
Apache Hive 系列文章
1、apache-hive-3.1.2简介及部署(三种部署方式-内嵌模式、本地模式和远程模式)及验证详解
2、hive相关概念详解–架构、读写文件机制、数据存储
3、hive的使用示例详解-建表、数据类型详解、内部外部表、分区表、分桶表
4、hive的使用示例详解-事务表、视图、物化视图、DDL(数据库、表以及分区)管理详细操作
5、hive的load、insert、事务表使用详解及示例
6、hive的select(GROUP BY、ORDER BY、CLUSTER BY、SORT BY、LIMIT、union、CTE)、join使用详解及示例
7、hive shell客户端与属性配置、内置运算符、函数(内置运算符与自定义UDF运算符)
8、hive的关系运算、逻辑预算、数学运算、数值运算、日期函数、条件函数和字符串函数的语法与使用示例详解
9、hive的explode、Lateral View侧视图、聚合函数、窗口函数、抽样函数使用详解
10、hive综合示例:数据多分隔符(正则RegexSerDe)、url解析、行列转换常用函数(case when、union、concat和explode)详细使用示例
11、hive综合应用示例:json解析、窗口函数应用(连续登录、级联累加、topN)、拉链表应用
12、Hive优化-文件存储格式和压缩格式优化与job执行优化(执行计划、MR属性、join、优化器、谓词下推和数据倾斜优化)详细介绍及示例
13、java api访问hive操作示例
文章目录
本文主要介绍了hive的架构、组件、数据模型、读写机制等内容。
本文分为2个部分,即架构及组件介绍、读写文件机制。
本文图片部分来源于互联网。
一、架构及组件介绍
1、hive整体架构图

2、Hive组件
- 用户接口 包括 CLI、JDBC/ODBC、WebGUI。 CLI(command line interface)为shell命令行 Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议 WebGUI是通过浏览器访问Hive
- 元数据存储 通常是存储在关系数据库如 mysql/derby中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
- Driver驱动程序 包括语法解析器、计划编译器、优化器、执行器 完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成 生成的查询计划存储在 HDFS 中,并在随后有执行引擎调用执行
- 执行引擎 Hive本身并不直接处理数据文件,是通过执行引擎处理 当下Hive支持MapReduce、Tez、Spark3种执行引擎
3、Hive数据模型(Data Model)
用来描述数据、组织数据和对数据进行操作
Hive的数据模型类似于RDBMS库表结构,此外还有自己特有模型
Hive中的数据可以在粒度级别上分为三类:Table 表、Partition分区、Bucket 分桶。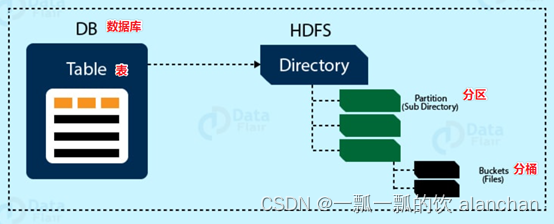
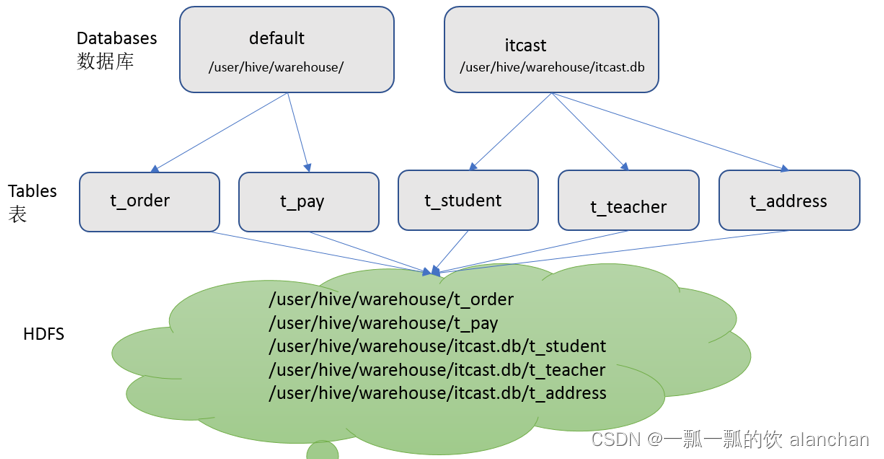
1)、Databases
Hive作为一个数据仓库,包含数据库(Schema),每个数据库下面有各自的表组成。默认数据库default。
Hive的数据都是存储在HDFS上的,默认有一个根目录,在hive-site.xml中,由参数hive.metastore.warehouse.dir指定。默认值为/user/hive/warehouse。
因此,Hive中的数据库在HDFS上的存储路径为:${hive.metastore.warehouse.dir}/databasename.db
比如,名为test的数据库存储路径为:/user/hive/warehouse/test.db
2)、Tables
Hive表与关系数据库中的表相同。Hive中的表所对应的数据是存储在Hadoop的文件系统中,而表相关的元数据是存储在RDBMS中。
