
目录
数据是整个深度学习中最重要的一环,因为数据的好坏决定了最终结果的上限,模型的好坏只是去无限逼近这个上限,所以高质量的数据输入,会在整个深度神经网络中起到积极作用,数据在整个数据处理和数据增强的过程像经过pipeline管道的水一样,源源不断地流向训练系统,如图所示:
MindSpore为用户提供了数据处理以及数据增强的功能,在数据的整个pipeline过程中,其中的每一步骤,如果都能够进行合理的运用,那么数据的性能会得到很大的优化和提升。
本次体验将基于CIFAR-10数据集来为大家展示如何在数据加载、数据处理和数据增强的过程中进行性能的优化。
此外,操作系统的存储、架构和计算资源也会一定程度上影响数据处理的性能。

如果你对MindSpore感兴趣,可以关注昇思MindSpore社区
一、环境准备
1.进入ModelArts官网
云平台帮助用户快速创建和部署模型,管理全周期AI工作流,选择下面的云平台以开始使用昇思MindSpore,可以在昇思教程中进入ModelArts官网
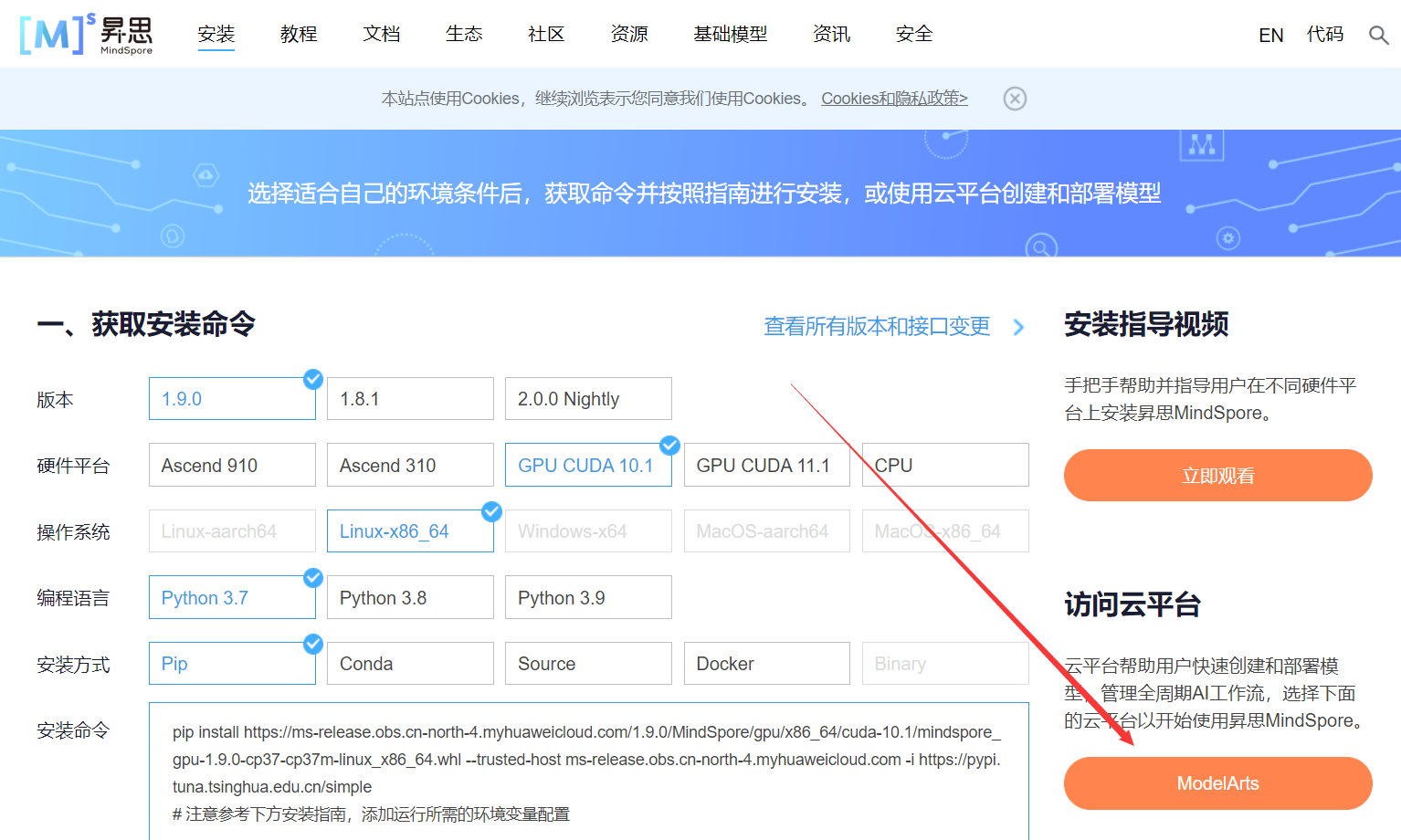
选择下方CodeLab立即体验
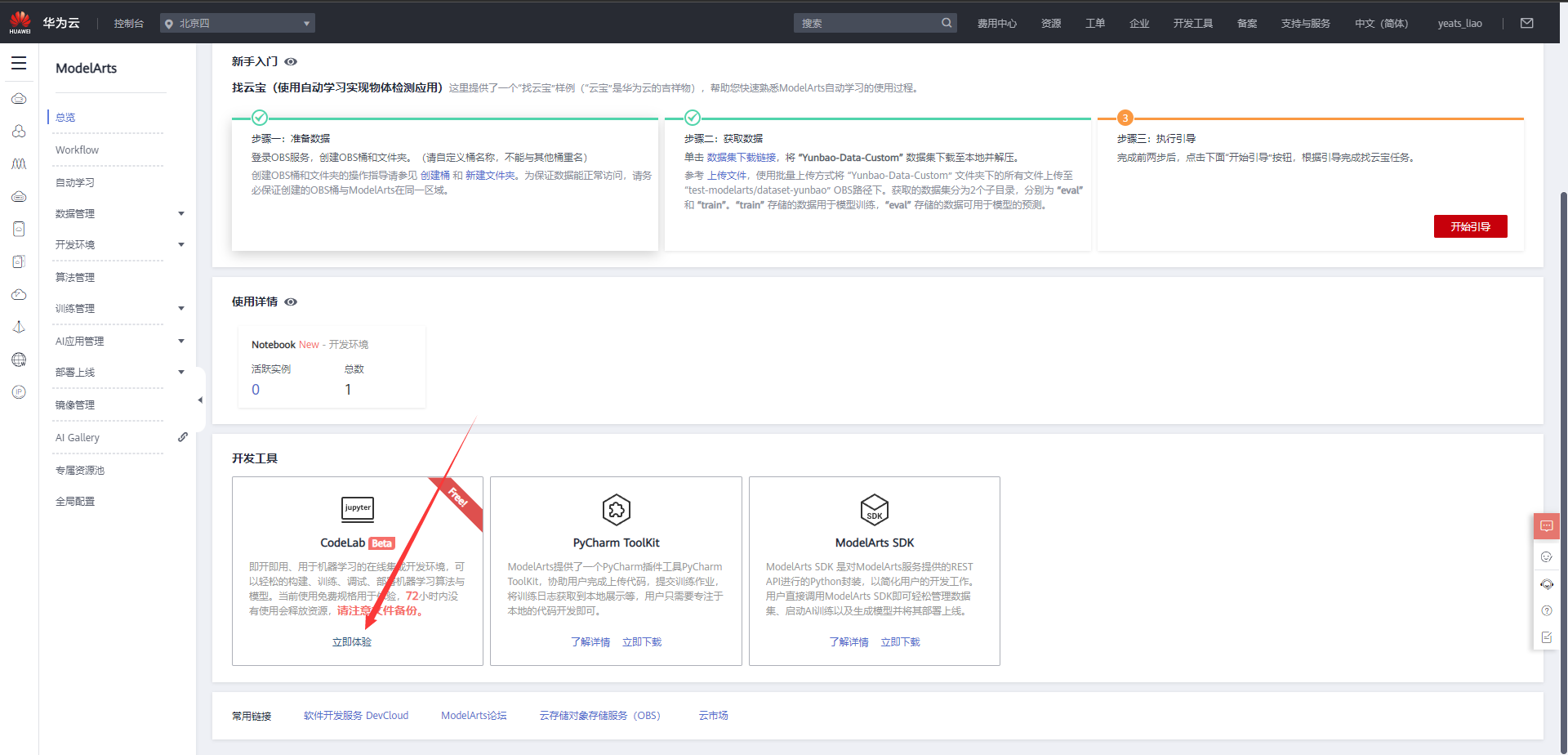
等待环境搭建完成
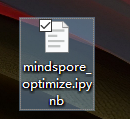
2.使用CodeLab体验Notebook实例
下载NoteBook样例代码,
.ipynb
为样例代码
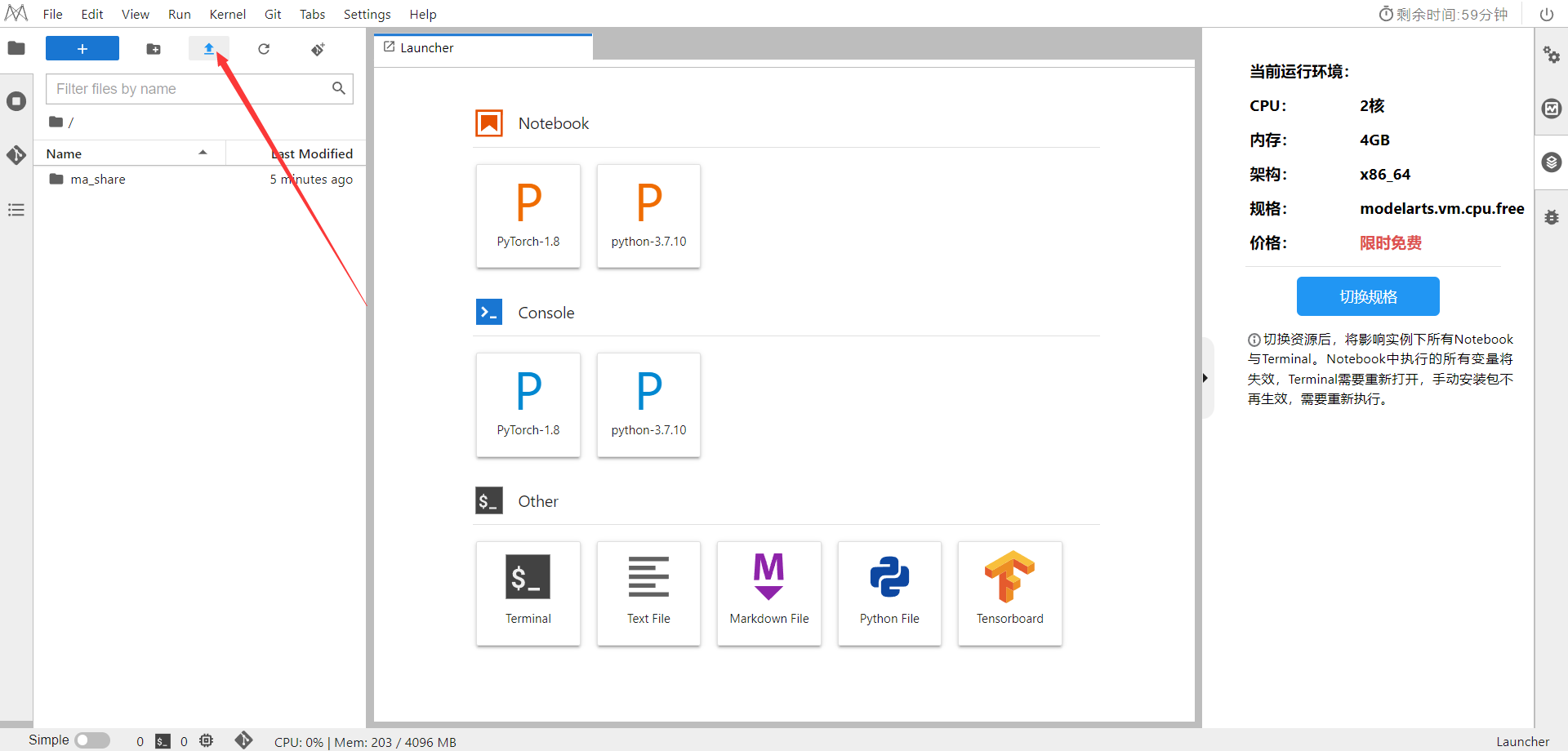
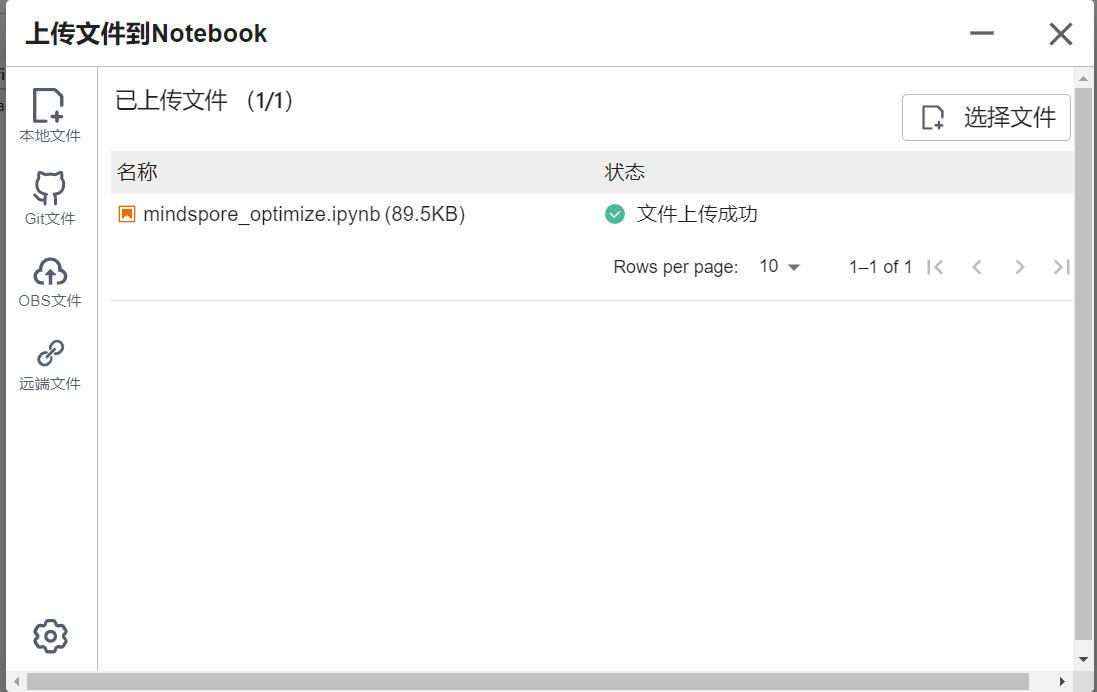
选择ModelArts Upload Files上传
.ipynb
文件
选择Kernel环境
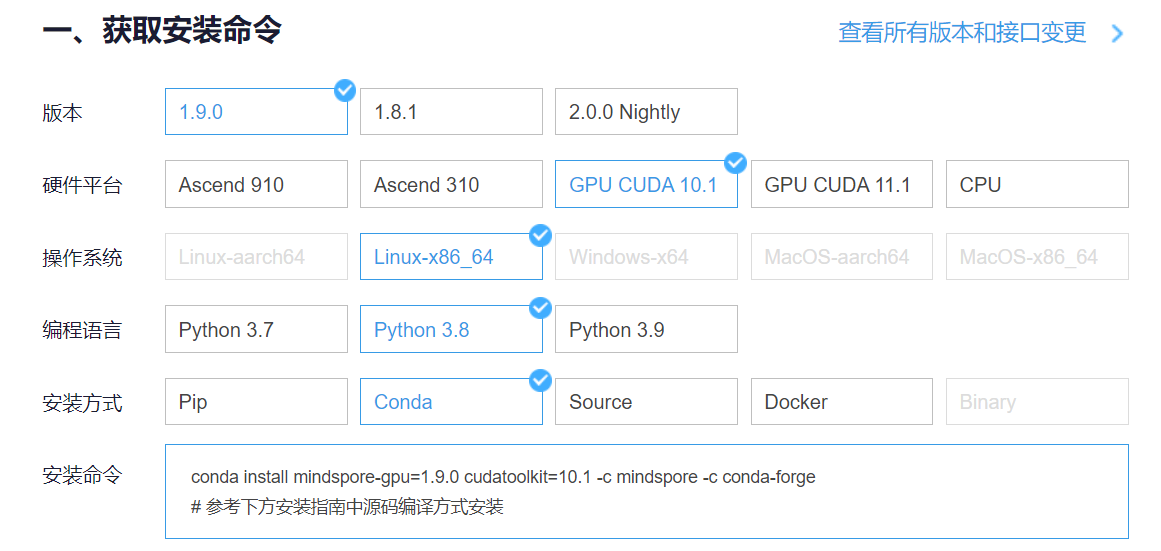
进入昇思MindSpore官网,点击上方的安装

获取安装命令
回到Notebook中,在第一块代码前加入三块命令
pip install --upgrade pip
conda install mindspore-gpu=1.9.0 cudatoolkit=10.1-c mindspore -c conda-forge
pip install mindvision
依次运行即可
二、下载数据集
运行以下命令来获取数据集:
下载CIFAR-10二进制格式数据集,并将数据集文件解压到
./datasets/
目录下,数据加载的时候使用该数据集。
from mindvision import dataset
import os
import shutil
dl_path ="./datasets"
data_dir ="./datasets/cifar-10-batches-bin/"
dl_url ="https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/cifar-10-binary.tar.gz"
dl = dataset.DownLoad()# 下载CIFAR-10数据集
dl.download_and_extract_archive(url=dl_url, download_path=dl_path)
test_path ="./datasets/cifar-10-batches-bin/test"
