
文章目录
ACmix网络理论简介
ACmix是卷积网络和transformer两种强大的网络优势的集合,具有较低的计算开销,同时也能提升网络性能,在卷积网络和transformer各行其是的今天,是一种融合两种优势的不错方法。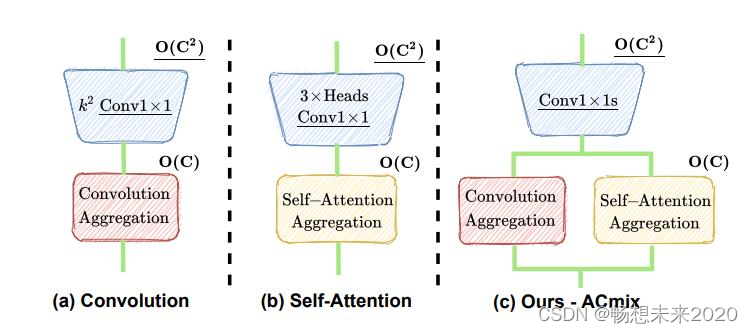
首先,通过使用1X1卷积对输入特征进行映射,获得丰富的中间特征集;
然后,按照不同的模式(分别以Self-Attention方式和卷积方式)重用和聚合中间特征。
主要贡献:
1.揭示了Self-Attention和卷积之间强大的潜在关系,为理解两个模块之间的联系提供了新的视角,并为设计新的学习范式提供了灵感;
2.介绍了Self-Attention和卷积模块的一个优雅集成,它享受这两者的优点。经验证据表明,混合模型始终优于其纯卷积或Self-Attention对应模型。
结论:
相比于普通卷积效果有所提升,但是相应计算量也比较大。
源码:
https://github.com/LeapLabTHU/ACmix
YOLOv7集成ACmix
修改结构配置yaml文件
新建一个
yolov7_acmix.yaml
文件,添加如下内容
# parametersnc:80# number of classesdepth_multiple:1.0# model depth multiplewidth_multiple:1.0# layer channel multiple# anchorsanchors:-[12,16,19,36,40,28]# P3/8-[36,75,76,55,72,146]# P4/16-[142,110,192,243,459,401]# P5/32# yolov7 backbonebackbone:# [from, number, module, args][[-1,1, Conv,[32,3,1]],# 0[-1,1, Conv,[64,3,2]],# 1-P1/2 [-1,1, Conv,[64,3,1]],[-1,1, Conv,[128,3,2]],# 3-P2/4 [-1,1, Conv,[64,1,1]],[-2,1, Conv,[64,1,1]],[-1,1, Conv,[64,3,1]],[-1,1, Conv,[64,3,1]],[-1,1, Conv,[64,3,1]],[-1,1, Conv,[64,3,1]],[[-1,-3,-5,-6],1, Concat,[1]],[-1,1, Conv,[256,1,1]],# 11[-1,1, MP,[]],[-1,1, Conv,[128,1,1]],[-3,1, Conv,[128,1,1]],[-1,1, Conv,[128,3,2]],[[-1,-3],1, Concat,[1]],# 16-P3/8 [-1,1, Conv,[128,1,1]],[-2,1, Conv,[128,1,1]],[-1,1, Conv,[128,3,1]],[-1,1, Conv,[128,3,1]],[-1,1, Conv,[128,3,1]],[-1,1, Conv,[128,3,1]],[[-1,-3,-5,-6],1, Concat,[1]],[-1,1, Conv,[512,1,1]],# 24[-1,1, MP,[]],[-1,1, Conv,[256,1,1]],[-3,1, Conv,[256,1,1]],[-1,1, Conv,[256,3,2]],[[-1,-3],1, Concat,[1]],# 29-P4/16 [-1,1, Conv,[256,1,1]],[-2,1, Conv,[256,1,1]],[-1,1, Conv,[256,3,1]],[-1,1, Conv,[256,3,1]],[-1,1, Conv,[256,3,1]],[-1,1, Conv,[256,3,1]],[[-1,-3,-5,-6],1, Concat,[1]],[-1,1, Conv,[1024,1,1]],# 37[-1,1, MP,[]],[-1,1, Conv,[512,1,1]],[-3,1, Conv,[512,1,1]],[-1,1, Conv,[512,3,2]],[[-1,-3],1, Concat,[1]],# 42-P5/32 [-1,1, Conv,[256,1,1]],[-2,1, Conv,[256,1,1]],[-1,1, Conv,[256,3,1]],[-1,1, Conv,[256,3,1]],[-1,1, Conv,[256,3,1]],[-1,1, Conv,[256,3,1]],[[-1,-3,-5,-6],1, Concat,[1]],[-1,1, Conv,[1024,1,1]],# 50]# yolov7 headhead:[[-1,1, SPPCSPC,[512]],# 51[-1,1, Conv,[256,1,1]],[-1,1, nn.Upsample,[None,2,'nearest']],[37,1, Conv,[256,1,1]],# route backbone P4[[-1,-2],1, Concat,[1]],[-1,1, Conv,[256,1,1]],[-2,1, Conv,[256,1,1]],[-1,1, Conv,[128,3,1]],[-1,1, Conv,[128,3,1]],[-1,1, Conv,[128,3,1]],[-1,1, Conv,[128,3,1]],[[-1,-2,-3,-4,-5,-6],1, Concat,[1]],[-1,1, Conv,[256,1,1]],# 63[-1,1, Conv,[128,1,1]],[-1,1, nn.Upsample,[None,2,'nearest']],[24,1, Conv,[128,1,1]],# route backbone P3[[-1,-2],1, Concat,[1]],[-1,1, Conv,[128,1,1]],[-2,1, Conv,[128,1,1]],[-1,1, Conv,[64,3,1]],[-1,1, Conv,[64,3,1]],[-1,1, Conv,[64,3,1]],[-1,1, Conv,[64,3,1]],[[-1,-2,-3,-4,-5,-6],1, Concat,[1]],[-1,1, Conv,[128,1,1]],# 