
DCGAN
本教程将通过一个示例来介绍 DCGAN。 我将训练一个生成对抗网络 (GAN) ,在向其展示许多真实名人的照片后生成新的名人。这里大部分代码来自于 pytorch/examples 。本文档针对这些实现进行全面解释,并阐述该模型的工作方式和原因。
Generative Adversarial Networks
What is a GAN?
GANs
是训练一个
DL
模型以获得训练数据分布的框架,因此我们可以从相同的分布中生成新数据。
GANs
是由
Ian Goodfellow
于 2014 年发明,并在论文
Generative Adversarial Nets
中首次描述。它们由两个不同的模型组成,一个生成模型,一个鉴别模型。生成器的工作是生成看起来像训练图像的“假”图像,鉴别器的工作是查看图像并输出它是来自生成器的真实图像还是伪图像。在训练过程中,生成器不断尝试通过生成越来越好的假图像来击败鉴别器,而鉴别器则努力成为更好的分辨器从而更好的区分图像的真伪。这个游戏的平衡点是,当生成器生成看起来直接来自训练数据的完美赝品时,鉴别器总是以 50% 的置信度猜测生成器输出是真的还是假的。
在开始鉴别器之前,我们做出一些定义,
x
x
x 代表的是图像数据,
D
(
x
)
D(x)
D(x) 是鉴别器网络,它输出概率来自于训练数据而不是生成器。这里,因为我们处理的是图像,所以
D
(
x
)
D(x)
D(x) 的尺寸为
【CHW】: 3*64*64
。直观地说,当
x
x
x 来自训练数据时,
D
(
x
)
D(x)
D(x) 应该高,当
x
x
x 来自生成器时,
D
(
x
)
D(x)
D(x) 应该低。
D
(
x
)
D(x)
D(x) 也可以被认为是传统的二分类器。
对于生成器,假设
z
z
z 是一个隐藏的空间向量,是从标准正态分布中采样的。
G
(
z
)
G(z)
G(z) 代表生成器函数,将隐藏向量
z
z
z 转换到数据空间。
G
G
G 的目标是评估来自于 (
p
d
a
t
a
p_{data}
pdata) 的训练数据的分布,从而可以从评估的分布(
p
g
p_g
pg)中生成假的样本。
所以,
D
(
G
(
z
)
)
D(G(z))
D(G(z)) 输出
G
G
G 是否为真实图像。Goodfellow’s paper,
D
D
D 试图最大化概率分类器区分真实和假的图像(
l
o
g
D
(
x
)
logD(x)
logD(x)),
G
G
G 最小化
G
G
G 生成的图像经过
D
D
D 判别为假图像的概率 (
l
o
g
(
1
−
D
(
G
(
z
)
)
)
log(1-D(G(z)))
log(1−D(G(z)))), GAN 的损失函数为
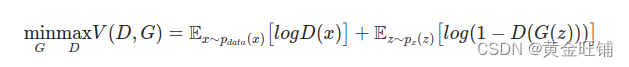
理论上,这个最小最大博弈游戏的解是
p
g
=
p
d
a
t
a
p_g=p_{data}
pg=pdata, 鉴别器随机猜测输入是真实的还是假的。然而,
GAN
的收敛理论仍在积极研究中,现实中的模型并不总是训练到这一点。
What is a DCGAN?
