
在上一篇文章中,我们简单的介绍了MAPPO算法的流程与核心思想,并未结合代码对MAPPO进行介绍,为此,本篇对MAPPO开源代码进行详细解读。
本篇解读超级详细,认真阅读有助于将自己的环境移植到算法中,如果想快速了解此代码,可参考小小何先生的博客
文章目录
代码下载地址
论文名称:
The Surprising Effectiveness of MAPPO in Cooperative, Multi-Agent Games
代码下载地址:
https://github.com/tinyzqh/light_mappo
这是官方提出的轻量型代码,对环境依赖不高,便于结合自己的项目进行改进。
代码总体流程
1)环境设置,设置智能体个数、动作空间维度、观测空间维度
2)初始化环境,将obs输入到actor网络生成action,将cent_obs输入到critic网络生成values
3)计算折扣奖励
4)开始训练,从buffer中抽样数据,计算actor的loss、critic的loss
5)保存模型,计算average episode rewards
环境设置
打开train文件夹下的train.py文件,运行此文件可对模型开始训练。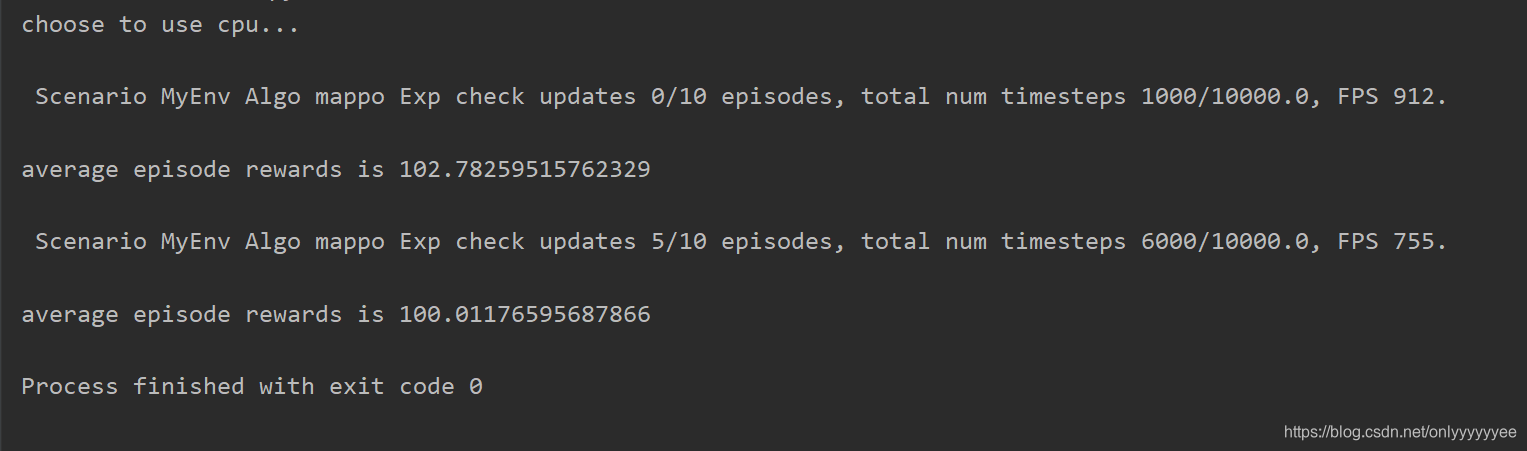
这里我对模型训练总步数进行了更改以方便运行,可在config.py,中更改总运行步数。
parser.add_argument("--num_env_steps",type=int, default=10e3,help='Number of environment steps to train (default: 10e6)')
通过parser = get_config()来把config.py里面的各种环境默认值传递给all_args,定义函数make_train_env(all_args) 和make_eval_env(all_args) 来进行默认参数赋值。
parser = get_config()#这里把config里面的参数传递给all-args
all_args = parse_args(args, parser)
环境的赋值:
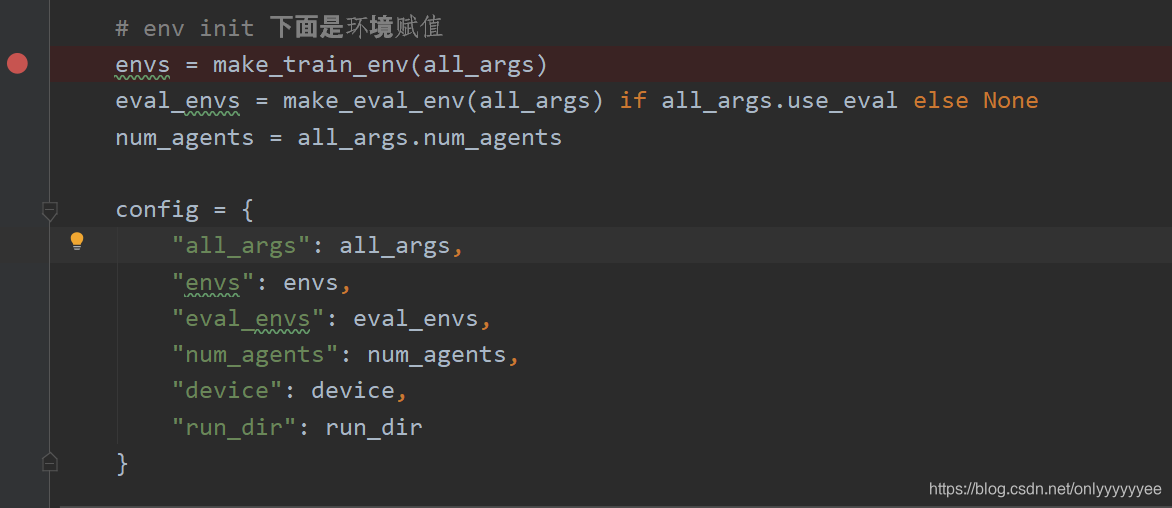
文件中runner = Runner(config)也是对各种参数、训练所用算法、训练所用buffer进行赋值,step into该函数,自动跳转到base_runner.py中可参看具体赋值情况。
from algorithms.algorithm.r_mappo import RMAPPO as TrainAlgo
from algorithms.algorithm.rMAPPOPolicy import RMAPPOPolicy as Policy
简单环境设置及如何更改
在该轻量级代码代码中,并未实例化环境,它只是定义了agent_num、obs_dim、action_dim,但是obs、reward都是随机产生的,actions和values是通过policy.get_actions函数产生的(下面有具体介绍)。
在envs文件夹中env.py来对环境进行查看,agent_num、obs_dim、action_dim默认值分别是2、14、5,在这里我们可以结合自己的项目对这三个数据进行更改,下面我在不改变动作类型的情况下介绍一下如何更改,假如想把它变成4、12、10(可结合情况随意更改),需要更改:
1)env.py中16、17、18行
def__init__(self, i):
self.agent_num =4# 设置智能体(小飞机)的个数,这里设置为两个
self.obs_dim =12# 设置智能体的观测纬度
