
Statistics窗口获取基本信息
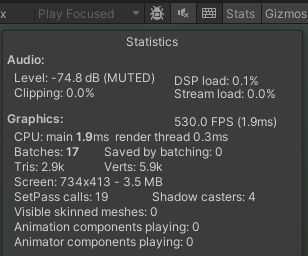
Level声音强度,单位是分贝(dB)DSP load数字信号处理器的负载。播放的声音越多、声音的采样率越高、声音效果越复杂,数值就越大Clipping音频的裁剪情况。当音频信号超过设备支持的最大范围时,该音频信号会被裁剪。应避免这项数据过大Stream load音频流的负载情况。流式加载就是边加载边播放,而不是一次性加载全部数据。应避免这项数据过大FPS帧率,也就是1秒内播放多少帧。530.0 FPS(1.9ms)表示平均每秒播放530张画面,平均每1.9毫秒播放一张画面CPUmain 表示Unity的主线程处理这一帧所花费的时间,render thread 渲染线程处理这一帧所花费的时间BatchesDraw Call就是CPU向GPU发送一组绘制指令,绘制一个或多个物体。将多个Draw Call合批成一个批次(Batch),Batches就是批次的总数Saved by batching有多少个Draw Call被合并到了批次。应尽量让这项数据大Tris摄像机视锥体内三角面的个数Verts摄像机视锥体内网格顶点的个数Screen当前的屏幕分辨率,以及屏幕的内存占用量SetPass calls切换Shader Pass的次数,一个Shader可以包含多个Pass,切换Pass会消耗一定的性能Shadow casters生成阴影的数量,一个游戏对象可能产生多个阴影Visible skinned meshes摄像机视锥体内有多少个可见的蒙皮网格Animator components playing当前场景中有多少个Animator组件正在播放动画Animation components playing当前场景中有多少个Animation组件正在播放动画
检测工具
Profiler
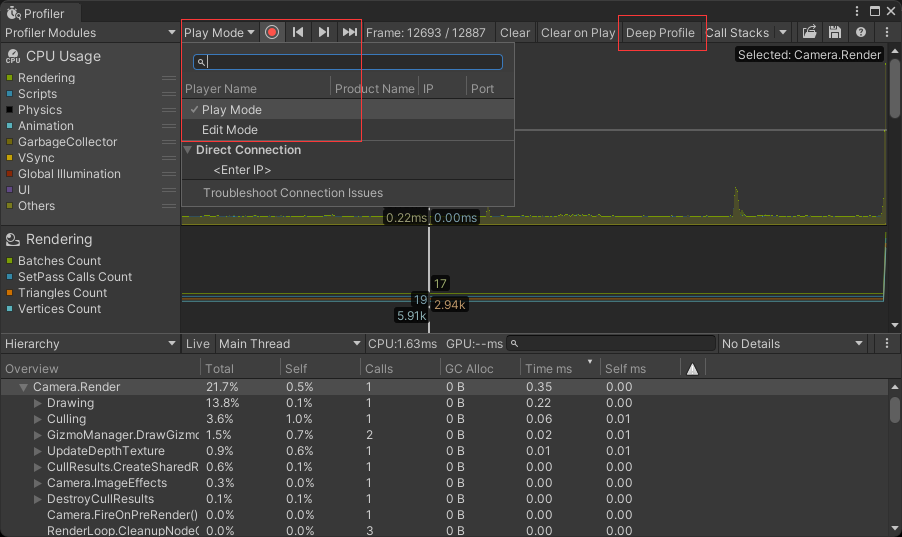
Edit Mode 是编辑器模式下检测,一般选择 Play Mode 检测运行时游戏性能
Deep Profile 开启后会检测所有C#方法,Unity会检测所有的mono调用,对脚本进行更详细的调查。对于大型项目开启后可能会很卡
不开 Deep Profile 的话,可以把 BeginSample,EndSample 放在测试代码的开头和结尾,然后在 Hierarchy 中查看这段代码性能
privatevoidUpdate(){
Profiler.BeginSample("自定义名称");//测试代码
Profiler.EndSample();}
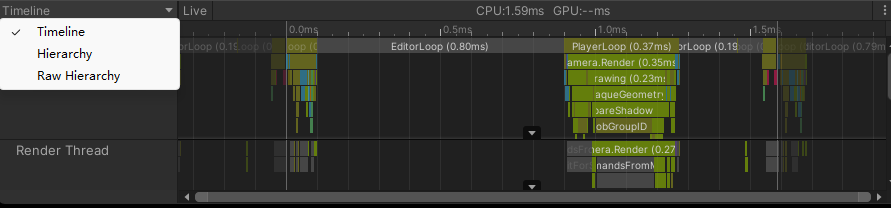
下方窗口选择Timeline,会以时间轴的方式显示CPU每帧调度
选择Hierarchy,可以查看CPU在这一帧中方法调用所消耗的性能和所花费的时间
选择Raw Hierarchy比起Hierarchy会单独列出更多信息,Hierarchy实际上是把这些信息合并了
Profiler(Standalone Process)
Profiler(Standalone Process) 的界面和功能和 Profiler 是一样的,区别是 Profiler 本身也会消耗性能,因此测试的不太准确,Profiler(Standalone Process) 会创建一个进程去运行,不会影响收集的数据,因此可以获得更加准确的数据,但是启动它的时间更长
Profile Analyzer