DCGAN是上述GAN的直接扩展,只是它分别在鉴别器和生成器中明确使用卷积和反卷积层。它首先由Radford等人在论文使用深度卷积生成对抗网络的无监督表示学习中描述. 鉴别器由 strided convolution, batch norm, LeakyReLU activation 组成;输入是
3x64x64
图像,输出是输入来自真实数据分布的标量概率。生成器由 convolutional-transpose, batch norm, ReLU 组成。输入是从标准正态分布绘制的潜在向量
z
z
z,输出是
3x64x64
图像。跨步反卷积层允许将潜在向量转换为与图像形状相同的尺寸。在本文中,作者还提供了一些关于如何设置优化器、如何计算损失函数以及如何初始化模型权重的提示,所有这些将在接下来的章节中进行解释。
import argparse
import os
import random
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
import torch.functional as F
from IPython.display import HTML
# set random seed for reprodicibility
manualSeed =999
random.seed(manualSeed)
torch.manual_seed(manualSeed)
Inputs
定义运行所需要的输入:
- dataroot - 数据集文件夹的路径;
- workers - DataLoader 加载数据用的线程
- batch_size - 训练的批大小,DCGAN一般设置为128
- image_size - 用于训练的图像尺寸,默认用
64*64 - nc - 输入图像的通道数,彩色为3
- nz - 隐藏向量的长度
- ngf - 与生成器中特征图的深度相关
- ndf - 鉴别器中特征图的深度
- num_epochs - 训练迭代次数,训练越长效果越好;
- lr - 训练的学习率,在DCGAN论文中,必须为 0.0002
- beta1 - Adam 优化器的 beta1 超参数,论文中必须为 0.5
- ngpu - GPU数量,如果为0,则在CPU上运行
# 数据路径
dataroot ="/home/jwzhou/data/baidudownload/celeba"# dataloader 工作线程数
workers =2# 训练批处理数量
batch_size =128# 图像大小
image_size =64# 输出通道数
nc =3# 输入的隐藏向量的维度
nz =100# 生成器的特征图大小
ngf =64# 鉴别器特征图大小
ndf =64# 迭代次数
num_epochs =5# 优化学习率
lr =0.0002# Adam 超参数
beta1 =0.5# GPU数量
ngpu =1
Data
本教程使用 Celeb-A 人脸数据集, 百度盘地址。
下载后解压文件路径如下:
/path/to/celeba
-> img_align_celeba
->188242.jpg
->173822.jpg
->284702.jpg
->537394.jpg
...
然后,我们创建 dataset, dataloader, 设置 device, 并显示部分训练数据;
# 创建数据集
dataset = dset.ImageFolder(root=dataroot,
transform=transforms.Compose([
transforms.Resize(image_size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))]))# 创建数据集的数据加载器
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,
shuffle=True, num_workers=workers)# device
device = torch.device("cuda:0"if(torch.cuda.is_available()and ngpu >0)else"cpu")# 显示一些图像
real_batch =next(iter(dataloader))
plt.figure(figsize=(8,8))
plt.axis("off")
plt.title("Training Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=2, normalize=True).cpu(),(1,2,0)))

Implementation
有了前面参数的设置和数据集的准备,我们就开始实现了,首先对权重进行初始化,然后定义生成器,鉴别器,损失函数,训练循环。
Weight Initialization
DCGAN
论文中,作者将模型的权重初始化为
mean=0, std=0.02
, 函数 weights_init 将模型作为参数,重新初始化所有卷积,反卷积,批处理等层的参数。
# 权重初始化defweights_init(m):
classname = m.__class__.__name__
if classname.find("Conv")!=-1:
m.weight.data.normal_(0.0,0.02)elif classname.find("BatchNorm")!=-1:
m.weight.data.normal_(1.0,0.02)
m.bias.data.fill_(0)
Generator
生成器
G
G
G 被设计成将隐藏向量
z
z
z 进行数据空间映射,因为我们的数据是图像,也就是说创建一个类似于训练图像(
3*64*64
)。实际操作中,经过一系列二维反卷积、2D batch norm 和 relu 激活,值得注意的是,在反卷积之后存在
batch norm
,因为这是
DCGAN
论文的一个重要贡献。这些层有助于训练期间的梯度流动。DCGAN 论文的生成器如下所示。
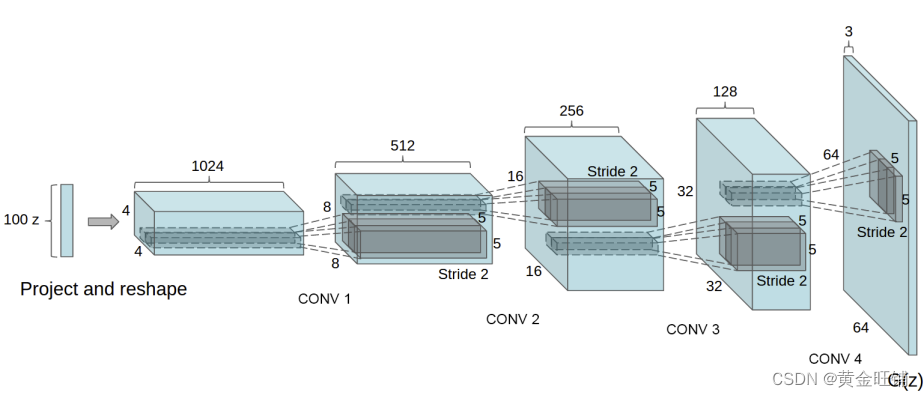
# GeneratorclassGenerator(nn.Module):def__init__(self, ngpu):super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
nn.ConvTranspose2d(nz, ngf *8,4,1,0, bias=False),
nn.BatchNorm2d(ngf *8),
nn.ReLU(True),
nn.ConvTranspose2d(ngf *8, ngf *4,4,2,1, bias=False),
nn.BatchNorm2d(ngf *4),
nn.ReLU(True),
nn.ConvTranspose2d(ngf *4, ngf *2,4,2,1, bias=False),
nn.BatchNorm2d(ngf *2),
nn.ReLU(True),