train_path ="./datasets/cifar-10-batches-bin/train"
os.makedirs(test_path, exist_ok=True)
os.makedirs(train_path, exist_ok=True)if not os.path.exists(os.path.join(test_path, "test_batch.bin")):
shutil.move("./datasets/cifar-10-batches-bin/test_batch.bin", test_path)[shutil.move("./datasets/cifar-10-batches-bin/"+i, train_path)foriin os.listdir("./datasets/cifar-10-batches-bin/")if os.path.isfile("./datasets/cifar-10-batches-bin/"+i) and not i.endswith(".html") and not os.path.exists(os.path.join(train_path, i))]
解压后的数据集文件的目录结构如下:
./datasets/cifar-10-batches-bin
├── readme.html
├── test
│ └── test_batch.bin
└── train
├── batches.meta.txt
├── data_batch_1.bin
├── data_batch_2.bin
├── data_batch_3.bin
├── data_batch_4.bin
└── data_batch_5.bin
三、数据加载性能优化
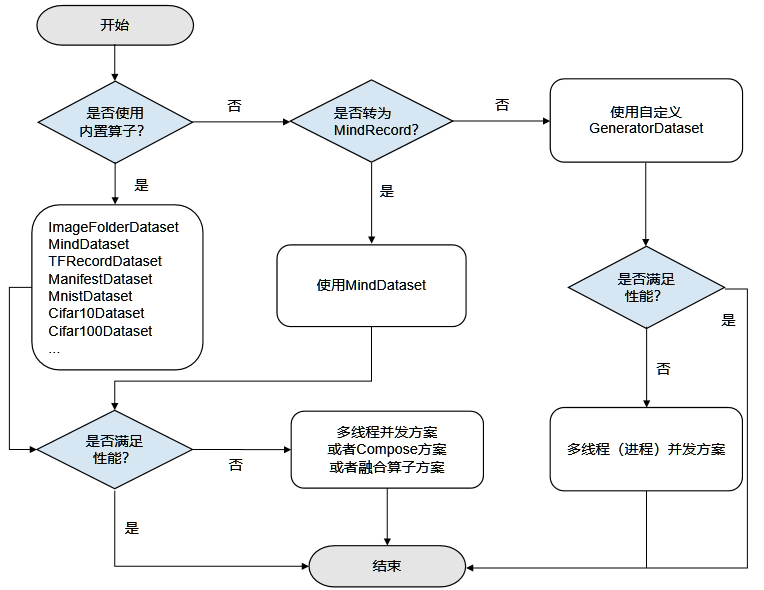
MindSpore支持加载计算机视觉、自然语言处理等领域的常用数据集、特定格式的数据集以及用户自定义的数据集。不同数据集加载接口的底层实现方式不同,性能也存在着差异,如下所示:
常用数据集用户自定义MindRecord底层实现C++PythonC++性能高中高
性能优化方案
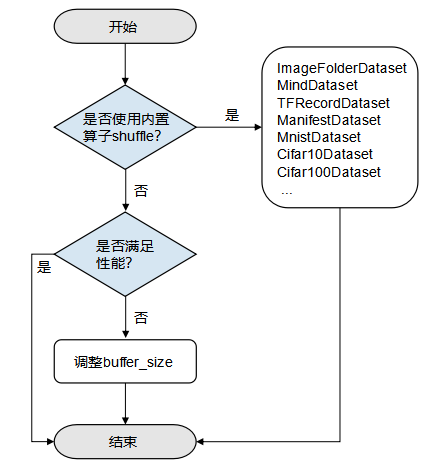
数据加载性能优化建议如下:对于已经提供加载接口的常用数据集,优先使用MindSpore提供的数据集加载接口进行加载,可以获得较好的加载性能,具体内容请参考内置加载算子,如果性能仍无法满足需求,则可采取多线程并发方案,请参考本文多线程优化。
不支持的数据集格式,推荐先将数据集转换为MindRecord数据格式后再使用
MindDataset类进行加载(详细使用方法参考API),具体内容请参考将数据集转换为MindSpore数据格式,如果性能仍无法满足需求,则可采取多线程并发方案,请参考本文多线程优化。
不支持的数据集格式,算法快速验证场景,优选用户自定义
GeneratorDataset类实现(详细使用方法参考API),如果性能仍无法满足需求,则可采取多进程并发方案,请参考本文多进程优化。
基于以上的数据加载性能优化建议,本次体验分别使用内置加载算子
Cifar10Dataset
类(详细使用方法参考API)、数据转换后使用
MindDataset
类、使用
GeneratorDataset
类进行数据加载,代码演示如下:
1.使用内置算子
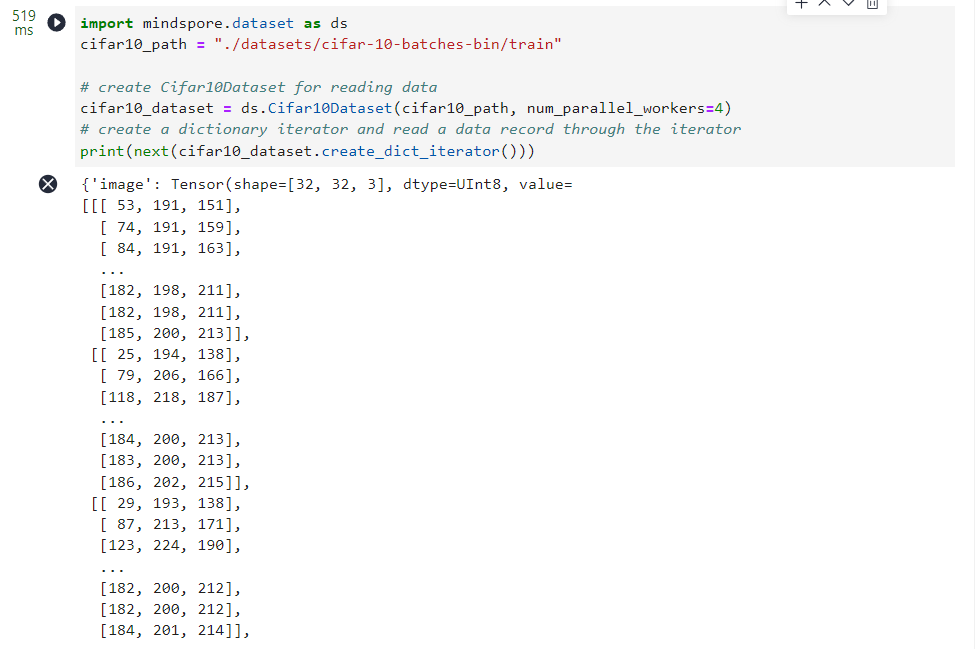