在Hadoop中,数据通常保存在HDFS中,尽管它可以保存在任何Hadoop文件系统中,包括本地文件系统或S3。
Hive有两种类型的表:
- Managed Table内部表、托管表
- External Table外部表 创建表时,默是内部表。Hive中的表的数据在HDFS上的存储路径为:${hive.metastore.warehouse.dir}/databasename.db/tablename 比如,test的数据库下t_user表存储路径为:/user/hive/warehouse/test.db/t_user
3)、Partitions
Partition分区是hive的一种优化手段表。
分区是指根据分区列(例如“日期day”)的值将表划分为不同分区。这样可以更快地对指定分区数据进行查询。
分区在存储层面上的表现是table表目录下以子文件夹形式存在
一个文件夹表示一个分区。子文件命名标准:分区列=分区值
Hive还支持分区下继续创建分区,所谓的多重分区。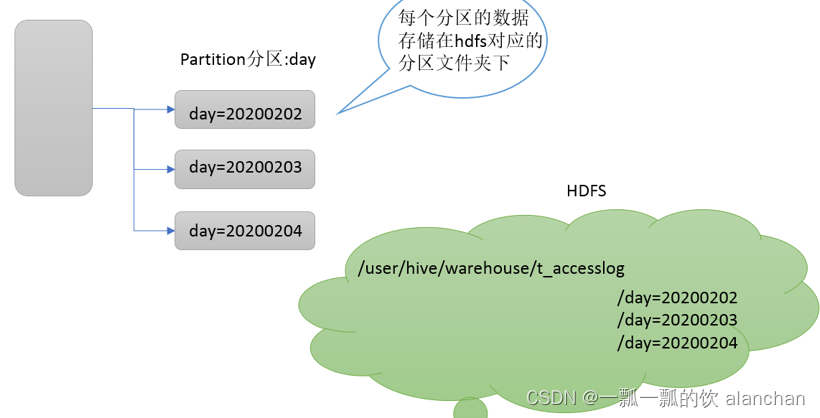
4)、Buckets
Bucket分桶表是hive的一种优化手段表。
分桶是指根据表中字段(例如“编号ID”)的值,经过hash计算规则将数据文件划分成指定的若干个小文件。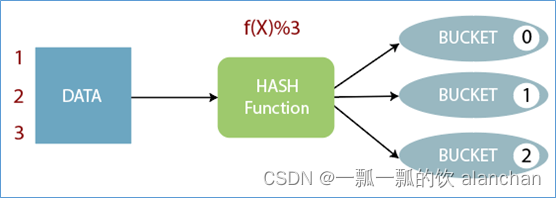
分桶规则:hashfunc(ID) % 桶个数,余数相同的分到同一个文件。
分桶的好处是可以优化join查询和方便抽样查询。Bucket分桶表在hdfs中表现为同一个表目录下数据根据hash散列之后变成多个文件。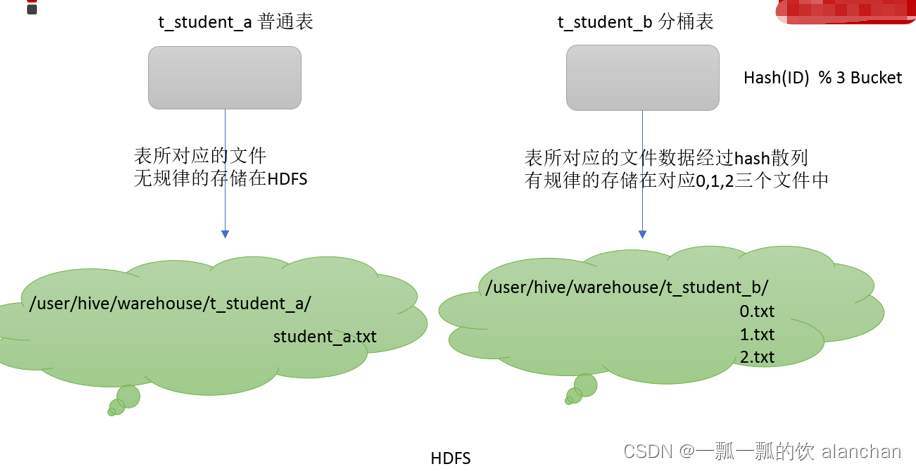
二、Hive读写文件机制
1、SerDe作用
SerDe是Serializer、Deserializer的简称,目的是用于序列化和反序列化。序列化是对象转化为字节码的过程;而反序列化是字节码转换为对象的过程。
Hive使用SerDe(和FileFormat)读取和写入行对象。
# 读过程
HDFS files --> InputFileFormat --><key,value> --> Deserializer(反序列化) --> Row Object
# 写过程
Row Object --> serializer(反序列化) --><key,value> --> OutputFileFormat --> HDFS files
# 需要注意的是,“key”部分在读取时会被忽略,而在写入时key始终是常数。基本上行对象存储在“value”中。# 通过desc formatted tablename查看表的相关SerDe信息,SerDe默认(org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe)如下:0: jdbc:hive2://server4:10000> desc formatted t_user;
INFO : Compiling command(queryId=alanchan_20221017153821_c8ac2142-aacf-479c-a8f2-e040f2f791cb): desc formatted t_user
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial =false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:col_name, type:string, comment:from deserializer), FieldSchema(name:data_type, type:string, comment:from deserializer), FieldSchema(name:comment, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=alanchan_20221017153821_c8ac2142-aacf-479c-a8f2-e040f2f791cb); Time taken: 0.024 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=alanchan_20221017153821_c8ac2142-aacf-479c-a8f2-e040f2f791cb): desc formatted t_user
