
斯坦福大学的FlashFFTConv优化了扩展序列的快速傅里叶变换(FFT)卷积。该方法引入Monarch分解,在FLOP和I/O成本之间取得平衡,提高模型质量和效率。并且优于PyTorch和FlashAttention-v2。它可以处理更长的序列,并在人工智能应用程序中打开新的可能性。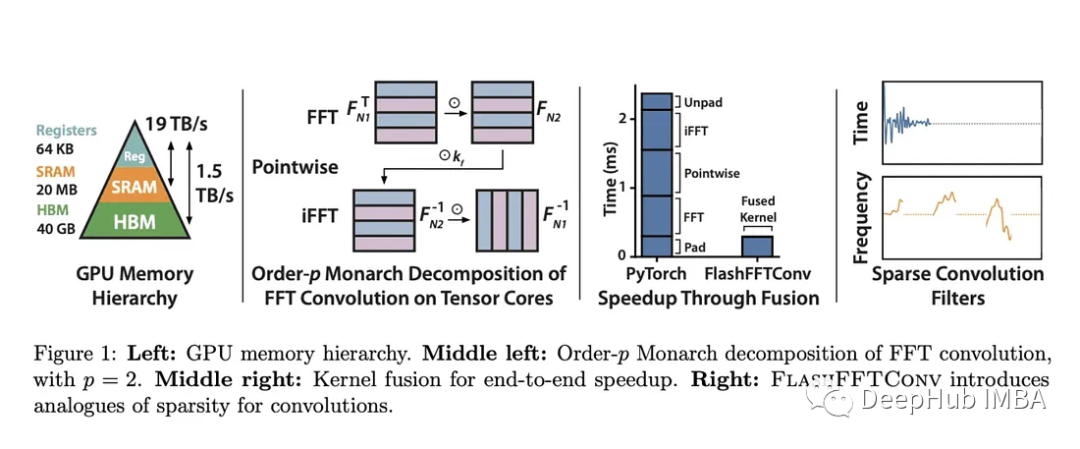
处理长序列的效率一直是机器学习领域的一个挑战。卷积神经网络(cnn)最近作为序列建模的关键工具获得了突出的地位,在从自然语言处理到计算机视觉和遗传学的各个领域都提供了一流的性能。尽管卷积序列模型具有卓越的品质,但在速度方面仍落后于Transformers 。
快速傅里叶变换(FFT)卷积算法,通过在频域内计算输入序列和核之间的卷积,可以解决上面卷积的问题。但是FFT卷积在执行时间方面有非常大的问题。
斯坦福大学的研究人员正在努力优化现代FFT卷积方法:
为较短序列优化FFT卷积是一种常见的做法,涉及跨多个批次重用内核滤波器和FFT的预计算。这种方法允许跨批处理和核的并行化,而核融合使中间卷积输出能够被有效地缓存。
但是随着序列长度的增长,出现了两个主要障碍。1、FFT卷积不能充分利用当代加速器中专用的矩阵-矩阵乘法单元。2、当序列超过SRAM的容量时,核融合因为需要昂贵的I/O操作变得不切实际。
而斯坦福大学的研究人员引入了FlashFFTConv,利用FFT的Monarch分解来优化扩展序列的卷积。这种分解将FFT重新想象为一系列矩阵-矩阵乘法运算,并选择分解顺序,表示为“p”。
这项研究提供了使用基于序列长度的直接成本模型来优化GPU中FLOP和I/O成本的“p”的见解。这种分解不仅有利于较长序列的核融合,而且还减少了必须驻留在SRAM中的序列数据量。FlashFFTConv可以有效地处理从256到惊人的400万个字符的序列。FlashFFTConv利用实值FFT算法并优化零填充输入的矩阵乘法操作,可以将FFT操作长度减少高达50%。
此外,FlashFFTConv还提供了一个通用的框架:部分卷积和频率稀疏卷积。这些技术类似于Transformers中的稀疏和近似注意力机制,可以显著降低内存使用和运行时间。
FlashFFTConv加速FFT卷积,可以提高卷积序列模型的质量和效率。对于相同的计算,它还可以实现指标的改进,例如Hyena-GPT-s的perplexity降低2.3,M2-BERT-base的平均GLUE分数提高3.3。这种性能提升类似于将模型的参数大小增加一倍。
FlashFFTConv在效率方面也很出色,与PyTorch相比,它提供了高达7.93倍的效率和高达5.6倍的内存节省。并且这些效率的提高在很长的序列长度范围内都持续存在。由于降低了FLOP成本,它在2K或更长时间序列的计算时间上超过了FlashAttention-v2,实现了高达62.3%的端到端FLOP使用率。
FlashFFTConv使模型能够处理更长的序列,打破了以前认为不可逾越的障碍。它已经完成了Path-512任务,这是一项序列长度为256K的高分辨率图像分类任务,并使用部分卷积将HyenaDNA扩展到惊人的400万序列长度。
斯坦福大学的FlashFFTConv在优化长序列的FFT卷积方面取得了非常巨大的进步。这项突破性技术有望重塑卷积序列模型的格局,提高它们的质量和效率。
以下是一些相关的信息:
官方发布的博客:
https://hazyresearch.stanford.edu/blog/2023-11-13-flashfftconv
论文地址:
https://arxiv.org/abs/2311.05908
github代码