先通过 Package Manager 安装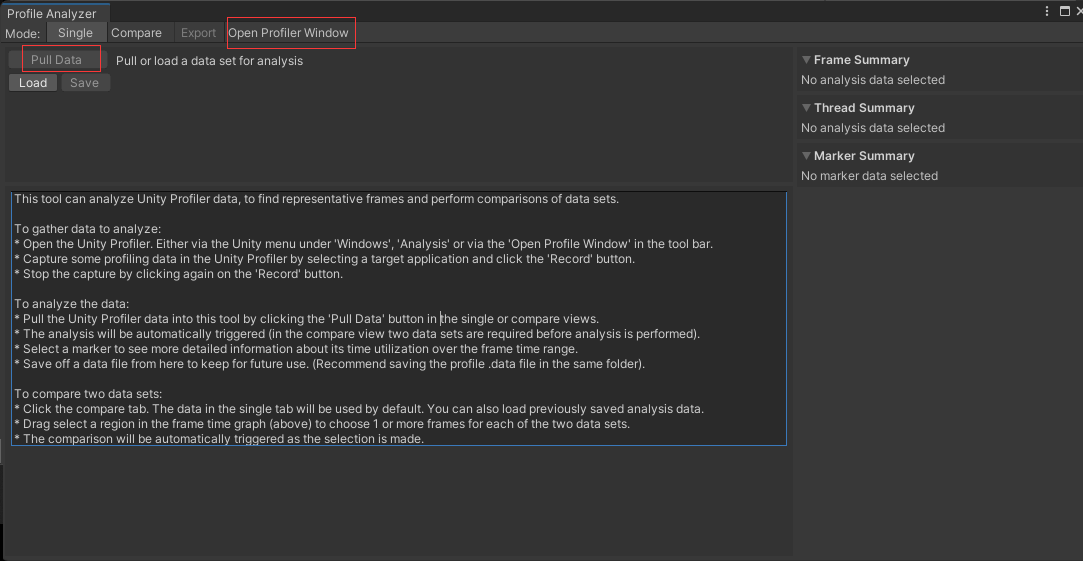
Profile Analyzer 是分析一段 Profile 记录的数据,点击 Open Profiler Window 可以打开 Profiler,记录一段数据后,点击 Pull Data 导入这段数据进行分析,图中间的文字说明工具的用法
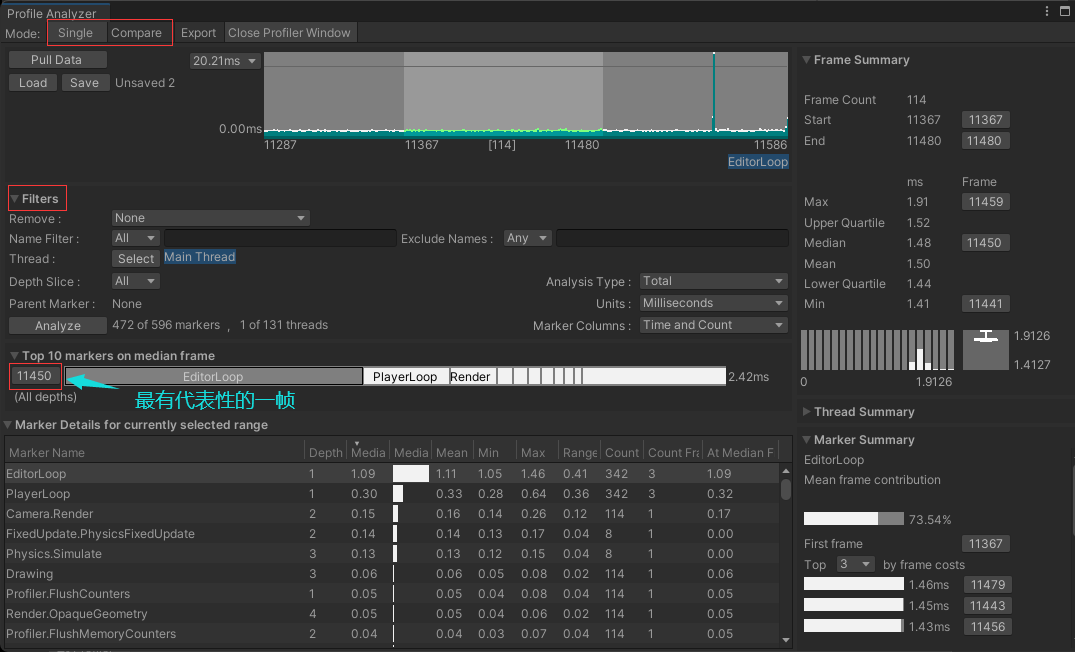
有两种模式,Single会分析一段数据,Compare会对比两段数据
上面的帧时间图中可以拖动选择一个区域
Filters 能设置一些过滤参数
Frame Debugger
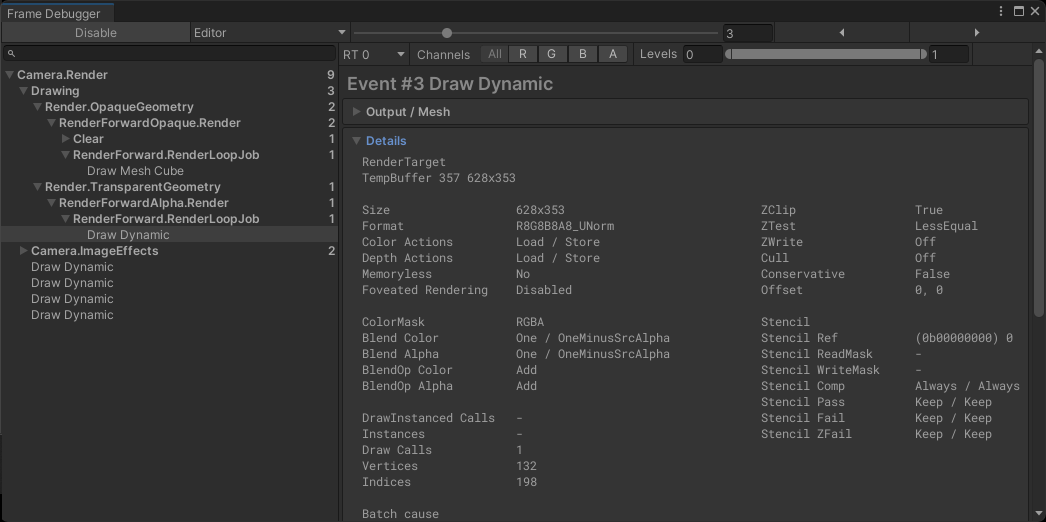
查看每一帧的画面是如何渲染出来的
Memory Profiler
先通过 Package Manager 安装
运行时点击 Capture New Snapshot 创建一个内存快照,点击 Open Preferences 可以修改内存快照存储的路径
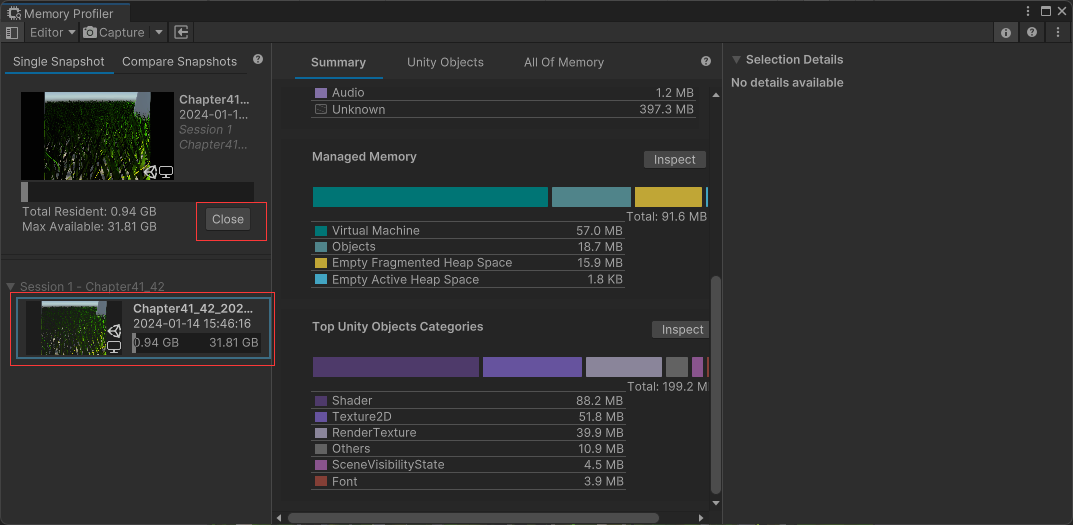
点击左下角快照显示内存详细信息,点击 Close 关闭显示
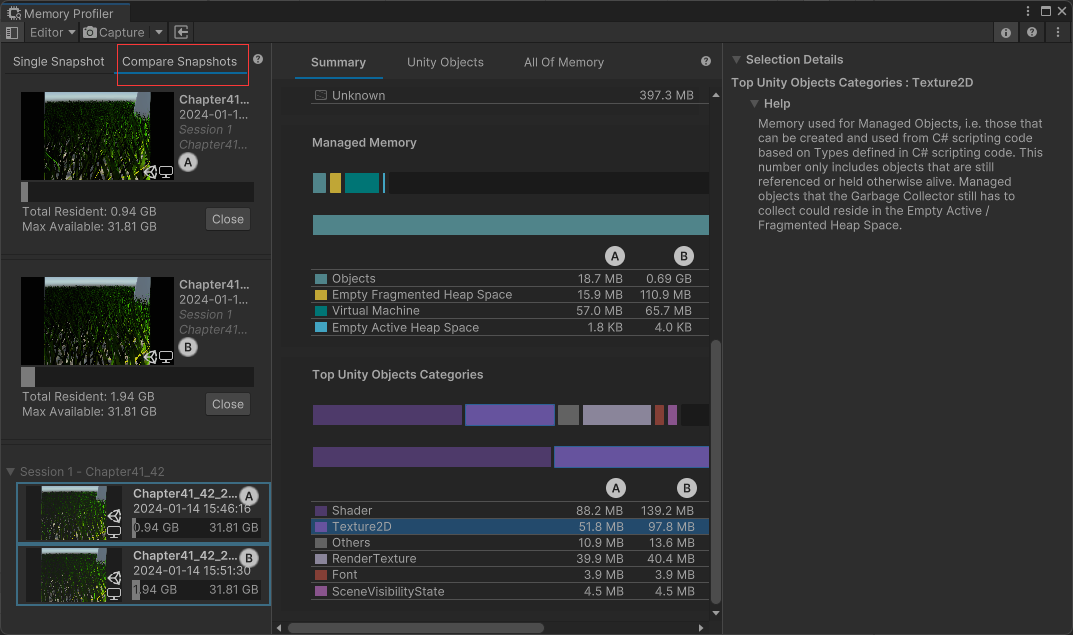
也可以创建两个内存快照,然后对比分析,编辑器模式下会显示一些 Editor 方法和编辑器自带图片的内存占用,因此是不准确的,最好打包出来查看
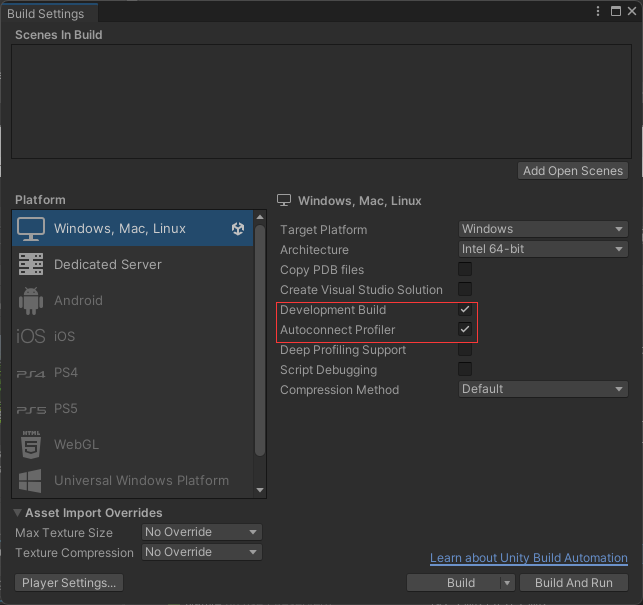
打包时需要勾选这两个选项
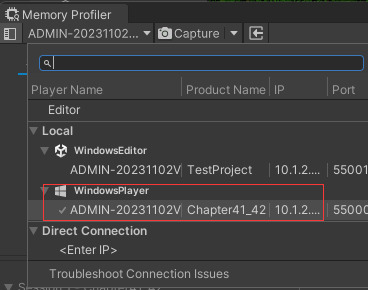
打包后启动程序,切换到 Memory Profiler,选择运行的程序,点击创建快照就可以看到更准确的数据了。手机的话得用数据线连到电脑上
Import Activity
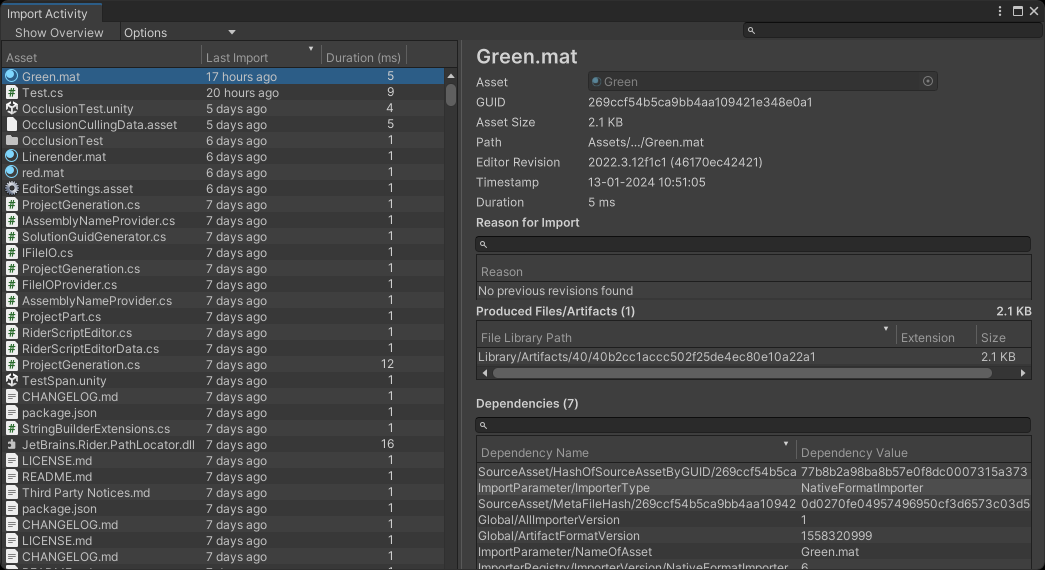
这是2021.2版本之后出现的新功能,可以查看资源的导入时间(Last Import)和导入耗时(Duration),点击某个资源可以查看它的详细信息和依赖项
图片,模型优化设置
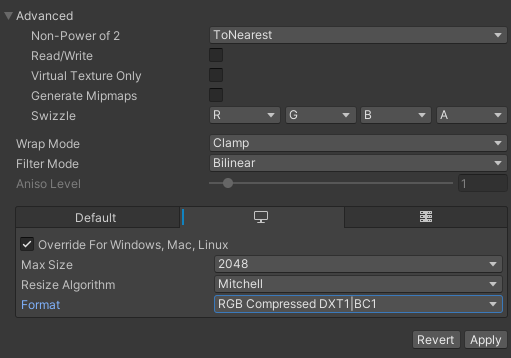
Non-Power of 2图片的长宽尽量是
2
n
2^n
2n ,选择 ToNearestRead/Write不需要运行时读写的取消勾选,勾选会导致双倍内存占用Generate MipmapsUI上的图不需要勾选Filter Mode效果 Point(no filter) < Bilinear < Trilinera,一般默认Bilinear就行,像素风游戏可以选择Point(no filter)Format参考官方文档,根据平台和质量要求进行选择
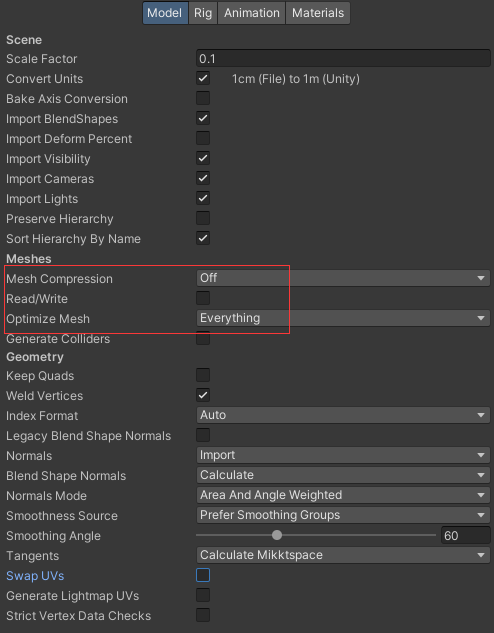
点击模型的fbx文件进行设置
Mesh Compression设置网格的压缩程度Read/Write一般不用勾选,除非要运行时修改网格Optimize Mesh一般选择Everything
其他的如法线,切线,BlendShapes 如果不需要,就不选Import
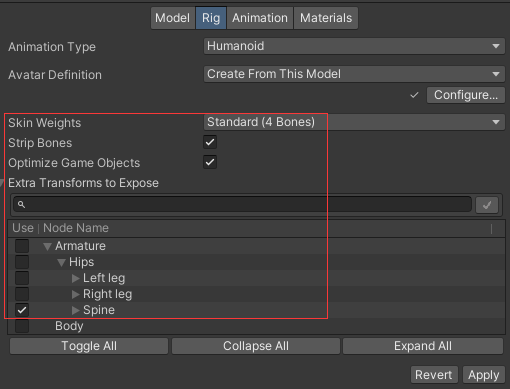
Rig页签设置模型使用哪种骨骼