Cifar10Dataset
类加载CIFAR-10数据集,这里使用的是CIFAR-10二进制格式的数据集,加载数据时采取多线程优化方案,开启了4个线程并发完成任务,最后对数据创建了字典迭代器,并通过迭代器读取了一条数据记录。
import mindspore.dataset as ds
cifar10_path ="./datasets/cifar-10-batches-bin/train"# create Cifar10Dataset for reading data
cifar10_dataset = ds.Cifar10Dataset(cifar10_path, num_parallel_workers=4)# create a dictionary iterator and read a data record through the iterator
print(next(cifar10_dataset.create_dict_iterator()))
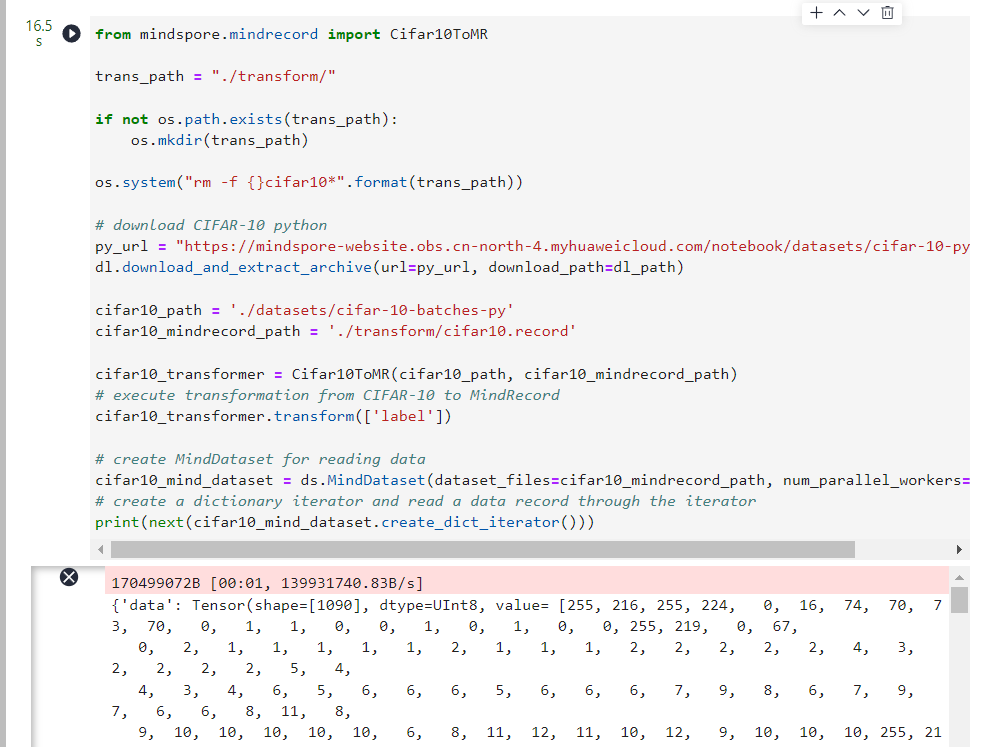
2.使用
Cifar10ToMR
这个类将CIFAR-10数据集转换为MindSpore数据格式,这里使用的是CIFAR-10 python文件格式的数据集,然后使用
MindDataset
类加载MindSpore数据格式数据集,加载数据采取多线程优化方案,开启了4个线程并发完成任务,最后对数据创建了字典迭代器,并通过迭代器读取了一条数据记录。
from mindspore.mindrecord import Cifar10ToMR
trans_path ="./transform/"if not os.path.exists(trans_path):
os.mkdir(trans_path)
os.system("rm -f {}cifar10*".format(trans_path))# download CIFAR-10 python
py_url ="https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/cifar-10-python.tar.gz"
dl.download_and_extract_archive(url=py_url, download_path=dl_path)
cifar10_path ='./datasets/cifar-10-batches-py'
cifar10_mindrecord_path ='./transform/cifar10.record'
cifar10_transformer = Cifar10ToMR(cifar10_path, cifar10_mindrecord_path)# execute transformation from CIFAR-10 to MindRecord
cifar10_transformer.transform(['label'])# create MindDataset for reading data
cifar10_mind_dataset = ds.MindDataset(dataset_files=cifar10_mindrecord_path, num_parallel_workers=4)# create a dictionary iterator and read a data record through the iterator
