
文章目录
1 前言

论文参考:
1 Neural Architectures for Named Entity Recognition
2 Attention is all you need
3 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
4 Bidirectional LSTM-CRF Models for Sequence Tagging
使用数据集:
https://www.datafountain.cn/competitions/529/ranking
Tips:文章可能存在一些漏洞,欢迎留言指出
2 数据准备
使用了transformers和seqeval库
安装方法:
huggingface-transformers
conda install -c huggingface transformers
seqeval
pip install seqeval -i https://pypi.tuna.tsinghua.edu.cn/simple
代码
import pandas as pd
import torch
from torch import optim
from torch.utils.data import DataLoader
from tqdm import tqdm
from bert_bilstm_crf import Bert_BiLSTM_CRF, NerDataset, NerDatasetTest
from bert_crf import Bert_CRF
from transformers import AutoTokenizer, BertTokenizer
from seqeval.metrics import f1_score
# 路径
TRAIN_PATH ='./dataset/train_data_public.csv'
TEST_PATH ='./dataset/test_public.csv'
MODEL_PATH1 ='./model/bert_bilstm_crf.pkl'
MODEL_PATH2 ='../model/bert_crf.pkl'# 超参数
MAX_LEN =64
BATCH_SIZE =16
EPOCH =5# 预设# 设备
DEVICE ="cuda:0"if torch.cuda.is_available()else"cpu"# tag2index
tag2index ={"O":0,# 其他"B-BANK":1,"I-BANK":2,# 银行实体"B-PRODUCT":3,"I-PRODUCT":4,# 产品实体"B-COMMENTS_N":5,"I-COMMENTS_N":6,# 用户评论,名词"B-COMMENTS_ADJ":7,"I-COMMENTS_ADJ":8# 用户评论,形容词}
index2tag ={v: k for k, v in tag2index.items()}
3 数据预处理
== 流程==
- 使用 s e r i e s . a p p l y ( l i s t ) \textcolor{red}{series.apply(list)} series.apply(list)函数将str转化为list格式
- 加载bert预训练tokenizer,使用 e n c o d e _ p l u s \textcolor{red}{encode_plus} encode_plus函数对每一个text进行encode
- 如果是训练集,则执行如下操作:首先按照空格将每一个tag分割,并转化为索引列表,对每一个index_list,按照长度大于MAX_LEN裁剪,小于MAX_LEN填充的规则,合并为一个list,最后转化为tensor格式
代码
# 预处理defdata_preprocessing(dataset, is_train):# 数据str转化为list
dataset['text_split']= dataset['text'].apply(list)# token
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
texts = dataset['text_split'].array.tolist()
token_texts =[]for text in tqdm(texts):
tokenized = tokenizer.encode_plus(text=text,
max_length=MAX_LEN,
return_token_type_ids=True,
return_attention_mask=True,
return_tensors='pt',
padding='max_length',
truncation=True)
token_texts.append(tokenized)# 训练集有tag,测试集没有tag
tags =Noneif is_train:
dataset['tag']= dataset['BIO_anno'].apply(lambda x: x.split(sep=' '))
tags =[]for tag in tqdm(dataset['tag'].array.tolist()):
index_list =[0]+[tag2index[t]for t in tag]+[0]iflen(index_list)< MAX_LEN:# 填充
pad_length = MAX_LEN -len(index_list)
index_list +=[tag2index['O']]* pad_length
iflen(index_list)> MAX_LEN:# 裁剪
index_list = index_list[:MAX_LEN-1]+[0]
tags.append(index_list)
tags = torch.LongTensor(tags)return token_texts, tags
4 Bert-BiLSTM-CRF模型

相对于Bert-CRF,中间添加了双向LSTM层。相对BiLSTM-CRF,相当于前面的word_embedding层替换为了bert预训练模型。
