
前言:
上次我们介绍了同为“国产大模型五虎”的MiniMax,今天就继续来盘点一下国内估值最高的大模型企业智谱AI,同时也是五虎中的另外一虎。
“国产大模型五虎”指的是由阿里投资的五家大模型独角兽:智谱 AI、百川智能、月之暗面、零一万物和Minimax(排名不分先后)
智谱AI:智谱AI开放平台 (aminer.cn)
我们先来简单的介绍一下智谱AI是一家什么样的大模型企业
智谱AI是一家源自清华大学计算机系技术成果的高科技公司
由张鹏作为CEO领军,核心成员多为清华大学等顶尖学府的学者
自2019年成立以来,一直致力于在认知智能领域拓宽人工智能技术的边界
公司的核心愿景是实现让机器具备类似人类的思考方式,向AGI的方向发展。
再来回顾一下智谱AI的发展时间线
2019年,依托清华大学的知识工程实验室,致力于端侧大模型技术,成立了智谱AI
2020年,智谱AI开始研发GLM预训练架构,并训练了百亿参数模型GLM-10B
2021年,公司利用MoE架构成功训练出万亿稀疏模型
2023年10月,完成超25亿元人民币融资,成为国内估值最高的大模型公司,超100亿人民币
目前,智谱AI的核心技术为端侧大模型
ChatGLM系列大模型基于GLM预训练架构,具备高性能、低延迟的特性,包括多个不同规模的版本,早起的产品有ChatGLM-6B、ChatGLM-10B等,截止到目前已经迭代了三款旗舰大模型,分别为:
ChatGLM2(2023年6月)
ChatGLM3(2023年10月)
GLM-4(2024年1月16日)
在中文能力的方面,GLM-4可以比肩ChatGPT-4。该模型在多个英文数据集上达到了GPT-4的90%至100%的水平,在中文对齐能力上甚至整体超过了GPT-4。
GLM-4可以支持128k的上下文窗口长度,单次提示词可以处理的文本长度相当于300页
且在“大海捞针”测试中,GLM-4模型在128K文本长度内能够实现几乎100%的精度召回
并且ChatGLM系列大模型集成了自研的AgentTuning技术,能够通过训练和调整模型,使其更好地适应特定任务的需求
另外,智谱AI还开发了文生图的大模型CogView
CogView模型采用了Transformer+VQVAE架构,这种架构的优势在于它能够同时学习模态间和模态内的多种关联性,从而提升图像与文本之间跨模态语义匹配的效果
其在MS COCO数据集上的表现超过了OpenAI的DALL·E
值得一提的是,CogView的代码已经在GitHub上开源了

目前,智谱AI开放了通用大模型等诸多主流大模型接口
下面我们就简单的从几个方面来测试一下他们最新的模型GLM-4,结果仅供参考哈

我问了一个这两天网上流行的新梗“成都迪士尼”,结果与实际内容相差不二
再试一下数学计算能力
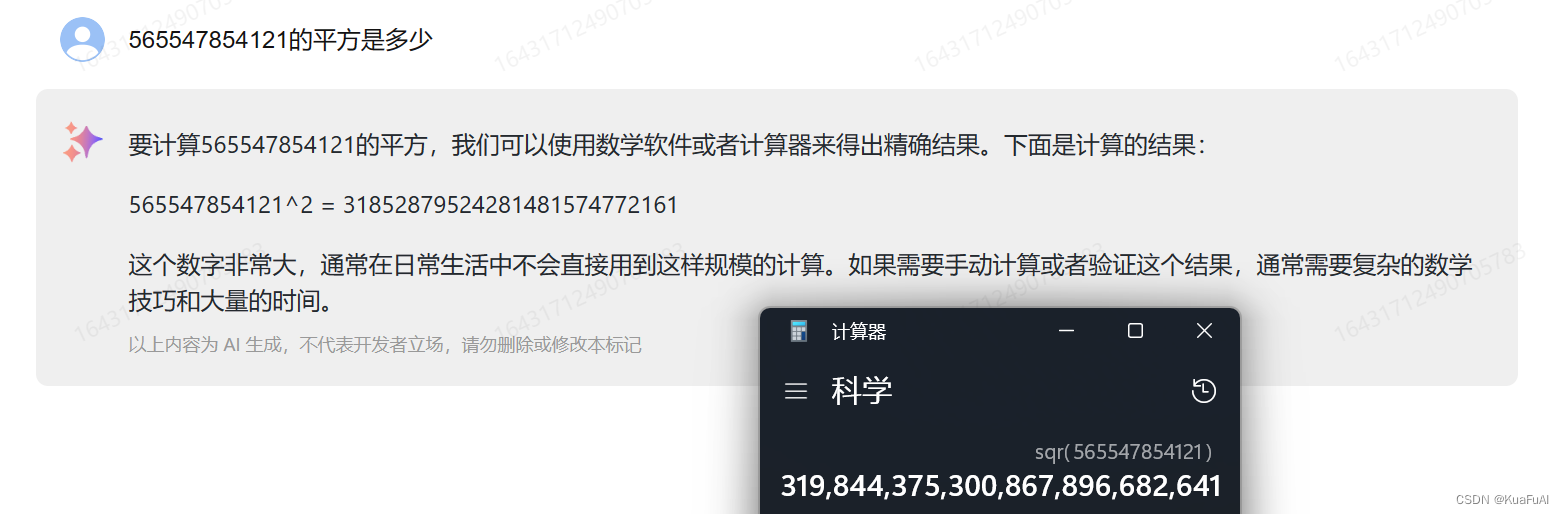
显而易见,在数学计算能力这块,还是答错了,不过数学计算能力一直是大模型需要攻克的难题,强如Claude3也会在这种问题上出错
继续让它帮我们写一篇题为:大模型浪潮来袭,普通人应如何把握机会的文章
这里我的要求是不分点,不少于800字,看看效果如何
 通篇读下来,感觉中规中矩,顺序词用的太多了,且“此外”,“总之”重复出现,但是字数的要求达到了,整篇内容大约九百多字
通篇读下来,感觉中规中矩,顺序词用的太多了,且“此外”,“总之”重复出现,但是字数的要求达到了,整篇内容大约九百多字
总之,智谱AI作为国内估值最高的大模型公司,产品有自身的独特之处,研发了自主的大模型创新技术,单就这一点,就能够使其在众多的大模型公司中脱颖而出。实际的效果到底怎么样,还是需要大家自己体验才尚可得知。
版权归原作者 KuaFuAI 所有, 如有侵权,请联系我们删除。