

我怀疑有些人会指责我设置引诱性标题。
其他人会说,这并不是真正的范围——大多数人在最初的人工智能尝试中都会失败,但这并不重要,学习是值得的。在某种程度上,两者都是对的——但我认为为什么企业会失败是值得探索的,并且可能让我们的一些读者至少在他们走得太远之前重新评估。
企业人工智能战略将在2024年失败,因为它们专注于模型,而不是数据。为基础模型选择什么远不如训练它所依据的数据重要。如果您的数据和数据基础设施建立在错误的基础上,那么您对向量数据库的选择就无关紧要了。
这似乎是不言而喻的,但我们与企业交谈,真正的大企业有很多聪明人,我们可以肯定地告诉你,组织动力导致其中一些企业认为模型下降而不是数据上升。这是一个严重的错误。

你必须从数据开始。构建适当的数据基础架构。然后想想你的模型。
如果考虑过程是购买一些 GPU 并重用现有的数据基础设施,那么您将失败。您现有的数据基础架构可能是一堆 SAN/NAS 设备。它们无法扩展。结果是,您将对公司数据的一小部分进行训练,并且您将获得一小部分价值。链的强度与其最薄弱的环节一样快,而您的 AI/ML 基础设施的速度仅与最慢的组件一样快。如果您使用 GPU 训练机器学习模型,那么您的薄弱环节可能是您的存储解决方案。Keith Pijanowski 称其为“饥饿的 GPU 问题”。当您的网络或存储解决方案无法以足够快的速度将训练数据提供给训练逻辑以充分利用 GPU 时,就会出现 GPU 匮乏问题。
我们有点超前了。让我们从数据应该是什么样子开始。
- 完整且正确:如果您愿意,可以将其称为“干净”数据。清洁度级别会显著影响 中LLMs的基础计算和向量表示。高质量的语料库对于微调和 RAG 至关重要。它必须包括代表组织正确和真实表示的文档/内容,以生成正确的输出。这对培训效率有影响。不完整的数据集会阻碍模型的学习过程,导致训练效率低下和对新数据的泛化能力差。最后,还有偏置放大。不正确的数据,尤其是系统性偏差,可能导致模型内偏差的放大,影响公平性和道德考虑。
- 扩展:这需要获得足够的数据。如果您的基础结构导致您人为地限制可以使用的数据量和/或类型,它将限制您生成的价值。例如,在检索增强生成中,拥有大量数据允许LLM从庞大的信息库中提取数据,使其能够提供更细致和更明智的答案,类似于咨询藏书丰富的图书馆。这同样适用于使用 AI 进行日志分析。是的,大多数情况下,该值位于最近的数据中,但这并不意味着该值不会扩展到较旧、较大的数据窗口。如果基础结构决策限制了可以分析的数据量,则会影响模型输出。
- 新近度:虽然我们刚才谈到了更长的窗口和更多的数据,但这显然是有限制的。该数据不能过时以至于不再有效。特定领域的专业知识在这里很重要。例如,对于技术、金融或时事等动态字段,超过 6-12 个月的数据可能被认为太旧。相比之下,对于稳定或历史领域,几年前的数据仍然很有价值(例如,关于伯罗奔尼撒战争的新信息有限)。必须使数据的年龄与LLM模型的特定用例和相关域的变化率保持一致。
