
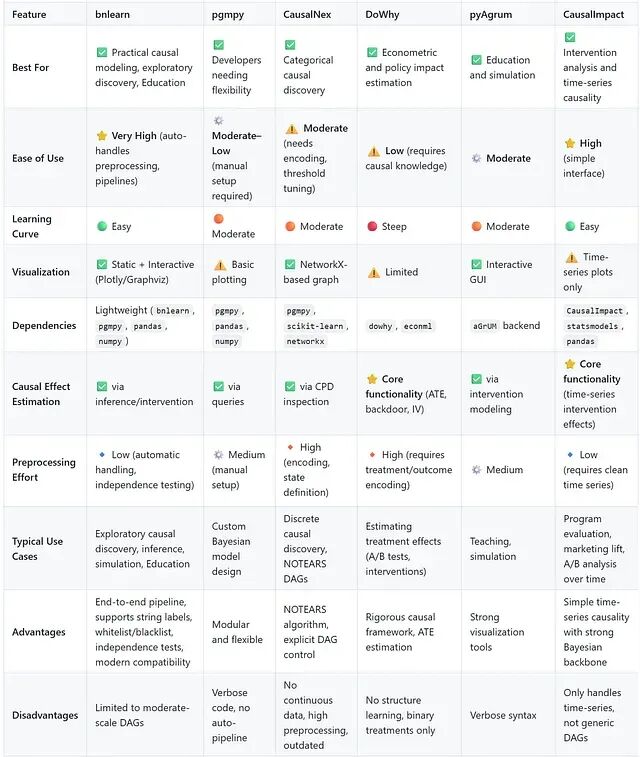
Python 生态里能用的因果库有很多选哪个往往要看你对模型的理解程度,以及项目对“可解释性”的要求。这篇文章将对比了六个目前社区中最常用的因果推断库:Bnlearn、Pgmpy、CausalNex、DoWhy、PyAgrum 和 CausalImpact。
贝叶斯因果模型
在因果推断里所有变量可以粗略分成两种:驱动变量(driver variables)和乘客变量(passenger variables)。驱动变量会直接影响结果,而乘客变量虽然跟结果有关但并不直接影响结果。区分这两者是整个因果分析的关键。比如在预测性维护或设备故障分析里,如果能识别出“导致故障”的那几个变量,后续的监控与优化策略就能有针对性地落地。
有时候,看似无关的变量其实藏着重要的效应。比如说假设某个工厂的发动机故障率在不同地区差异很大,你可能认为这是地理差异,其实真正的原因可能是工厂里湿度、保养周期或人员经验这样的隐含驱动因子。因果推断的价值就在这里——它帮助区分“看上去相关”和“真正原因”的区别。
相比纯预测模型,因果推断更像是在回答“为什么”,而不是“多少”。通过找出系统中真正起作用的变量,才能解释模型的行为,也才能对系统做出有效干预。
数据集与整体实验思路
为了让对比更直观,所有实验都使用相同的数据:Census Income 数据集。这个经典的数据集包含 48,842 条记录和 14 个变量,多数为离散特征。目标也很简单:拥有研究生(postgraduate)学历是否能显著提高年收入超过 50K 美元的概率?