Skin Weights设置每个顶点受几个骨骼影响,一般选默认的4个骨骼就行Strip Bones勾选会去除模型的骨骼信息,适用于静态物体Optimize Game Objects勾选后Unity会删除模型在hierarchy上的节点,可能影响动画,慎重勾选Extra Transforms to Expose仅当 Optimize Game Object 勾选时才会显示,设置那些节点不合并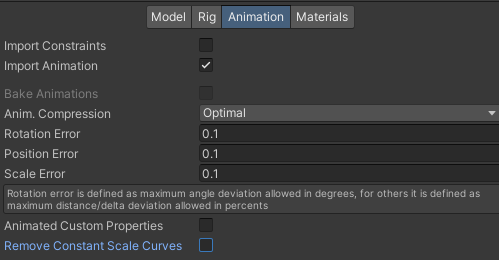
Animation页签设置动画相关的东西
Import Animation不需要动画的模型不勾选Anim Compression压缩算法,压缩程度 KeyframeReduction < OptimalRotation/Position/Scale Error自定义压缩阈值,误差小于这个值的会被压缩Animation Custom Properties导入用户自定义属性,一般对应DCC工具中的extraUserProperties字段中定义的数据Remove Constant Scale Curves勾选会移除动画中那些只包含常量缩放值的曲线,因为这些曲线在大多数情况下是多余的。动画将不再包含缩放值的关键帧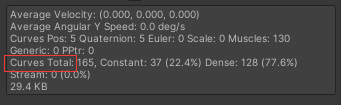
在动画片段上会有动画相关的曲线信息
Curves Pos位置曲线Quaternion四元数曲线Euler欧拉曲线Scale欧拉曲线Muscles肌肉曲线,Humanoid类型下会有Generic一般属性动画曲线,如颜色,材质等PPtr精灵动画曲线,一般2D系统下会有Curves Total曲线总数Constant优化为常数的曲线Dense使用了密集数据(线性插值后的离散值)存储Stream使用了流式数据(插值的时间和切线数据)存储
重点关注Curves Total,越少越好,且常数曲线占总曲线比重越高越好
LOD Group
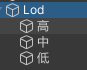
把不同精度的模型放在同一个根节点下面,每一级LOD可以有多个模型,在根节点上添加 LOD Group 组件
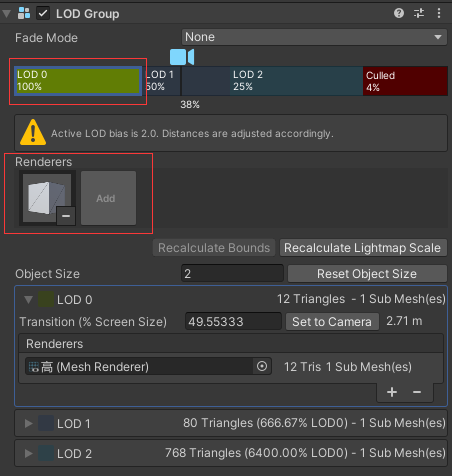
点击每一级 LOD 的方框,在 Renderer 添加对应的子物体,移动 LOD 方框上的相机查看 LOD 切换效果,Culled表示完全剔除
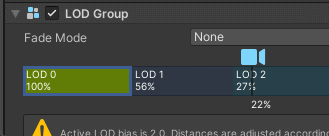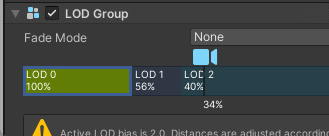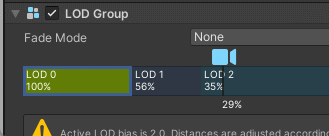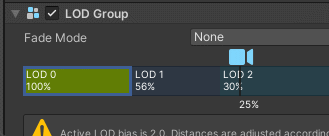
左右拖动可以调整每一级 LOD 的阈值,每个 LOD 级别方框中显示的百分比代表该级别激活的阈值,该阈值基于游戏对象的屏幕空间高度与屏幕总高度的比率。例如,如果 LOD 1 的阈值设置为 50%,那么当摄像机向后拉开到足够游戏对象的高度充满视图的一半时,LOD 1 就会激活

右键添加新的 LOD 级别,或者删除某一级别
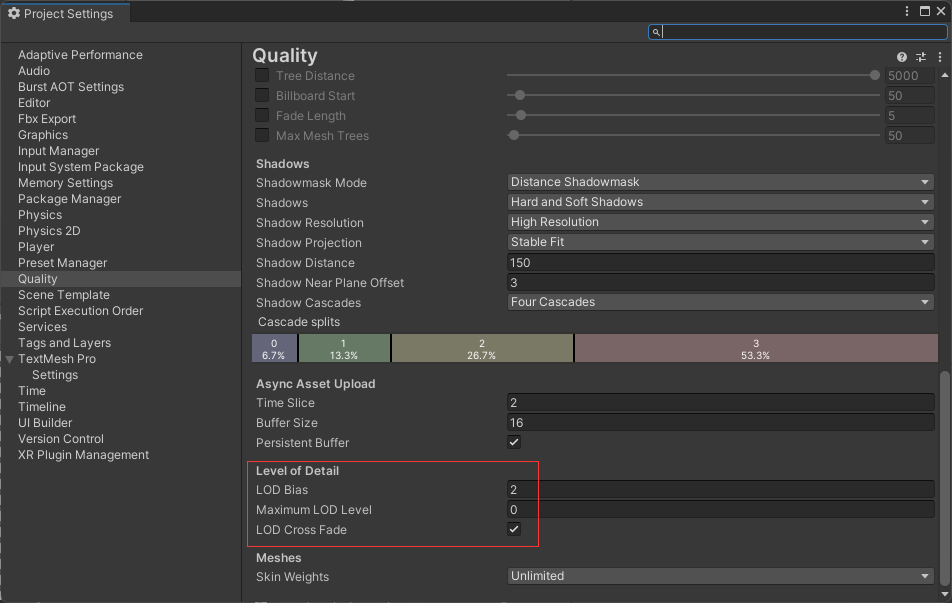
LOD Bias的值小,则摄像机离物体的距离稍微有些变化,则不同的LOD级别就会切换。如果LOD Bias的值大,则摄像机需要与物体有比较大的距离变化,不同的LOD级别才会切换
Maximum LOD Level 所有LOD Group组件最大能使用LOD级别,如果设置为1,则不会切换到 LOD 0,精细度 LOD 0 > LOD 1 > LOD 2
LODGroup的一些常用属性