代码
import torch
from torch import nn
from torchcrf import CRF
from transformers import BertModel
from torch.utils.data import Dataset
classBert_BiLSTM_CRF(nn.Module):def__init__(self, tag2index):super(Bert_BiLSTM_CRF, self).__init__()
self.tagset_size =len(tag2index)# bert层
self.bert = BertModel.from_pretrained('bert-base-chinese')# config = self.bert.config# lstm层
self.lstm = nn.LSTM(input_size=768, hidden_size=128, num_layers=1, batch_first=True, bidirectional=True)# dropout层
self.dropout = nn.Dropout(p=0.1)# Dense层
self.dense = nn.Linear(in_features=256, out_features=self.tagset_size)# CRF层
self.crf = CRF(num_tags=self.tagset_size)# 隐藏层
self.hidden =None# 负对数似然损失函数defneg_log_likelihood(self, emissions, tags=None, mask=None, reduction=None):return-1* self.crf(emissions=emissions, tags=tags, mask=mask, reduction=reduction)defforward(self, token_texts, tags):"""
token_texts:{"input_size": tensor, [batch, 1, seq_len]->[batch, seq_len]
"token_type_ids": tensor, [batch, 1, seq_len]->[batch, seq_len]
"attention_mask": tensor [batch, 1, seq_len]->[batch, seq_len]->[seq_len, batch]
}
tags: [batch, seq_len]->[seq_len, batch]
bert_out: [batch, seq_len, hidden_size(768)]->[seq_len, batch, hidden_size]
self.hidden: [num_layers * num_directions, hidden_size(128)]
out: [seq_len, batch, hidden_size * 2(256)]
lstm_feats: [seq_len, batch, tagset_size]
loss: tensor
predictions: [batch, num]
"""
texts, token_type_ids, masks = token_texts['input_ids'], token_texts['token_type_ids'], token_texts['attention_mask']
texts = texts.squeeze(1)
token_type_ids = token_type_ids.squeeze(1)
masks = masks.squeeze(1)
bert_out = self.bert(input_ids=texts, attention_mask=masks, token_type_ids=token_type_ids)[0]
bert_out = bert_out.permute(1,0,2)# 检测设备
device = bert_out.device
# 初始化隐藏层参数
self.hidden =(torch.randn(2, bert_out.size(0),128).to(device),
torch.randn(2, bert_out.size(0),128).to(device))
out, self.hidden = self.lstm(bert_out, self.hidden)
lstm_feats = self.dense(out)# 格式转换
masks = masks.permute(1,0)
masks = masks.clone().detach().bool()# masks = torch.tensor(masks, dtype=torch.uint8)# 计算损失值和预测值if tags isnotNone:
tags = tags.permute(1,0)
loss = self.neg_log_likelihood(lstm_feats, tags, masks,'mean')
predictions = self.crf.decode(emissions=lstm_feats, mask=masks)# [batch, 任意数]return loss, predictions
else:
predictions = self.crf.decode(emissions=lstm_feats, mask=masks)return predictions
Dataset
classNerDataset(Dataset):def__init__(self, token_texts, tags):super(NerDataset, self).__init__()
self.token_texts = token_texts
self.tags = tags
