
📚博客主页:knighthood2001
✨公众号:认知up吧 (目前正在带领大家一起提升认知,感兴趣可以来围观一下)
🎃知识星球:【认知up吧|成长|副业】介绍
❤️感谢大家点赞👍🏻收藏⭐评论✍🏻,您的三连就是我持续更新的动力❤️
🙏笔者水平有限,欢迎各位大佬指点,相互学习进步!
vgg16网络架构
前言
很多时候,对于一些网络结构,我们总是会看到其对应的图片,但是代码部分,讲的人不是很多。
比如,下面这两张图片,就是讲解VGG16的博客或者视频中经常能够看到的。
下面这张图片的D类型是VGG16架构,E类型是VGG19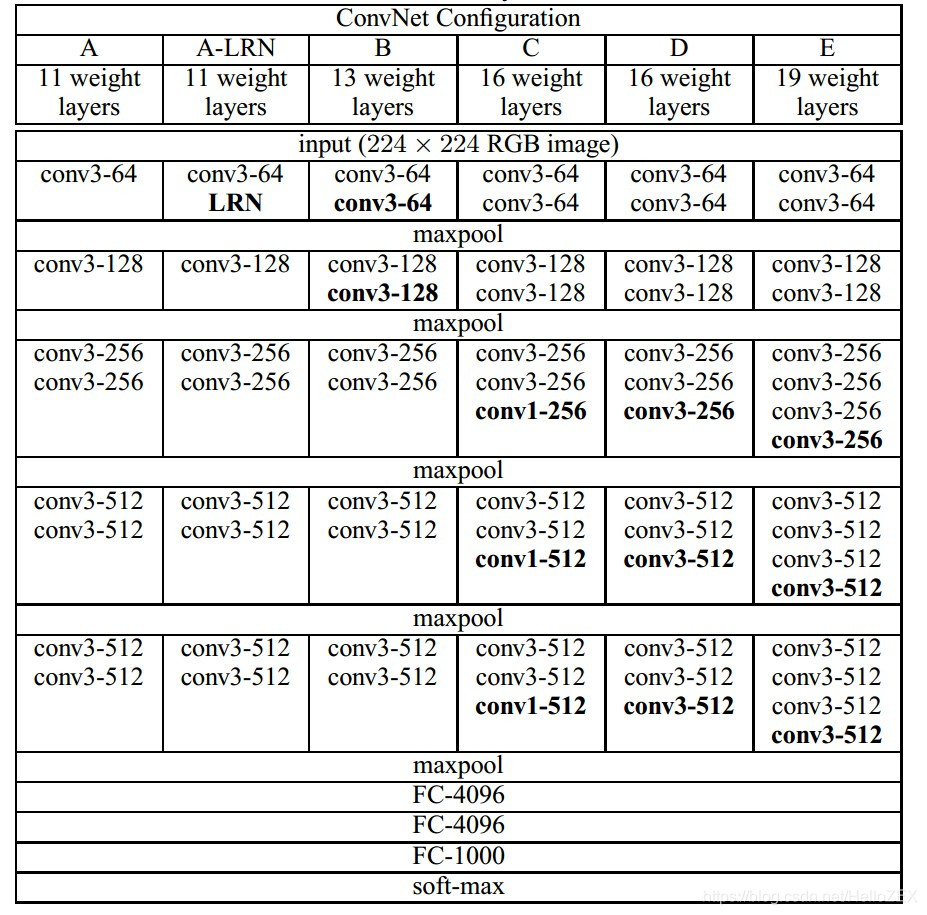
初次见到这种图片,其实不是特别清楚,就导致很多人对网络结构其实不是那么清楚。
比如,conv3-64是啥意思等等。
因此,我接下来打算使用pytorch代码进行讲解。尤其是对于构造网络时候的参数,需要一步一步计算后,才会有比较清晰的理解。
图片讲解
从上面两张图片,可以看出网络结构:
卷积层(+relu激活函数)
卷积层(+relu激活函数)
最大池化层
卷积层(+relu激活函数)
卷积层(+relu激活函数)
最大池化层
卷积层(+relu激活函数)
卷积层(+relu激活函数)
卷积层(+relu激活函数)
最大池化层
卷积层(+relu激活函数)
卷积层(+relu激活函数)
卷积层(+relu激活函数)
最大池化层
卷积层(+relu激活函数)
卷积层(+relu激活函数)
卷积层(+relu激活函数)
最大池化层
全连接层(+relu激活函数)
全连接层(+relu激活函数)
全连接层
除去最大池化层,刚好16层(relu激活函数不算层数)。
数据维度讲解(含代码)
搞清楚层数后,接着开始看数据维度。
对于VGG16这样的经典模型,其设计是基于224x224大小的输入图像的。这个尺寸不是随意确定的,而是经过仔细考虑和实验确定的。因此这里暂时先不考虑更改成其他数据。
首先,输入图像维度是2242243,图片大小是224224,通道数是3。
输出图像维度是22422464,图片大小是224224,通道数是64。
至于卷积核,说是3*3的(这个我也不知道从哪里看的,可能需要去看原作者的论文)。
至于padding:
在卷积神经网络中,padding(填充)是指在输入图像周围添加额外的像素,以便在进行卷积操作时可以保持输入和输出的尺寸相同或者更接近。
padding='same'
是一种常见的填充方式,它的含义是将输入的每一侧都填充足够的零值,以使输出与输入的尺寸相同。
通常图像大小的计算公式是,假设输入图像的大小为NxN,卷积核的大小为FxF,如果没有填充(padding=‘valid’),则输出图像的大小为(N-F+1)x(N-F+1)。而如果进行了填充(padding=‘same’),则在输入图像的周围填充了P个像素,使得输出图像的大小变为N+2P。
使用
padding='same'
填充时,通常选择填充的数量P,使得输出图像的大小与输入图像的大小相同。这样做有助于在卷积操作中保持输入输出尺寸的一致性,同时有助于减少信息丢失。
第一层
在224224图像中,卷积核为33,如果没有在周围填充,那么最后的输出图像大小就是(224-3+1)(224-3+1)=222222,就和原来输入图像大小不相同了。
如果padding=1,则在224224图像外围添加1个单位的行和列。最终图片就变成了226226,在利用上面的公式,对于卷积核为33,最终输出图像大小就是(226-3+1)(226-3+1)=224*224,和原始图片大小一样,保证了图像大小的一致性。
因此VGG16网络的第一层就是这样:
self.conv1 = nn.Conv2d(3,64, kernel_size=3, padding=1)
self.relu1 = nn.ReLU(inplace=True)
注意,激活函数不会改变数据的维度。
数据维度变化:2242243->22422464
第二层
对于第二层,其图像大小就是第一层输出的图像大小,为224*224,其输入通道就是第一层的输出通道,为64,输出通道为64。因此第二层代码如下:
self.conv2 = nn.Conv2d(64,64, kernel_size=3, padding=1)
self.relu2 = nn.ReLU(inplace=True)
数据维度变化:22422464->22422464
池化层1
接着,就到了一个最大池化层:
最大池化层(Max Pooling Layer)是卷积神经网络中常用的一种池化操作。在最大池化层中,通过在每个池化窗口中选择最大值来减小特征图的尺寸。最大池化层通常用于减少特征图的空间维度,从而降低模型的计算量,同时保留重要的特征。
最大池化层的工作原理如下:
- 首先,将输入特征图划分为不重叠的矩形区域(池化窗口)。
- 对于每个池化窗口,从窗口内提取出一个值,通常是窗口内的最大值(即最大池化)。
- 最终,输出的特征图尺寸减小,但保留了最显著的特征。
最大池化层具有以下几个重要的参数:
- 池化窗口大小:确定了每次池化操作中提取的区域大小。
- 步长(stride):确定了池化窗口在输入特征图上滑动的步长。
- 填充(padding):可选参数,用于控制在特征图周围是否进行填充操作。
