
【AI数字人】如何基于GeneFace自训练AI数字人
环境配置
因为我已经搭好ER-NeRF项目的虚拟环境,GeneFace和ER-NeRF项目都是基于NeRF的数字人项目,因此我是在ernerf的虚拟环境中,按照下述命令行,增添GeneFace项目的一些库文件。
pip install -r docs/prepare_env/requirements.txt
bash docs/prepare_env/install_ext.sh
由于install_ext.sh安装gridencoder,与ernerf的gridencoder的grid.py文件有出入,导致运行ER-NeRF项目时报错。所以最好单独创建一个新的虚拟环境。
conda create -n geneface python=3.9.16-y
conda activate geneface
pip install fvcore iopath
conda install -c bottler nvidiacub -y
pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0--extra-index-url https://download.pytorch.org/whl/cu113
sudo apt-get install libasound2-dev portaudio19-dev
pip install -r docs/prepare_env/requirements.txt
bash docs/prepare_env/install_ext.sh
准备3DMM 模型
AD-NeRF、ER-NeRF和GeneFace这些基于NeRF的数字人项目,都需要
01_MorphableModel.mat
文件。我已经在AD-NeRF项目中,下载好01_MorphableModel.mat文件,因此复制到./deep_3drecon/BFM文件夹下即可。
同样的还有生成face_tracking需要的文件。
cd data_util/face_tracking
conda activate geneface
python convert_BFM.py #生成info文件保存在data_util/face_tracking/3DMM/3DMM_info.npy
下载
Exp_Pca.bin
和
BFM_model_front.mat
,并将其保存在./deep_3drecon/BFM文件夹下。
下载FaceRecon Model的预训练模型
epoch_20.pth
,并将其保存在./deep_3drecon/checkpoints/facerecon文件夹下。
上述四个文件,如果自己网络不能下载,可访问下述链接用百度网盘下载(GeneFace官方的链接)
链接:https://pan.baidu.com/s/1aMCRjrEKyeVeNGnvJoWF8g?pwd=qwer
提取码:qwer
测试
配置好上述环境之后,按照下述代码进行测试。
export PYTHONPATH=./# 不加这一行,会报“No module named 'deep_3drecon'”的错误。
CUDA_VISIBLE_DEVICES=0 python deep_3drecon/test.py
数据准备和预处理
LMS3数据集
LRS3-TED 是一个用于视觉和视听语音识别的多模态数据集。它包括来自 400 多个小时的 TED 和 TEDx 视频的人脸轨迹,以及相应的字幕和单词对齐边界。
特定的说话人视频
运行脚本对特定的说话人进行数据处理,命令行如下所示:
export PYTHONPATH=./
export VIDEO_ID=May
CUDA_VISIBLE_DEVICES=0 data_gen/nerf/process_data.sh $VIDEO_ID
bug
数据预处理的主程序是data_util/process.py 文件,video_id默认为May,共有9个小任务。数据处理的过程并不是一帆风顺的,出现了很多bug。我就通过下述命令行,一个任务一个任务地过了一遍,查看具体的bug所在并一一解决。
# --task后面是任务数字,1表示任务1
CUDA_VISIBLE_DEVICES=0 data_util/process.py --video_id May --task 1
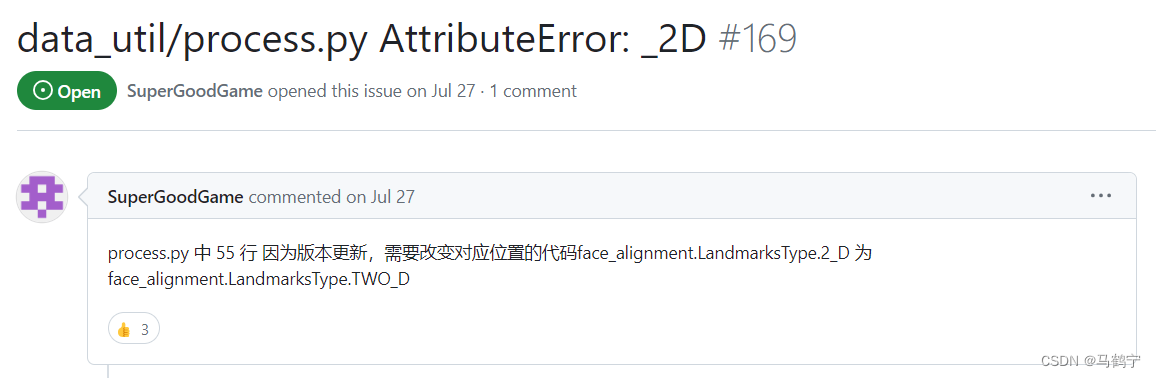
- 任务7的AttributeError: _2D错误,错误行为data_util/process.py 文件中的第55行,在issue中找到如下解决方案。 同样的错误也出现在计算3DMM时,data_util/process.py 文件的第26行,data_gen/nerf/extract_3dmm.py文件中的第16行。
训练
GeneFace 包含三个模块:
- 一个训练于LRS3数据集并通用于所有说话人的语音转动作模块;