self.action_dim =10# 设置智能体的动作纬度,这里假定为一个五个纬度的
2)env.py中26、40行
sub_obs = np.random.random(size=(12,))
sub_agent_obs.append(np.random.random(size=(12,)))
3)train.py中34行
parser.add_argument('--num_agents',type=int, default=4,help="number of players")
4)env_wrappers.py中176、194
if self.discrete_action_space:
u_action_space = spaces.Discrete(10)
obs_dim =12
更改完毕,更改完后可以试运行一下。
动作类型更改
代码默认动作类型为diecrete,如果想把动作类型改为continue,需要更改env_wrapper.py的设置。
self.discrete_action_space =True
把这句的True改为False,有两处,操作两次
u_action_space = spaces.Box(low=-1, high=1, shape=(5,), dtype=np.float32)
shape=(5,)代表动作维度,5为动作维度,有两处,操作两次
程序运行流程
在完成上面的各种赋值后,就可以step into算法训练入口runner.run()中去看run函数并一步步调试程序了(此部分的代码大都是env_runner.py里面)。
初始化环境
首先调用warmup函数进行一些数据的初始化,其中的envs.reset函数是用numpy随机生成数据。
defwarmup(self):# reset env 这里是随机初始化环境,用numpy函数随机生成数据
obs = self.envs.reset()# shape = (n_rollout_threads, agent_num,obs_dim )# replay bufferif self.use_centralized_V:#定义share_obs
share_obs = obs.reshape(self.n_rollout_threads,-1)# shape = (n_rollout_threads,agent_num*obs_dim )
share_obs = np.expand_dims(share_obs,1).repeat(self.num_agents, axis=1)# shape = (n_rollout_threads,agent_num,agent_num*obs_dim)else:
share_obs = obs
self.buffer.share_obs[0]= share_obs.copy()
self.buffer.obs[0]= obs.copy()
actions、obs更新
赋值后,就可以进行values、actions等数据的迭代更新了:
start = time.time()
episodes =int(self.num_env_steps)// self.episode_length // self.n_rollout_threads
for episode inrange(episodes):#没隔1000步if self.use_linear_lr_decay:
self.trainer.policy.lr_decay(episode, episodes)for step inrange(self.episode_length):# Sample actions