print(next(cifar10_mind_dataset.create_dict_iterator()))
{'data': Tensor(shape=[1289], dtype=UInt8, value=[255, 216, 255, 224, 0, 16, 74, 70, 73, 70, 0, 1, 1, 0, 0, 1, 0, 1, 0, 0, 255, 219, 0, 67,
0, 2, 1, 1, 1, 1, 1, 2, 1, 1, 1, 2, 2, 2, 2, 2, 4, 3, 2, 2, 2, 2, 5, 4,
4, 3, 4, 6, 5, 6, 6, 6, 5, 6, 6, 6, 7, 9, 8, 6, 7, 9, 7, 6, 6, 8, 11, 8,
9, 10, 10, 10, 10, 10, 6, 8, 11, 12, 11, 10, 12, 9, 10, 10, 10, 255, 219, 0, 67, 1, 2, 2,
...
...
...
39, 227, 206, 143, 241, 91, 196, 154, 230, 189, 125, 165, 105, 218, 94, 163, 124, 146, 11, 187, 29, 34, 217, 210,
23, 186, 56, 14, 192, 19, 181, 1, 57, 36, 14, 51, 211, 173, 105, 9, 191, 100, 212, 174, 122, 25, 110, 39,
11, 133, 193, 226, 169, 73, 36, 234, 69, 90, 222, 93, 31, 223, 115, 255, 217]), 'id': Tensor(shape=[], dtype=Int64, value=46084), 'label': Tensor(shape=[], dtype=Int64, value=5)}
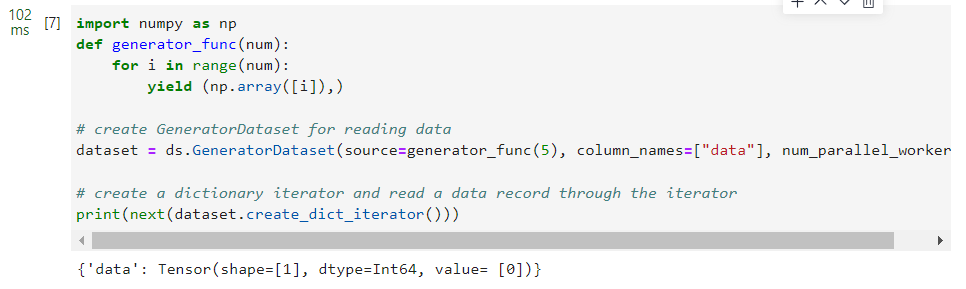
3.使用
GeneratorDataset
类加载自定义数据集,并且采取多进程优化方案,开启了4个进程并发完成任务,最后对数据创建了字典迭代器,并通过迭代器读取了一条数据记录。
import numpy as np
def generator_func(num):
foriin range(num):
yield (np.array([i]),)# create GeneratorDataset for reading data
dataset = ds.GeneratorDataset(source=generator_func(5), column_names=["data"], num_parallel_workers=4)# create a dictionary iterator and read a data record through the iterator
print(next(dataset.create_dict_iterator()))
四、shuffle性能优化
shuffle操作主要是对有序的数据集或者进行过repeat的数据集进行混洗,MindSpore专门为用户提供了
shuffle函数,其中设定的
buffer_size参数越大,混洗程度越大,但时间、计算资源消耗也会大。该接口支持用户在整个pipeline的任何时候都可以对数据进行混洗,具体内容请参考shuffle处理。但是因为底层的实现方式不同,该方式的性能不如直接在内置加载算子中设置
