
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 三、流水线优化
- 总结
前言
首先,我们先对Spark的内核调度做个理解。
Spark的核心是根据RDD来实现的,Spark Scheduler则为Spark核心实现的重要一环,其作用就是任务调度。Spark的任务调度就是如何组织任务去处理RDD中每个分区的数据,根据RDD的依赖关系构建DAG,基于DAG划分Stage,将每个Stage中的任务发到指定节点运行。基于Spark的任务调度原理,可以合理规划资源利用,做到尽可能用最少的资源高效地完成任务计算。
一、RDD依赖
为什么要设计宽窄依赖?
1.对于窄依赖
Spark可以并行计算。例如 map,filter等操作。
如果有一个分区数据丢失,只需要从父RDD的对应1个分区重新计算即可,不需要重新计算整个任务,提高容错。
2.对于宽依赖
是划分Stage的依据,产生Shuffle。例如GroupByKey,reduceByKey,join,sortByKey等操作。
3.构建Lineage血缘关系
RDD只支持粗粒度转换,即只记录单个块上执行的单个操作。将创建RDD的一系列Lineage(即血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
二、宽窄依赖
1.窄依赖
窄依赖中:即父 RDD 与子 RDD 间的分区是一对一的。换句话说父RDD中,一个 分区内的数据是不能被分割的,只能由子RDD中的一个分区整个利用。同时包含一对固定个数的窄依赖,也就是说对父RDD的依赖的Partition的数量不会随着RDD数据规模的改变而改变。
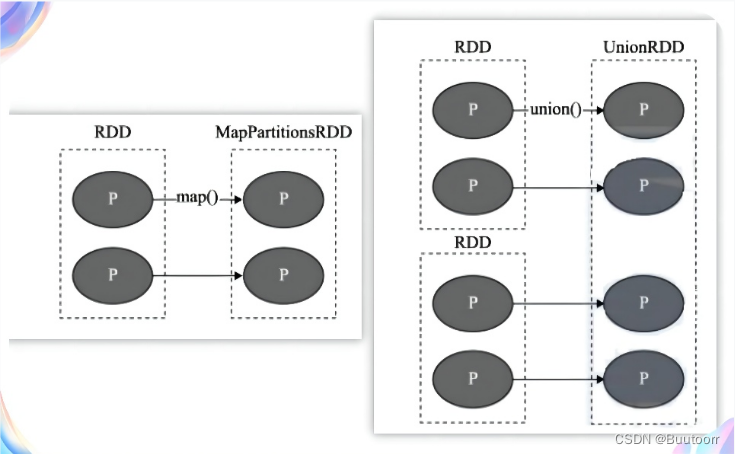
上图中 P代表 RDD中的每个分区(Partition),我们看到,RDD 中每个分区内的数据在上面的几种转移操作之后被一个分区所使用,即其依赖的父分区只有一个。比如图中的 map、union,都是窄依赖的。(注意,join 操作大多是宽依赖,某特殊情况可能是窄依赖,当join操作的每个partition 仅仅和已知的Partition进行join,此时的join操作就是窄依赖,因为此依赖关系是对确认的partition数量)
2.宽依赖
宽依赖也可称 Shuffle依赖
宽依赖也会打乱原 RDD 结构的操作。具体来说,父 RDD 中的分区可能会被多个子 RDD 分区使用。因为父 RDD 中一个分区内的数据会被分割并发送给子 RDD 的所有分区,因此 Shuffle 依赖也意味着父 RDD与子 RDD 之间存在着 Shuffle 过程。
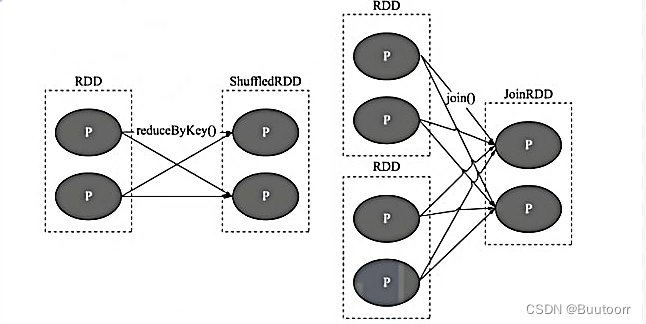
上图中 P 代表 RDD 中的多个分区,我们会发现对于 Shuffle 类操作而言,父 RDD 中的每个分区可能会分发到子 RDD的多个分区中。需要说明的是,依赖关系是 RDD 到 RDD 之间的一种映射关系,是两个 RDD 之间的依赖,如果在一次操作中涉及多个父 RDD,也有可能同时包含窄依赖和 Shuffle 依赖。
三、流水线优化
在Spark中,shuffle 是 Spark 用于重新分配数据的机制,以便跨分区以不同方式分组。这通常涉及跨执行器和机器复制数据,使洗牌成为一项复杂且成本高昂的操作。
窄依赖对优化很有利。Spark把这个叫做流水线(pipeline)优化。流水线优化,它在RDD级别或其以下级别执行。通过流水线技术,在不需要任何跨节点的数据移动的情况下,可以将一系列操作合并为一个单独的任务阶段。实际上,spark流水线优化对你是透明的。Spark引擎会自动完成。你可以通过SparkUI或其日志文件检查你的应用程序。
优化是通过fork/join机制。多个分区通过fork并行执行转化操作,再通过join操作。去掉在join过程,管道化处理,形成流水线操作,数据不再需要保存在磁盘或者其他存储器中,可以直接进行使用。
宽依赖中,shuffle操作发生(数据的写磁盘和等待操作),产生数据来回转换并发生等待,则无法进行流水线化操作。
总结
区分RDD之间的依赖为宽依赖还是窄依赖,主要在于父RDD分区数据和子RDD分区数据关系:
窄依赖:父RDD的一个分区只会被子RDD的一个分区依赖。
宽依赖:父RDD的一个分区会被子RDD的多个分区依赖,涉及Shuffle。
在spark中pipeline是一个partition对应一个partition,所以在stage内部只有窄依赖。stage与stage之间是宽依赖。
本文转载自: https://blog.csdn.net/Buutoorr/article/details/126947392
版权归原作者 Buutoorr 所有, 如有侵权,请联系我们删除。
版权归原作者 Buutoorr 所有, 如有侵权,请联系我们删除。