voidStart(){LODGroup lodGroup =GetComponent<LODGroup>();//LODGroup组件的LOD级别的数量。Culled是不算在内的。默认情况下,有LOD 0、LOD 1、LOD 2,这个变量的值是3int lodCount = lodGroup.lodCount;//强制切换到某个级别
lodGroup.ForceLOD(0);//LOD是个结构体,存储这个级别lod的RendererLOD[] lods = lodGroup.GetLODs();//设置这个LOD级别渲染元素LOD[] newLods =newLOD[1];//屏幕相对高度,范围 [0-1]float screenRelativeTransitionHeight =0.5f;Renderer[] renderers =newRenderer[1];LOD lod =newLOD(screenRelativeTransitionHeight, renderers);
newLods[0]= lod;
lodGroup.SetLODs(newLods);}
合并静态网格
Unity 资源商店有些插件可以帮我们合并网格,减少Draw Call,一般是调用 MeshFilter.mesh.CombineMeshes 方法
注意合并的网格需要使用相同的材质
动画优化
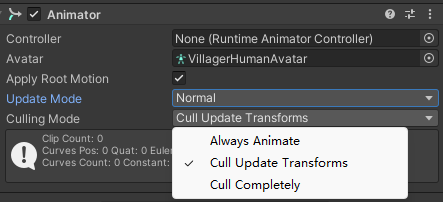
Culling Mode描述Always Animate不剔除,始终运行动画Cull Update Transforms不可见时不会渲染该动画,但是依然会根据该动画的播放来改变游戏对象的位置、旋转、缩放Cull Completely不可见时停止模拟,再次出现时,从停止的状态继续模拟
Culling Mode 一般使用 Cull Update Transforms
一些简单的动画使用 Animation 或 DoTween 实现,尽量不要使用 Animator,因为只要 Animator 存在,就会消耗性能来检测当前的状态和过渡条件
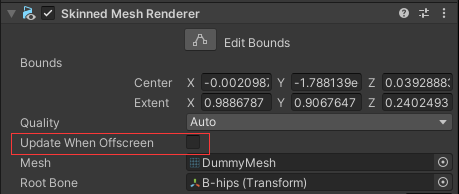
Update When Offscreen 勾选后会在屏幕外也更新,尽量不要勾选
代码中使用动画名称的 hash 值可以提高性能
privateAnimator _animator;privateint _jumpHash = Animator.StringToHash("Jump");voidStart(){
_animator =GetComponent<Animator>();// _animator.SetBool("Jump", true);
_animator.SetBool(_jumpHash,true);}
音频优化
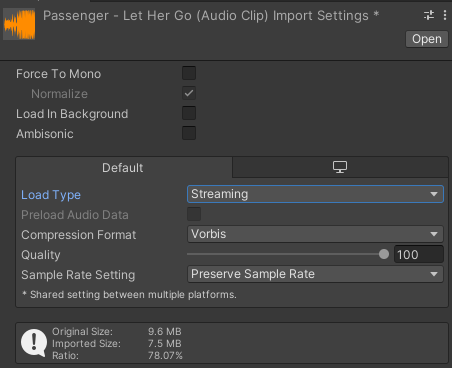
Force To Mono勾选会把这个音频文件设置为单声道,节省内存Load In Background加载将在单独的线程上进行,而不会阻塞主线程Ambisonic环绕声,适用于360度视频和XR应用Load TypeDecompress On Load 音频文件加载后立即解压缩,适用于小的音频文件(小于200kb)Compressed In Memory 在内存中保留压缩音频,并在播放时解压缩,适用于中等大小的文件Streaming 流式加载,适用于比较大的文件(如背景音乐)Preload Audio Data勾选后,将在加载场景后预加载音频片段Compression FormatPCM不压缩,其他的会压缩,长时间的音频文件可以使用Vorbis,短时间的音频文件可以使用ADPCMSample Rate SettingPreserve Sample Rate 保持采样率不变Optimize Sample Rate 分析的最高频率内容自动优化采样率Override Sample Rate 手动设置采样率
