
事务
目的:保证数据的最终一致性## 事务的目的
事务的4大特性(ACID)
1.原子性(Atomicity):由undo log日志来保证
2.一致性(Consistency):使用事务的最终目的,由业务代码正确逻辑保证,比如错误的try-catch
3.隔离性(Isolation):在事务并发执行时,他们内部的操作不能互相干扰
4.持久性(Dur©bility):一旦提交了事务,对数据库的改变就应该是永久性的。由redo log日志来保证
事务的隔离级别(4种)
事务隔离级别:从小到大,级别越高,数据直接影响越小
1.read uncommit 读未提交
2.read commit 读已提交:oracle 数据库默认
3.repeatable read 可重复度 :mysql 数据库默认
4.serializble 串行
每个隔离级别的缺点:
1.读未提交:读到了没有提交的数据,即脏读,性能很高,但不会使用
2.读已提交:不可重复读,在当前事务中,(由于其他事务已提交)每次读取到的数据都不一样,例如,在一个方法中,第一次读取时值是100,当其他事务提交后,将该值改为200,那么在该事务中再次读取时,就会变成200。
3.可重复读:幻读,脏写,在当前事务中,不管其他事务怎么提交数据,每次读到的值都一样。
4.串行:阻塞,效率低,当前事务未执行完,其余事务都得排队等待。

MVCC机制(多版本并发控制)(undo日志版本链)
引申:写时复制 机制(copy on write ):更新副本,然后进行替换。
这样机制优点是:读写分离,这样不管读操作和写操作,都可以支持并发。
虽然在替换过程中,可能会读到旧数据,但是在并发场景下可以接收
MVCC :undo.log日志版本链
流程实现:
数据库在每次插入数据时,每条数据都有对应的事务id和回滚指针
1.数据每次操作后,会在undo.log 日志中插入一条回滚数据,并标记事务和回滚指针
2.在每次写的时候,都是先复制,再修改。
读已提交,指的就是每次都读最新提交的数据