nn.ConvTranspose2d(ngf *2, ngf,4,2,1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
nn.ConvTranspose2d(ngf, nc,4,2,1, bias=False),
nn.Tanh())defforward(self, x):return self.main(x)
实例化生成器并初始化参数。
# 创建 生成器
netG = Generator(ngpu).to(device)# 转移数据if(device.type=='cuda')and(ngpu >1):
netG = nn.DataParallel(netG,list(range(ngpu)))# 初始化权重
netG.apply(weights_init)# 打印生成器网络print(netG)
<torch._C.Generator at 0x7f9055846ed0><matplotlib.image.AxesImage at 0x7f9144554bb0>
Generator((main): Sequential((0): ConvTranspose2d(100, 512, kernel_size=(4, 4), stride=(1, 1), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): ConvTranspose2d(512, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): ConvTranspose2d(256, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(7): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(8): ReLU(inplace=True)(9): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(10): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(11): ReLU(inplace=True)(12): ConvTranspose2d(64, 3, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(13): Tanh()))
Discriminator
鉴别器
D
D
D 是一个二分类网络,输入为图像,输出对应图像的分类标量概率结果。这里,输入为
3*64*64
的图像。
# 鉴别器classDiscriminator(nn.Module):def__init__(self, ngpu):super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
nn.Conv2d(nc, ndf,4,2,1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf, ndf *2,4,2,1, bias=False),
nn.BatchNorm2d(ndf*2),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf *2, ndf *4,4,2,1, bias=False),
nn.BatchNorm2d(ndf *4),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf *4, ndf *8,4,2,1, bias=False),
nn.BatchNorm2d(ndf *8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf *8,1,4,1,0, bias=False),
nn.Sigmoid())defforward(self, x):return self.main(x)
# 鉴别器
netD = Discriminator(ngpu).to(device)# 转移数据if(device.type=='cuda')and(ngpu >1):
netD = nn.DataParallel(netD,list(range(ngpu)))# 初始化权重
netD.apply(weights_init)# 打印模型print(netD)
Discriminator((main): Sequential((0): Conv2d(3, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(1): LeakyReLU(negative_slope=0.2, inplace=True)(2): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): LeakyReLU(negative_slope=0.2, inplace=True)(5): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(6): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(7): LeakyReLU(negative_slope=0.2, inplace=True)(8): Conv2d(256, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)(9): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(10): LeakyReLU(negative_slope=0.2, inplace=True)(11): Conv2d(512, 1, kernel_size=(4, 4), stride=(1, 1), bias=False)(12): Sigmoid()))
Loss Functions and Optimizers
建立了
D
D
D 和
G
G
G 后,我们可以指定他们如何通过损失函数和优化器学习, 我们将使用
Binary Cross Entropy loss
(BCELoss) 。
ℓ
(
x
,
y
)
=
L
=
{
l
1
,
…
,
l
N
}
⊤
,
l
n
=
−
[
y
n
⋅
log
x
n
+
(
1
−
y
n
)
⋅
log
(
1
−
x
n
)
]
\ell(x, y) = L = \{l_1,\dots,l_N\}^\top, \quad l_n = - \left[ y_n \cdot \log x_n + (1 - y_n) \cdot \log (1 - x_n) \right]
ℓ(x,y)=L={l1,…,lN}⊤,ln=−[yn⋅logxn+(1−yn)⋅log(1−xn)]
这个函数结合了
log
(
D
(
x
)
)
\log(D(x))
log(D(x)) 和
log
(
1
−
D