def__getitem__(self, index):return{"token_texts": self.token_texts[index],"tags": self.tags[index]if self.tags isnotNoneelseNone,}def__len__(self):returnlen(self.token_texts)classNerDatasetTest(Dataset):def__init__(self, token_texts):super(NerDatasetTest, self).__init__()
self.token_texts = token_texts
def__getitem__(self, index):return{"token_texts": self.token_texts[index],"tags":0}def__len__(self):returnlen(self.token_texts)
前向传播分析
token_texts:{
“input_size”: tensor, [batch, 1, seq_len]->[batch, seq_len]
“token_type_ids”: tensor, [batch, 1, seq_len]->[batch, seq_len]
“attention_mask”: tensor [batch, 1, seq_len]->[batch, seq_len]->[seq_len, batch]
}
tags: [batch, seq_len]->[seq_len, batch]
bert_out: [batch, seq_len, hidden_size(768)]->[seq_len, batch, hidden_size]
self.hidden: [num_layers * num_directions, hidden_size(128)]
out: [seq_len, batch, hidden_size * 2(256)]
lstm_feats: [seq_len, batch, tagset_size]
loss: tensor
predictions: [batch, num]
5 Bert-CRF模型

from torch import nn
from torchcrf import CRF
from transformers import BertModel
classBert_CRF(nn.Module):def__init__(self, tag2index):super(Bert_CRF, self).__init__()
self.tagset_size =len(tag2index)# bert层
self.bert = BertModel.from_pretrained('bert-base-chinese')# dense层
self.dense = nn.Linear(in_features=768, out_features=self.tagset_size)# CRF层
self.crf = CRF(num_tags=self.tagset_size)# 隐藏层
self.hidden =Nonedefneg_log_likelihood(self, emissions, tags=None, mask=None, reduction=None):return-1* self.crf(emissions=emissions, tags=tags, mask=mask, reduction=reduction)defforward(self, token_texts, tags):"""
token_texts:{"input_size": tensor, [batch, 1, seq_len]->[batch, seq_len]
"token_type_ids": tensor, [batch, 1, seq_len]->[batch, seq_len]
"attention_mask": tensor [batch, 1, seq_len]->[batch, seq_len]->[seq_len, batch]
}
tags: [batch, seq_len]->[seq_len, batch]
bert_out: [batch, seq_len, hidden_size(768)]->[seq_len, batch, hidden_size]
feats: [seq_len, batch, tagset_size]
loss: tensor
predictions: [batch, num]
"""
texts, token_type_ids, masks = token_texts.values()
texts = texts.squeeze(1)
token_type_ids = token_type_ids.squeeze(1)
masks = masks.squeeze(1)
bert_out = self.bert(input_ids=texts, attention_mask=masks, token_type_ids=token_type_ids)[0]
bert_out = bert_out.permute(1,0,2)
feats = self.dense(bert_out)# 格式转换
masks = masks.permute(1,0)
masks = masks.clone().detach().bool()# 计算损失之和预测值if tags isnotNone:
tags = tags.permute(1,0)
loss = self.neg_log_likelihood(feats, tags, masks,'mean')
predictions = self.crf.decode(emissions=feats, mask=masks)return loss, predictions
else:
predictions = self.crf.decode(emissions=feats, mask=masks)return predictions
前向传播分析
token_texts:{
“input_size”: tensor, [batch, 1, seq_len]->[batch, seq_len]
“token_type_ids”: tensor, [batch, 1, seq_len]->[batch, seq_len]