values, actions, action_log_probs, rnn_states, rnn_states_critic, actions_env = self.collect(step)#上面这行过后actions等变化# Obser reward and next obs
obs, rewards, dones, infos = self.envs.step(actions_env)#上面这行过后obs等变化
data = obs, rewards, dones, infos, values, actions, action_log_probs, rnn_states, rnn_states_critic
# insert data into buffer
self.insert(data)
actions、valus更新
actions通过下面代码来更新:
defcollect(self, step):#并行的环境的数据拼接在一起,这一步是将并行采样的那个纬度降掉
self.trainer.prep_rollout()
value, action, action_log_prob, rnn_states, rnn_states_critic \
= self.trainer.policy.get_actions(np.concatenate(self.buffer.share_obs[step]),
np.concatenate(self.buffer.obs[step]),
np.concatenate(self.buffer.rnn_states[step]),
np.concatenate(self.buffer.rnn_states_critic[step]),
np.concatenate(self.buffer.masks[step]))#生成拼接型的value、action原始数据,用于下面values和actions的生成#action_log_prob是计算action在定义的正态分布对应的概率的对数# [self.envs, agents, dim]
values = np.array(np.split(_t2n(value), self.n_rollout_threads))#将value转化成5层4行1列的数据
actions = np.array(np.split(_t2n(action), self.n_rollout_threads))#这action转化成5层4行1列的数据
action_log_probs = np.array(np.split(_t2n(action_log_prob), self.n_rollout_threads))
rnn_states = np.array(np.split(_t2n(rnn_states), self.n_rollout_threads))
rnn_states_critic = np.array(np.split(_t2n(rnn_states_critic), self.n_rollout_threads))#下面是get_actions的功能,在rMAPPOPolicy.py里defget_actions(self, cent_obs, obs, rnn_states_actor, rnn_states_critic, masks, available_actions=None,
deterministic=False):
actions, action_log_probs, rnn_states_actor = self.actor(obs,#调用actor去获取动作和动作的对数概率
rnn_states_actor,
masks,
available_actions,
deterministic)