下面的代码用于载入和清理数据。连续变量与敏感特征(如性别、种族等)被移除,以便专注在离散特征的因果结构学习上。
# 安装
pip install datazets
# 导入库
import datazets as dz
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 导入数据集并删除连续型与敏感特征
df = dz.import_example(data='census_income')
# 数据清洗
drop_cols = ['age', 'fnlwgt', 'education-num', 'capital-gain', 'capital-loss', 'hours-per-week', 'race', 'sex']
df.drop(labels=drop_cols, axis=1, inplace=True)
# 打印样本
df.head()
1、Bnlearn
bnlearn
是一个封装度很高的贝叶斯网络库,几乎把因果分析的标准流程都集成在一套 API 里。它支持离散、连续和混合类型数据,可以进行 结构学习、参数学习(CPD 估计)、推理(inference)和合成数据生成(synthetic data generation)。更重要的是,它把常用的独立性检验、评分函数、拓扑排序、模型比较和可视化都做成了开箱即用的函数。
下面是使用 HillClimbSearch 和 BIC 评分方法学习结构的完整流程代码
# 安装
pip install bnlearn
# 加载库
import bnlearn as bn
# 结构学习
model = bn.structure_learning.fit(df, methodtype='hillclimbsearch', scoretype='bic')
# 检验边显著性并剪枝
model = bn.independence_test(model, df, test="chi_square", alpha=0.05, prune=True)
# 参数学习(可选)
model = bn.parameter_learning.fit(model, df)
# 绘制图形
G = bn.plot(model, interactive=False)
dotgraph = bn.plot_graphviz(model)
dotgraph.view(filename=r'c:/temp/bnlearn_plot')
模型学得的 DAG(有向无环图)结构如下: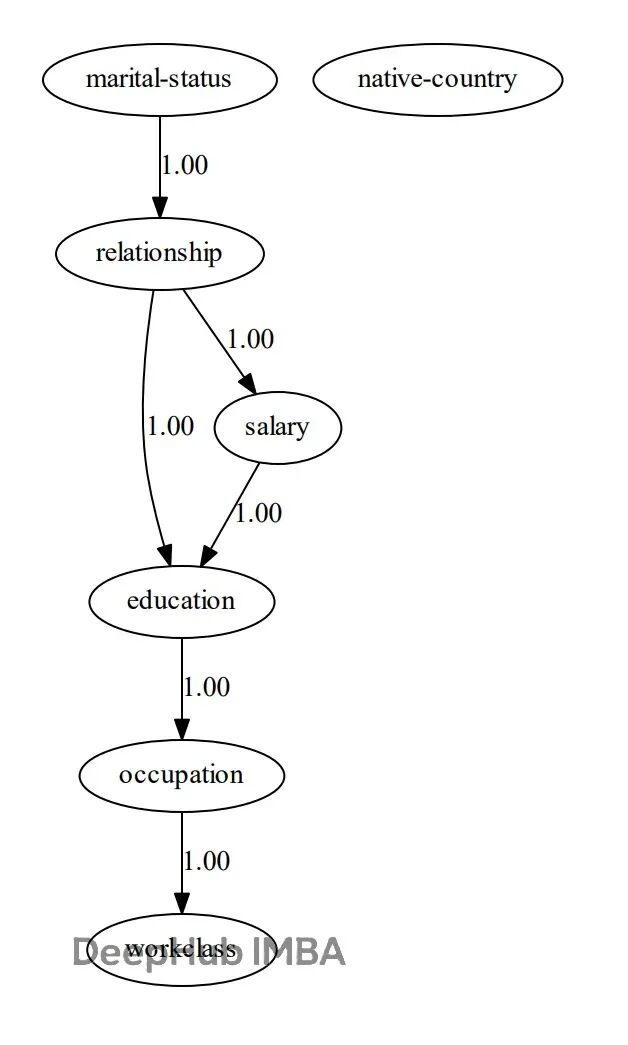
静态图展示了
bnlearn
学出的 Census Income 因果结构图。交互式版本可以直接查看每条边的条件概率分布。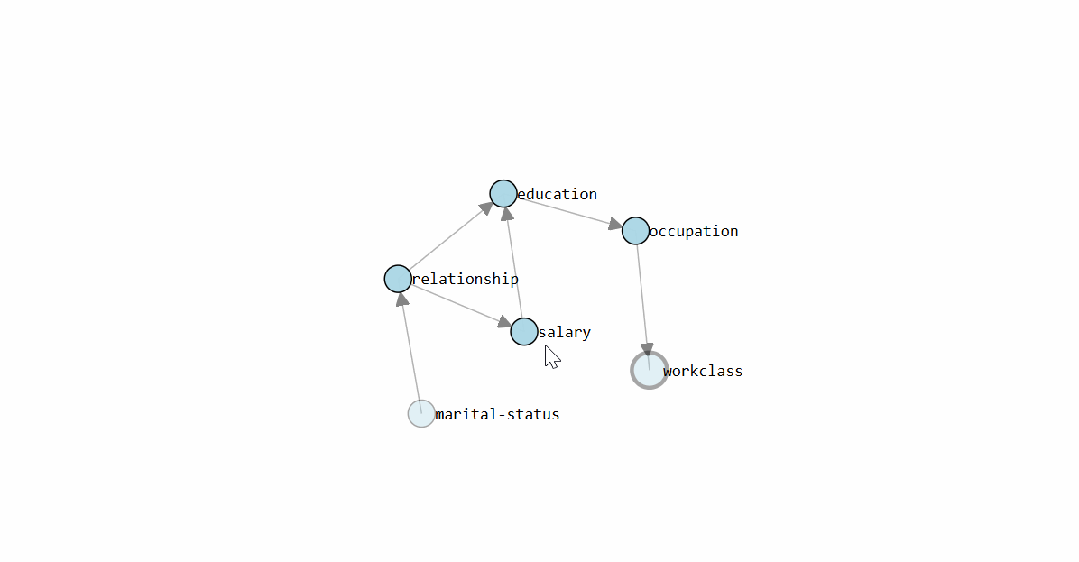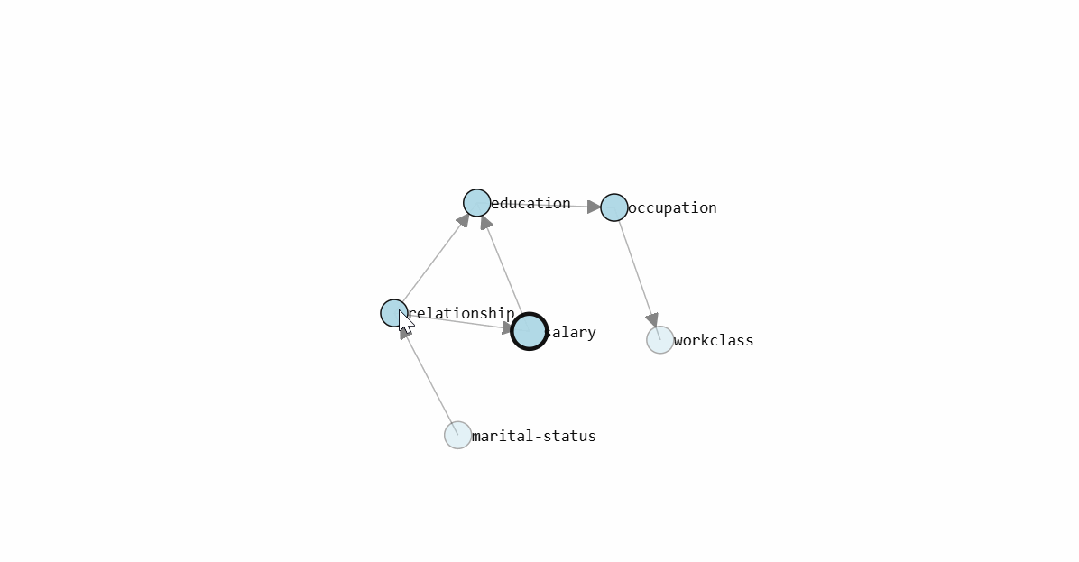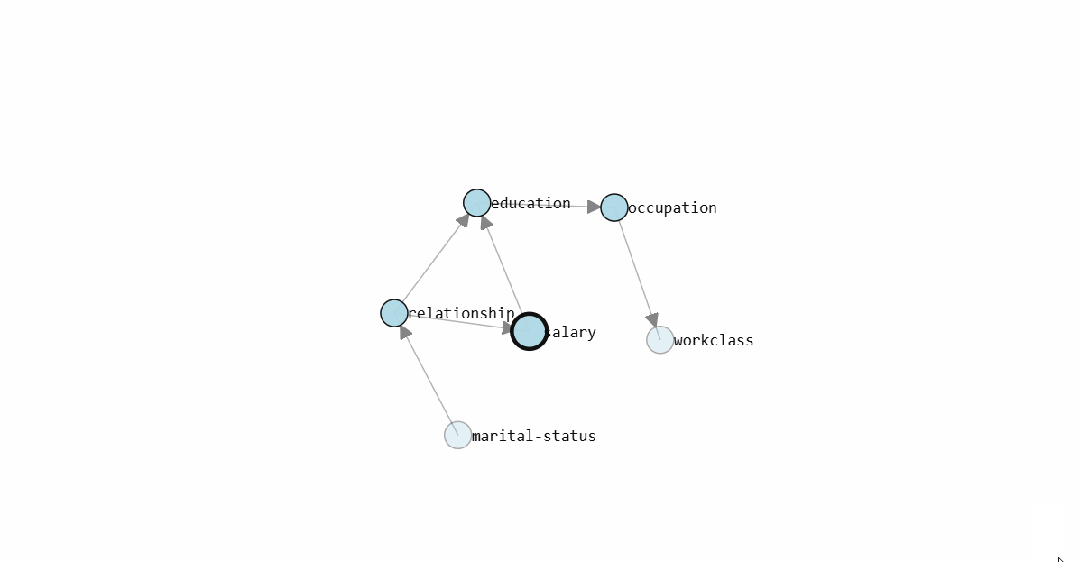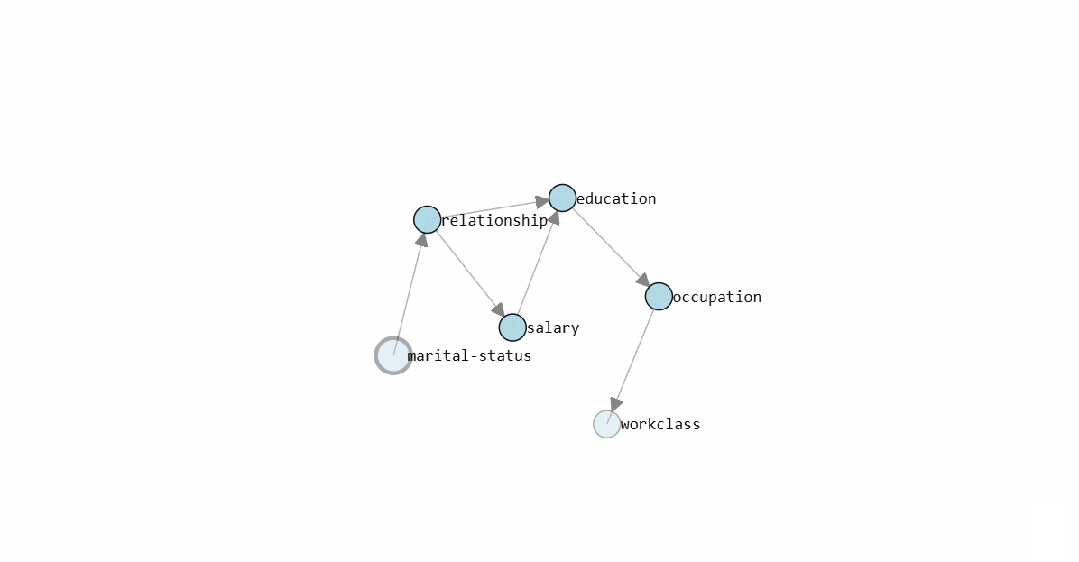
DAG 学成之后,可以直接执行推理。例如计算当教育水平为博士时,收入大于 50K 的后验概率:
