
上周,文档解析测评工具发布后,我们收到最多的反馈问题是—— 你们这套测试指标是如何确定的?表格、段落、标题、阅读顺序、公式这些维度分别代表什么? 测试结果中数字都有什么意义?在实际使用中又起到怎样的作用呢?
大家关心的问题,就是我们的最高优先级。
今天,我们先来聊聊PDF解析过程中的一项重难点——表格。
💡首先,为什么说表格是解析任务中的一项重点? 从语料源头来看,需要解析的文档中含有表格的情况十分常见。论文、年报、财报、行研报告、法律文件、企业文档等等类型的文件中,表格都是构成要件之一,且往往包含重要、精密的数据或信息。 当我们将注意力放到下游应用,会发现在普遍的知识库搭建、RAG(Retrieval-Augmented Generation)系统建设等场景中,表格解析也是至关重要的一环。 对于RAG系统的整体性能和效果,表格解析能力可以显著提升以下几方面:
- 信息召回的精度与准确性:表格数据通常包含丰富的结构化信息,如日期、金额等,这些信息在非结构化文本中难以直接提取。通过高效的表格解析技术,可以将这些信息以更易于处理的格式(如Markdown)呈现出来,从而提高信息的召回率和准确性。同时,准确的表格解析有助于RAG系统更精确地定位和检索信息,减少错误检索或信息片段的不完整检索。
- 复杂文档的处理能力:许多专业文档包含复杂的表格和其他视觉元素。表格解析能力可以帮助RAG系统处理这些复杂结构,提供更深入的内容分析。
- 增强上下文理解,改善答案生成质量:举例来说,在财务报告中,表格中的数据与文本描述相结合可以提供更全面的业务洞察,并生成更加准确、相关和全面的回答。
💡其次,为什么表格是咱们算法开发同学关注的重点? 主要问题在于表格的多样性和复杂性。我们需要直面表格样式的复杂多变:无线表、合并单元格、跨页表格、超密集表格和不规则表单的还原,单元格内多行文字的还原等。在一些情况下,还会有扫描模糊或倾斜、表格中含有手写内容这些难度叠加buff。
那么,一个好的表格解析效果是什么样呢?
从直接观感上看,主要有两方面:第一,每个单元格里的内容识别都是正确的;第二,表格整体上没有错行、漏行、错误合并或错误拆分等问题。 为了定量计算以上标准,我们的测试指标在表格维度定义了三个指标,即表格文本全对率、表格结构树状编辑距离以及表格树状编辑距离。
- 表格文本全对率=文本全对的表格个数(pred)/ 总表格个数(gt) 用术语来讲,这个指标的含义是:解析出的表格中每个单元格的文本是否与原始表格完全一致,没有遗漏、错误或多余的字符。 我们可以非常直白地理解,它的意义就是看一个表格中,每个单元格的内容是否完全准确。 以下面这个表为例:
col_a
col_b
1
2
3
4
如果其中每个格子的文本都对,那么此处的全对率就是100%。文本全对率越高,说明内容识别越准确。 值得注意的是,在我们的测试工具里,这个标准比较严苛:表格中只要有一个单元格有误,即判为该表格出错。因此该项数据结果与观测感受相比,可能会偏低。 我们对文本全对秉持高标准的原因在于,解析误差对后续的语义理解、数据分析工作影响重大。尤其对于一些金融、经济报告或论文中的表格数据,一个数字的差错,都会对结论产生很大干扰。所以,我们认为优秀的文本全对率是解析需要提供的重要保障。