(
G
(
z
)
)
)
\log(1-D(G(z)))
log(1−D(G(z))) 。真实的图像标签为1,假图像标签为0,这些标签在计算
D
D
D 和
G
G
G 的损失函数时用得到。
# 初始化 BCE Loss
criterion = nn.BCELoss()# 创建一批随机的隐藏向量,用来显示生成器的过程
fixed_noise = torch.randn(64, nz,1,1, device=device)# 训练时真假标签
real_label =1.
fake_label =0.# 为 G 和 D 建立 Adam 优化器
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1,0.999))
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1,0.999))
Training
最后,现在我们已经定义了
GAN
框架的所有部分,我们可以对其进行训练。请注意,训练
GAN
多少是一种艺术形式,因为不正确的超参数设置会导致模式崩溃,而对错误的解释很少。在这里,我们将严格遵循
Goodfellow
论文中的算法1,同时遵守ganhacks 。
# Training Loop# Lists to keep track of progress
img_list =[]
G_losses =[]
D_losses =[]
iters =0print("Starting Training Loop...")# For each epochfor epoch inrange(num_epochs):# For each batch in the dataloaderfor i, data inenumerate(dataloader,0):############################# (1) Update D network: maximize log(D(x)) + log(1 - D(G(z)))############################# Train with all-real batch
netD.zero_grad()# Format batch
real_cpu = data[0].to(device)
b_size = real_cpu.size(0)
label = torch.full((b_size,), real_label,
dtype=torch.float, device=device)# Forward pass real batch through D
output = netD(real_cpu).view(-1)# Calculate loss on all-real batch
errD_real = criterion(output, label)# Calculate gradients for D in backward pass
errD_real.backward()
D_x = output.mean().item()## Train with all-fake batch# Generate batch of latent vectors
noise = torch.randn(b_size, nz,1,1, device=device)# Generate fake image batch with G
fake = netG(noise)
label.fill_(fake_label)# Classify all fake batch with D
output = netD(fake.detach()).view(-1)# Calculate D's loss on the all-fake batch
errD_fake = criterion(output, label)# Calculate the gradients for this batch, accumulated (summed) with previous gradients
errD_fake.backward()
D_G_z1 = output.mean().item()# Compute error of D as sum over the fake and the real batches
errD = errD_real + errD_fake
# Update D
optimizerD.step()############################# (2) Update G network: maximize log(D(G(z)))###########################
netG.zero_grad()
label.fill_(real_label)# fake labels are real for generator cost# Since we just updated D, perform another forward pass of all-fake batch through D
output = netD(fake).view(-1)# Calculate G's loss based on this output
errG = criterion(output, label)# Calculate gradients for G
errG.backward()
D_G_z2 = output.mean().item()# Update G
optimizerG.step()# Output training statsif i %50==0:print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'%(epoch, num_epochs, i,len(dataloader),
errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))# Save Losses for plotting later
G_losses.append(errG.item())
D_losses.append(errD.item())# Check how the generator is doing by saving G's output on fixed_noiseif(iters %500==0)or((epoch == num_epochs-1)and(i ==len(dataloader)-1)):with torch.no_grad():
fake = netG(fixed_noise).detach().cpu()
img_list.append(vutils.make_grid(fake, padding=2, normalize=True))
iters +=1
Output exceeds the size limit. Open the full output data in a text editor
Starting Training Loop...