“attention_mask”: tensor [batch, 1, seq_len]->[batch, seq_len]->[seq_len, batch]
}
tags: [batch, seq_len]->[seq_len, batch]
bert_out: [batch, seq_len, hidden_size(768)]->[seq_len, batch, hidden_size]
feats: [seq_len, batch, tagset_size]
loss: tensor
predictions: [batch, num]
6 模型训练
# 训练deftrain(train_dataloader, model, optimizer, epoch):for i, batch_data inenumerate(train_dataloader):
token_texts = batch_data['token_texts'].to(DEVICE)
tags = batch_data['tags'].to(DEVICE)
loss, predictions = model(token_texts, tags)
optimizer.zero_grad()
loss.backward()
optimizer.step()if i %200==0:
micro_f1 = get_f1_score(tags, predictions)print(f'Epoch:{epoch} | i:{i} | loss:{loss.item()} | Micro_F1:{micro_f1}')
7 结果评估
# 计算f1值defget_f1_score(tags, predictions):
tags = tags.to('cpu').data.numpy().tolist()
temp_tags =[]
final_tags =[]for index inrange(BATCH_SIZE):# predictions先去掉头,再去掉尾
predictions[index].pop()
length =len(predictions[index])
temp_tags.append(tags[index][1:length])
predictions[index].pop(0)# 格式转化,转化为List(str)
temp_tags[index]=[index2tag[x]for x in temp_tags[index]]
predictions[index]=[index2tag[x]for x in predictions[index]]
final_tags.append(temp_tags[index])
f1 = f1_score(final_tags, predictions, average='micro')return f1
Bert-BiLSTM-CRF
GPU_NAME:NVIDIA GeForce RTX 3060 Laptop GPU | Memory_Allocated:413399040
Epoch:0 | i:0 | loss:58.75139236450195 | Micro_F1:0.0
Epoch:0 | i:200 | loss:26.20857048034668 | Micro_F1:0.0
Epoch:0 | i:400 | loss:18.385879516601562 | Micro_F1:0.0
Epoch:1 | i:0 | loss:20.496620178222656 | Micro_F1:0.0
Epoch:1 | i:200 | loss:15.421577453613281 | Micro_F1:0.0
Epoch:1 | i:400 | loss:11.486358642578125 | Micro_F1:0.0
Epoch:2 | i:0 | loss:14.486601829528809 | Micro_F1:0.0
Epoch:2 | i:200 | loss:10.369649887084961 | Micro_F1:0.18867924528301888
Epoch:2 | i:400 | loss:8.056020736694336 | Micro_F1:0.5652173913043479
Epoch:3 | i:0 | loss:14.958343505859375 | Micro_F1:0.41025641025641024
Epoch:3 | i:200 | loss:9.968450546264648 | Micro_F1:0.380952380952381
Epoch:3 | i:400 | loss:8.947534561157227 | Micro_F1:0.5614035087719299
Epoch:4 | i:0 | loss:9.189300537109375 | Micro_F1:0.5454545454545454
Epoch:4 | i:200 | loss:8.673486709594727 | Micro_F1:0.43999999999999995
Epoch:4 | i:400 | loss:6.431578636169434 | Micro_F1:0.6250000000000001
Bert-CRF
GPU_NAME:NVIDIA GeForce RTX 3060 Laptop GPU | Memory_Allocated:409739264
Epoch:0 | i:0 | loss:57.06057357788086 | Micro_F1:0.0
Epoch:0 | i:200 | loss:12.05904483795166 | Micro_F1:0.0
Epoch:0 | i:400 | loss:13.805888175964355 | Micro_F1:0.39393939393939387
Epoch:1 | i:0 | loss:9.807424545288086 | Micro_F1:0.4905660377358491
Epoch:1 | i:200 | loss:8.098043441772461 | Micro_F1:0.509090909090909