Drawcall优化
- 静态合批
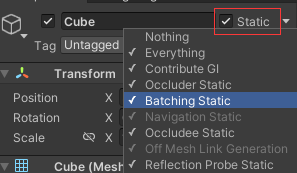 物体勾选Static或只选择Batching Static就会静态合批,对于始终静止不动的物体使用静态合批后,CPU会把它们合并为一个批次发送给GPU处理,这样可以减少Draw Call带来的性能消耗
物体勾选Static或只选择Batching Static就会静态合批,对于始终静止不动的物体使用静态合批后,CPU会把它们合并为一个批次发送给GPU处理,这样可以减少Draw Call带来的性能消耗 - 动态合批
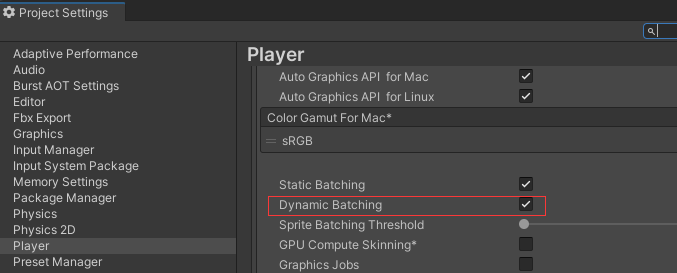 设置中勾选即可开启,开启后Unity会自动对使用相同材质的物体进行合批 限制:相同材质,网格顶点属性不能超过900
设置中勾选即可开启,开启后Unity会自动对使用相同材质的物体进行合批 限制:相同材质,网格顶点属性不能超过900 - GPU Instanceing
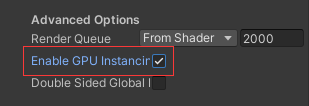 材质上勾选Enable GPU Instancing,本质是提交一个物体(模型,材质),GPU绘制出来这个物体的N个实例到不同的位置(位置,旋转,缩放) 限制:相同的网格和材质,材质支持GPU Instancing
材质上勾选Enable GPU Instancing,本质是提交一个物体(模型,材质),GPU绘制出来这个物体的N个实例到不同的位置(位置,旋转,缩放) 限制:相同的网格和材质,材质支持GPU Instancing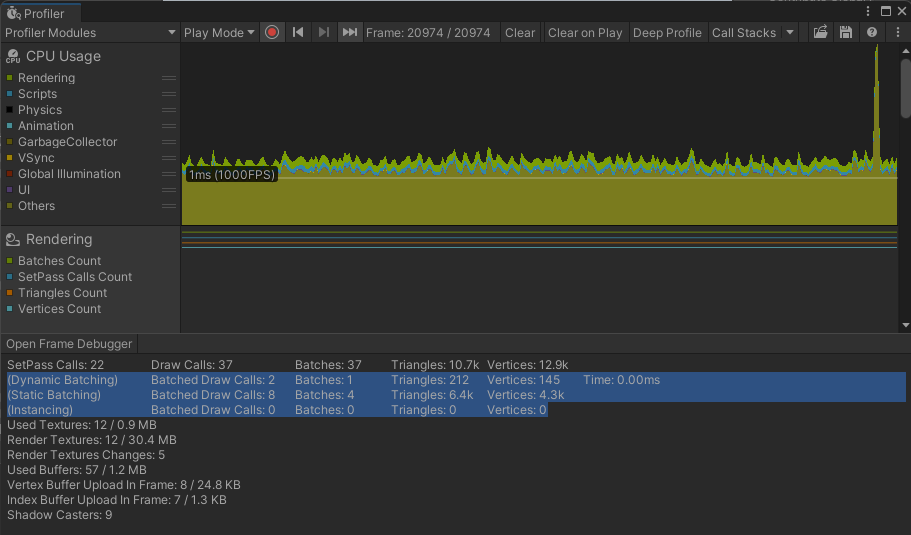 Profiler中可以看到动态合批,静态合批,GPU Instancing相关的信息
Profiler中可以看到动态合批,静态合批,GPU Instancing相关的信息 - 合理的安排物体的绘制顺序,减少重叠,不要打断合批
- 多个物体尽量使用相同的材质,Shader
GC优化
在Unity中,使用的是一种叫Boehm-Demers-Weiser的GC器,它会在需要进行GC时占用主线程,进行遍历-标记-垃圾回收的过程,然后在归还主线程控制权。它有以下特点:
- Stop The World:即当发生GC时,程序的所有线程都必须停止工作,等GC完成才能继续,Unity不支持多线程GC,即使是Unity 2019后使用的增量式GC,在回收时也是要停掉所有线程
- 不分代:.NET和Java会把托管堆分成多个代(Generation),新生代的内存空间非常小,而且一般来说,GC主要会集中在新生代上,这让每一次GC的速度也非常快,但是Unity的GC是完全不分代的,即只要发生GC,就会对整个托管堆进行GC(Full GC)
- 不压缩:不会对堆内存进行碎片整理,如下图:

.NET CLR采用的Mark Sweep算法。
阶段1: Mark-Sweep 标记清除阶段,先假设heap中所有对象都可以回收,然后找出不能回收的对象,给这些对象打上标记,最后heap中没有打标记的对象都是可以被回收的。
