
1. 达芬奇NPU
1.1 AI Core的逻辑结构:
计算类:矩阵、向量、标量
存储类:各种缓冲区
控制类:处理、发射、同步...
所以需要知道数据从哪搬到哪、是什么目的
但是太复杂了 ,怎么办?
抽象:
片上存储都抽象为local memory
DMA搬运单元负责内外搬运数据
AI Core内部六条流水线,可以完全并行(不需要时分复用)
带来问题:依赖关系执行顺序出错怎么办?
所以要在片上搞同步,这是coding时候需要考虑的
1.2 算子:处理单元
广义上,对函数的任何操作都可以是算子(不一定函数)
比如:激活函数(ReLU、sigmod)

基本概念:
- 算子名称(Name)
如:Conv1, Conv2
- 算子类型(Type)
如:Conv1, Conv2都可以是卷积类
- 数据容器(Tensor)存储算子输入数据与输出数据的容器包括属性:name(需要唯一),shape(形状),dtype(数据类型),format(内存是一维的,数据是多维的,如何去遍历)题外话:tensorflow的名字起的很形象,tensor的flow,不断往下流
2. Ascend C快速入门
动手去喽
Ascend C编程语言开发的算子被称为Ascend C算子
2.1. 什么场景需要开发自定义算子
人无我有:算子有无的问题,遇到了不支持的算子
人有我优:已经有算子,但是开发性能更好的
2.2 Host与Device的区别
从装机到元神启动
信息读取到内存,cpu给gpu下画图任务,gpu从内存把信息获取到显存,画图
在这个场景下,进程是cpu启动的,但是任务是在gpu进行的
cpu是host,gpu是device,显存就是Device Memory
训练AI也是一样的,host上写代码,但是在device上跑
2.3 核函数
什么是核函数
我们就是要编写跑在AI Core上的函数,也就是核函数
核函数是host和device的桥梁
入参统一为__gm__unit8_t*
怎么调用核函数
kernel_name<<<blockDim, 12ctrl, stream>>>(argument list);
核函数是跑在一个AI Core上的,blockDim代表跑在几个核上,12ctrl保留参数,stream是一个任务队列,用来管理任务的并行
2.4 编程模型——SPMD模型
Local storage
并行计算:把AI Core编号,block_idx,每个AI Core拿一定长度的内存,可以从首地址判断自己取哪一段地址的数据
2.5 编程范式——流水任务
progress的n=3,三个流水线顺序执行加速
2.6 矢量编程任务间的通信与同步
三个阶段分为CopyIn、Compute、CopyOut
放入队列vecin中,CpoyIn阶段才完成
放入到vecout中,Compute阶段才算完成
vectut放入output tensor中,copyOut阶段才算完成
vecin和vecout有enque和deque,保证三个阶段调用顺序
2.7 算子类实现
类名:KernelAdd
初始函数Init()和核心处理函数Process()
三个流水线任务 CopyIn、Compute、CopyOut
2.8 算子在host侧实现
之前的都是device侧,这里有三个要考量的
Tilling,张量分型每次送一个小快到device,叫tiling算法,如何分这个块,叫tiling算法算法打包,叫tiling结构体,具体实现是tiling函数
Shape推导,根据输入推测输出的形状意义:提前算好需要的内存,执行期就不需要malloc了,提升性能
算子原型注册配置信息
2.9 动手
改函数:
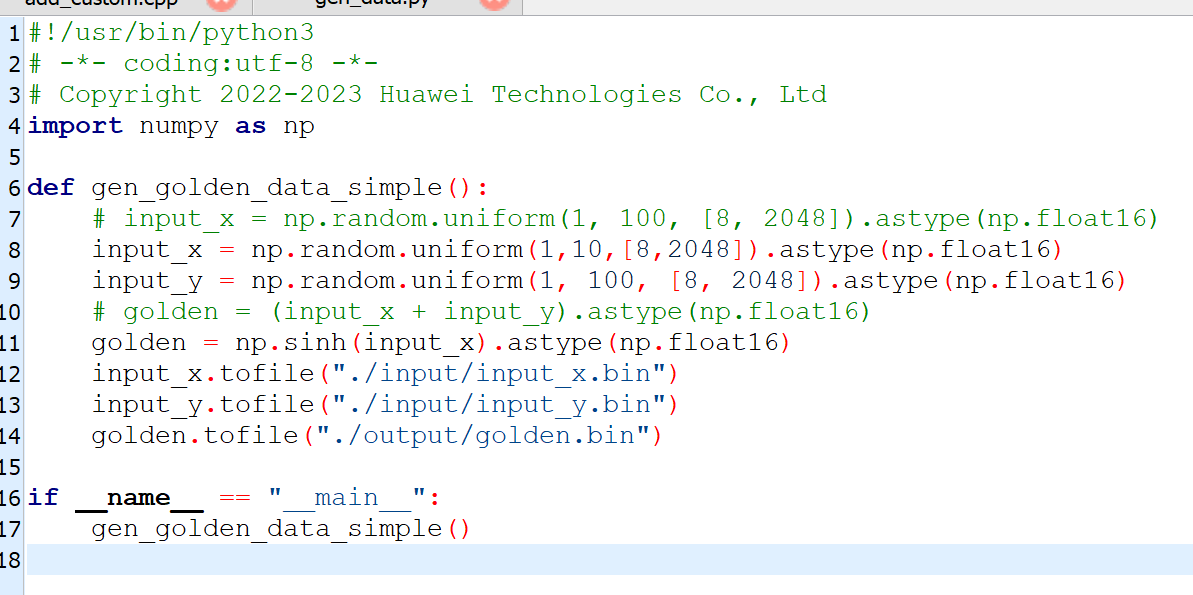
根据API文档,找到Muls、Exp、Sub的用法

成功运行
版权归原作者 ZUOHS 所有, 如有侵权,请联系我们删除。