INFO : Starting task [Stage-0:DDL]in serial mode
INFO : Completed executing command(queryId=alanchan_20221017153821_c8ac2142-aacf-479c-a8f2-e040f2f791cb); Time taken: 0.037 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+-------------------------------+----------------------------------------------------+----------------------------------------------------+
| col_name | data_type | comment |
+-------------------------------+----------------------------------------------------+----------------------------------------------------+
|# col_name | data_type | comment ||id| int ||| name | varchar(255)||| age | int ||| city | varchar(255)|||| NULL | NULL ||# Detailed Table Information | NULL | NULL || Database: |test| NULL || OwnerType: |USER| NULL || Owner: | alanchan | NULL || CreateTime: | Mon Oct 1714:47:08 CST 2022| NULL || LastAccessTime: | UNKNOWN | NULL || Retention: |0| NULL || Location: | hdfs://HadoopHAcluster/user/hive/warehouse/test.db/t_user | NULL || Table Type: | MANAGED_TABLE | NULL || Table Parameters: | NULL | NULL ||| COLUMN_STATS_ACCURATE |{\"BASIC_STATS\":\"true\",\"COLUMN_STATS\":{\"age\":\"true\",\"city\":\"true\",\"id\":\"true\",\"name\":\"true\"}}||| bucketing_version |2||| numFiles |0||| numRows |0||| rawDataSize |0||| totalSize |0||| transient_lastDdlTime |1665989228||| NULL | NULL ||# Storage Information | NULL | NULL || SerDe Library: | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | NULL || InputFormat: | org.apache.hadoop.mapred.TextInputFormat | NULL || OutputFormat: | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | NULL || Compressed: | No | NULL || Num Buckets: | -1 | NULL || Bucket Columns: |[]| NULL || Sort Columns: |[]| NULL || Storage Desc Params: | NULL | NULL ||| field.delim | , ||| serialization.format | , |