阶段2: Compact 压缩阶段,对象回收之后heap内存空间变得不连续,在heap中移动这些对象,使他们重新从heap基地址开始连续排列,类似于磁盘空间的碎片整理。
.NET将heap分成3个代龄区域: Gen 0、Gen 1、Gen 2。存在时间最短的分在第0代,最长的分在第2代。
GC触发3个条件:(1)堆内存分配而当内存不足时,(2)按频率自动触发,(3)手动强行触发(一般用在场景切换)
优化方法1:GC会遍历内存中的对象,因此减少对象数量可以加快GC。
//优化前classItem{publicint a;publicshort b;}Item[] items;//对于items数组,每一个元素都会产生一个对象。//优化后classItem{publicint[] a;publicshort[] b;}Item item;//不管a和b有多少个元素,数组都只有一个对象,这样就会减少对象数量。
方法2:方法参数使用泛型来避免装箱,但是这样在IL2CPP中会有个问题,因为IL2CPP是AOT机制的, 所有泛型调用最后 会为每种类型单独生成代码,增加代码体积,同时也会增加堆内存。
方法3:优化可变参数,使用params的可变参数是一种语法糖,它和传入一个数组是等价的。
//定义方法voidFunc(paramsint[] n);//调用方法,只要可变参数不为空,就一定会产生临时的数组,大量调用会产生很多的GC Alloc。Func(1,2,3) 等价于 Func(newint[]{1,2,3})//优化方法是用一系列若干数量的参数的重载方法代替,把常用的1个、2个、3个参数的方法单独提出来,
剩下的再用可变参数来做。
方法4:使用对象池。
方法5:缓存对象。如在协程里频繁调用WaitForEndOfFrame,可以建一个静态变量缓存起来,
如public static WaitForEndOfFrame WaitForEndOfFrame = new WaitForEndOfFrame();
方法6:尽量避免使用匿名函数。不使用外部变量的匿名函数,编译器会把这个函数变成静态函数,在首次调用时初始化,之后就再也不会new新的对象。 当使用外部变量时(闭包),C#为了实现这一点会生成一个匿名类来保存用到的外部变量,因此当调用这个闭包时,会根据这个匿名类去实例化一个临时对象,同时会采用外部变量实际值来初始化这个对象,最终致使会在堆上分配内存。也就是说闭包就一定会产生内存分配。如果需要使用,可以缓存下再用。
Unity API使用注意:
- GameObject.name 或者 GameObject.tag两个函数都会将结果存为新的字符串返回,会有堆内存分配,使用GameObject.CompareTag代替。
- 所有返回是数组的API都会有GC Alloc不过,大部分API也都会提供个可以传入List参数的方法,每次调用都会生成个新的数组对象,可以配合ListPool对其进行优化:
List<Text> texts = ListPool<Text>.Get();GetComponentsInChildren(texts);//...
ListPool<Text>.Release(texts);//再比如,这种很容易被当成字段来使用,但其实每次调用也会生成新的Material数组var materials = renderer.sharedMaterials;//可以改成下面的代码:List<Material> materials = ListPool<Material>.Get();
renderer.GetSharedMaterials(materials);//...