75[-1,1, MP,[]],[-1,1, Conv,[128,1,1]],[-3,1, Conv,[128,1,1]],[-1,1, Conv,[128,3,2]],[[-1,-3,63],1, Concat,[1]],[-1,1, Conv,[256,1,1]],[-2,1, Conv,[256,1,1]],[-1,1, Conv,[128,3,1]],[-1,1, Conv,[128,3,1]],[-1,1, Conv,[128,3,1]],[-1,1, Conv,[128,3,1]],[[-1,-2,-3,-4,-5,-6],1, Concat,[1]],[-1,1, Conv,[256,1,1]],# 88[-1,1, MP,[]],[-1,1, Conv,[256,1,1]],[-3,1, Conv,[256,1,1]],[-1,1, Conv,[256,3,2]],[[-1,-3,51],1, Concat,[1]],[-1,1, Conv,[512,1,1]],[-2,1, Conv,[512,1,1]],[-1,1, Conv,[256,3,1]],[-1,1, Conv,[256,3,1]],[-1,1, Conv,[256,3,1]],[-1,1, ACmix,[256]],#9 修改[[-1,-2,-3,-4,-5,-6],1, Concat,[1]],[-1,1, Conv,[512,1,1]],# 101[75,1, RepConv,[256,3,1]],[88,1, RepConv,[512,3,1]],[101,1, RepConv,[1024,3,1]],[[102,103,104],1, IDetect,[nc, anchors]],# Detect(P3, P4, P5)]# [-1, 1, ACmix, [1024]], #9
修改common.py文件
在
./models/common.py
文件中,添加以下内容
defposition(H, W, is_cuda=True):if is_cuda:
loc_w = torch.linspace(-1.0,1.0, W).cuda().unsqueeze(0).repeat(H,1)
loc_h = torch.linspace(-1.0,1.0, H).cuda().unsqueeze(1).repeat(1, W)else:
loc_w = torch.linspace(-1.0,1.0, W).unsqueeze(0).repeat(H,1)
loc_h = torch.linspace(-1.0,1.0, H).unsqueeze(1).repeat(1, W)
loc = torch.cat([loc_w.unsqueeze(0), loc_h.unsqueeze(0)],0).unsqueeze(0)return loc
defstride(x, stride):
b, c, h, w = x.shape
return x[:,:,::stride,::stride]definit_rate_half(tensor):if tensor isnotNone:
tensor.data.fill_(0.5)definit_rate_0(tensor):if tensor isnotNone:
tensor.data.fill_(0.)classACmix(nn.Module):def__init__(self, in_planes, out_planes, kernel_att=7, head=4, kernel_conv=3, stride=1, dilation=1):super(ACmix, self).__init__()
self.in_planes = in_planes
self.out_planes = out_planes
self.head = head
self.kernel_att = kernel_att
self.kernel_conv = kernel_conv
self.stride = stride
self.dilation = dilation
self.rate1 = torch.nn.Parameter(torch.Tensor(1))
self.rate2 = torch.nn.Parameter(torch.Tensor(1))
self.head_dim = self.out_planes // self.head
self.conv1 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv3 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv_p = nn.Conv2d(2, self.head_dim, kernel_size=1)
self.padding_att =(self.dilation *(self.kernel_att -1)+1)//2
self.pad_att = torch.nn.ReflectionPad2d(self.padding_att)
self.unfold = nn.Unfold(kernel_size=self.kernel_att, padding=0, stride=self.stride)
self.softmax = torch.nn.Softmax(dim=1)
self.fc = nn.Conv2d(3*self.head, self.kernel_conv * self.kernel_conv, kernel_size=1, bias=False)
self.dep_conv = nn.Conv2d(self.kernel_conv * self.kernel_conv * self.head_dim, out_planes, kernel_size=self.kernel_conv, bias=True, groups=self.head_dim, padding=1, stride=stride)
