
前言
在上一篇博客文本匹配中的示例代码中使用到了一个SimCSE模型,用来提取短文本的特征,然后计算特征相似度,最终达到文本匹配的目的。但是该示例代码中的短文本是用的英文短句,其实SimCSE模型也可以用于中文短文本的特征提取,本篇博客就基于苏沐剑发表于科学空间的中文任务还是SOTA吗?我们给SimCSE补充了一些实验博客中使用到的代码,来记录一下代码梳理的笔记,并且使用自己的数据集在这篇代码上进行训练。另外,关于这个模型的原理细节等,可以参考别的博主写的内容,还有就是作者的论文,这些会附在最后的参考链接。
代码详解
数据导入部分
数据导入部分的代码主要有三个步骤,(1)从txt中读取文本数据,常规操作,这里没什么可说的;
datasets ={'%s-%s'%(task_name, f):
load_data('%s%s/%s.%s.data'%(data_path, task_name, task_name, f))for f in['train','valid','test']}
(2)将读取到的文本句子转换成id向量,同样也是常规操作;
defconvert_to_ids(data, tokenizer, maxlen=64):"""转换文本数据为id形式
"""
a_token_ids, b_token_ids, labels =[],[],[]for d in tqdm(data):
token_ids = tokenizer.encode(d[0], maxlen=maxlen)[0]
a_token_ids.append(token_ids)
token_ids = tokenizer.encode(d[1], maxlen=maxlen)[0]
b_token_ids.append(token_ids)
labels.append(d[2])
a_token_ids = sequence_padding(a_token_ids)
b_token_ids = sequence_padding(b_token_ids)return a_token_ids, b_token_ids, labels
(3)第三步则是写了一个class,使用了一个生成器,完成数据batch读取。这里需要注意的是,每个batch中,同一个文本数据,输入了两次,一个batch中的两个一样的文本输入,由于模型最后一层的加入了dropout,模型输出结果是有些许差别的,这样有差别的输出,则可以互为label,这也是SimCSE模型巧妙的地方。
classdata_generator(DataGenerator):"""训练语料生成器
"""def__iter__(self, random=False):
batch_token_ids =[]for is_end, token_ids in self.sample(random):
batch_token_ids.append(token_ids)##同一条文本输入两次
batch_token_ids.append(token_ids)##同一条文本输入两次iflen(batch_token_ids)== self.batch_size *2or is_end:
batch_token_ids = sequence_padding(batch_token_ids)
batch_segment_ids = np.zeros_like(batch_token_ids)
