
HW12
一、作业描述
在这个HW中,你可以自己实现一些深度强化学习方法:
1、策略梯度Policy Gradient
2、Actor-Critic
这个HW的环境是OpenAI gym的月球着陆器。希望这个月球着陆器落在两个旗子中间。
什么是月球着陆器?
“LunarLander-v2”是模拟飞行器在月球表面着陆时的情况。
这项任务是使飞机能够“安全地”降落在两个黄色旗帜之间的停机坪上。着陆平台始终位于坐标(0,0)处。坐标是状态向量中的前两个数字。“LunarLander-v2”实际上包括“代理”和“环境”。在本作业中,我们将利用函数“step()”来控制“代理”的动作。
那么‘step()’将返回由“环境”给出的观察/状态和奖励…
Box(8,)意味着观察是一个8维向量

‘Discrete(4)’意味着代理可以采取四种行动。
- 0表示代理不会采取任何操作
- 2意味着代理将向下加速
- 1,3意味着代理将向左和向右加速
接下来,我们将尝试让代理与环境进行交互。
在采取任何行动之前,我们建议调用’ reset()'函数来重置环境。此外,该函数将返回环境的初始状态。
1、Policy Gradient
直接根据状态输出动作或者动作的概率。那么怎么输出呢,最简单的就是使用神经网络。网络应该如何训练来实现最终的收敛呢?反向传播算法,我们需要一个误差函数,通过梯度下降来使我们的损失最小。但对于强化学习来说,我们不知道动作的正确与否,只能通过奖励值来判断这个动作的相对好坏。如果一个动作得到的reward多,那么我们就使其出现的概率增加,如果一个动作得到的reward少,我们就使其出现的概率减小。