可重复读,指的是每次都读和当前事务绑定的数据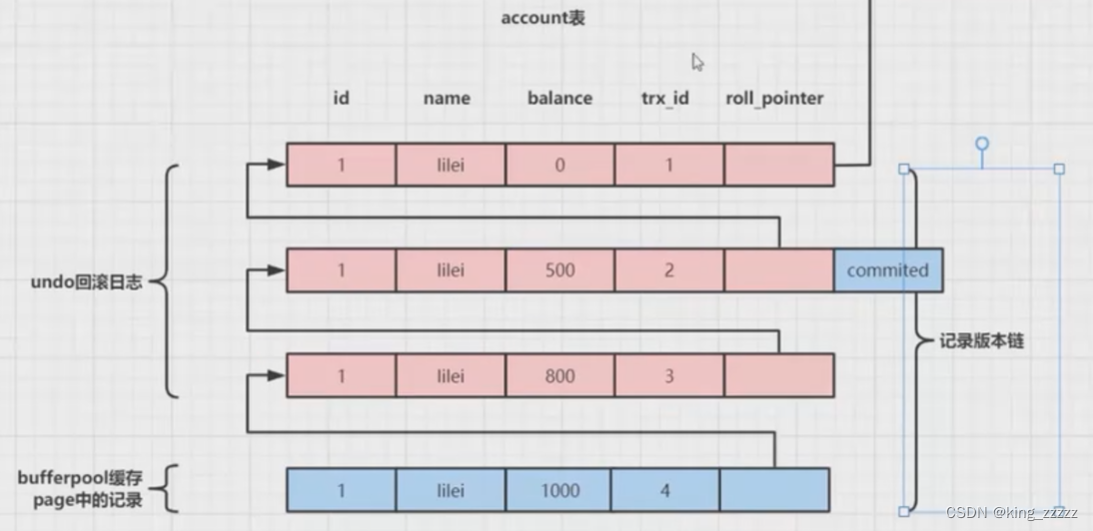
暴露问题:
可重复读:脏写问题
原因:可重复读会读到之前版本的数据,利用之前的数据进行操作后,来修改数据库,这样就会出现脏写的问题
解决:
1.利用乐观锁
数据库增加版本字段,每次查询和修改时带上版本号,然后可以在业务代码中来循环重试根据版本号进行修改,直到修改成功。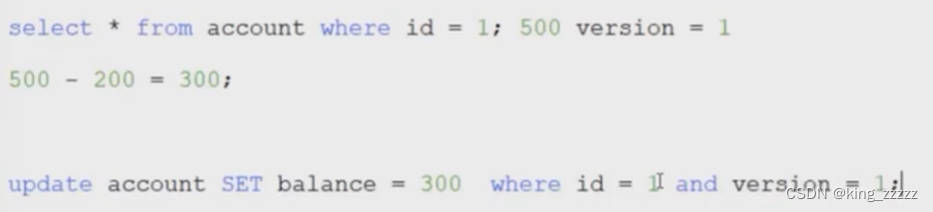
2.直接数据库进行操作,这样会加悲观锁
mysql执行过程(持久性的实现)
redo日志(Buffer Pool缓存池)
1.写入数据时,InnoDB 会先将数据先放到 Buffer Pool缓存池
2.然后将要回滚的数据写入到undo日志
3.同步的会写到 redo日志(先写到redori值缓存,然后再写的redo 日志磁盘文件)(写入redo 日志成功,就表示数据写成功)
4.同时会写到binlog日志
5.再将缓存数写入到**.ibd数据**文件
写入redo 日志和写入 ibd 文件的区别
顺序写:顺序写的效率远高于随机写
rdeo 日志是顺序写,每次都是在文件末尾追加
ibd文件是随机写,每张表都有对应的ibd文件,所以无法顺序写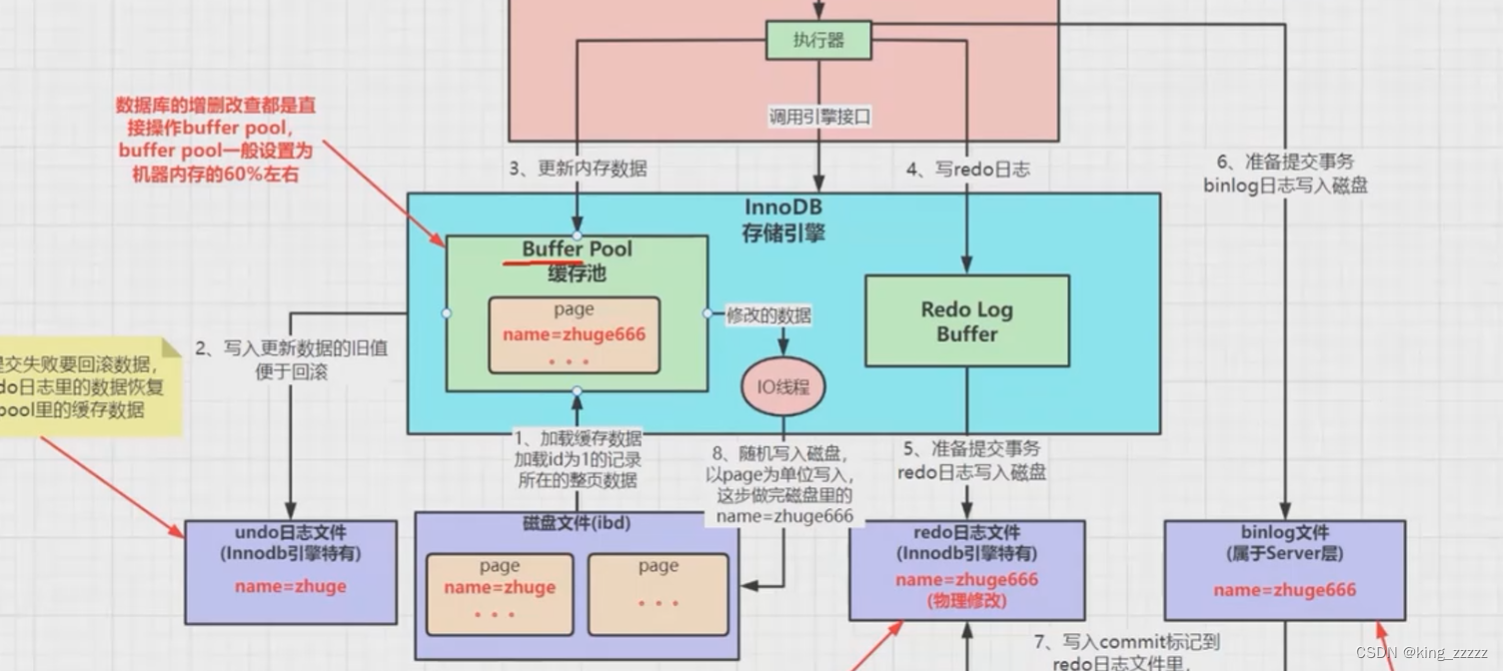
查询方法需要事务吗?
查询方法中有多条查询语句,若隔离级别时可重复读,则需要开启事务
基于时间维度,对于统计报表等来讲,使用事务可以读到同一时间点的数据。这样数据的一致性会更高
对于高并发场景下的公司,一般使用读已提交。
对于传统公司,需要更多报表统计的公司,使用可重复度,保证同一时间点的数据一致性。
事务优化
长事务:
优化方案:
1.查询放到事务外
2.处理数据过多,则拆分多个事务处理
3.先insert后update,更新update操作放到事务后面,insert 放到前面(update 语句其他其他事务可能会用到)
4.应用侧保证一致:即放弃事务,回滚操作等放到代码中实现
版权归原作者 LeBron.JG 所有, 如有侵权,请联系我们删除。