# 开始推理
query = bn.inference.fit(model, variables=['salary'], evidence={'education':'Doctorate'})
print(query)
结果如下:
salary <=50K : 29.1%
salary >50K : 70.9%
这个概率几乎符合我们的理解:博士学历的确带来更高的收入区间。
换成高中毕业(
HS-grad
)再试一次:
query = bn.inference.fit(model, variables=['salary'], evidence={'education':'HS-grad'})
得到:
salary <=50K : 83.8%
salary >50K : 16.2%
还可以组合多个条件,例如:
# 当 education=Doctorate 且 marital-status=Never-married 时,预测 workclass
query = bn.inference.fit(model, variables=['workclass'], evidence={'education':'Doctorate', 'marital-status':'Never-married'})
从整体来看,
bnlearn
适合快速构建因果结构并做概率推理,功能完整。输入数据可为离散、连续或混合类型。对于想在业务场景中快速验证因果假设的人,这个库的学习曲线非常平缓。
2、 Pgmpy
Pgmpy
是一个更偏底层的概率图模型库,如果说
bnlearn
是“开箱即用”那
pgmpy
更像是一套“拼装工具箱”。他的灵活性非常高,但也意味着需要较强的贝叶斯建模功底。
这两个库的功能其实有重叠,因为
bnlearn
的底层实现部分依赖
pgmpy
。但在
pgmpy
中,所有步骤都要自己搭建:数据处理、建模、参数估计、推理、可视化都要自己写。
下面是用
HillClimbSearch
和
BIC
评分方法做结构学习的例子:
# 安装 pgmpy
pip install pgmpy
# 导入函数
from pgmpy.estimators import HillClimbSearch, BicScore, BayesianEstimator
from pgmpy.models import BayesianNetwork, NaiveBayes
from pgmpy.inference import VariableElimination
# 导入数据并删除连续与敏感特征
df = bn.import_example(data='census_income')
drop_cols = ['age', 'fnlwgt', 'education-num', 'capital-gain', 'capital-loss', 'hours-per-week', 'race', 'sex']
df.drop(labels=drop_cols, axis=1, inplace=True)
# 创建估计器与评分方法
est = HillClimbSearch(df)
scoring_method = BicScore(df)
# 建立模型并打印边
model = est.estimate(scoring_method=scoring_method)