batch_labels = np.zeros_like(batch_token_ids[:,:1])yield[batch_token_ids, batch_segment_ids], batch_labels
batch_token_ids =[]
模型定义部分
这个模型的定义其实很简单,就是用bert作为特征提取的基础模型,然后再bert模型输出的基础上加上一个dropout操作,就是代码中的pooling层,核心代码就是下面几行
bert = build_transformer_model(
config_path,
checkpoint_path,
model=model,
with_pool='linear',
dropout_rate=dropout_rate
)
outputs, count =[],0whileTrue:try:
output = bert.get_layer('Transformer-%d-FeedForward-Norm'% count
).output
outputs.append(output)
count +=1except:break
output = bert.output
# 最后的编码器
encoder = Model(bert.inputs, output)
模型的损失函数
模型的损失函数是所有代码中最难理解的部分,虽然代码只有十几行,但是最需要花费时间去理解的。
在阐述这个SimCSE模型的损失函数代码之前,首先要搞清楚,这个模型是要解决什么问题,其目的主要是为了提取短文本的特征,使得相似的句子,提取出来的特征距离更近,不同语义的句子,特征距离越远,这样使得提取出来的文本特征更具有辨识度,和人脸识别原理很类似,这就是对比学习模型系列想要达到的目的。
在了解了对比学习的大致原理之后,再来看代码,下面是解释
idxs = K.arange(0, K.shape(y_pred)[0])
这行代码就是模型输出的一个维度(模型输入的batchsize),构建一个索引,比如,模型输入batchsize为6,那idxs则就是[0,1,2,3,4,5]
idxs_1 = idxs[None,:]
这就是给idxs增加一个维度,使其变成[[0,1,2,3,4,5]]
idxs_2 =(idxs +1- idxs %2*2)[:,None]
这行代码比较关键,目的是让idxs向量中数值是奇数的赋值为它的前一个数,数值为偶数的则赋值为它后一个索引值,这个一前一后的赋值,就是它相似度最大的索引值(排除自己)。这里需要解释一下的是,这里每个索引值背后代表的是SimCSE模型输出的一个个的提取到的文本特征向量,维度是1*768,和bert模型输出应该是一样的维度。而这里为什么要取一前一后的赋值索引,这因为数据导入时候,在每个batch里面同一条文本被相邻的导入了两次,那么这两个相邻的文本,经过SimCSE模型提取到的特征也是最为相似的,其相似度要接近1,而每个batch里面不相邻的模型输出,则应该是0,这样模型才能达到收敛的效果
y_true = K.equal(idxs_1, idxs_2)
y_true = K.cast(y_true, K.floatx())
这两行代码就是可以将y_true变成一个batchsize * batchsize大小的相似度矩阵,相似度的规则和上面描述的一样
生成y_true的中间值,其实可以打印出来看看,设定 y_pred为[‘a’, ‘a’, ‘b’, ‘b’, ‘c’, ‘c’]时候,整个调试代码如下:
