
第一类:PEFT类论文
(我还挺喜欢的,不知道自己什么时候可以搞出这种工作
(为什么中英文穿插,利于自己写论文:)
FAME-ViL: Multi-Tasking Vision-Language Model for Heterogeneous Fashion Tasks
1.这篇论文属于 PEFT类论文,即不训练clip,参数效率提高类
2.这篇论文主打 利用一个 unified 模型(统一)来解决大部分的 fashion领域任务,文中说即多任务学习。
3.模型主要三个模块:文本encoder 和 视觉 encoder (两者都是之间由clip模型中的参数初始化的)以及一系列本文提出的adapter(嗯,就两个)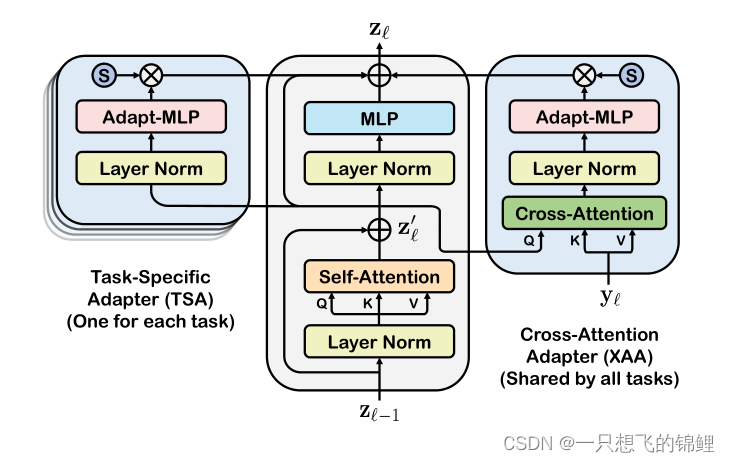
4. 接下来的多teacher 训练,也就是为了多任务提出的训练方法嘿嘿 ,这一段说的很清楚了,感觉不是很优雅,特别复杂。

5. 实验模块 没有细看,但是那个比较图是真的好看呀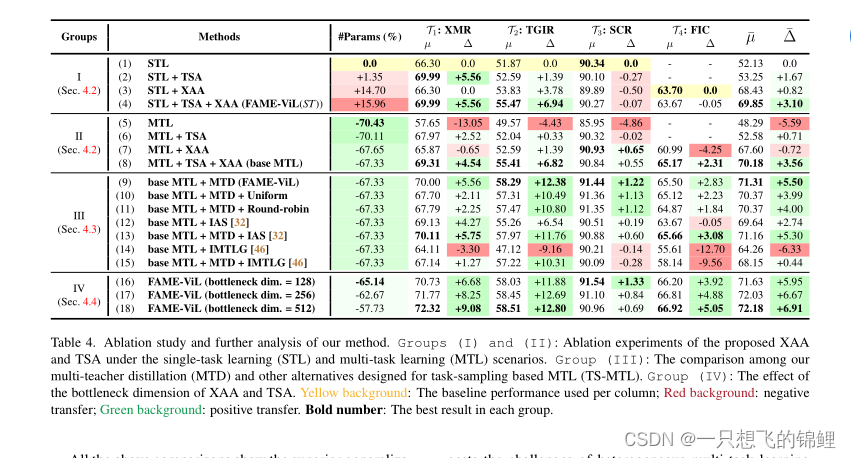
- 总结:超少的系数(基于clip)的一个统一架构(提出了两个adapter)能够解决多个fashion类任务,且效果很好,训练方法是使用的多teacher蒸馏。文中说这样效果好是因为 inter-task可以互相交流了,而且他这个方式解决了原来MTL的一些问题。 This is made possible by the proposed task-versatile architecture with cross-attention adapters and task-specific adapters, and a scalable multi-task training pipeline with multi-teacher distillation7.其他要点:这个知识是每个论文可以学习的嘿嘿

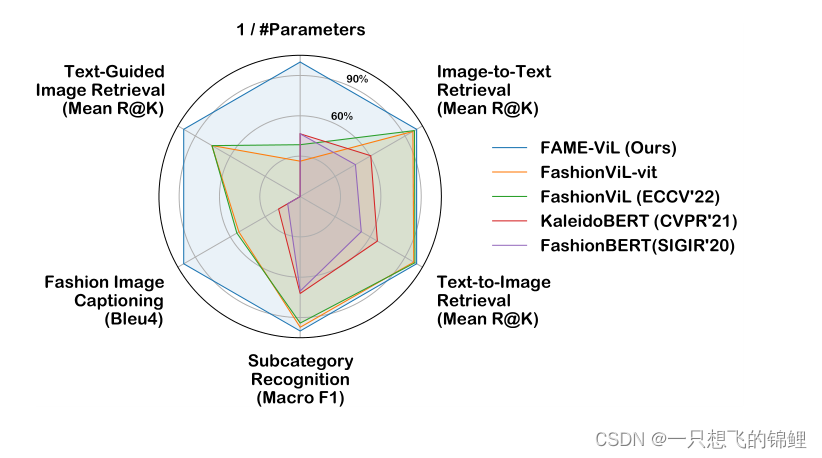
本文转载自: https://blog.csdn.net/m0_37847767/article/details/130085918
版权归原作者 一只想飞的锦鲤 所有, 如有侵权,请联系我们删除。
版权归原作者 一只想飞的锦鲤 所有, 如有侵权,请联系我们删除。