print(model.edges())
建好结构后需要手动拟合条件概率分布(CPD):
vec = {
'source': ['education', 'marital-status', 'occupation', 'relationship', 'relationship', 'salary'],
'target': ['occupation', 'relationship', 'workclass', 'education', 'salary', 'education'],
'weight': [True, True, True, True, True, True]
}
vec = pd.DataFrame(vec)
# 创建贝叶斯模型
bayesianmodel = BayesianNetwork(vec)
# 拟合模型
bayesianmodel.fit(df, estimator=BayesianEstimator, prior_type='bdeu', equivalent_sample_size=1000)
# 推理
model_infer = VariableElimination(bayesianmodel)
query = model_infer.query(variables=['salary'], evidence={'education':'Doctorate'})
print(query)
输出结果与
bnlearn
基本一致:
salary <=50K : 29.1%
salary >50K : 70.9%
不同的是,这个过程需要你自己定义 DAG、参数估计和推理方式。这个库灵活性很高,但显然更适合研究者或开发自定义因果框架的场景,而不是想“直接上手跑”的业务人员。
3、CausalNex
CausalNex
是一个专注于从数据中学习因果图并量化因果效应的 Python 库。它只支持离散分布,这点很重要。所以在建模前必须把所有连续变量或高基数特征离散化,否则模型无法拟合。
文档里也明确提到,如果特征太多、状态太复杂,模型效果会明显下降。不过好处是,它提供了一些便捷函数来帮助降低类别数量和处理标签编码。
下面是一个完整的示例,仍然使用同样的 Census Income 数据。第一步需要把所有类别变量转为数值型(因为 NOTEARS 算法要求矩阵计算):
# 安装
pip install causalnex
# 导入库
from causalnex.structure.notears import from_pandas
from causalnex.network import BayesianNetwork
import networkx as nx
import datazets as dz
from sklearn.preprocessing import LabelEncoder
import matplotlib.pyplot as plt
le = LabelEncoder()
# 导入数据并删除连续与敏感特征
df = dz.get(data='census_income')
drop_cols = ['age', 'fnlwgt', 'education-num', 'capital-gain', 'capital-loss', 'hours-per-week', 'race', 'sex']