最大池化层通常用于卷积神经网络的不同层次,可以帮助网络在保持重要特征的同时降低维度,提高计算效率。
在VGG16中,最大池化层的池化窗口大小是2,步长也是2。且不会改变通道数。
由于池化窗口=2,因此如果步长是1的话,就在22的数据区域内选择1个最大值,然后以1为间隔平移。最后数据变化应该是**数据维度变化:22422464->(224-2+1)(224-2+1)64也就是(22322364*
但是如果池化窗口大小是2,步长也是2,那么每次移动2格子,刚好使得图像大小减半,使得数据维度变化:22422464->11211264
self.max_pooling1 = nn.MaxPool2d(kernel_size=2, stride=2)
数据维度变化:22422464->11211264
第三层
经过最大池化层后,数据维度已经变成11211264,查看VGG16架构图,我们看到第三个卷积层,需要将其通道数变成128。并且图像大小不发生改变,因此这里当kernel_size=3时候padding=1。
上面的数据维度转换,我讲了很多,目的就是带着大家一起感受维度的变化,因为神经网络本质就是矩阵运算,一旦出现维度的不同,就会报错。
self.conv3 = nn.Conv2d(64,128, kernel_size=3, padding=1)
self.relu3 = nn.ReLU(inplace=True)
数据维度变化:11211264->112112128
第四层
经过第三层时,数据维度已经变成112112128,查看VGG16架构图,我们看到第四个卷积层其通道数还是128。因此代码没什么变化,就是把输入通道数改成第三层的输出通道数,也就是128。
self.conv4 = nn.Conv2d(128,128, kernel_size=3, padding=1)
self.relu4 = nn.ReLU(inplace=True)
数据维度变化:112112128->112112128
池化层2
经过第四层时,数据维度已经变成112112128,因此当经过
kernel_size=2, stride=2
的最大池化层时候,图片大小减半,通道数不变
self.max_pooling2 = nn.MaxPool2d(kernel_size=2, stride=2)
数据维度变化:112112128->5656128
第五层
经过最大池化层后,数据维度已经变成5656128,查看VGG16架构图,我们看到第五个卷积层,需要将其通道数变成256。并且图像大小不发生改变,因此这里当kernel_size=3时候padding=1。
self.conv5 = nn.Conv2d(128,256, kernel_size=3, padding=1)
self.relu5 = nn.ReLU(inplace=True)
数据维度变化:5656128->5656256
第六层~第七层
经过第五层时,数据维度已经变成5656256,查看VGG16架构图,我们看到第六个和第七个卷积层其通道数还是256。因此代码如下(这里我把两个层不单独讲了,大家也能看懂了吧)
self.conv6 = nn.Conv2d(256,256, kernel_size=3, padding=1)
self.relu6 = nn.ReLU(inplace=True)
self.conv7 = nn.Conv2d(256,256, kernel_size=3, padding=1)
self.relu7 = nn.ReLU(inplace=True)
数据维度变化:5656256->5656256->5656256
池化层3
经过第七层时,数据维度已经变成5656256,因此当经过
kernel_size=2, stride=2
的最大池化层时候,图片大小减半,通道数不变。
self.max_pooling3 = nn.MaxPool2d(kernel_size=2, stride=2)
数据维度变化:5656256->2828256
剩余的卷积层和池化层
请允许我偷个懒,剩余的卷积层和池化层的代码如下:
self.conv8 = nn.Conv2d(256,512, kernel_size=3, padding=1)
self.relu8 = nn.ReLU(inplace=True)
self.conv9 = nn.Conv2d(512,512, kernel_size=3, padding=1)
self.relu9 = nn.ReLU(inplace=True)
self.conv10 = nn.Conv2d(512,512, kernel_size=3, padding=1)
self.relu10 = nn.ReLU(inplace=True)
self.max_pooling4 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv11 = nn.Conv2d(512,512, kernel_size=3, padding=1)
self.relu11 = nn.ReLU(inplace=True)
self.conv12 = nn.Conv2d(512,512, kernel_size=3, padding=1)
self.relu12 = nn.ReLU(inplace=True)