shuffle参数直接对数据进行混洗。
性能优化方案
shuffle性能优化建议如下:
- 直接使用内置加载算子的
shuffle参数进行数据的混洗。- 如果使用的是
shuffle函数,当性能仍无法满足需求,可通过调大buffer_size参数的值来优化提升性能。
基于以上的shuffle性能优化建议,本次体验分别使用内置加载算子
Cifar10Dataset
类的
shuffle
参数和
Shuffle
函数进行数据的混洗,代码演示如下:
1.使用内置算子
Cifar10Dataset
类加载CIFAR-10数据集,这里使用的是CIFAR-10二进制格式的数据集,并且设置
shuffle
参数为True来进行数据混洗,最后对数据创建了字典迭代器,并通过迭代器读取了一条数据记录。
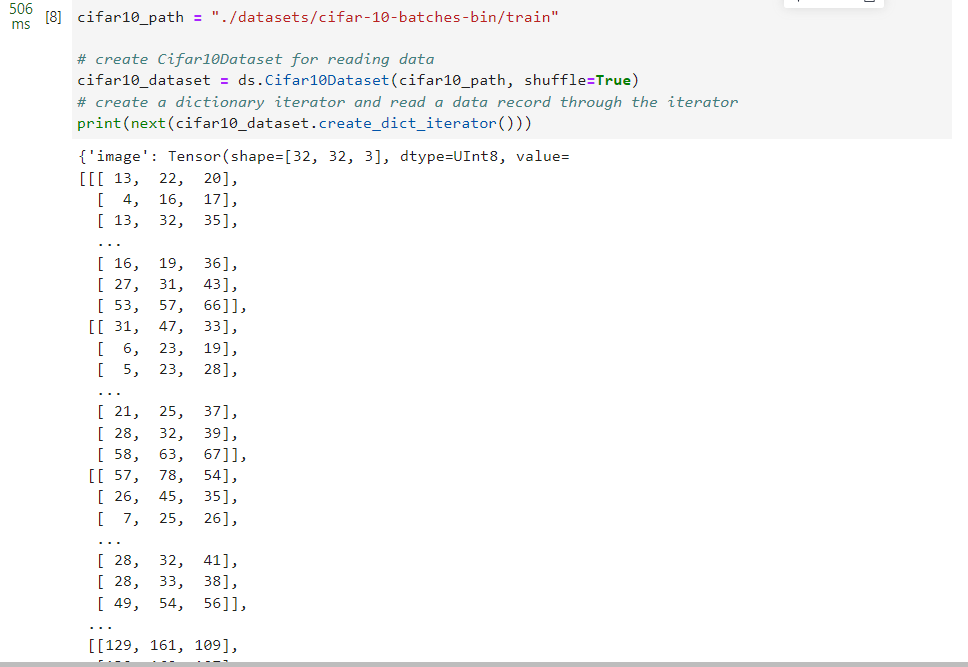
cifar10_path ="./datasets/cifar-10-batches-bin/train"# create Cifar10Dataset for reading data
cifar10_dataset = ds.Cifar10Dataset(cifar10_path, shuffle=True)# create a dictionary iterator and read a data record through the iterator
print(next(cifar10_dataset.create_dict_iterator()))
2.使用
shuffle
函数进行数据混洗,参数
buffer_size
设置为3,数据采用
GeneratorDataset
类自定义生成。
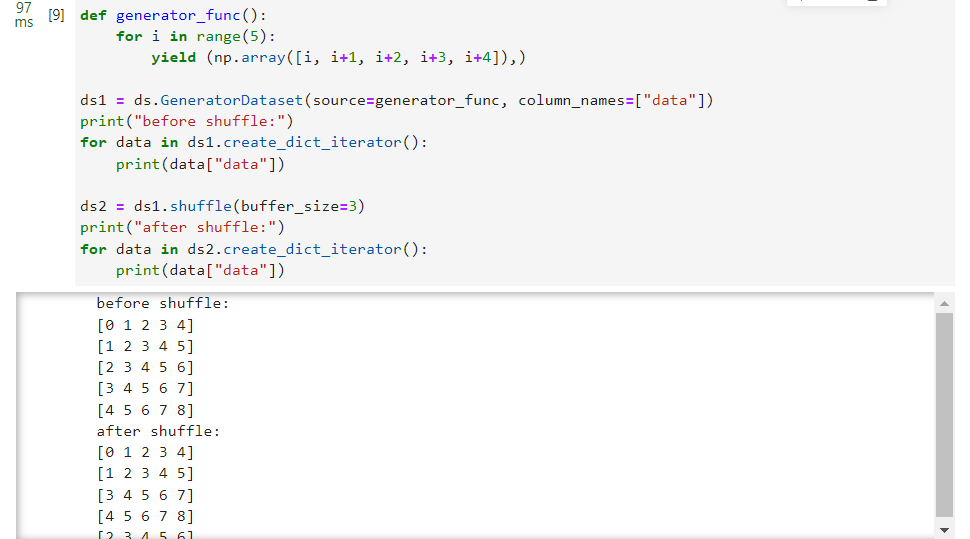
def generator_func():
foriin range(5):
yield (np.array([i, i+1, i+2, i+3, i+4]),)
ds1 = ds.GeneratorDataset(source=generator_func, column_names=["data"])
print("before shuffle:")fordatain ds1.create_dict_iterator():
print(data["data"])
ds2 = ds1.shuffle(buffer_size=3)
print("after shuffle:")fordatain ds2.create_dict_iterator():
print(data["data"])
五、数据增强性能优化
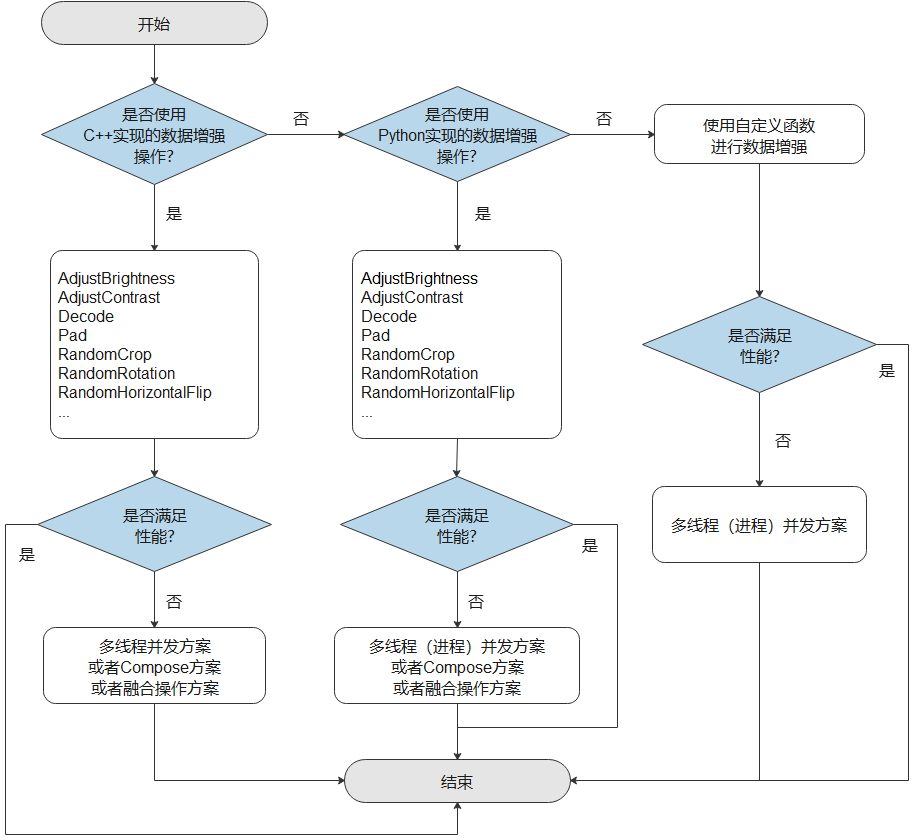
在图片分类的训练中,尤其是当数据集比较小的时候,用户可以使用数据增强的方法来预处理图片,达到丰富数据集的目的。MindSpore为用户提供了多种数据增强操作,其中包括:
- 使用C++代码实现(主要基于OpenCV)的数据增强操作。
- 使用Python代码实现(主要基于Pillow)的数据增强操作。
- 用户可根据特定的需求,自定义Python数据增强函数。
具体的内容请参考数据增强。由于底层的实现方式不同,各个版本的数据增强操作的性能存在一定差异,具体如下所示:
编程语言三方库说明C++OpenCV使用C++代码实现,性能较高PythonPillow使用Python代码实现,更加灵活
性能优化方案
数据增强性能优化建议如下:
- 优先使用实现在C++层的数据增强操作,能获得更好的性能,如果性能仍无法满足需求,可采取多线程优化、Compose优化方案或者算子融合优化。
- 如果使用了实现在Python层的数据增强操作,当性能无法满足需求时,可采取多线程优化方案、多进程优化、compose优化或者算子融合优化。
- 如果用户使用自定义Python函数进行数据增强,当性能仍无法满足需求,可采取多线程优化或者多进程优化,如果还是无法提升性能,就需要对自定义的Python代码进行优化。
MindSpore也支持用户同时使用实现在C++层的和实现在Python层的数据增强操作,但由于两者底层实现不同,过度地混用将增加资源开销,降低处理性能。推荐用户只使用其中的一种,或者先集中使用其中一种,再集中使用另外一种。不要在两种不同实现的数据增强操作中频繁地进行切换。
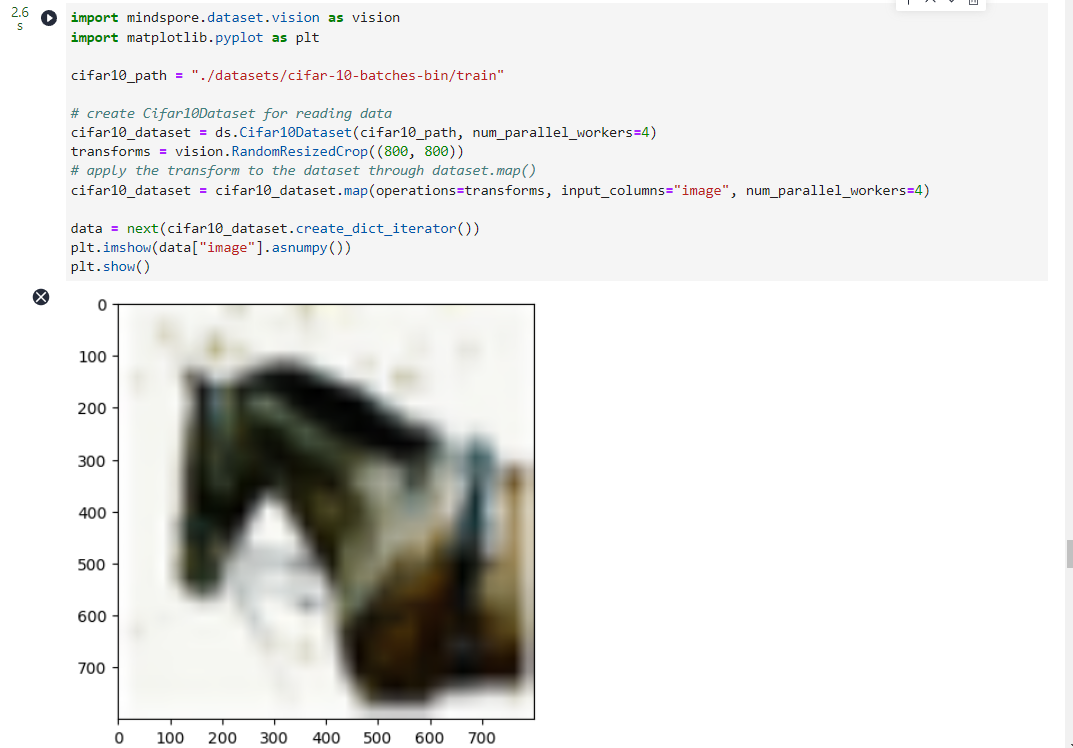
基于以上的数据增强性能优化建议,本次体验分别使用实现在C++层的数据增强操作和自定义Python函数进行数据增强,演示代码如下所示:
1.使用实现在C++层的数据增强操作,采用多线程优化方案,开启了4个线程并发完成任务,并且采用了算子融合优化方案,使用
RandomResizedCrop
融合类替代
RandomResize
类和
RandomCrop
类。
import mindspore.dataset.vision as vision
import matplotlib.pyplot as plt
cifar10_path ="./datasets/cifar-10-batches-bin/train"# create Cifar10Dataset for reading data
cifar10_dataset = ds.Cifar10Dataset(cifar10_path, num_parallel_workers=4)
transforms = vision.RandomResizedCrop((800,800))# apply the transform to the dataset through dataset.map()
cifar10_dataset = cifar10_dataset.map(operations=transforms, input_columns="image", num_parallel_workers=4)
data = next(cifar10_dataset.create_dict_iterator())
plt.imshow(data["image"].asnumpy())
plt.show()
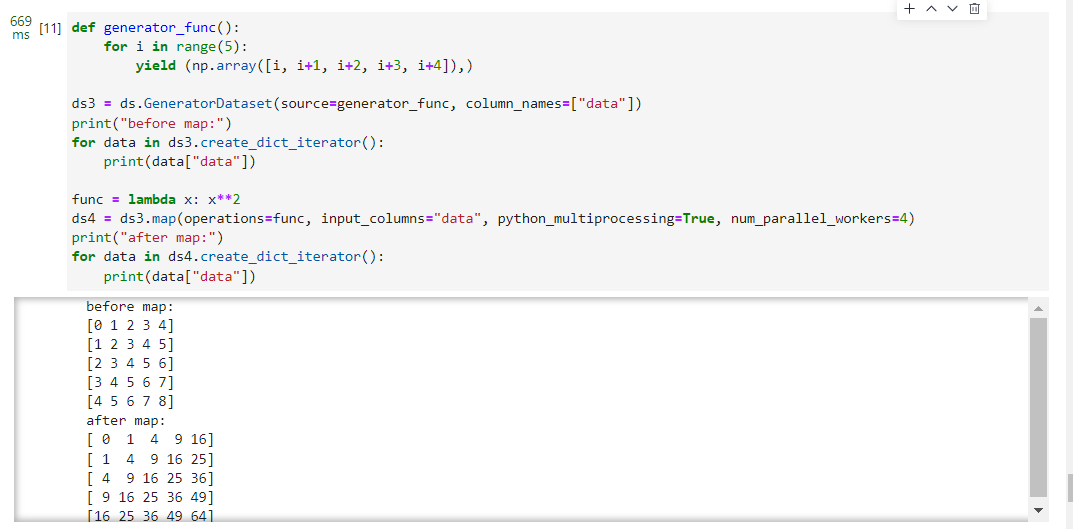
2.使用自定义Python函数进行数据增强,数据增强时采用多进程优化方案,开启了4个进程并发完成任务。
def generator_func():
foriin range(5):
yield (np.array([i, i+1, i+2, i+3, i+4]),)
ds3 = ds.GeneratorDataset(source=generator_func, column_names=["data"])