- 一致性:数据一致性是指数据集中数据的一致性、准确性和可靠性。它确保数据在其从收集到处理和分析的整个生命周期中保持不变,为 AI 模型提供稳定和连贯的基础,以便从中学习和做出预测。因为LLMs,不一致的数据会破坏语言模式的学习,导致文本生成或理解不准确。对于像拓扑数据分析这样的方法,它分析了数据的形状和结构,不一致可能会扭曲拓扑见解,从而影响复杂数据集的解释。从本质上讲,一致的数据类似于建筑物的稳定基础,确保人工智能的“结构”站稳脚跟并正常运行。
- 唯一性:数据唯一性对 an LLM 很重要,因为它确保了多样化的训练集,增强了模型泛化和理解不同上下文的能力。独特的数据点可防止对重复信息的过度拟合,从而LLM能够更广泛地理解并生成更具创造性、更准确的响应。它还支持对模型和 RAG 进行微调。
这是“干净”数据的有效起点。接下来是您的数据基础架构选择。数据基础设施必须支持您的数据,而不是限制数据。您的数据基础架构不能“强迫”您只查看行和列中的数据。您的数据基础架构无法限制您可以从视频或日志文件中收集的内容。它必须启用。
下面是现代数据湖的参考体系结构。将其用于 AI 等。
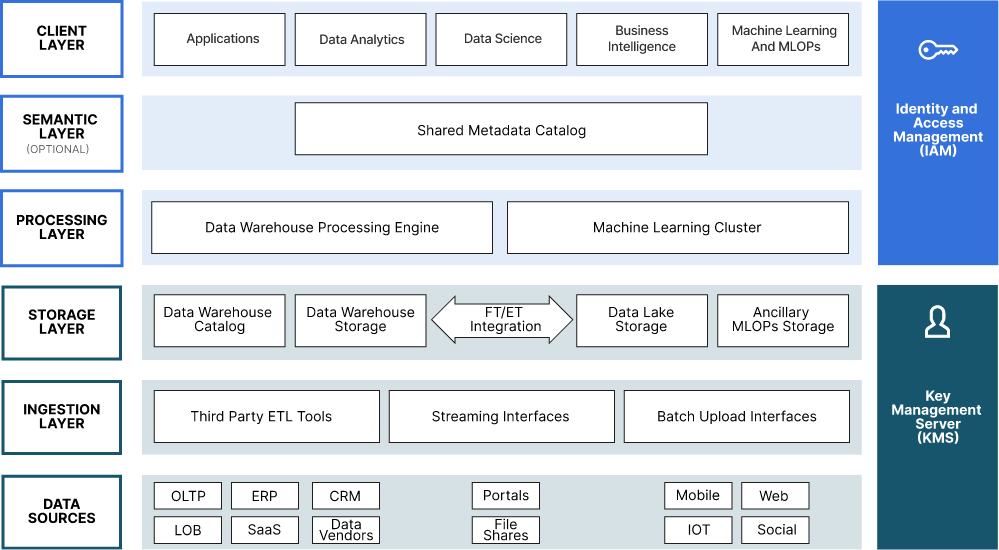
如果你愿意,你可以开始用徽标来填充它。使用像 MinIO 这样的工具的优势之一是整个生态系统将开箱即用。MLflow、Tensorflow、Kubeflow、PyTorch、Ray - 你明白了。
这里的重点是,您希望将所有数据都放在一个存储库中(适当复制)。它支持更好的治理、访问控制和安全性。
这需要高度可扩展的东西,并且可以处理各种类型的数据。那将是一个对象存储(一个现代的,同样,电器在这里没有太多的实用性)。
您需要一些高性能的东西(吞吐量和 IOPS),而在这里,现代对象存储就是答案。你想要一些简单的东西 - 因为规模需要简单。你想要一些软件定义的东西。您需要的秤需要商用硬件才能实现经济效益。电器是一个糟糕的选择。
你想要一些你控制的东西。这是你的数据,它是你整个人工智能工作所依赖的基础。你不能把它外包给可能在几个季度内与你竞争的人。构建您控制的 AI 现代数据湖。
你想要一些云原生的东西。Kubernetes 是云运营模式的操作系统。容器化和编排原生的数据基础架构实际上是一项要求。
这需要一个可以跨数据中心和地理位置复制(主动-主动)的解决方案。
可能需要在国家/地区存储一些数据,这也需要满足。重点应该很清楚,数据需求定义了基础设施要求,并为框架/模型提供了信息。反之则不然。从数据出发并努力工作的公司将取得成功。这是构建功能性人工智能战略的基础。框架和模型很重要,但阿尔法和欧米茄是数据。我们正在为数据第一的世界而建设,事实上,我们已经这样做了十年的大部分时间。这就是为什么 AI 生态系统与我们一起开箱即用的原因。要了解更多信息,请查看我们的 AI 和 ML 解决方案页面。它深入探讨了使我们成为全球 AI 架构师选择的特性、功能和性能。
版权归原作者 MinIO官方账号 所有, 如有侵权,请联系我们删除。