self.conv13 = nn.Conv2d(512,512, kernel_size=3, padding=1)
self.relu13 = nn.ReLU(inplace=True)
self.max_pooling5 = nn.MaxPool2d(kernel_size=2, stride=2)
卷积层中的
kernel_size=3, padding=1
,目的还是为了保证图片大小不会改变,最大池化层的
kernel_size=2, stride=2
,目的是为了让图片的宽高减半。
因此
第八层数据维度变化:2828256->2828512
第九层数据维度变化:2828512->2828512
第十层数据维度变化:2828512->2828512
池化层4数据维度变化:2828512->1414512
第十一层数据维度变化:1414512->1414512
第十二层数据维度变化:1414512->1414512
第十三层数据维度变化:1414512->1414512
池化层5数据维度变化:1414512->77512
第十四层(全连接层)~第十六层
经过上面13层,数据维度已经变成77512了,如果需要连接全连接层,就需要将数据展平。
x = x.view(-1,512*7*7)
上面的-1表示,会根据总的数据量和第二个占有的数据量大小,计算一个合适的值。
在 PyTorch 中,当你使用
.view()函数对张量进行形状变换时,可以用 -1 来表示一个特殊的值,它表示该维度的大小由函数自动推断而来,以保证张量的总元素数不变。
具体来说,对于输入张量 x,如果你使用
x.view(-1, 512*7*7)进行形状变换,其中 -1 的位置表示 PyTorch 应该根据其他维度和张量的总元素数来自动计算该维度的大小。
举个例子,假设输入张量 x 的形状是 (B, C, H, W),其中 B 表示批量大小,C 表示通道数,H 表示高度,W 表示宽度。假设在这之前的处理中,已经得到了一个形状为 (B, 512, 7, 7) 的张量 x。如果使用
x.view(-1, 512*7*7),PyTorch 将会自动计算出第一个维度的大小,以确保总元素数不变,也就是保证张量的批量大小 B 不变。
因此,
x.view(-1, 512*7*7)的作用是将输入张量 x 在第一个维度上重新调整为 -1 所代表的大小(由其他维度和张量的总元素数来确定),并且将后三个维度展平成一维。
因此,根据这一步,就将数据维度变成1*(51277)=1*25088,当然这里的1,说的不太准确,准确来说应该是批数,因为卷积层的第一个参数是批数。下面我还是用1来表示吧,方便理解哈。
# 全连接层部分
self.fc1 = nn.Linear(512*7*7,4096)
self.relu14 = nn.ReLU(inplace=True)
self.fc2 = nn.Linear(4096,4096)
self.relu15 = nn.ReLU(inplace=True)
self.dropout = nn.Dropout(),
self.fc3 = nn.Linear(4096,1000)
全连接层1的数据维度变化:1*(51277)=125088->14096
全连接层2的数据维度变化:14096->14096
全连接层3的数据维度变化:14096->11000
其中的
nn.Dropout()
现在还不需要了解,是正则化,用来防止过拟合的。
最后,如果输入数据是13224224,经过VGG16网络,输出就是11000;
如果输入数据是23224224,经过VGG16网络,输出就是21000。这就是我说的批数变化。
全部代码
大家这里不要忘记在全连接层后面加上softmax激活函数。这里我就不加了。
不用nn.Sequential()
import torch
import torch.nn as nn
import numpy as np
# 定义VGG16网络类classVGG16(nn.Module):def__init__(self):super(VGG16, self).__init__()# 卷积层部分
self.conv1 = nn.Conv2d(3,64, kernel_size=3, padding=1)
self.relu1 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(64,64, kernel_size=3, padding=1)
self.relu2 = nn.ReLU(inplace=True)
self.max_pooling1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv3 = nn.Conv2d(64,128, kernel_size=3, padding=1)
self.relu3 = nn.ReLU(inplace=True)
self.conv4 = nn.Conv2d(128,128, kernel_size=3, padding=1)
self.relu4 = nn.ReLU(inplace=True)
self.max_pooling2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv5 = nn.Conv2d(128,256, kernel_size=3, padding=1)
