
在python的数据分析中,使用apply(),map(),applymap(),可以方便地实现对批量数据的自定义操作。其用法归纳如下。
文章目录
函数用法apply()用于对DataFrame中的数据进行按行或者按列 操作map()用于对Series中的每一个数据 操作applymap()用于对DataFrame的 每一个数据操作
示例
apply()
apply()用于对DataFrame中的数据进行按行或者按列 操作。
import pandas as pd
data =[[110,120,110],[130,130,130],[130,120,130]]
columns =['语文','数学','英语']
df = pd.DataFrame(data=data, columns=columns)print(df)print("=============================")print(df.apply(lambda x: x.sum(), axis=1))

其中axis=1表示对行操作。若axis为0则表示对列操作。
map()
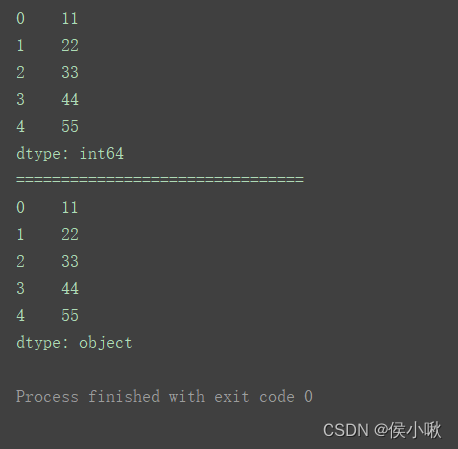
map()用于对Series中的每一个数据 操作。
import pandas as pd
s1 = pd.Series([11,22,33,44,55])print(s1)print("================================")print(s1.map(lambda x:str(x)))
applymap
applymap()用于对DataFrame的 每一个数据操作。
操作DataFrame的每一个数据。
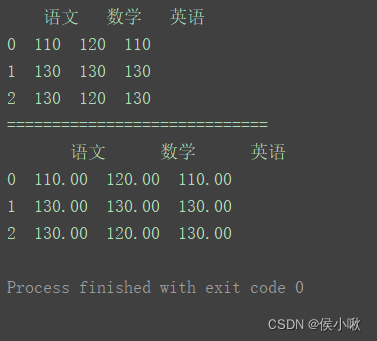
以将每一个数据保留两位小数为例:
import pandas as pd
data =[[110,120,110],[130,130,130],[130,120,130]]
columns =['语文','数学','英语']
df = pd.DataFrame(data=data, columns=columns)print(df)print("=============================")print(df.applymap(lambda x:'%.2f'%x))
本文转载自: https://blog.csdn.net/weixin_48964486/article/details/123307049
版权归原作者 侯小啾 所有, 如有侵权,请联系我们删除。
版权归原作者 侯小啾 所有, 如有侵权,请联系我们删除。