
1. ChatGLM介绍
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答,

代码链接👇🏻
ChatGLM_实战_信息抽取
2. 场景说明
由于工作原因,需要对机器上的文本进行分类。其核心功能就是通过文件的文本内容,提取关键信息,判断文件类别 ,下文教程为通过ChatGLM模型进行信息提取的实战的一部分。

任务可拆解为两步:
1.非结构化内容提取
2.命名实体识别,内容抽取
其中第二步为信息提取,输入输出如下
- input -> 大段文本
- output -> 识别&提取的结构化内容
因为应用场景,短时间无法获取高质量样本,优先使用预训练模型实现,后期积累样本做微调(fine-tuning)
3. 模型选择
由于业务场景主要为中文,而且识别的类型经常发生变化 ,传统的NER模型不一定使用 ,固直接选用清华开源的ChatGLM作为前置数据提取模块,后期积累高质量数据再进行微调、模型重构。
清华ChatGLM-6B
优点: 私有部署,低成本部署。

默认情况下,模型以 FP16 精度加载,运行上述代码需要大概 13GB 显存。如果你的 GPU 显存有限,可以尝试以量化方式加载模型 ,INT4 量化后的模型仅需大概 5.2GB 的内存.
4. 模型部署
由于手头无16G显存的GPU,所以使用Google Colab进行验证。
4.1 GPU设置

免费版只能用
T4

查看显存,16G也够用了
!nvidia-smi

4.2 安装环境
代码拉取
!git clone https://github.com/THUDM/ChatGLM-6B.git

环境安装
!pip install -r /content/ChatGLM-6B/requirements.txt

模型下载,默认下载
FP16,
colab内存限制,目前只能直接加载
FP4,下文直接加载
FP4
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4",trust_remote_code=True).half().cuda()

硬件要求参考
量化等级****最低 GPU 显存(推理)最低 GPU 显存(高效参数微调)FP16(无量化)13 GB14 GBINT88 GB9 GBINT46 GB7 GB
FP4模型加载完成