self.relu5 = nn.ReLU(inplace=True)
self.conv6 = nn.Conv2d(256,256, kernel_size=3, padding=1)
self.relu6 = nn.ReLU(inplace=True)
self.conv7 = nn.Conv2d(256,256, kernel_size=3, padding=1)
self.relu7 = nn.ReLU(inplace=True)
self.max_pooling3 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv8 = nn.Conv2d(256,512, kernel_size=3, padding=1)
self.relu8 = nn.ReLU(inplace=True)
self.conv9 = nn.Conv2d(512,512, kernel_size=3, padding=1)
self.relu9 = nn.ReLU(inplace=True)
self.conv10 = nn.Conv2d(512,512, kernel_size=3, padding=1)
self.relu10 = nn.ReLU(inplace=True)
self.max_pooling4 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv11 = nn.Conv2d(512,512, kernel_size=3, padding=1)
self.relu11 = nn.ReLU(inplace=True)
self.conv12 = nn.Conv2d(512,512, kernel_size=3, padding=1)
self.relu12 = nn.ReLU(inplace=True)
self.conv13 = nn.Conv2d(512,512, kernel_size=3, padding=1)
self.relu13 = nn.ReLU(inplace=True)
self.max_pooling5 = nn.MaxPool2d(kernel_size=2, stride=2)# 全连接层部分
self.fc1 = nn.Linear(512*7*7,4096)
self.relu14 = nn.ReLU(inplace=True)
self.fc2 = nn.Linear(4096,4096)
self.relu15 = nn.ReLU(inplace=True)
self.dropout = nn.Dropout(),
self.fc3 = nn.Linear(4096,1000)# 前向传播函数defforward(self, x):
x = self.conv1(x)
x = self.relu1(x)
x = self.conv2(x)
x = self.relu2(x)
x = self.max_pooling1(x)
x = self.conv3(x)
x = self.relu3(x)
x = self.conv4(x)
x = self.relu4(x)
x = self.max_pooling2(x)
x = self.conv5(x)
x = self.relu5(x)
x = self.conv6(x)
x = self.relu6(x)
x = self.conv7(x)
x = self.relu7(x)
x = self.max_pooling3(x)
x = self.conv8(x)
x = self.relu8(x)
x = self.conv9(x)
x = self.relu9(x)
x = self.conv10(x)
x = self.relu10(x)
x = self.max_pooling4(x)
x = self.conv11(x)
x = self.relu11(x)
x = self.conv12(x)
x = self.relu12(x)
x = self.conv13(x)
x = self.relu13(x)
x = self.max_pooling5(x)print(x.shape)
x = x.view(-1,512*7*7)print(x.shape)
x = self.fc1(x)
x = self.relu14(x)
x = self.fc2(x)
x = self.relu15(x)
x = self.fc3(x)return x
# 生成随机的224x224x3大小的数据if __name__ =='__main__':
random_data = np.random.rand(1,3,224,224)# 调整数据形状为 (batch_size, channels, height, width)
random_data_tensor = torch.from_numpy(random_data.astype(np.float32))# 将NumPy数组转换为PyTorch的Tensor类型,并确保数据类型为float32print("输入数据的数据维度", random_data_tensor.size())# 检查数据形状是否正确# 创建VGG16网络实例