values, rnn_states_critic = self.critic(cent_obs, rnn_states_critic, masks)#调用critic去对动作打分,得到valuesreturn values, actions, action_log_probs, rnn_states_actor, rnn_states_critic
而后通过140行的语句将actions传递给action_env。
下面解释一下actions里面数据的含义。如这里定义agent_num=4,action_dim=10,生成的actions数据会有4行,动作值最大不会超过9。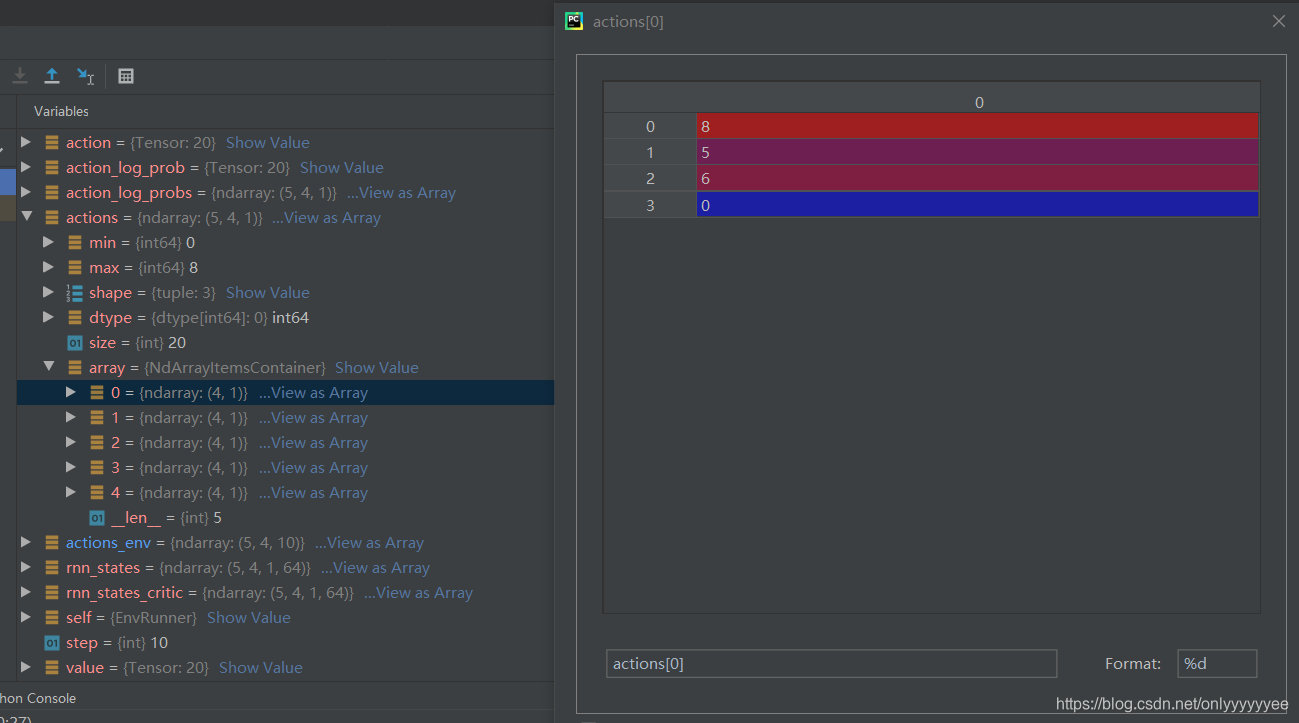
生成的8、5、6、0分别代表在dim-8、dim-5、dim-6、dim-0处应用动作: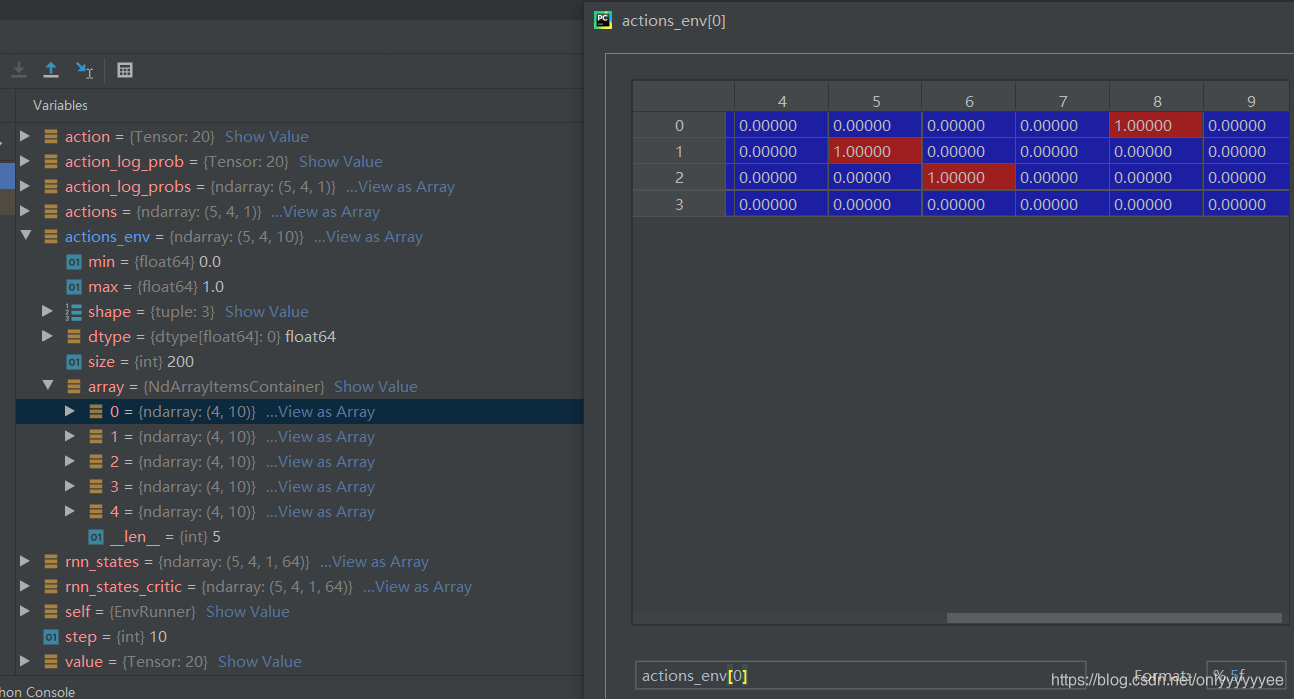
obs、reward更新
#这里给奖励、状态的具体数据,zip函数将可迭代的对象作为参数,将对象中对应的元素打包成一个元祖,然后返回有这些元祖组成的列表defstep(self, actions):
results =[env.step(action)for env, action inzip(self.env_list, actions)]
obs, rews, dones, infos =zip(*results)#这一行后状态开始变化return np.stack(obs), np.stack(rews), np.stack(dones), infos
obs(next)、reward获得在env.py里面,由于这个轻量型代码没有设置具体环境,这里的obs(next)、reward都是随机生成的在加入自己的环境时,注意env.step里面的dones、info,dones表示本回合的结束,dones默认为false,在实例型的代码中,dones在智能体死亡或满足特定条件时为true,info这个不重要,只有在可视化环境时才用到:
defstep(self, actions):#定义obs、reward的更新方式,在这里它是随机生成的,可以结合自己项目对更新方式进行定义
sub_agent_obs =[]
sub_agent_reward =[]
sub_agent_done =[]
sub_agent_info =[]for i inrange(self.agent_num):
sub_agent_obs.append(np.random.random(size=(12,)))#这里的obs是在[0,1]之间随机产生的
sub_agent_reward.append([np.random.rand()])#通过本函数可以返回一个或一组服从“0~1”均匀分布的随机样本值。随机样本取值范围是[0,1),不包括1。
sub_agent_done.append(False)
sub_agent_info.append({})return[sub_agent_obs, sub_agent_reward, sub_agent_done, sub_agent_info]
折扣回报计算
每隔episode_length=200步用compute函数计算一下折扣回报:
defcompute(self):#计算这个episode的折扣回报,先用rMAPPOPolicy.py里面的get_values计算一下next_values"""Calculate returns for the collected data."""
self.trainer.prep_rollout()
next_values = self.trainer.policy.get_values(np.concatenate(self.buffer.share_obs[-1]),