from bert4keras.backend import keras, K
import tensorflow as tf
y_pred =['a','a','b','b','c','c']
session = tf.Session()# 张量转化为ndarray
idxs = K.arange(0, K.shape(y_pred)[0])
array = session.run(idxs)print('1', array)
idxs_1 = idxs[None,:]
array = session.run(idxs_1)print('2', array)
idxs_2 =(idxs +1- idxs %2*2)[:,None]
array = session.run(idxs_2)print('3', array)
y_true = K.equal(idxs_1, idxs_2)
array = session.run(y_true)print('4', array)
y_true = K.cast(y_true, K.floatx())
array = session.run(y_true)print('5',array)
y_pred = K.l2_normalize(y_pred, axis=1)
similarities = K.dot(y_pred, K.transpose(y_pred))
similarities = similarities - tf.eye(K.shape(y_pred)[0])*1e12
similarities = similarities *20
这几行代码就是计算SimCSE模型预测出来每个batch里的每个文本特征之间的相似度,特征越相似,K.dot(y_pred, K.transpose(y_pred)),特征向量点乘越接近1,similarities = similarities - tf.eye(K.shape(y_pred)[0]) * 1e12,则是为了消除相似度矩阵对角线上的元素,即同一条特征自身与自身点乘的结果。
loss = K.categorical_crossentropy(y_true, similarities, from_logits=True)
最后用交叉熵损失来定义模型最后的输出损失
训练自己的数据
在这个模型需要训练自己的数据,首先是环境搭建:
jieba-0.42.1
bert4keras-0.10.5
keras-2.3.1
cudatoolkit 10.0.130
cudnn 7.6.0
tensorflow-gpu 1.13.1
然后准备数据集,格式如下:
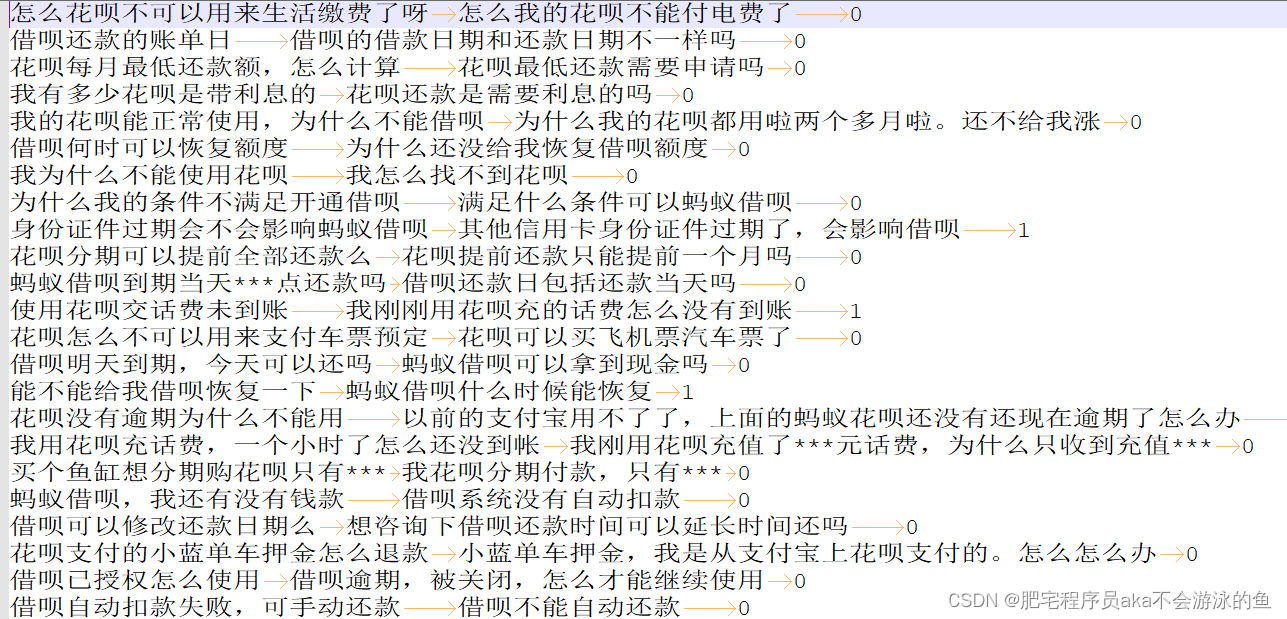
txt这个标签,0,1可以有,也可以没有
接着就是下载预训练模型,bert的模型,下载之后,修改eval.py中的数据集和预训练模型的路径,将其修改成自己的路径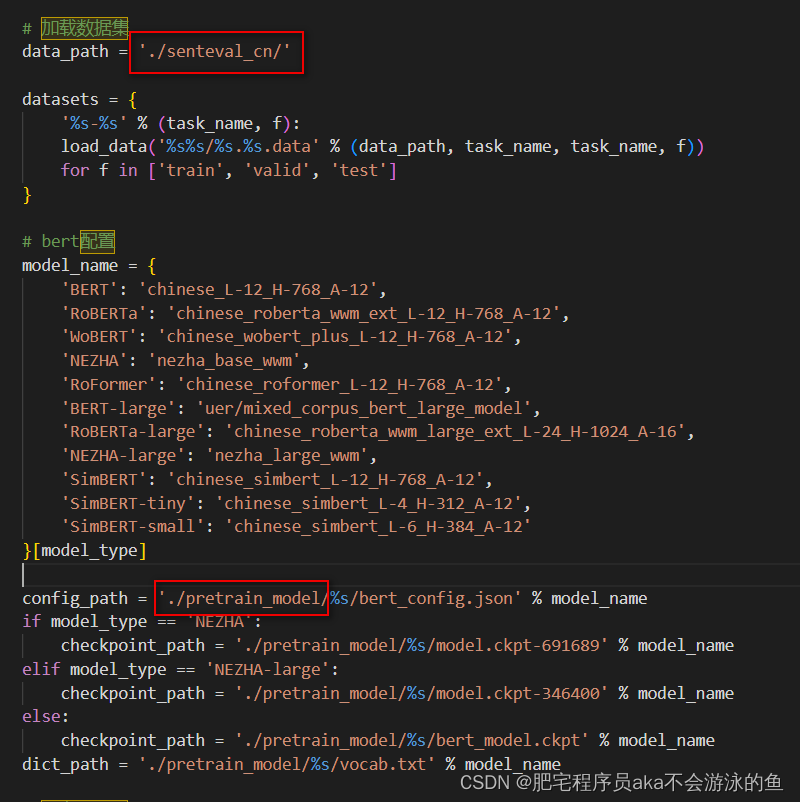
最后运行代码训练模型即可得到预测结果

参考链接
SimCSE论文及源码解读
SimCSE的loss实现源码解读
SimCSE: Simple Contrastive Learning of Sentence Embeddings
princeton-nlp/SimCSE
版权归原作者 肥宅程序员aka不会游泳的鱼 所有, 如有侵权,请联系我们删除。