ListPool<Material>.Release(materials);//还有导航网格,即使缓存了NavMeshPath, navMeshPath.corners也是每次生成一个数组,//使用GetCornersNonAlloc并传入一个足够大小的数组会解决这个问题。如:
pub1ic staticVector3[] cachedPath{get;}=newVector3[256];
pub1ic staticint pathCount {get;privateset;}privatestaticNavMeshPath navMeshPath;publicstaticvoid CalculatePath (Vector3 startPos,Vector3 endPos){
navMeshPath.ClearCorners();
NavMesh.CalculatePath(startPos, endPos, NavMesh.AllAreas, navMeshPath);
pathCount = navMeshPath.GetCornersNonAlloc(cachedPath);//...}
UGUI优化细节
- 动静分离。缩放,位移,旋转,文字的修改,图片的变化都会触发重绘。元素的改变可分为布局变化、顶点变化、材质变化,所以分别提供了三个方法SetLayoutDirty(); SetVerticesDirty(); SetMaterialDirty(); 供选择。
- 尽量使用RectMask2D代替Mask进行裁剪。 Mask会多出两个DrawCall,因为Mask的原理是GPU的Shader实现,第一个Mask是一个在底层模板绘制一个区域的指令,根据Image传进来的图片的Alpha值,确定裁剪区域,之后Mask节点下的元素会根据这个区域计算Alpha的值,最后个Mask是绘制区域结束的指令,用于结束计算裁剪的操作。 RectMask2D不需要Image的图片作为裁剪区域,所以它的裁剪区域永远是矩形大小,进而CPU计算元素是否在矩形区域之内,如果在区域之内,则节点下常规方式合批之后进行顶点裁剪,而如果一个元素完全不在矩形区域,则这个元素不会被渲染。因此当我们将一个元素完全脱离矩形之外,这个节点的DrawCall则变为0,而Mask却没有这个现象。 所以Mask与RectMask2D的本质区别是CPU的实现还是GPU的实现。
- 不需要进行事件接收的组件,取消勾选Raycast Target。
- 尽量使用TextMeshPro代替UIText。
- UI组件的显隐,如果需要控制UI物体的显隐,如果使用gameObject.SetActive,会造成不小的消耗,那么如果使用Color来调整,会引起它的重建,可以考虑通过材质球的_Color属性进行调整,是不会引起重建的,如果只是控制单个物体的显隐,推荐勾选CanvasRenderer的CullTransparentMesh,当图片的Alpha为0会忽略物体的顶点,如果需要控制一组物体的显隐,推荐使用CanvasGroup的Alpha属性。
- 游戏中的Tab页尽量做成单独的界面,切换后动态加载。
- 粒子特效不要直接放在界面上,需要时候再动态加载。
- 加载元素过多时可以考虑分帧加载。
- 全屏界面关闭后面的渲染。
- 对复杂的UI进行预加载
- Canvas下的某个UI元素使用 SetActive(true) 激活时,会导致这个Canvas下的其他UI元素和这个Canvas的父Canvas下的其他UI元素触发SyncTransform,当CanvasRenderer.SyncTransform触发次数非常频繁时,会导致它的父节点 Rendering.UpdateBatches产生非常高的耗时,使用 Scale = 0,Scale = 1来代替激活,隐藏,或者把UI元素移除屏幕外
加载优化
- 分帧加载,异步加载
- 限制每帧加载数量
- 预加载
- 对象池
协程优化
publicstaticclassYieldHelper{//静态对象便于重用publicstaticWaitForEndOfFrame WaitForEndOfFrame =newWaitForEndOfFrame();publicstaticIEnumeratorWaitForSeconds(float totalTime,bool ignoreTimeScale =false){float time =0;while(time < totalTime){
time += ignoreTimeScale ? Time.unscaledDeltaTime : Time.deltaTime;yieldreturnnull;}}/// <summary>/// 等待frameNum帧后运行/// </summary>publicstaticIEnumeratorWaitForFrame(int frameNum){int count =0;while(count < frameNum){yieldreturnnull;++frameNum;}}}
内存优化
- 避免装箱,减少可变参数的使用
- 使用对象池,缓存对象,UnityAPI里所有返回数组都会产生GC
- 尽量避免使用匿名函数
- List,Dictionary初始化容量
- 注意结构体/类的内存对齐规则
- 和美术定义一套资源规范,使用AssetPostprocessor对资源进行检查,比如纹理格式,安卓一般用ETC,IOS一般用ASTC。图片一般都需要关闭Read & Write,UI关闭mipmap。
- 频繁的字符串拼接,使用StringBuilder优化,StringBuilder底层也是数组实现的,注意扩容问题。
- 资源按需加载,比如配置表用到了在加载
- 对称的图片,切图的时候只切一半,另一半程序生成,减少资源量。
- 避免实用linq,会有gc
- 一些长字符串如果使用的次数少就直接写在方法里,不要定义成const,会一直占用内存
Overdraw优化(GPU)
- 减少不透明物体的使用
- 全屏界面关闭后面的渲染
- 3D物体遮挡剔除,不渲染被挡住的物体
遮挡剔除步骤:
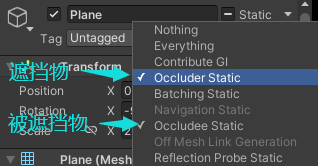