Epoch:1 | i:400 | loss:7.059831619262695 | Micro_F1:0.611111111111111
Epoch:2 | i:0 | loss:6.629759788513184 | Micro_F1:0.6133333333333333
Epoch:2 | i:200 | loss:3.593130350112915 | Micro_F1:0.6896551724137931
Epoch:2 | i:400 | loss:6.8786163330078125 | Micro_F1:0.6666666666666666
Epoch:3 | i:0 | loss:5.009466648101807 | Micro_F1:0.6969696969696969
Epoch:3 | i:200 | loss:2.9549810886383057 | Micro_F1:0.8450704225352113
Epoch:3 | i:400 | loss:3.3801448345184326 | Micro_F1:0.868421052631579
Epoch:4 | i:0 | loss:5.864352226257324 | Micro_F1:0.626865671641791
Epoch:4 | i:200 | loss:3.308518409729004 | Micro_F1:0.7666666666666667
Epoch:4 | i:400 | loss:4.221902847290039 | Micro_F1:0.7000000000000001
分析
进行了5个epoch的训练
数据集比较小,只有7000多条数据,因此两个模型效果拟合效果相对BiLSTM+CRF模型提升不大。而添加了双向LSTM层之后,模型效果反而有所下降。
8 训练集流水线
注意学习率要设置小一点(小于1e-5),否则预测结果均为0,不收敛。
defexecute():# 加载训练集
train_dataset = pd.read_csv(TRAIN_PATH, encoding='utf8')# 数据预处理
token_texts, tags = data_preprocessing(train_dataset, is_train=True)# 数据集装载
train_dataset = NerDataset(token_texts, tags)
train_dataloader = DataLoader(dataset=train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=4)# 构建模型# model = Bert_BiLSTM_CRF(tag2index=tag2index).to(DEVICE)
model = Bert_CRF(tag2index=tag2index).to(DEVICE)
optimizer = optim.AdamW(model.parameters(), lr=1e-6)print(f"GPU_NAME:{torch.cuda.get_device_name()} | Memory_Allocated:{torch.cuda.memory_allocated()}")# 模型训练for i inrange(EPOCH):
train(train_dataloader, model, optimizer, i)# 保存模型
torch.save(model.state_dict(), MODEL_PATH2)
9 测试集流水线
# 测试集预测实体标签deftest():# 加载数据集
test_dataset = pd.read_csv(TEST_PATH, encoding='utf8')# 数据预处理
token_texts, _ = data_preprocessing(test_dataset, is_train=False)# 装载测试集
dataset_test = NerDatasetTest(token_texts)
test_dataloader = DataLoader(dataset=dataset_test, batch_size=BATCH_SIZE, shuffle=False, num_workers=4)# 构建模型# model = Bert_BiLSTM_CRF(tag2index).to(DEVICE)
model = Bert_CRF(tag2index).to(DEVICE)
model.load_state_dict(torch.load(MODEL_PATH2))# 模型预测
model.eval()
predictions_list =[]with torch.no_grad():for i, batch_data inenumerate(test_dataloader):
token_texts = batch_data['token_texts'].to(DEVICE)
predictions = model(token_texts,None)
predictions_list.extend(predictions)print(len(predictions_list))print(len(test_dataset['text']))# 将预测结果转换为文本格式
entity_tag_list =[]
index2tag ={v: k for k, v in tag2index.items()}# 反转字典for i,(text, predictions)inenumerate(zip(test_dataset['text'], predictions_list)):# 删除首位和最后一位
predictions.pop()
predictions.pop(0)
text_entity_tag =[]for c, t inzip(text, predictions):if t !=0:
text_entity_tag.append(c + index2tag[t])