[0/5][0/1583] Loss_D: 1.9443 Loss_G: 2.4681 D(x): 0.3288 D(G(z)): 0.3883 / 0.1142[0/5][50/1583] Loss_D: 0.2114 Loss_G: 10.2926 D(x): 0.9067 D(G(z)): 0.0073 / 0.0001[0/5][100/1583] Loss_D: 0.6894 Loss_G: 10.5395 D(x): 0.7054 D(G(z)): 0.0129 / 0.0003[0/5][150/1583] Loss_D: 0.4926 Loss_G: 5.8063 D(x): 0.8946 D(G(z)): 0.2637 / 0.0060[0/5][200/1583] Loss_D: 1.1559 Loss_G: 5.9362 D(x): 0.5082 D(G(z)): 0.0065 / 0.0101[0/5][250/1583] Loss_D: 0.3253 Loss_G: 3.5304 D(x): 0.8113 D(G(z)): 0.0353 / 0.0558[0/5][300/1583] Loss_D: 0.6675 Loss_G: 5.1617 D(x): 0.8416 D(G(z)): 0.3300 / 0.0119[0/5][350/1583] Loss_D: 0.4813 Loss_G: 2.9057 D(x): 0.7531 D(G(z)): 0.0635 / 0.0858[0/5][400/1583] Loss_D: 0.5922 Loss_G: 5.2983 D(x): 0.9001 D(G(z)): 0.3426 / 0.0088[0/5][450/1583] Loss_D: 0.4844 Loss_G: 7.2637 D(x): 0.9148 D(G(z)): 0.2675 / 0.0017[0/5][500/1583] Loss_D: 0.4116 Loss_G: 4.3610 D(x): 0.8469 D(G(z)): 0.1585 / 0.0238[0/5][550/1583] Loss_D: 0.6790 Loss_G: 5.8678 D(x): 0.8724 D(G(z)): 0.3513 / 0.0060[0/5][600/1583] Loss_D: 0.4209 Loss_G: 4.2898 D(x): 0.8563 D(G(z)): 0.1590 / 0.0223[0/5][650/1583] Loss_D: 0.5120 Loss_G: 6.5634 D(x): 0.8905 D(G(z)): 0.2808 / 0.0027[0/5][700/1583] Loss_D: 0.5932 Loss_G: 6.3401 D(x): 0.9004 D(G(z)): 0.3259 / 0.0041[0/5][750/1583] Loss_D: 0.3768 Loss_G: 5.9319 D(x): 0.8984 D(G(z)): 0.2017 / 0.0048[0/5][800/1583] Loss_D: 0.7084 Loss_G: 5.6795 D(x): 0.6093 D(G(z)): 0.0029 / 0.0080[0/5][850/1583] Loss_D: 0.4788 Loss_G: 4.3612 D(x): 0.7587 D(G(z)): 0.0744 / 0.0253[0/5][900/1583] Loss_D: 0.8956 Loss_G: 6.1116 D(x): 0.5294 D(G(z)): 0.0064 / 0.0135[0/5][950/1583] Loss_D: 0.3724 Loss_G: 4.2488 D(x): 0.8344 D(G(z)): 0.1434 / 0.0268[0/5][1000/1583] Loss_D: 0.2876 Loss_G: 4.5981 D(x): 0.9064 D(G(z)): 0.1443 / 0.0165[0/5][1050/1583] Loss_D: 0.7042 Loss_G: 6.4109 D(x): 0.8478 D(G(z)): 0.3358 / 0.0043[0/5][1100/1583] Loss_D: 0.4343 Loss_G: 3.7318 D(x): 0.7284 D(G(z)): 0.0309 / 0.0459[0/5][1150/1583] Loss_D: 0.5568 Loss_G: 4.7865 D(x): 0.8266 D(G(z)): 0.2446 / 0.0142...