df.drop(labels=drop_cols, axis=1, inplace=True)
# 转换为数值型
df_num = df.copy()
for col in df_num.columns:
df_num[col] = le.fit_transform(df_num[col])
结构学习部分用的是 NOTEARS 算法,可以自动从相关矩阵中推导 DAG。不过输出可能太密集,需要设定阈值过滤掉弱边:
# 结构学习
sm = from_pandas(df_num)
# 阈值剪枝
sm.remove_edges_below_threshold(0.8)
# 绘图
plt.figure(figsize=(15,10))
edge_width = [d['weight']*0.3 for (u,v,d) in sm.edges(data=True)]
nx.draw_networkx(sm, node_size=400, arrowsize=20, alpha=0.6, edge_color='b', width=edge_width)
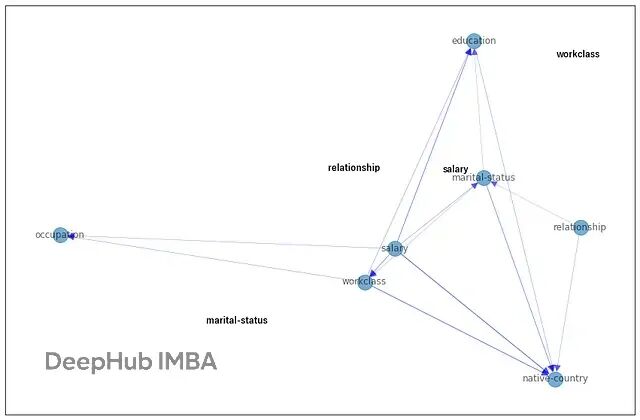
上图是
CausalNex
学出的结构图。没有标签的节点表示因为阈值太高被剪掉的弱边。也可以通过调整参数
w_threshold
控制网络稀疏度,或者用
tabu_edges
禁止某些边生成。
建好结构后,需要学习节点的条件概率分布:
# 第一步:创建 BayesianNetwork 实例
bn = BayesianNetwork(sm)
# 第二步:降低分类特征基数(可选)
# 第三步:定义每个节点的状态字典
# 第四步:拟合节点状态
bn = bn.fit_node_states(df)
# 第五步:拟合条件概率分布
bn = bn.fit_cpds(df, method="BayesianEstimator", bayes_prior="K2")
# 输出某个节点的 CPD
result = bn.cpds["education"]
print(result)
CausalNex
的可解释性和结构学习能力都不错,但预处理要求多、类型限制严格,对 Python 版本也挑剔(仅兼容 3.6–3.10)。如果只想跑标准数据,它表现稳定,但要集成到更复杂的生产环境,需要额外工作。
4、DoWhy
DoWhy
是一个专注于因果推断验证的库,设计理念与前面提到的贝叶斯网络工具完全不同。它并不尝试从数据中直接学习因果图,而是要求用户显式定义因果假设,包括:
- 结果变量(outcome variable)
- 处理变量(treatment variable)
- 潜在混杂变量(common causes)
也就是说
DoWhy
更像是一个验证框架用来系统地质疑和检验你提出的因果假设,而不是生成因果结构。
如果没有提供 DAG(因果图),它会自动把所有变量连接到结果与处理变量上。但实际使用中最好结合领域知识自行定义 DAG,否则模型会过度简化。
使用同样的 Census Income 数据集,只是处理变量定义为“是否拥有博士学位”:
# 安装
pip install dowhy
# 导入库
from dowhy import CausalModel
