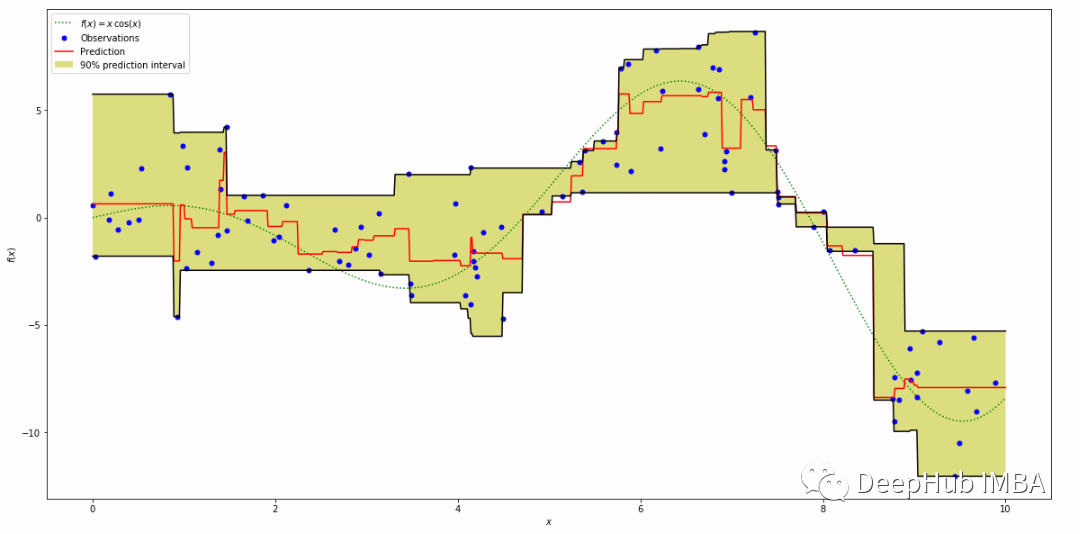
在使用机器学习构建预测模型时,我们不只是想知道“预测值(点预测)”,而是想知道“预测值落在某个范围内的可能性有多大(区间预测)”。例如当需要进行需求预测时,如果只储备最可能的需求预测量,那么缺货的概率非常的大。但是如果库存处于预测的第95个百分位数(需求有95%的可能性小于或等于该值),那么缺货数量会减少到大约20分之1。
获得这些百分位数值的机器学习方法有:
scikit-learn:GradientBoostingRegressor(loss='quantile, alpha=alpha)LightGBM: LGBMRegressor(objective='quantile', alpha=alpha)XGBoost: XGBoostRegressor(objective='reg:quantileerror', quantile_alpha=alpha) (version 2.0~)
这种”预测值落在某个范围内的可能性有多大(区间预测)”的方法都被称作分位数回归,上面的这些机器学习的方法是用了一种叫做Quantile Loss的损失。
Quantile loss是用于评估分位数回归模型性能的一种损失函数。在分位数回归中,我们不仅关注预测的中心趋势(如均值),还关注在分布的不同分位数处的预测准确性。Quantile loss允许我们根据所关注的分位数来量化预测的不确定性。
假设我们有一个预测问题,其中我们要预测一个连续型变量的分布,并且我们关注不同的分位数,例如中位数、0.25分位数、0.75分位数等。对于第q分位数,Quantile Loss定义为:
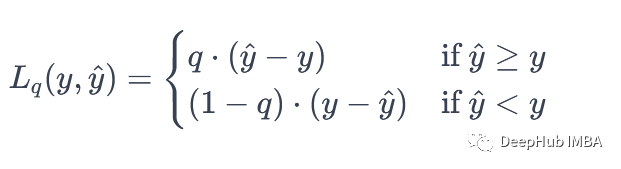
这里:
- yy 是真实值。
- yy 是模型的预测值。
- qq 是目标分位数,取值范围为0,10,1。