[4/5][1400/1583] Loss_D: 0.7685 Loss_G: 1.6348 D(x): 0.6787 D(G(z)): 0.2528 / 0.2367[4/5][1450/1583] Loss_D: 0.6327 Loss_G: 2.0540 D(x): 0.6973 D(G(z)): 0.1944 / 0.1660[4/5][1500/1583] Loss_D: 0.5396 Loss_G: 2.2505 D(x): 0.7664 D(G(z)): 0.2037 / 0.1315[4/5][1550/1583] Loss_D: 0.6219 Loss_G: 1.3390 D(x): 0.6625 D(G(z)): 0.1465 / 0.2989
Results
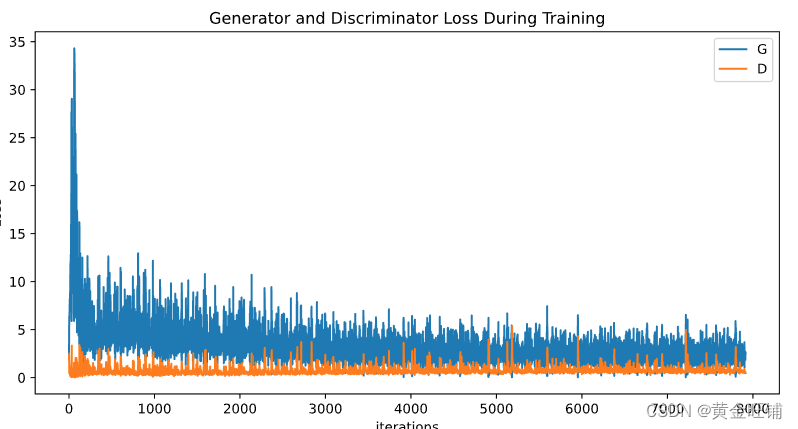
Finally, lets check out how we did. Here, we will look at three different results. First, we will see how D and G’s losses changed during training. Second, we will visualize G’s output on the fixed_noise batch for every epoch. And third, we will look at a batch of real data next to a batch of fake data from G.
最后,让我们看看我们是如何做到的。在这里,我们将看到
loss
变化,
G
G
G 的可视化输出,真假数据对比。
Loss versus training iteration
plt.figure(figsize=(10,5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses, label="G")
plt.plot(D_losses, label="D")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
Visualization of G’s progression
fig = plt.figure(figsize=(8,8))
plt.axis("off")
ims =[[plt.imshow(np.transpose(i,(1,2,0)), animated=True)]for i in img_list]
ani = animation.ArtistAnimation(
fig, ims, interval=1000, repeat_delay=1000, blit=True)
HTML(ani.to_jshtml())

Real Images vs. Fake Images
# Grab a batch of real images from the dataloader
real_batch =next(iter(dataloader))# Plot the real images
plt.figure(figsize=(15,15))
plt.subplot(1,2,1)
plt.axis("off")
plt.title("Real Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=5, normalize=True).cpu(),(1,2,0)))# Plot the fake images from the last epoch
plt.subplot(1,2,2)
plt.axis("off")
plt.title("Fake Images")
plt.imshow(np.transpose(img_list[-1],(1,2,0)))
plt.show()

【参考】
DCGAN TUTORIAL
版权归原作者 黄金旺铺 所有, 如有侵权,请联系我们删除。