import dowhy.datasets
import datazets as dz
from sklearn.preprocessing import LabelEncoder
import numpy as np
le = LabelEncoder()
# 导入数据并删除连续和敏感特征
df = dz.get(data='census_income')
drop_cols = ['age', 'fnlwgt', 'education-num', 'capital-gain', 'capital-loss', 'hours-per-week', 'race', 'sex']
df.drop(labels=drop_cols, axis=1, inplace=True)
# 处理变量必须为二元
df['education'] = df['education']=='Doctorate'
# 将数据转换为数值型
df_num = df.copy()
for col in df_num.columns:
df_num[col] = le.fit_transform(df_num[col])
# 指定处理变量、结果变量和潜在混杂变量
treatment = "education"
outcome = "salary"
# Step 1: 创建因果图
model = CausalModel(
data=df_num,
treatment=treatment,
outcome=outcome,
common_causes=list(df.columns[~np.isin(df.columns, [treatment, outcome])]),
graph_builder='ges',
alpha=0.05,
)
# 查看模型
model.view_model()
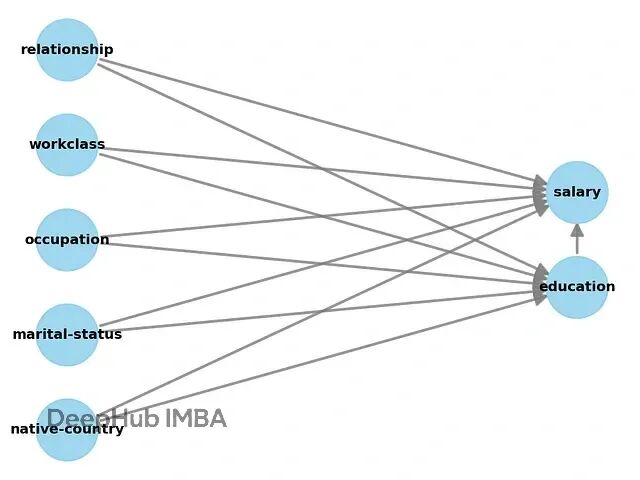
上图展示了
DoWhy
自动生成的 DAG,结果变量为“salary”,处理变量为“education”。可以看到,模型假设教育水平会影响薪资,并且两者都可能受婚姻状态、工作类型等混杂因素的干扰。
接下来是识别和估计因果效应的步骤:
# Step 2: 识别因果效应
identified_estimand = model.identify_effect(proceed_when_unidentifiable=True)
print(identified_estimand)
一旦模型识别出可估计的因果效应,就可以计算平均处理效应(ATE):
# Step 3: 估计效应
estimate = model.estimate_effect(identified_estimand, method_name="backdoor.propensity_score_stratification")
print(estimate)
输出的平均效应值约为 0.47,说明博士学位与高收入存在明显的正向因果关系。最后再做稳健性检验:
# Step 4: 稳健性验证
refute_results = model.refute_estimate(identified_estimand, estimate, method_name="random_common_cause")