查看系统资源消耗,FP4 模型加载后 ,显存使用4.6 G ,内测使用2.7G

5. 模型预测
首次加载,约
15s
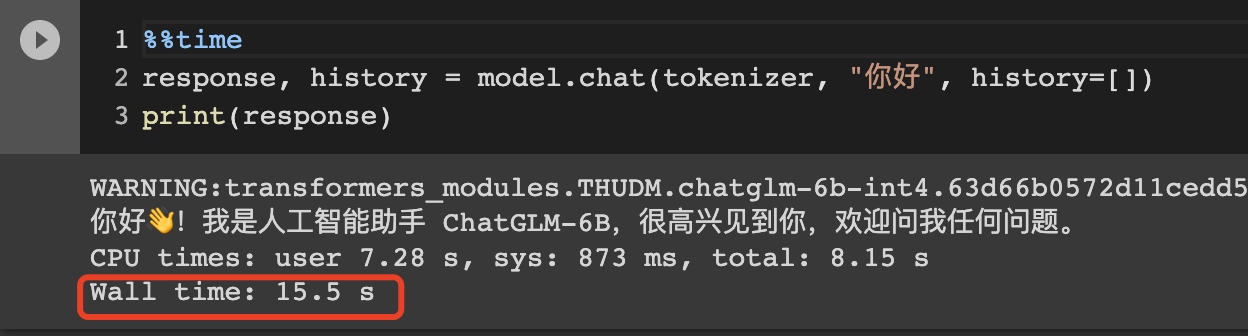
之后预测,耗时约
1s

上述仅单条测试时间,批量(batch)推理理论上更加高效 ,时长与输入的token长度有关。
6. 信息抽取
通过使用适当
prompt可以让模型完成信息抽取任务,并且按指定的格式输出(
json) ,以满足批处理,结构化输出的要求。
6.1 信息抽取任务
%%time
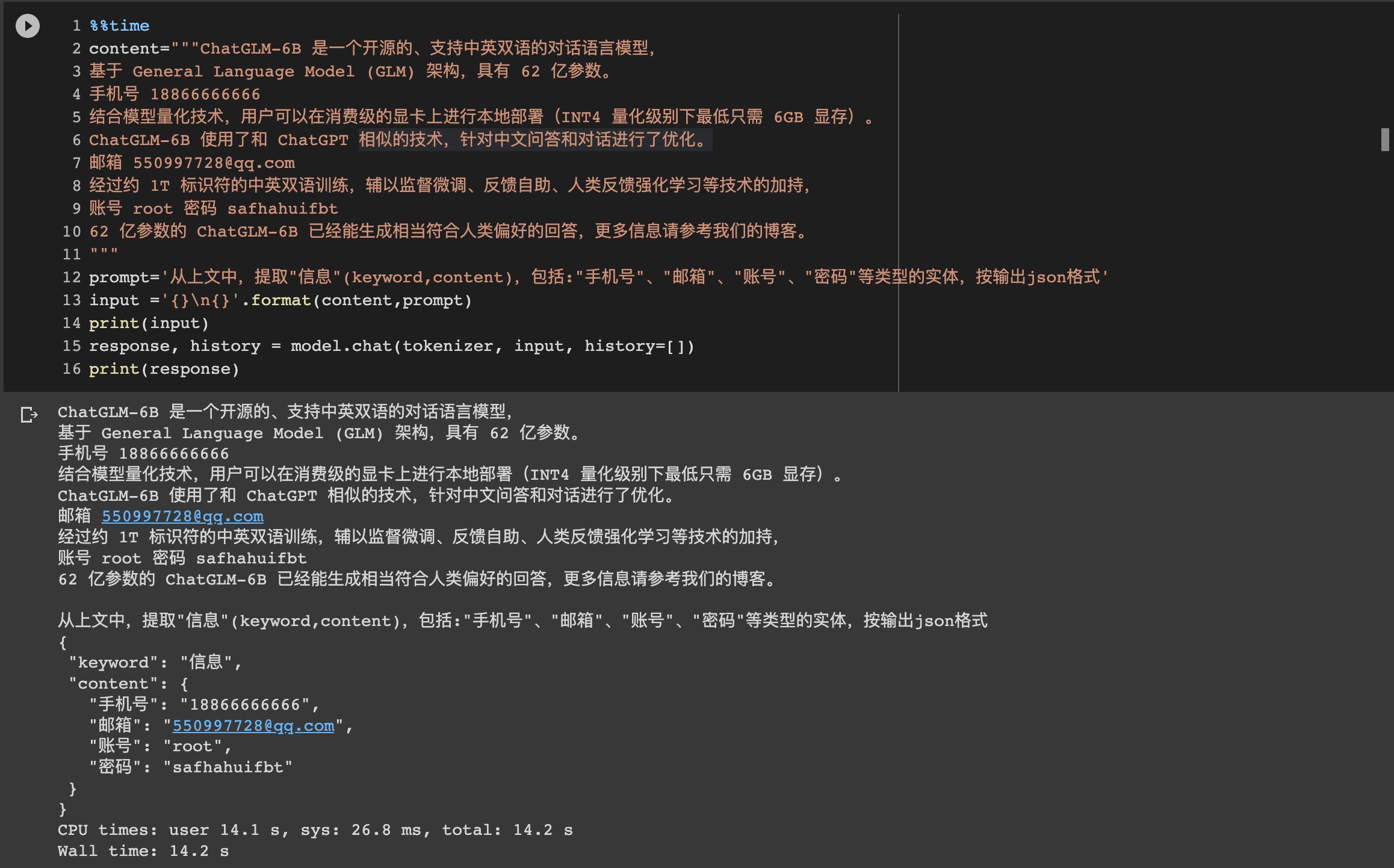
content="""ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,
基于 General Language Model (GLM) 架构,具有 62 亿参数。
手机号 18866666666
结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。
ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。
邮箱 [email protected]
经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,
账号 root 密码 safhahuifbt
62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答,更多信息请参考我们的博客。
"""
prompt='从上文中,提取"信息"(keyword,content),包括:"手机号"、"邮箱"、"账号"、"密码"等类型的实体,输出json格式内容'input='{}\n\n{}'.format(content,prompt)print(input)
response, history = model.chat(tokenizer,input, history=[])print(response)
6.2 输出校验
返回结果为合法json
import json
json.loads(response)