(1)场景中的遮挡物和被遮挡物需要是静态的,有Terrain或Mesh Renderer组件,不透明。选择上面两个选项,一个物体即可以是遮挡物,也可以是被遮挡物,且两者使用的材质需要支持遮挡剔除,默认的Standard shader支持
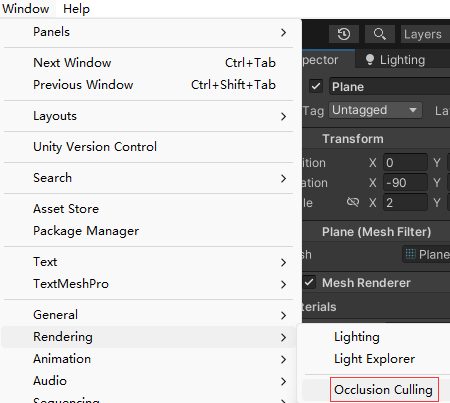
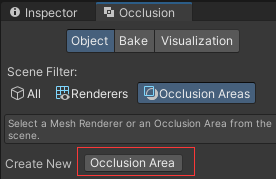
(2)打开遮挡剔除窗口,创建一个遮挡剔除区域(Occlusion Area)
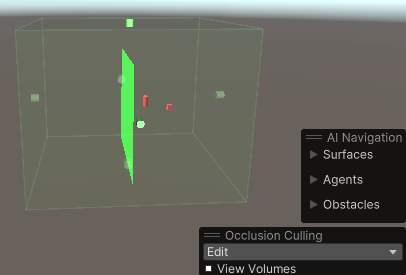
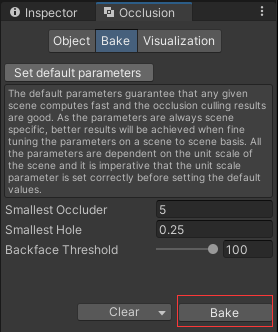
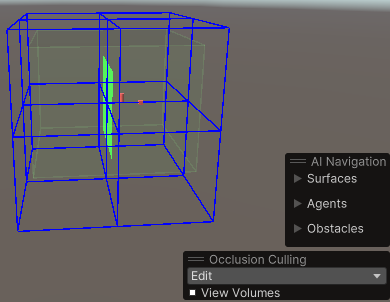
(3)调整遮挡剔除区域,它类似一个矩形碰撞体,最后点击Bake,生成一个蓝色区域,当摄像机在这个蓝色区域内,遮挡剔除才有效。重新Bake时最好先点一下Clear
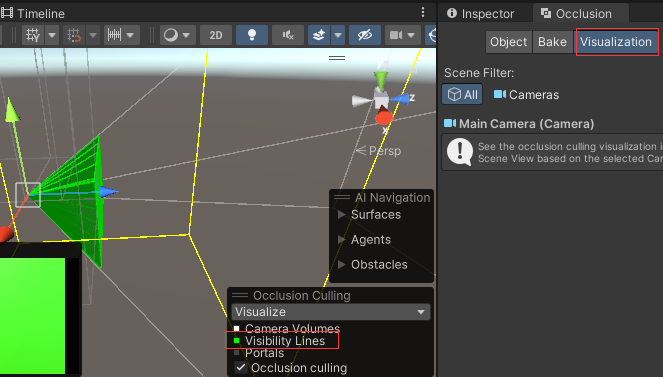
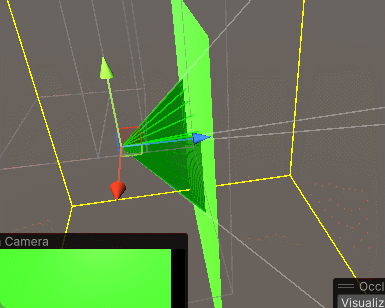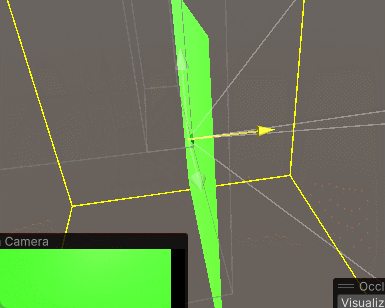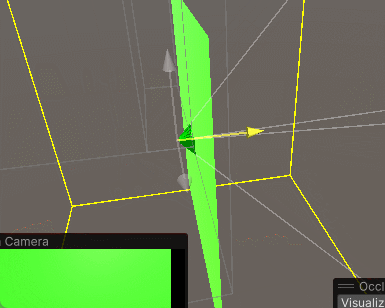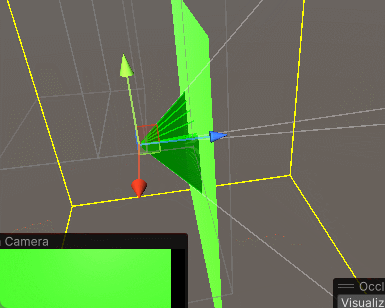
(4)切换到Visualization,勾选Visibility Lines,即可看到摄像机的视锥体范围,调整相机位置就能看到遮挡剔除的效果
运行时开启或关闭遮挡剔除
与上面的步骤基本一致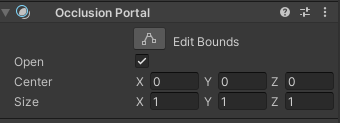
遮挡物需要添加Occlusion Portal组件,Open勾选表示不启用遮挡剔除,不勾选启用遮挡剔除(有点反直觉😓),Size调整范围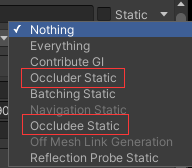
并且遮挡物不能选择Occluder Static和Occludee Static,被遮挡物还是要勾选的
修改后重新Bake,运行时通过代码修改Open属性就能开启或关闭遮挡剔除
Log添加宏定义
使用条件编译特性
namespaceLog{publicstaticclassMyLogger{//条件编译特性[Conditional("ENABLE_DEBUG_LOG")]publicstaticvoidLog(string content){
Debug.Log(content);}}publicclassConditionLog:MonoBehaviour{privatevoidStart(){//没有"ENABLE_DEBUG_LOG"这个编译符号,所有的MyLogger.Log都不会编译到最终最终的程序集中
MyLogger.Log("条件log");}}}
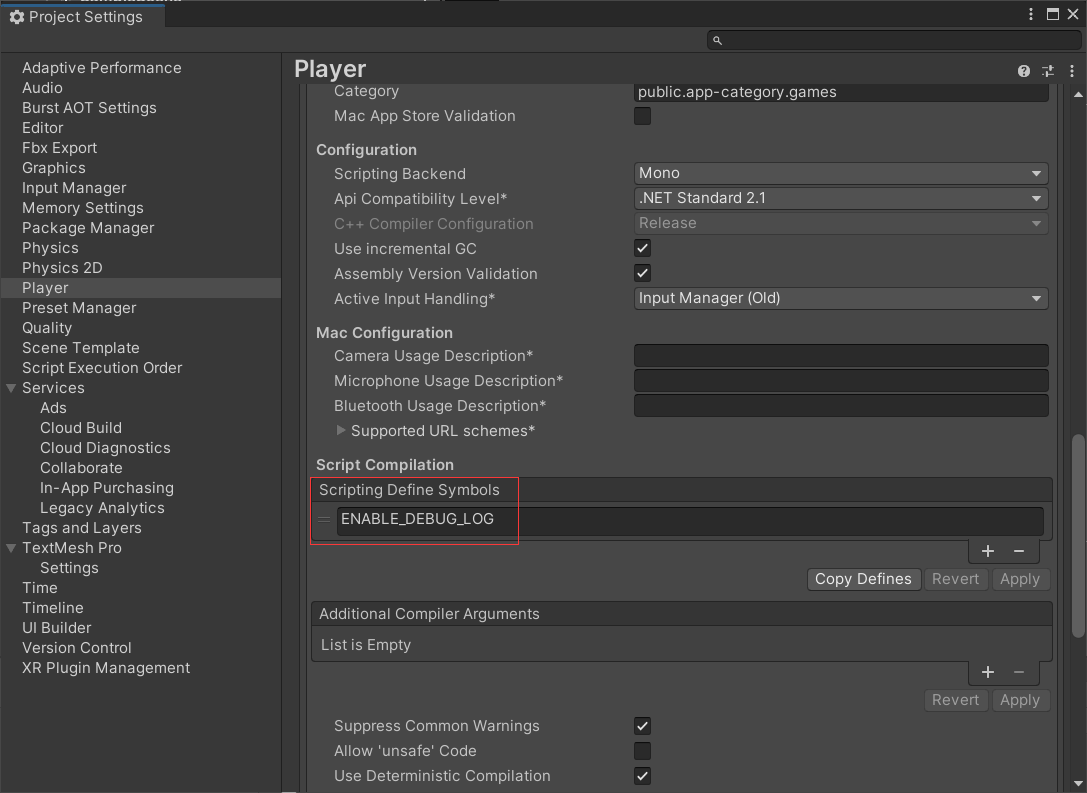
调试的时候加上这个预定义,发布的时候去掉这个预定义。
publicclassLogOutput:MonoBehaviour{[SerializeField]privateText _outputText;privatestring _newMsg;privateStringBuilder _builder =newStringBuilder();//使用线程安全队列来保存日志字符串privateConcurrentQueue<string> _concurrentQueue =newConcurrentQueue<string>();privatevoidOnEnable(){//主线程中调用,线程不安全,可以调用Unity的api//Application.logMessageReceived += OnLogMessageReceived;//其他线程中调用,线程安全,不能调用Unity的api,可以在多线程中调用,使用文件保存日志
Application.logMessageReceivedThreaded += OnLogMessageReceived;}privatevoidOnDisable(){//Application.logMessageReceived -= OnLogMessageReceived;
Application.logMessageReceivedThreaded -= OnLogMessageReceived;}/// <summary>/// 监听Debug.Log日志/// </summary>/// <param name="condition">日志内容</param>/// <param name="stacktrace">堆栈信息</param>/// <param name="type">日志类型</param>privatevoidOnLogMessageReceived(string condition,string stacktrace,LogType type){
_newMsg = condition;
_concurrentQueue.Enqueue(_newMsg);}privatevoidAddToOutputShow(){//跨平台换行符 System.Environment.NewLine
_builder.Append($"{Environment.NewLine}");
_builder.Append($"{_newMsg}");
_outputText.text = _builder.ToString();}privatevoidUpdate(){string result;while(_concurrentQueue.TryDequeue(out result)){
_builder.Append($"{Environment.NewLine}");
_builder.Append($"{result}");if(_concurrentQueue.Count ==0){
_outputText.text = _builder.ToString();}}}}
参考
siki 《Unity性能优化》
版权归原作者 北海6516 所有, 如有侵权,请联系我们删除。