np.concatenate(self.buffer.rnn_states_critic[-1]),
np.concatenate(self.buffer.masks[-1]))
next_values = np.array(np.split(_t2n(next_values), self.n_rollout_threads))
self.buffer.compute_returns(next_values, self.trainer.value_normalizer)#折扣回报的的计算方式
开始训练
deftrain(self):#算完折扣回报之后调用self.train()函数进行训练"""Train policies with data in buffer. """
self.trainer.prep_training()#将网络设置为train()的格式
train_infos = self.trainer.train(self.buffer)
self.buffer.after_update()#将buffer的第一个元素设置为其episode最后的一个元素return train_infos
step_into train_infos = self.trainer.train(self.buffer),在self.trainer.train(self.buffer)函数中先基于数据,计算优势函数(优势函数是针对全局的观测信息所得到的):
if self._use_popart or self._use_valuenorm:#优势函数计算
advantages =buffer.returns[:-1]- self.value_normalizer.denormalize(buffer.value_preds[:-1])else:
advantages =buffer.returns[:-1]-buffer.value_preds[:-1]
advantages_copy = advantages.copy()
advantages_copy[buffer.active_masks[:-1]==0.0]= np.nan
mean_advantages = np.nanmean(advantages_copy)
std_advantages = np.nanstd(advantages_copy)
advantages =(advantages - mean_advantages)/(std_advantages +1e-5)
然后从buffer抽样数据,将抽样的数据里的obs送给actor网络,得到action_log_probs, dist_entropy,把cent_obs送到critic得到新的values。
for sample in data_generator:
value_loss, critic_grad_norm, policy_loss, dist_entropy, actor_grad_norm, imp_weights \
= self.ppo_update(sample, update_actor)#调用ppo_update函数
ppo_update函数大体流程是:
1)从buffer中抽样建立sample
2)将抽样的数据传递给rMAPPOPolicy.py中的evaluate_actions函数,得到values, action_log_probs, dist_entropy
3)计算actor的loss
4)计算critic的loss
defppo_update(self, sample, update_actor=True):"""
Update actor and critic networks.