每次循环都要收集很多数据才进行一次参数更新。
2、Actor-Critic

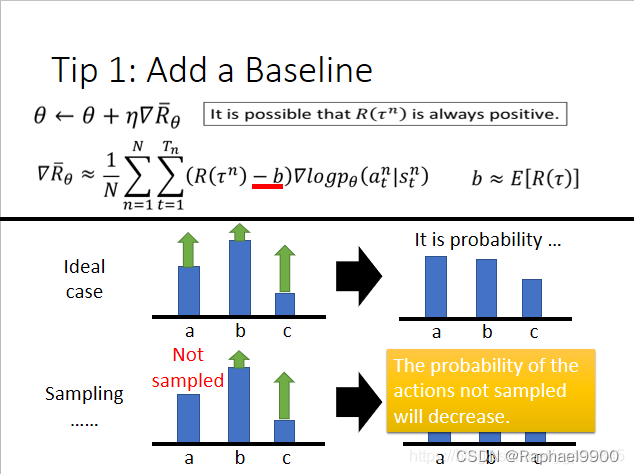
增加基准判断这个动作是否是真的好!
分配不同的权重

组合衰减因子。
二、实验
1、simple
#torch.set_deterministic(True)
torch.use_deterministic_algorithms(True)
training result: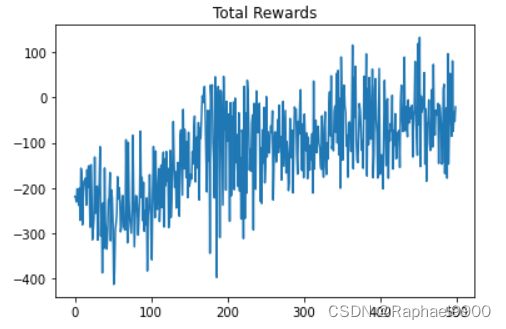
testing: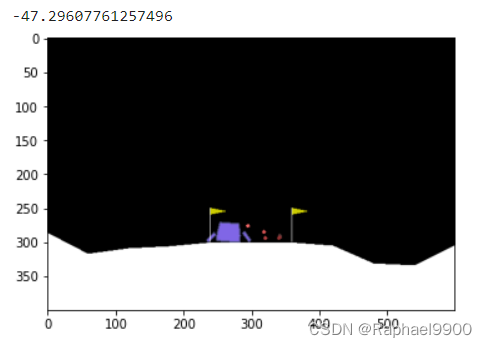
test reward: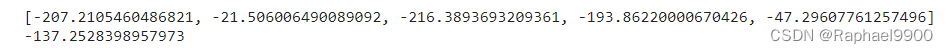
server: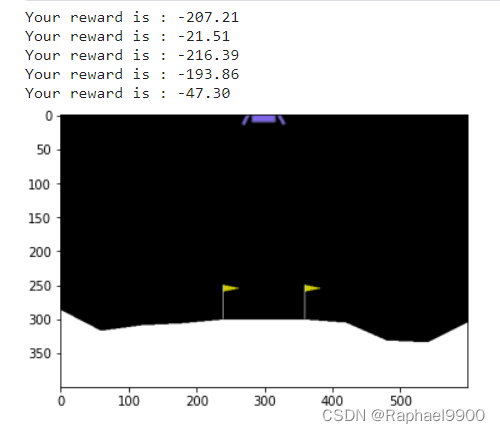
score:
2、medium
……
NUM_BATCH =500 # totally update the agent for400 time
rate =0.99
……
while True:
action, log_prob = agent.sample(state) # at,log(at|st)
next_state, reward, done, _ = env.step(action)
log_probs.append(log_prob) # [log(a1|s1),log(a2|s2),....,log(at|st)]
seq_rewards.append(reward)
state = next_state
total_reward += reward
total_step +=1if done:
final_rewards.append(reward)
total_rewards.append(total_reward)#calculateaccumulative rewardsfor i in range(2,len(seq_rewards)+1):
seq_rewards[-i]+= rate *(seq_rewards[-i+1])
rewards += seq_rewards
break
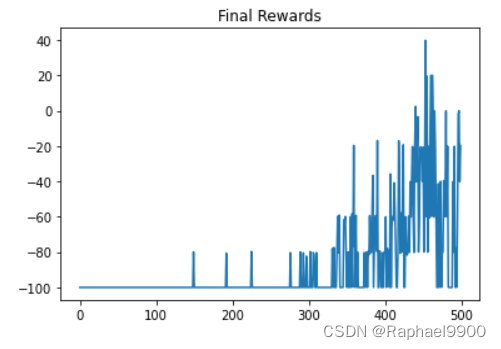
training result:
testing: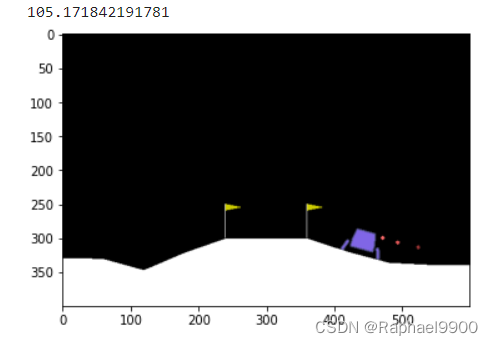
test reward:
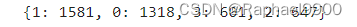
server: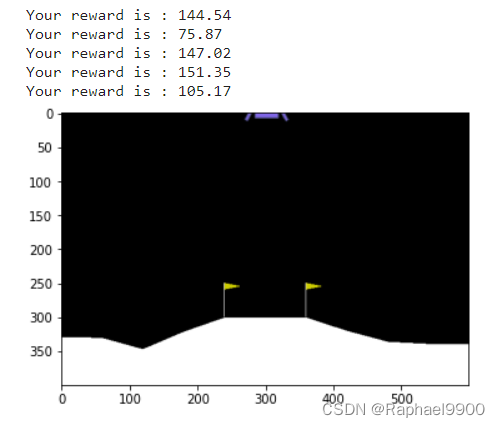
score:

3、strong
from torch.optim.lr_scheduler import StepLR
class ActorCritic(nn.Module):
def __init__(self):super().__init__()
self.fc = nn.Sequential(
nn.Linear(8,16),
nn.Tanh(),
nn.Linear(16,16),
nn.Tanh())
self.actor = nn.Linear(16,4)
self.critic = nn.Linear(16,1)
self.values =[]
self.optimizer = optim.SGD(self.parameters(), lr=0.001)
def forward(self, state):
hid = self.fc(state)
self.values.append(self.critic(hid).squeeze(-1))return F.softmax(self.actor(hid), dim=-1)
def learn(self, log_probs, rewards):
values = torch.stack(self.values)
loss =(-log_probs *(rewards - values.detach())).sum()
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.values =[]
def sample(self, state):
action_prob =self(torch.FloatTensor(state))
action_dist =Categorical(action_prob)
action = action_dist.sample()
log_prob = action_dist.log_prob(action)return action.item(), log_prob
training result:


testing:
test reward:

server:
score: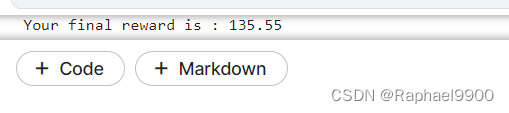
三、代码
** 准备工作**
首先,我们需要安装所有必要的软件包。
其中一个是由OpenAI构建的gym,它是一个开发强化学习算法的工具包。
可以利用“step()”使代理按照随机选择的“random_action”动作。
“step()”函数将返回四个值:
-观察/状态
-奖励
-完成 done(对/错)
-其他信息
observation, reward, done, info = env.step(random_action)print(done)

奖励
着陆平台始终位于坐标(0,0)处。坐标是状态向量中的前两个数字。奖励从屏幕顶部移动到着陆垫和零速度大约是100…140分。如果着陆器离开着陆平台,它将失去回报。如果着陆器崩溃或停止,本集结束,获得额外的-100或+100点。每个支腿接地触点为+10。点燃主引擎每帧扣-0.3分。解决了就是200分。
随机代理
开始训练之前,我们可以看看一个随机的智能体能否成功登陆月球。
env.reset()
img = plt.imshow(env.render(mode='rgb_array'))
done = False
while not done:
action = env.action_space.sample()
observation, reward, done, _ = env.step(action)
img.set_data(env.render(mode='rgb_array'))
display.display(plt.gcf())#展示当前图窗的句柄
display.clear_output(wait=True)