这个损失函数的核心思想是,当模型的预测值超过真实值时,损失是预测值与真实值的差值乘以q。当预测值低于真实值时,损失是预测值与真实值的差值乘以1−q。这确保了对于不同的分位数,我们有不同的惩罚。如果我们更关心较小分位数(例如,中位数),我们会设定较小的q,反之亦然。
用Pytorch实现分位数损失
下面是一个使用Pytorch将分位数损失定义为自定义损失函数的示例。
importtorch
defquantile_loss(y_true, y_pred, quantile):
errors=y_true-y_pred
loss=torch.mean(torch.max((quantile-1) *errors, quantile*errors))
returnloss
对于训练来说,跟正常的训练方法一样:
for epoch in range(num_epochs):
for batch_x, batch_y in dataloader:
optimizer.zero_grad()
outputs = model(batch_x)
loss = quantile_loss(outputs, batch_y, quantile)
loss.backward()
optimizer.step()
让我们看看这个自定义的损失函数是否如预期的那样工作。
Pytorch分位数损失测试
首先,我们尝试为x生成均匀随机分布(-5~5),为y生成与x指数成比例的正态随机分布,看看是否可以从x预测y的分位数点。
# Generate dummy data
num_samples = 10000
shape = (num_samples, 1)
torch.manual_seed(0)
# x is uniform random from -5 to 5
# y is random normal distribution * exp(scaled x)
x_tensor = torch.rand(shape) * 10 - 5
x_scaled = x_tensor / 5