+-------------------------------+----------------------------------------------------+----------------------------------------------------+
35 rows selected (0.081 seconds)
2、Hive读写文件流程
- 读过程 HDFS files --> InputFileFormat --> <key,value> --> Deserializer(反序列化) --> Row Object Hive读取文件机制 首先调用InputFormat(默认TextInputFormat),返回一条一条kv键值对记录(默认是一行对应一条记录)。 然后调用SerDe(默认LazySimpleSerDe)的Deserializer,将一条记录中的value根据分隔符切分为各个字段。
- 写过程 Row Object --> serializer(反序列化) --> <key,value> --> OutputFileFormat --> HDFS files Hive写文件机制 将Row写入文件时,首先调用SerDe(默认LazySimpleSerDe)的Serializer将对象转换成字节序列 然后调用OutputFormat将数据写入HDFS文件中。
3、SerDe相关语法
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-RowFormats&SerDe
在Hive的建表语句中,和SerDe相关的语法为:
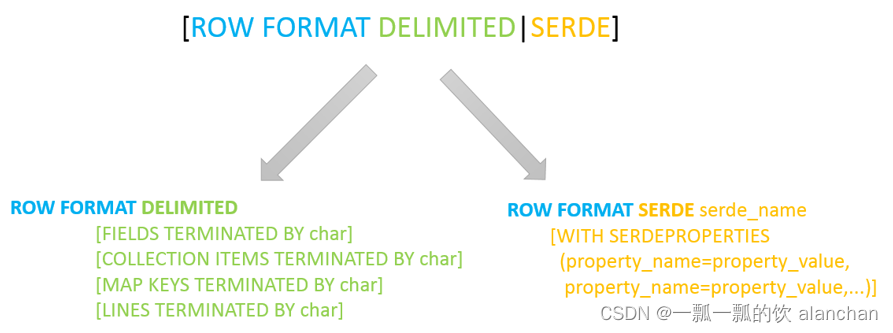
其中ROW FORMAT是语法关键字,DELIMITED和SERDE二选其一。
如果使用delimited表示使用默认的LazySimpleSerDe类来处理数据。如果数据文件格式比较特殊可以使用ROW FORMAT SERDE serde_name指定其他的Serde类来处理数据,甚至支持用户自定义SerDe类。
1)、LazySimpleSerDe分隔符指定
LazySimpleSerDe是Hive默认的序列化类,包含4种子语法,分别用于指定字段之间、集合元素之间、map映射 kv之间、换行的分隔符号。在建表的时候可以根据数据的特点灵活搭配使用。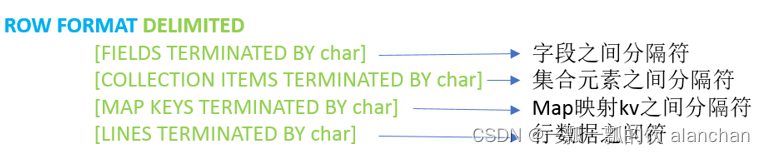
2)、默认分隔符
hive建表时如果没有row format语法。此时字段之间默认的分割符是’\001’,是一种特殊的字符,使用的是ascii编码的值。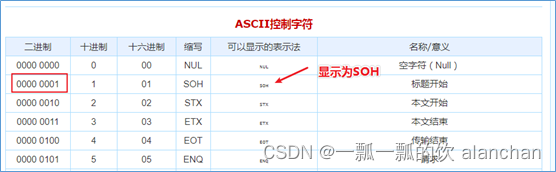
在vim编辑器中,连续按下Ctrl+v/Ctrl+a即可输入’\001’ ,显示^A
在一些文本编辑器中将以SOH的形式显示:
4、Hive数据存储路径
1)、默认存储路径
Hive表默认存储路径是由${HIVE_HOME}/conf/hive-site.xml配置文件的hive.metastore.warehouse.dir属性指定。默认值是:/user/hive/warehouse。
在该路径下,文件将根据所属的库、表,有规律的存储在对应的文件夹下。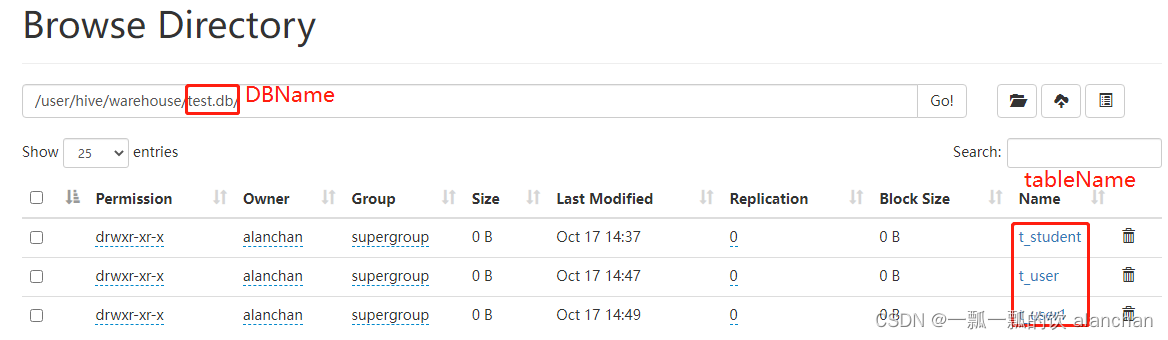
2)、指定存储路径
在Hive建表的时候,可以通过location语法来更改数据在HDFS上的存储路径,使得建表加载数据更加灵活方便。
语法:LOCATION ‘<hdfs_location>’。
对于已经生成好的数据文件,使用location指定路径将会很方便。
以上,介绍了hive的整体架构、相关组件、数据模型等,同时也介绍 了hive的读写文件流程、机制等相关内容。
版权归原作者 一瓢一瓢的饮 alanchan 所有, 如有侵权,请联系我们删除。