print("before map:")fordatain ds3.create_dict_iterator():
print(data["data"])
func = lambda x: x**2
ds4 = ds3.map(operations=func, input_columns="data", python_multiprocessing=True, num_parallel_workers=4)
print("after map:")fordatain ds4.create_dict_iterator():
print(data["data"])
六、操作系统性能优化
由于MindSpore的数据处理主要在Host端进行,运行环境的配置也会对处理性能产生影响,主要体现在存储设备、NUMA架构和CPU计算资源等方面。
1.存储设备
数据的加载过程涉及频繁的磁盘操作,磁盘读写的性能直接影响了数据加载的速度。当数据集较大时,推荐使用固态硬盘进行数据存储,固态硬盘的读写速度普遍较普通磁盘高,能够减少I/O操作对数据处理性能的影响。
一般地,加载后的数据将会被缓存到操作系统的页面缓存中,在一定程度上降低了后续读取的开销,加速了后续Epoch的数据加载速度。用户也可以通过MindSpore提供的单节点缓存技术,手动缓存加载增强后的数据,避免了重复的数据加载和数据增强。
2.NUMA架构
NUMA的全称为Non-Uniform Memory Access,即非一致性内存访问,是为了解决传统的对称多处理器(SMP)架构中的可扩展性问题而诞生的一种内存架构。在传统架构中,多个处理器共用一条内存总线,容易产生带宽不足、内存冲突等问题。
而在NUMA架构中,处理器和内存被划分为多个组,每个组称为一个节点(Node),各个节点拥有独立的集成内存控制器(IMC)总线,用于节点内通信,不同节点间则通过快速路径互连(QPI)进行通信。对于某一节点来说,处在同节点内的内存被称为本
numactl --cpubind=0--membind=0 python train.py

3.CPU计算资源
尽管可以通过多线程并行技术加快数据处理的速度,但是实际运行时并不能保证CPU计算资源完全被利用起来。如果能够人为地事先完成计算资源配置的设定,将能在一定程度上提高CPU计算资源的利用率。
- 计算资源的分配
在分布式训练中,同一设备上可能开启多个训练进程。默认情况下,各个进程的资源分配与抢占将会遵循操作系统本身的策略进行,当进程较多时,频繁的资源竞争可能会导致数据处理性能的下降。如果能够事先设定各个进程的计算资源分配,就能避免这种资源竞争带来的开销。
numactl --cpubind=0 python train.py

- CPU频率设置
出于节约能效的考虑,操作系统会根据需要适时调整CPU的运行频率,但更低的功耗意味着计算性能的下降,会减慢数据处理的速度。要想充分发挥CPU的最大算力,需要手动设置CPU的运行频率。如果发现操作系统的CPU运行模式为平衡模式或者节能模式,可以通过将其调整为性能模式,提升数据处理的性能。
cpupower frequency-set -g performance

七、自动数据加速
MindSpore提供了一种自动数据调优的工具——Dataset AutoTune,用于在训练过程中根据环境资源的情况自动调整数据处理管道的并行度,最大化利用系统资源加速数据处理管道的处理速度。详细用法请参考自动数据加速。