y_tensor = torch.randn(shape) * torch.exp(x_scaled)
# Convert values to NumPy array (for graphs)
x = x_tensor.numpy()
y = y_tensor.numpy()
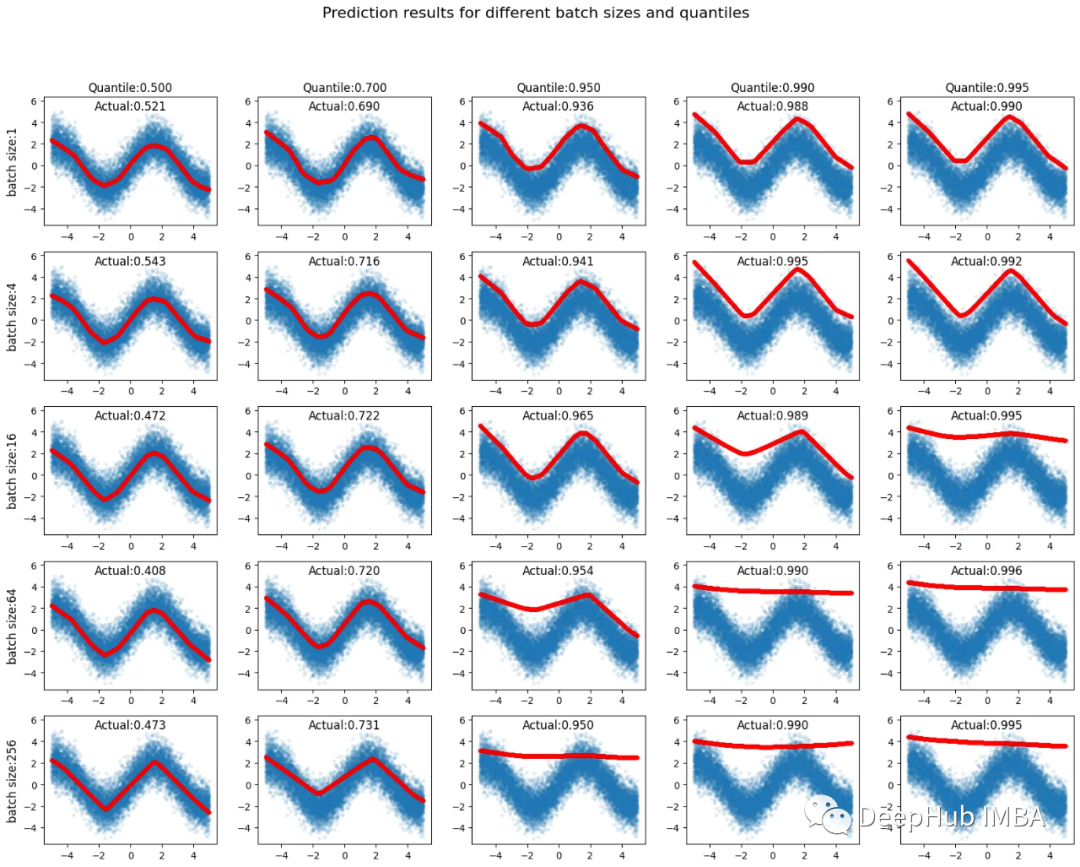
网络结构很简单,两个中间层64个节点+每层relu。在没有任何正则化或提前停止的情况下使用100次epoch。待预测的四分位数(百分位数)在列中为[0.500,0.700,0.950,0.990,0.995],在行中为批大小[1,4,16,64,256],总共有25个预测。在10,000个训练数据实例(蓝色)中,低于预测输出值(红色)的实例的比率在图中被标记为“实际”值。
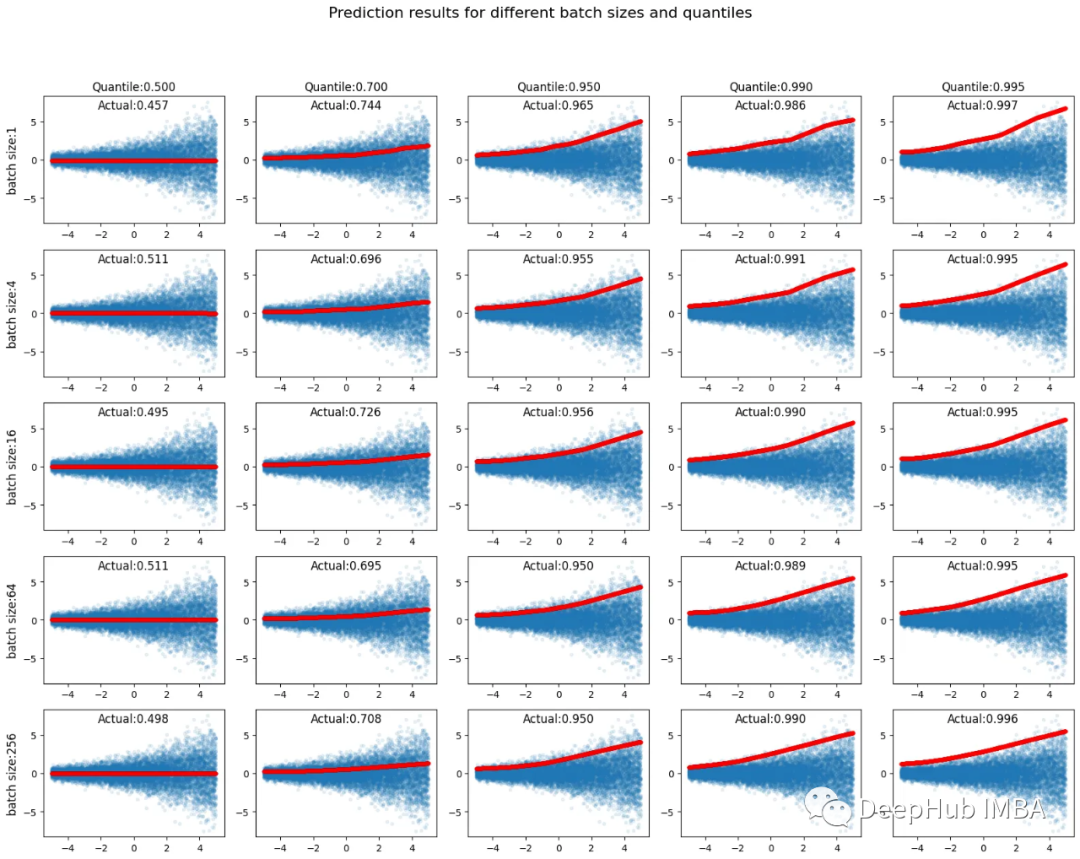
低于指定百分位数值的样本百分比通常接近指定值,并且输出分位数预测的是非常直接的。
再考虑一个稍微复杂的例子,其中y=clip(x, - 2,2) + randn。其中clip(x, - 2,2)是剪辑函数(将值限制在指定范围内)。当数字超出给定范围时,该函数将其限制到最近的边界(如果将范围设置为-2到2,并输入-5的输入值,该函数将返回-2;如果输入10,它将返回2),而randn是遵循正态分布的随机数。网络结构和其他设置与前一种情况相同。
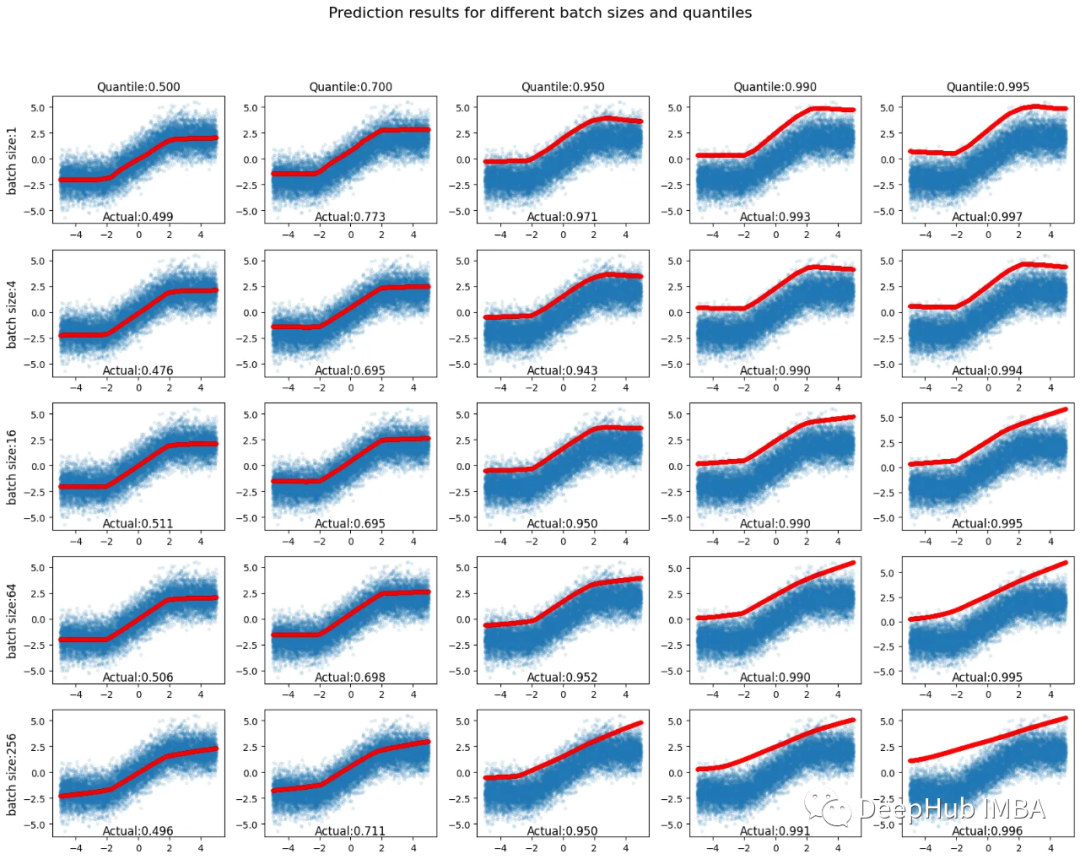
与前一种情况一样,低于指定百分位数值的样本百分比通常接近指定值。分位数预测的理想形状总是左上角图中红线的形状。它应该随着指定的百分位数的增加而平行向上移动。当移动到图的右下方时,预测的红线呈现出更线性的形状,这不是一个理想的结果。
让我们用一个更复杂的形状,我们的目标是y=2sin(x) + randn。其他设置与前一种情况相同。