- 表格结构树状编辑距离=所有表格树编辑距离分数之和(pred,不包含文字)/ 总表格数量(gt) 与文本全对率相比,这是一个相对抽象的概念。 首先,在测评中,我们将表格结构用树状形式表现,这是一种对比逻辑结构的实用方法,图示可以参考下方图1。 我们再来看何为“编辑距离”。 这个概念最早来自于机器翻译,指的是对给定的两个字符串,最少要经历多少次插入、删除、替换操作,才能使两个字符串完全一样。 举一个例子:"kitten" 和 "sitting":
- 把 'k' 换成 's'(替换) -> "sitten"
- 把 'e' 换成 'i'(替换) -> "sittin"
- 在最后插入一个 'g'(插入) -> "sitting"
这里共用了三次操作,所以这两个字符串的编辑距离是3。 而树状编辑距离,就是将对比对象从字符串变成了一棵逻辑树,从操作字符变成了操作树的节点。 对于树而言 ,同样定义了树编辑距离的增删改操作:
- 增:添加一个节点在父节点和其子节点之间
- 删:将树的某个节点删除,同时将其子节点移动到该节点的父节点上。
- 改:修改节点的label
计算树的编辑距离就是求从一棵树转换为另一棵树所需要树的编辑操作的最少次数,图示请见下方图2。


如果我们的解析引擎给出的表格结构与实际结构完全一致,测试结果中,表格结构树状编辑距离就是0,也即得到满分💯。 这个指标得分越高,意味着表格结构还原越好,错行、漏行或合并单元格错误等问题越少。
- 表格树状编辑距离=所有表格树编辑距离分数之和(pred,包含文字)/ 总表格数量(gt) 在前两个指标的基础上,表格树状编辑距离的概念就很好理解了。 这是一项将上述1和2综合起来的指标,整体评估了文本全对率与结构准确度,不仅考虑了单元格的内容,还考虑了表格的层次结构和布局。 通过这项指标,我们能整合测评表格解析结果的准确程度。 放几个案例👇直观感受表格解析的效果。

显然,图中的表格数据没有被解析为各列一一对应的格式。如果大模型获得这样的解析结果,必然无法在此基础上提取到准确的参数信息,并建立正确的分析或回答。
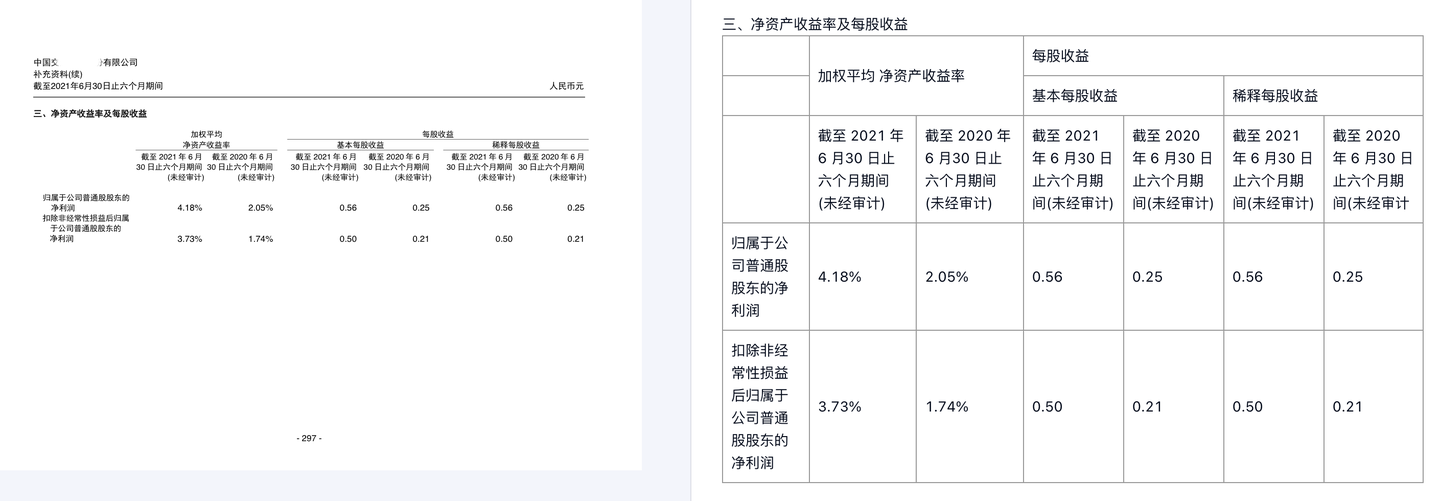
对比来看一份正确解析的表格。在大部分无框线、合并单元格的情况下,准确还原文本内容及各单元格结构关系,为RAG提供高质量信息基础。
本期我们主要介绍了测评指标中针对表格的部分,接下来,我们还会继续探讨标题、段落等指标的设计逻辑。
欢迎各位开发者随时给我们提出需求,包括但不限于对这个tester本身的优化建议,或者提供样本找我们对比测试,甚至是指定产品做对比测试~
TextIn文档解析产品目前正在内测计划中,为每位用户提供每周7000页的额度福利,关注公众号《合研社》即可申领。
关于测评工具、产品或需求,都可以随时找我们沟通。我们欢迎所有探讨和交流!
版权归原作者 合合技术团队 所有, 如有侵权,请联系我们删除。