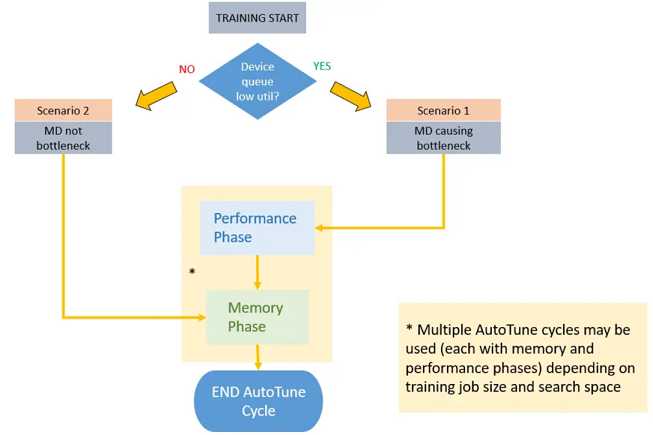
在整个训练的过程中,Dataset
AutoTune模块会持续检测当前训练性能瓶颈处于数据侧还是网络侧。如果检测到瓶颈在数据侧,则将进一步对数据处理管道中的各个算子(如GeneratorDataset、map、batch此类数据算子)进行参数调整,目前可调整的参数包括算子的工作线程数(num_parallel_workers),算子的内部队列深度(prefetch_size)。启动AutoTune后,MindSpore会根据一定的时间间隔,对数据处理管道的资源情况进行采样统计。
当Dataset AutoTune收集到足够的信息时,它会基于这些信息分析当前的性能瓶颈是否在数据侧。 如果是,Dataset
AutoTune将调整数据处理管道的并行度,并加速数据集管道的运算。 如果不是,Dataset
AutoTune也会尝试减少数据管道的内存使用量,为CPU释放一些可用内存。
启动自动数据加速(不保存调优后的推荐配置):
import mindspore.dataset as ds
ds.config.set_enable_autotune(True)
启动自动数据加速并设定调优结果的保存路径:
import mindspore.dataset as ds
ds.config.set_enable_autotune(True, "/path/to/autotune_out")
八、数据异构加速
MindSpore提供了一种运算负载均衡的技术,可以将MindSpore的算子计算分配到不同的异构硬件上,一方面均衡不同硬件之间的运算开销,另一方面利用异构硬件的优势对算子的运算进行加速。详细用法请参考数据异构加速。
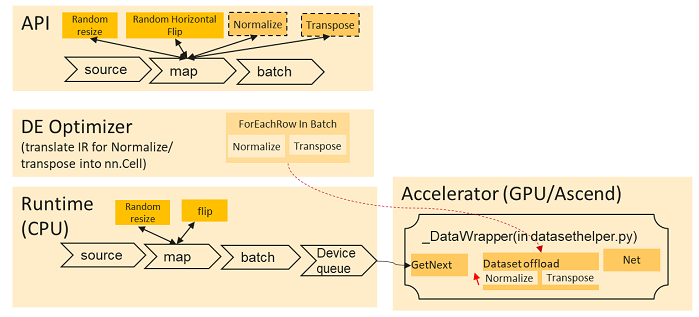
目前该异构硬件加速技术仅支持将数据算子均衡到网络侧,均衡数据处理管道与网络运算的计算开销。具体来说,目前数据处理管道的算子均在CPU侧运算,该功能将部分数据操作从CPU侧“移动”到网络端,利用昇腾Ascend或GPU的计算资源对数据数据处理的算子进行加速。
该功能仅支持将作用于特定数据输入列末端的数据增强操作移至异构侧进行加速,输入列末端指的是作用于该数据的map算子所持有的位于末端且连续的数据增强操作。
下图显示了给定数据处理管道使用异构加速的典型计算过程。
异构加速功能对两个API进行了相关更新以允许用户启用此功能:
- map数据算子新增offload输入参数,
- 数据集全局配置mindspore.dataset.config中新增set_auto_offload接口。
如需检查数据增强算子是否移动至加速器,用户可以保存并检查计算图IR文件。在异构加速功能被启动后,相关计算算子会被写入IR文件中。异构加速功能同时适用于数据集下沉模式(dataset_sink_mode=True)和数据集非下沉模式(dataset_sink_mode=False)。
使用全局配置设置自动异构加速。在这种情况下,所有map数据处理算子的offload参数将设置为True(默认为None)。值得注意的是,如果用户指定特定map操作算子的offload为False,该map算子将直接应用该配置而不是全局配置。
import mindspore.dataset as ds
ds.config.set_auto_offload(True)
版权归原作者 Yeats_Liao 所有, 如有侵权,请联系我们删除。