DoWhy在学术界非常常见,优点是框架清晰、假设透明、验证逻辑完备; 缺点是对输入要求高(变量需二值化、分类需数值编码),且不能从数据自动学习结构。
换句话说,它假设你已经知道潜在的因果关系,现在只想验证这个假设是否合理。
5、PyAgrum
PyAgrum
是另一个功能相对完整的概率图模型库。它支持贝叶斯网络、马尔可夫网络以及决策图的构建,能做结构学习、参数学习、推理和可视化。并且语法偏工程化,比
pgmpy
直观一些,但要求所有变量都必须是离散型。
如果数据里有缺失值或连续变量需要进行处理,否则算法会直接报错。下面的例子展示了从数据清洗到结构学习的完整流程:
# 安装
pip install pyagrum
# 可选:安装可视化依赖
pip install setgraphviz
import datazets as dz
import pandas as pd
import pyagrum as gum
import pyagrum.lib.notebook as gnb
import pyagrum.lib.explain as explain
import pyagrum.lib.bn_vs_bn as bnvsbn
# 导入可视化设置
from setgraphviz import setgraphviz
setgraphviz()
# 导入数据并删除连续与敏感特征
df = dz.get(data='census_income')
drop_cols = ['age', 'fnlwgt', 'education-num', 'capital-gain', 'capital-loss', 'hours-per-week', 'race', 'sex']
df.drop(labels=drop_cols, axis=1, inplace=True)
# 清理缺失值
df2 = df.dropna().copy()
df2 = df2.fillna("missing").replace("?", "missing")
# 所有列转换为分类类型
for col in df2.columns:
df2[col] = df2[col].astype("category")
# 创建学习器
learner = gum.BNLearner(df2)
learner.useScoreBIC()
learner.useGreedyHillClimbing()
# 学习结构
bn = learner.learnBN()
# 学习参数
bn2 = learner.learnParameters(bn.dag())
# 可视化结果
gnb.showBN(bn2)
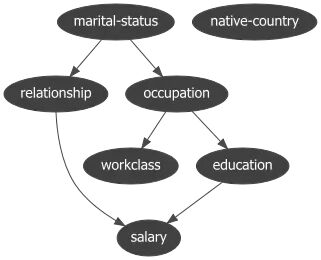
上图展示了
PyAgrum
学到的贝叶斯网络结构。节点之间的箭头表示潜在的因果方向。
它提供了一系列辅助模块,可以比较不同结构(
bn_vs_bn
)、解释单个节点(
explain
)或生成报告。
PyAgrum
的特点是:学习过程透明、支持约束学习(可指定禁止/强制边),但代价是输入准备相对繁琐。 没有自动缺失值处理、连续特征必须离散化,而且某些函数依赖 Graphviz 进行可视化。
6、CausalImpact
CausalImpact