- 一个适用于特定说话人的动作后处理网络,它被训练于LRS3数据集和对应说话人的视频数据;
- 一个适用于特定说话人的基于NeRF的渲染器,它被训练于对应说话人的视频数据。
SyncNet和Audio2Motion
github项目中提供了在LRS3数据集上预训练的模型压缩文件lrs3.zip 。lrs3.zip文件中包括一个 lm3d_vae_sync模型以实现语音转动作的变换(上述模块1),和一个 syncnet以实现对语音-嘴形对齐程度的衡量,这些模型是通用于所有说话人视频的,只需要训练一次即可。因此,可使用提供的预训练模型;也可以准备好LRS3数据集,在自己的机器上按下述命令训练一遍。
# 训练syncnet模型,适用于所有说话人视频
export PYTHONPATH=./
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config=egs/datasets/lrs3/lm3d_syncnet.yaml --exp_name=lrs3/syncnet
# 训练Audio2Motion模型,适用于所有说话人视频
export PYTHONPATH=./
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config=egs/datasets/videos/lrs3/lm3d_vae_sync.yaml --exp_name=lrs3/lm3d_vae_sync
这两步,我没有单独训练,下载的官方提供的模型。
PostNet
postnet模型仅适用于对应的说话人视频,所以对每个新的说话人视频你都需要训练一个新的postnet。
数据准备:LRS3数据集和对应的说话人视频数据集。
export PYTHONPATH=./
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config=egs/datasets/videos/May/lm3d_postnet_sync.yaml --exp_name=May/postnet
官方文档中介绍了如何选择合适步数的checkpoints的提示。
原因: 因为postnet训练属于对抗域适应(Adversarial Domain Adaptation)过程,而对抗训练的训练过程被广泛公认是不稳定的。
可能出现现象:当训练步数过多时,可能导致模型出现模式坍塌,比如postnet可能会学到将输入的任意表情都映射到同一个target person domain的表情(体现在validation sync/mse loss上升)
解决方案:
- validation sync/mse loss越低越好;
- adversarial loss达到收敛。
- 尽量选择步数较小的checkpoint。
我在这一步最优的checkpoints是8000步。
验证和可视化的命令行如下所示。需要根据自己最优ckpt步数和路径更改infer_postnet.sh文件中的变量赋值。
bash scripts/infer_postnet.sh # predict the 3D landmark sequence.
python utils/visualization/lm_visualizer.py # 可视化
可视化结果如下所示:
zozo
基于RAD-NeRF的渲染器
NeRF模型仅适用于对应的说话人视频,所以对每个新的说话人视频你都需要训练一个新的NeRF模型。
数据准备:LRS3数据集和对应的说话人视频数据集。
conda activate geneface
export PYTHONPATH=./
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config=egs/datasets/videos/May/lm3d_radnerf.yaml --exp_name=May/lm3d_radnerf
# Train the torso rad_nerf
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config=egs/datasets/videos/May/lm3d_radnerf_torso.yaml --exp_name=May/lm3d_radnerf_torso
在训练头部radnerf的时候,报错如下:
原因:ANTIALIAS已弃用,改用Ressampling.LANCZOS即可。
推理
生成说话人视频
当进行推理时,需要两步。
- 第一步使用postnet模型生成3D landmark序列,见PostNet下的视频。
- 第二步使用radnerf模型进行推理,合成的视频保存位置如下所示。

bash scripts/infer_postnet.sh # 预测3D landmark序列
bash scripts/infer_lm3d_radnerf.sh
参考
- GeneFace code
版权归原作者 马鹤宁 所有, 如有侵权,请联系我们删除。