7. 成本估算
7.1 单价计算
- 腾讯云T4 GPU 公有云成本在
2500/月, 1/4卡975元/月 - 测试400词,抽取耗时
15s(批处理理论上会更快N倍) ,26.6 Token/s。

满载处理量= 30天x24小时x60分钟x60秒x26Token=6894w Token/月
Token成本=6894w/975元= 7w/元
按照6.9的汇率折算 ,
487k Token/1
美元 ,既
0.002$/1k
Tokens

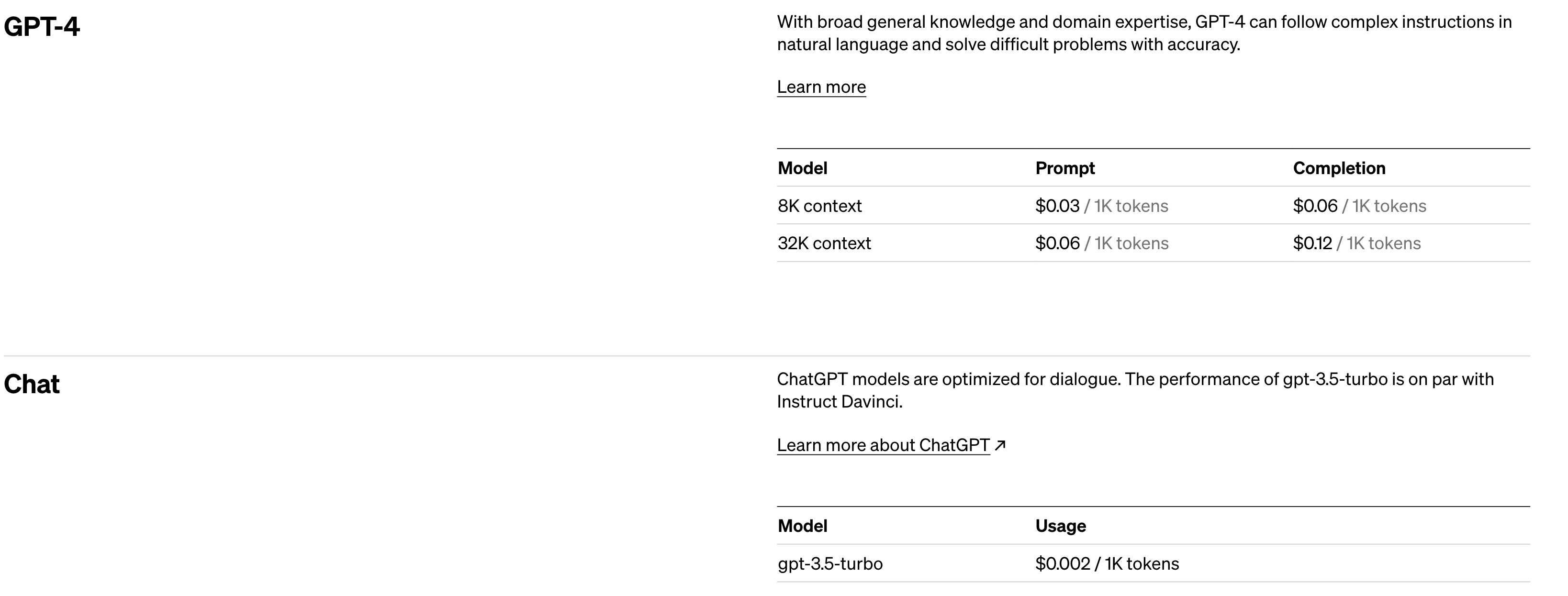
7.2 ChatGPT价格对比
与
chatgpt3.5,
gpt4相比, 价格与
chatgpt 3.5持平 ,远低于
gpt40.03$/1ktoken 的价格。
此处使用粗略估算,理论上有5倍以上的能效优化空间,所以成本远应远低于gpt
8. 总结
上文仅对ChatGLM-6B模型进行简单尝试,稍许改造即能满足日常使用,另外上述成本估算仅供参考,以实际使用为准。目前得知,ChatGLM 1300 亿参数版本正在测试,命名为GLM-130B,相信在未来,将会在更多复杂场景上得到应用。
9. 参考
版权归原作者 罗杰海贼团 所有, 如有侵权,请联系我们删除。