原本是 Google 的开源项目,用于通过贝叶斯结构时间序列模型来衡量干预效果。 它与前面几个库不同,不学习因果图而是针对时间序列数据计算干预带来的量化影响。
常见场景是评估营销活动、价格调整或新功能上线的效果。比如,一个电商网站想知道广告活动是否带来了实际销售提升。
CausalImpact
会先用干预前的数据建立基线模型,再将干预后的实际观测值与预测值比较,计算“反事实差异”。
下面是一个简洁的示例,构造 100 个样本点,并在第 71 个时间点之后人为引入干预效应:
# 安装
pip install causalimpact
# 导入库
import numpy as np
import pandas as pd
from statsmodels.tsa.arima_process import arma_generate_sample
import matplotlib.pyplot as plt
from causalimpact import CausalImpact
# 生成样本
x1 = arma_generate_sample(ar=[0.999], ma=[0.9], nsample=100) + 100
y = 1.2 * x1 + np.random.randn(100)
y[71:] = y[71:] + 10
data = pd.DataFrame(np.array([y, x1]).T, columns=["y","x1"])
# 初始化模型
impact = CausalImpact(data, pre_period=[0,69], post_period=[71,99])
# 执行推断
impact.run()
# 绘图与结果
impact.plot()
impact.summary()
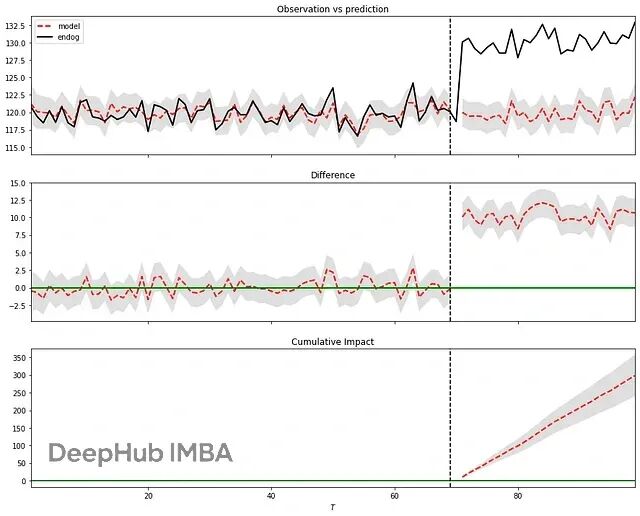
图中上半部分显示实际值与模型预测值的对比;中间部分是两者的差值(即时效应);下半部分是累计效应。
结果显示,干预带来了显著提升,概率为 100%,P 值为 0。这种方法假设干预前后协变量与响应变量的关系稳定,且协变量本身不受干预影响。若满足这些假设,
CausalImpact
在定量评估干预效应方面非常可靠。
总结
六个库的思路差异很大。从整体来看,可以分成两类:
结构学习型:
Bnlearn
、
Pgmpy
、
CausalNex
、
PyAgrum
用于发现变量间的潜在因果关系,适合探索性分析与结构建模。
因果效应型:
DoWhy
、
CausalImpact
侧重在给定结构或时间序列下量化干预效果,适合政策分析或实验验证。
从工程角度看:
Bnlearn
的易用性最高,接口友好、兼容性强,是入门和快速验证的好工具;
Pgmpy
灵活性最强,适合深度研究与自定义算法;
CausalNex
拥有良好的可解释图形界面,但依赖特定 Python 版本;
DoWhy
是学术研究常用工具,强调理论严谨性;
PyAgrum
稳定、透明,但数据准备较重;
CausalImpact
专注时间序列因果评估。
六个因果库覆盖了从结构学习到因果效应估计的完整路径。
Bnlearn
、
Pgmpy
、
CausalNex
和
PyAgrum
负责构建网络、识别驱动因素;
DoWhy
和
CausalImpact
则更像“量化工具”,用于评估处理或干预带来的实际影响。