:param sample: (Tuple) contains data batch with which to update networks.
:update_actor: (bool) whether to update actor network.
:return value_loss: (torch.Tensor) value function loss.
:return critic_grad_norm: (torch.Tensor) gradient norm from critic up9date.
;return policy_loss: (torch.Tensor) actor(policy) loss value.
:return dist_entropy: (torch.Tensor) action entropies.
:return actor_grad_norm: (torch.Tensor) gradient norm from actor update.
:return imp_weights: (torch.Tensor) importance sampling weights.
"""
share_obs_batch, obs_batch, rnn_states_batch, rnn_states_critic_batch, actions_batch, \
value_preds_batch, return_batch, masks_batch, active_masks_batch, old_action_log_probs_batch, \
adv_targ, available_actions_batch = sample #然后从buffer中采样数据,把线程、智能体的纬度全部降掉
old_action_log_probs_batch = check(old_action_log_probs_batch).to(**self.tpdv)
adv_targ = check(adv_targ).to(**self.tpdv)
value_preds_batch = check(value_preds_batch).to(**self.tpdv)
return_batch = check(return_batch).to(**self.tpdv)
active_masks_batch = check(active_masks_batch).to(**self.tpdv)# Reshape to do in a single forward pass for all steps
values, action_log_probs, dist_entropy = self.policy.evaluate_actions(share_obs_batch,
obs_batch,
rnn_states_batch,
rnn_states_critic_batch,
actions_batch,
masks_batch,
available_actions_batch,
active_masks_batch)# actor update 计算actor的loss
imp_weights = torch.exp(action_log_probs - old_action_log_probs_batch)
surr1 = imp_weights * adv_targ
surr2 = torch.clamp(imp_weights,1.0- self.clip_param,1.0+ self.clip_param)* adv_targ
if self._use_policy_active_masks:
policy_action_loss =(-torch.sum(torch.min(surr1, surr2),
dim=-1,
keepdim=True)* active_masks_batch).sum()/ active_masks_batch.sum()else:
policy_action_loss =-torch.sum(torch.min(surr1, surr2), dim=-1, keepdim=True).mean()
policy_loss = policy_action_loss
self.policy.actor_optimizer.zero_grad()if update_actor:(policy_loss - dist_entropy * self.entropy_coef).backward()if self._use_max_grad_norm:
actor_grad_norm = nn.utils.clip_grad_norm_(self.policy.actor.parameters(), self.max_grad_norm)else:
actor_grad_norm = get_gard_norm(self.policy.actor.parameters())
self.policy.actor_optimizer.step()# critic update 计算critic的loss
value_loss = self.cal_value_loss(values, value_preds_batch, return_batch, active_masks_batch)
self.policy.critic_optimizer.zero_grad()(value_loss * self.value_loss_coef).backward()if self._use_max_grad_norm:
critic_grad_norm = nn.utils.clip_grad_norm_(self.policy.critic.parameters(), self.max_grad_norm)else:
critic_grad_norm = get_gard_norm(self.policy.critic.parameters())
self.policy.critic_optimizer.step()return value_loss, critic_grad_norm, policy_loss, dist_entropy, actor_grad_norm, imp_weights
结语
此篇轻量型代码较为简单易懂,在使用时只需要把自己的环境在env.py文件中即可,其它方面不用可结合实际情况更改。
如果对MAPPO算法流程不太了解,可以参考我的另一篇文章MAPPO算法理论知识,本人水平有限,如有错误,欢迎指出!!!
参考文献:
[1]MAPPO-Joint Optimization of Handover Control and Power Allocation Based on Multi-Agent Deep Reinforcement Learning.
[2]The Surprising Effectiveness of MAPPO in Cooperative, Multi-Agent Games.
[3]多智能体强化学习(二) MAPPO算法详解
版权归原作者 onlyyyyyyee 所有, 如有侵权,请联系我们删除。