可以看到低于指定百分位数值的样本百分比通常接近指定值。当向5x5图的右下方移动时,分位数预测的形状偏离了正弦形状。在图的右下方,预测值的红线变得更加线性。
如何选择Q
我们看到,如果设置过高的quantile,会得到扁平化的值,那么如何判断使用Quantile Loss得到的结果是否“扁平”,如何“避免扁平呢”?
检测“扁平化”的方法之一是一起计算第50、68和95个百分位值,并检查这些值之间的关系,即使要获得的最终值是99.5百分位值。如果样本分布服从正态分布,以μ为均值,σ为标准差
在μ±σ区间内的概率约为68;在μ±2σ区间内的概率约为95;在μ±3σ区间内的概率约为99.7
如果第68百分位-第50百分位、第95百分位-第50百分位和99.5百分位-第50百分位值的比值明显偏离1:2:3,我们可以确定偏离的百分位值已经“变平”。
避免扁平化”的第一种方法是减少批量大小,如上面的实验所示。较小的批量大小避免了这个问题,并且不太可能产生平坦的预测。但是减少批大小也有缺点,比如收敛不稳定和增加训练时间,所以它只是有时一个容易采用的选择。
第二种方法是在同一批次中收集相似的样本,而不是随机生成批次。这避免了“在批内低于和高于预测值的样本比例与指定的百分位数值之间的平衡”。
最后"扁平化"是无法避免的,我们只能进行缓解,下列符号用于下列方程。
- P0:第50个百分位值
- P1:第68个百分位值
- P2:第95百分位值
- P3: 99.5百分位值
使用上述变量,可以使用以下流程图获得适当的99.5%百分位数值。

总结
分位数回归是一种强大的统计工具,对于那些关注数据分布中不同区域的问题,以及需要更加灵活建模的情况,都是一种有价值的方法。
本文将介绍了在神经网络种自定义损失实现分位数回归,并且介绍了如何检测和缓解预测结果的"扁平化"问题。Quantile loss在一些应用中很有用,特别是在金融领域的风险管理问题中,因为它提供了一个在不同分位数下评估模型性能的方法。
作者:Shiro Matsumoto