政策梯度
现在,我们可以建立一个简单的政策网络。网络将返回动作空间中的一个动作。
class PolicyGradientNetwork(nn.Module):
def __init__(self):super().__init__()
self.fc1 = nn.Linear(8,16)
self.fc2 = nn.Linear(16,16)
self.fc3 = nn.Linear(16,4)
def forward(self, state):
hid = torch.tanh(self.fc1(state))
hid = torch.tanh(self.fc2(hid))return F.softmax(self.fc3(hid), dim=-1)
然后,我们需要构建一个简单的代理。代理将根据上述策略网络的输出进行操作。代理可以做几件事:
learn():根据对数概率和奖励更新策略网络。sample():在从环境接收到观察之后,利用策略网络来告知要采取哪个动作。该函数的返回值包括动作概率和对数概率。
from torch.optim.lr_scheduler import StepLR
class PolicyGradientAgent():
def __init__(self, network):
self.network = network
self.optimizer = optim.SGD(self.network.parameters(), lr=0.001)
def forward(self, state):return self.network(state)
def learn(self, log_probs, rewards):
loss =(-log_probs * rewards).sum() # You don't need to revise this to pass simple baseline(but you can)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
def sample(self, state):
action_prob = self.network(torch.FloatTensor(state))
action_dist =Categorical(action_prob)
action = action_dist.sample()
log_prob = action_dist.log_prob(action)return action.item(), log_prob
训练代理
现在让我们开始训练我们的代理人。
通过将代理和环境之间的所有交互作为训练数据,策略网络可以从所有这些尝试中学习。
agent.network.train() # Switch network into training mode
EPISODE_PER_BATCH =5 # update the agent every 5 episode
NUM_BATCH =500 # totally update the agent for400 time
avg_total_rewards, avg_final_rewards =[],[]
prg_bar =tqdm(range(NUM_BATCH))#进度条
for batch in prg_bar:
log_probs, rewards =[],[]
total_rewards, final_rewards =[],[]#collecttrajectoryfor episode in range(EPISODE_PER_BATCH):
state = env.reset()
total_reward, total_step =0,0
seq_rewards =[]while True:
action, log_prob = agent.sample(state) # at,log(at|st)
next_state, reward, done, _ = env.step(action)
log_probs.append(log_prob) # [log(a1|s1),log(a2|s2),....,log(at|st)]#seq_rewards.append(reward)
state = next_state
total_reward += reward
total_step +=1
rewards.append(reward) # change here
# ! IMPORTANT !#Current reward implementation: immediate reward, given action_list : a1, a2, a3 ......#rewards: r1, r2 ,r3 ......#medium:change "rewards"to accumulative decaying reward, given action_list : a1, a2, a3,......#rewards: r1+0.99*r2+0.99^2*r3+......, r2+0.99*r3+0.99^2*r4+......, r3+0.99*r4+0.99^2*r5+......#boss: implement Actor-Criticif done:
final_rewards.append(reward)
total_rewards.append(total_reward)breakprint(f"rewards looks like ", np.shape(rewards))print(f"log_probs looks like ", np.shape(log_probs))#recordtraining process
avg_total_reward =sum(total_rewards)/len(total_rewards)
avg_final_reward =sum(final_rewards)/len(final_rewards)
avg_total_rewards.append(avg_total_reward)
avg_final_rewards.append(avg_final_reward)
prg_bar.set_description(f"Total: {avg_total_reward: 4.1f}, Final: {avg_final_reward: 4.1f}")#updateagent#rewards= np.concatenate(rewards, axis=0)
rewards =(rewards - np.mean(rewards))/(np.std(rewards)+1e-9) # normalize the reward ,std求标准差
agent.learn(torch.stack(log_probs), torch.from_numpy(rewards))#torch.from_numpy创建一个张量,torch.stack沿一个新维度对输入张量序列进行连接,序列中所有张量应为相同形状
print("logs prob looks like ", torch.stack(log_probs).size())print("torch.from_numpy(rewards) looks like ", torch.from_numpy(rewards).size())
训练结果
在训练过程中,我们记录了“avg_total_reward ”,它表示在更新策略网络之前集的平均总奖励。理论上,如果代理变得更好,avg_total_reward会增加。
plt.plot(avg_total_rewards)
plt.title("Total Rewards")
plt.show()
此外,“avg_final_reward”表示集的平均最终奖励。具体来说,最终奖励是一集最后收到的奖励,表示飞行器是否成功着陆。
plt.plot(avg_final_rewards)
plt.title("Final Rewards")
plt.show()
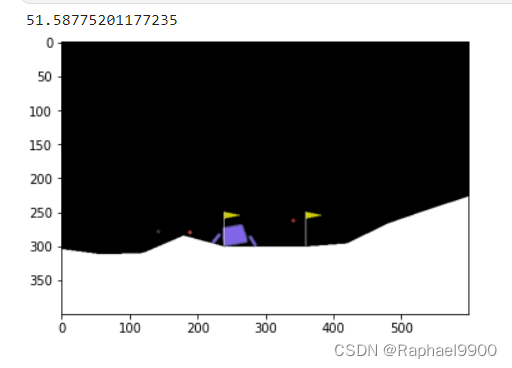
测试
测试结果将是5次测试的平均奖励
fix(env, seed)
agent.network.eval() # set the network into evaluation mode
NUM_OF_TEST =5 # Do not revise this !!!
test_total_reward =[]
action_list =[]for i in range(NUM_OF_TEST):
actions =[]
state = env.reset()
img = plt.imshow(env.render(mode='rgb_array'))
total_reward =0
done = False
while not done:
action, _ = agent.sample(state)
actions.append(action)
state, reward, done, _ = env.step(action)
total_reward += reward
img.set_data(env.render(mode='rgb_array'))
display.display(plt.gcf())
display.clear_output(wait=True)print(total_reward)
test_total_reward.append(total_reward)
action_list.append(actions) # save the result of testing
动作分布
distribution ={}for actions in action_list:for action in actions:if action not in distribution.keys():
distribution[action]=1else:
distribution[action]+=1print(distribution)
服务器
下面的代码模拟了judge服务器上的环境。可用于测试。
action_list = np.load(PATH,allow_pickle=True) # The action list you upload
seed =543 # Do not revise this
fix(env, seed)
agent.network.eval() # set network to evaluation mode
test_total_reward =[]iflen(action_list)!=5:print("Wrong format of file !!!")exit(0)for actions in action_list:
state = env.reset()
img = plt.imshow(env.render(mode='rgb_array'))
total_reward =0
done = False
for action in actions:
state, reward, done, _ = env.step(action)
total_reward += reward
if done:breakprint(f"Your reward is : %.2f"%total_reward)
test_total_reward.append(total_reward)
版权归原作者 Raphael9900 所有, 如有侵权,请联系我们删除。