entity_tag_list.append(" ".join(text_entity_tag))# 合并为str并加入列表中print(len(entity_tag_list))
result_df = pd.DataFrame(data=entity_tag_list, columns=['result'])
result_df.to_csv('./data/result_df3.csv')
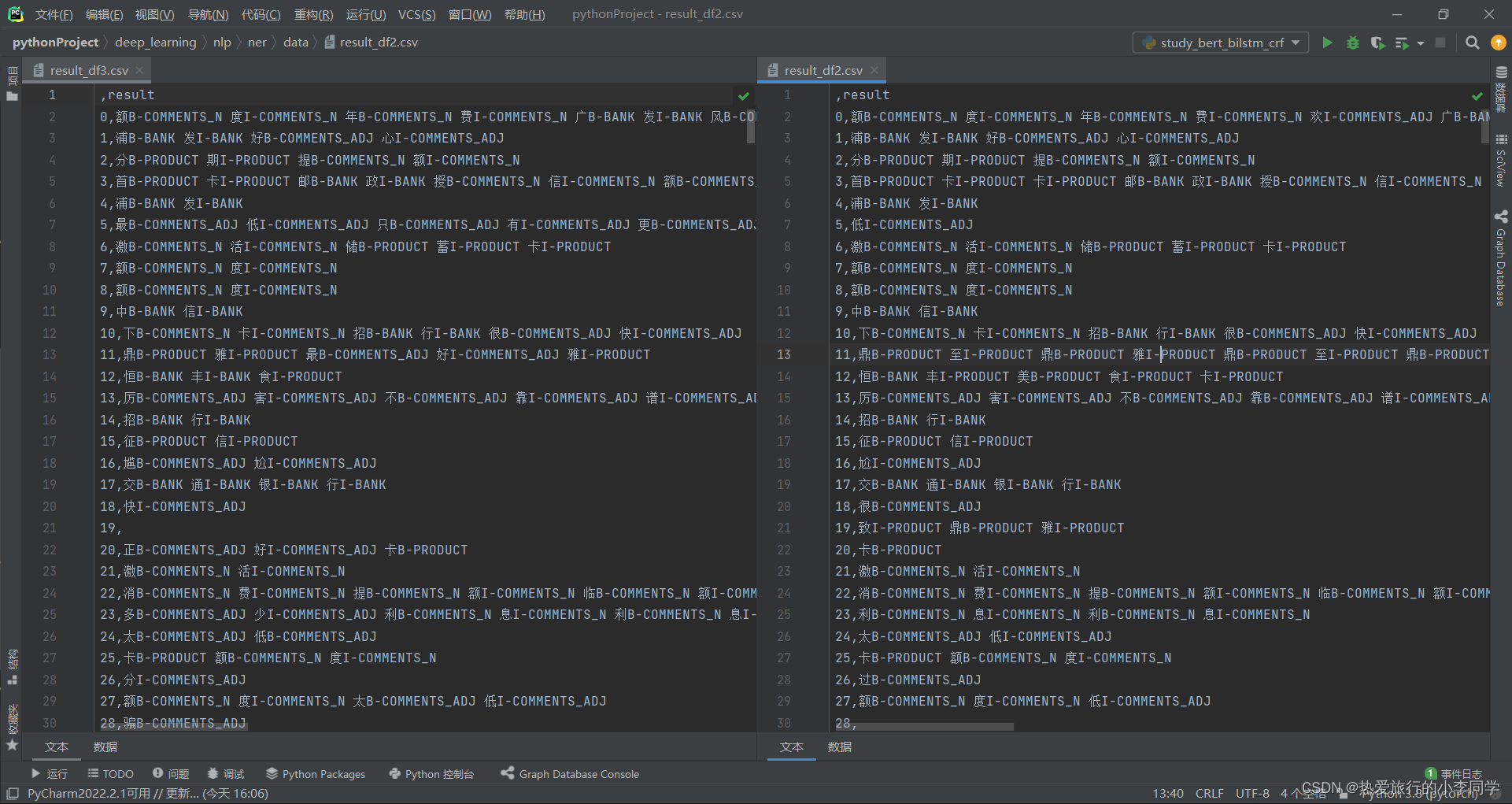
结果好像存在一些问题。。。
10 记录遇到的一些坑
(1)模型预测结果全为O
原因:按照之前的模型,AdamW优化器学习率设置0.001,学习率过高,导致梯度下降过程中落入了局部最低点。
解决方法:重新设置学习率为1e-6
(2)transformers的AdamW显示过期
解决方法:直接使用torch.optim的AdamW即可
(3)transformers库在ubuntu上无法使用
原因:缺少依赖
解决方法:
apt-get update
apt-getinstall libssl1.0.0 libssl-dev
使用此代码在服务器终端上跑完后,仍会报错,原因未知,暂时用os.system()嵌入到代码中,在windows系统中无此报错。
(4)笔记本(联想R7000P2021)运行代码温度过高(最高95度)
解决方法:先用均衡模式(CPU不睿频)跑,温度只有六七十度,然后开启野兽模式跑一段时间,温度高了再切换为均衡模式。
11 完整代码
import pandas as pd
import torch
from torch import optim
from torch.utils.data import DataLoader
from tqdm import tqdm
from bert_bilstm_crf import Bert_BiLSTM_CRF, NerDataset, NerDatasetTest
from bert_crf import Bert_CRF
from transformers import AutoTokenizer, BertTokenizer
from seqeval.metrics import f1_score
# 路径
TRAIN_PATH ='./dataset/train_data_public.csv'
TEST_PATH ='./dataset/test_public.csv'
MODEL_PATH1 ='./model/bert_bilstm_crf.pkl'
MODEL_PATH2 ='../model/bert_crf.pkl'# 超参数
MAX_LEN =64
BATCH_SIZE =16
EPOCH =5# 预设# 设备
DEVICE ="cuda:0"if torch.cuda.is_available()else"cpu"# tag2index
tag2index ={"O":0,# 其他"B-BANK":1,"I-BANK":2,# 银行实体"B-PRODUCT":3,"I-PRODUCT":4,# 产品实体"B-COMMENTS_N":5,"I-COMMENTS_N":6,# 用户评论,名词"B-COMMENTS_ADJ":7,"I-COMMENTS_ADJ":8# 用户评论,形容词}
index2tag ={v: k for k, v in tag2index.items()}# 训练deftrain(train_dataloader, model, optimizer, epoch):for i, batch_data inenumerate(train_dataloader):
token_texts = batch_data['token_texts'].to(DEVICE)
tags = batch_data['tags'].to(DEVICE)
loss, predictions = model(token_texts, tags)
optimizer.zero_grad()
loss.backward()
optimizer.step()if i %200==0:
micro_f1 = get_f1_score(tags, predictions)print(f'Epoch:{epoch} | i:{i} | loss:{loss.item()} | Micro_F1:{micro_f1}')# 计算f1值defget_f1_score(tags, predictions):
tags = tags.to('cpu').data.numpy().tolist()
temp_tags =[]
final_tags =[]for index inrange(BATCH_SIZE):# predictions先去掉头,再去掉尾
predictions[index].pop()
length =len(predictions[index])
temp_tags.append(tags[index][1:length])
predictions[index].pop(0)# 格式转化,转化为List(str)
temp_tags[index]=[index2tag[x]for x in temp_tags[index]]
predictions[index]=[index2tag[x]for x in predictions[index]]
final_tags.append(temp_tags[index])
f1 = f1_score(final_tags, predictions, average='micro')return f1
# 预处理defdata_preprocessing(dataset, is_train):# 数据str转化为list
dataset['text_split']= dataset['text'].apply(list)# token
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
texts = dataset['text_split'].array.tolist()
token_texts =[]for text in tqdm(texts):