self.reset_parameters()defreset_parameters(self):
init_rate_half(self.rate1)
init_rate_half(self.rate2)
kernel = torch.zeros(self.kernel_conv * self.kernel_conv, self.kernel_conv, self.kernel_conv)for i inrange(self.kernel_conv * self.kernel_conv):
kernel[i, i//self.kernel_conv, i%self.kernel_conv]=1.
kernel = kernel.squeeze(0).repeat(self.out_planes,1,1,1)
self.dep_conv.weight = nn.Parameter(data=kernel, requires_grad=True)
self.dep_conv.bias = init_rate_0(self.dep_conv.bias)defforward(self, x):
q, k, v = self.conv1(x), self.conv2(x), self.conv3(x)
scaling =float(self.head_dim)**-0.5
b, c, h, w = q.shape
h_out, w_out = h//self.stride, w//self.stride
# ### att# ## positional encoding
pe = self.conv_p(position(h, w, x.is_cuda))
q_att = q.view(b*self.head, self.head_dim, h, w)* scaling
k_att = k.view(b*self.head, self.head_dim, h, w)
v_att = v.view(b*self.head, self.head_dim, h, w)if self.stride >1:
q_att = stride(q_att, self.stride)
q_pe = stride(pe, self.stride)else:
q_pe = pe
unfold_k = self.unfold(self.pad_att(k_att)).view(b*self.head, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out)# b*head, head_dim, k_att^2, h_out, w_out
unfold_rpe = self.unfold(self.pad_att(pe)).view(1, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out)# 1, head_dim, k_att^2, h_out, w_out
att =(q_att.unsqueeze(2)*(unfold_k + q_pe.unsqueeze(2)- unfold_rpe)).sum(1)# (b*head, head_dim, 1, h_out, w_out) * (b*head, head_dim, k_att^2, h_out, w_out) -> (b*head, k_att^2, h_out, w_out)
att = self.softmax(att)
out_att = self.unfold(self.pad_att(v_att)).view(b*self.head, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out)
out_att =(att.unsqueeze(1)* out_att).sum(2).view(b, self.out_planes, h_out, w_out)## conv
f_all = self.fc(torch.cat([q.view(b, self.head, self.head_dim, h*w), k.view(b, self.head, self.head_dim, h*w), v.view(b, self.head, self.head_dim, h*w)],1))
f_conv = f_all.permute(0,2,1,3).reshape(x.shape[0],-1, x.shape[-2], x.shape[-1])
out_conv = self.dep_conv(f_conv)return self.rate1 * out_att + self.rate2 * out_conv
修改yolo.py文件
在
./models/yolo.py
文件下里的
parse_model
函数,将ACmix类名添加上
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']):
内部对应位置,需要增加以下内容
elif m in[ACmix]:
c1, c2 = ch[f], args[0]if c2 != no:# if not output
c2 = make_divisible(c2 * gw,8)
args =[c1, c2,*args[1:]]
PS
出现RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.cuda.HalfTensor) should be the same解决办法: 跑包含
Acmix结构的网络,直接将test.py的
half_precision参数改成false
利用yolov7_acmix.yaml训练模型
python train.py --cfg yolov7_acmix.yaml --acmix
本文转载自: https://blog.csdn.net/weixin_39588099/article/details/132082036
版权归原作者 畅想未来2020 所有, 如有侵权,请联系我们删除。
版权归原作者 畅想未来2020 所有, 如有侵权,请联系我们删除。