tokenized = tokenizer.encode_plus(text=text,
max_length=MAX_LEN,
return_token_type_ids=True,
return_attention_mask=True,
return_tensors='pt',
padding='max_length',
truncation=True)
token_texts.append(tokenized)# 训练集有tag,测试集没有tag
tags =Noneif is_train:
dataset['tag']= dataset['BIO_anno'].apply(lambda x: x.split(sep=' '))
tags =[]for tag in tqdm(dataset['tag'].array.tolist()):
index_list =[0]+[tag2index[t]for t in tag]+[0]iflen(index_list)< MAX_LEN:# 填充
pad_length = MAX_LEN -len(index_list)
index_list +=[tag2index['O']]* pad_length
iflen(index_list)> MAX_LEN:# 裁剪
index_list = index_list[:MAX_LEN-1]+[0]
tags.append(index_list)
tags = torch.LongTensor(tags)return token_texts, tags
# 执行流水线defexecute():# 加载训练集
train_dataset = pd.read_csv(TRAIN_PATH, encoding='utf8')# 数据预处理
token_texts, tags = data_preprocessing(train_dataset, is_train=True)# 数据集装载
train_dataset = NerDataset(token_texts, tags)
train_dataloader = DataLoader(dataset=train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=4)# 构建模型# model = Bert_BiLSTM_CRF(tag2index=tag2index).to(DEVICE)
model = Bert_CRF(tag2index=tag2index).to(DEVICE)
optimizer = optim.AdamW(model.parameters(), lr=1e-6)print(f"GPU_NAME:{torch.cuda.get_device_name()} | Memory_Allocated:{torch.cuda.memory_allocated()}")# 模型训练for i inrange(EPOCH):
train(train_dataloader, model, optimizer, i)# 保存模型
torch.save(model.state_dict(), MODEL_PATH2)# 测试集预测实体标签deftest():# 加载数据集
test_dataset = pd.read_csv(TEST_PATH, encoding='utf8')# 数据预处理
token_texts, _ = data_preprocessing(test_dataset, is_train=False)# 装载测试集
dataset_test = NerDatasetTest(token_texts)
test_dataloader = DataLoader(dataset=dataset_test, batch_size=BATCH_SIZE, shuffle=False, num_workers=4)# 构建模型
model = Bert_BiLSTM_CRF(tag2index).to(DEVICE)
model.load_state_dict(torch.load(MODEL_PATH2))# 模型预测
model.eval()
predictions_list =[]with torch.no_grad():for i, batch_data inenumerate(test_dataloader):
token_texts = batch_data['token_texts'].to(DEVICE)
predictions = model(token_texts,None)
predictions_list.extend(predictions)print(len(predictions_list))print(len(test_dataset['text']))# 将预测结果转换为文本格式
entity_tag_list =[]
index2tag ={v: k for k, v in tag2index.items()}# 反转字典for i,(text, predictions)inenumerate(zip(test_dataset['text'], predictions_list)):# 删除首位和最后一位
predictions.pop()
predictions.pop(0)
text_entity_tag =[]for c, t inzip(text, predictions):if t !=0:
text_entity_tag.append(c + index2tag[t])
entity_tag_list.append(" ".join(text_entity_tag))# 合并为str并加入列表中print(len(entity_tag_list))
result_df = pd.DataFrame(data=entity_tag_list, columns=['result'])
result_df.to_csv('./data/result_df3.csv')if __name__ =='__main__':
execute()
test()
版权归原作者 热爱旅行的小李同学 所有, 如有侵权,请联系我们删除。