vgg16 = VGG16()
output = vgg16(random_data_tensor)print("输出数据维度", output.shape)print(output)
使用nn.Sequential()
看看上面的代码,是不是觉得光定义网络就要好多代码写。
import torch
import torch.nn as nn
import numpy as np
# 定义VGG16网络类classVGG16(nn.Module):def__init__(self, num_classes=1000):super(VGG16, self).__init__()# 卷积层部分
self.features = nn.Sequential(
nn.Conv2d(3,64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64,64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64,128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(128,128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128,256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256,256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256,256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256,512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512,512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512,512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(512,512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512,512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512,512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),)# 全连接层部分
self.classifier = nn.Sequential(
nn.Linear(512*7*7,4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096,4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, num_classes),)# 前向传播函数defforward(self, x):
x = self.features(x)
x = torch.flatten(x,1)
x = self.classifier(x)return x
# 生成随机的224x224x3大小的数据if __name__ =='__main__':
random_data = np.random.rand(1,3,224,224)# 调整数据形状为 (batch_size, channels, height, width)
random_data_tensor = torch.from_numpy(random_data.astype(np.float32))# 将NumPy数组转换为PyTorch的Tensor类型,并确保数据类型为float32print("输入数据的数据维度", random_data_tensor.size())# 检查数据形状是否正确# 创建VGG16网络实例
vgg16 = VGG16()
output = vgg16(random_data_tensor)print("输出数据维度", output.shape)print(output)
nn.Sequential()
是
PyTorch
中的一个容器,用于按顺序地将多个神经网络层组合在一起,构建一个神经网络模型。通过
nn.Sequential()
,你可以方便地定义一个神经网络模型,按照你指定的顺序依次添加神经网络层。
torch.flatten(x, 1)
的作用和我说的.view()一样,也是用来展平操作的。
这里的1,表示的就是[batch,通道数,高,宽]中的通道数所在的维度。
举个例子,假设输入张量 x 的形状为 (B, C, H, W),其中 B 表示批量大小,C 表示通道数,H 表示高度,W 表示宽度。如果使用
torch.flatten(x, 1)
,则函数会将输入张量在通道维度上(维度索引从0开始,因此通道维度索引为1)进行展平,结果将是一个形状为 (B, CHW) 的一维张量。
至于数据,你可以使用numpy随机生成一个符合条件的数据,但是喂到网络中之前,你需要将其类型转化为tensor格式,并确保数据类型为float32
运行一下
批数为1时: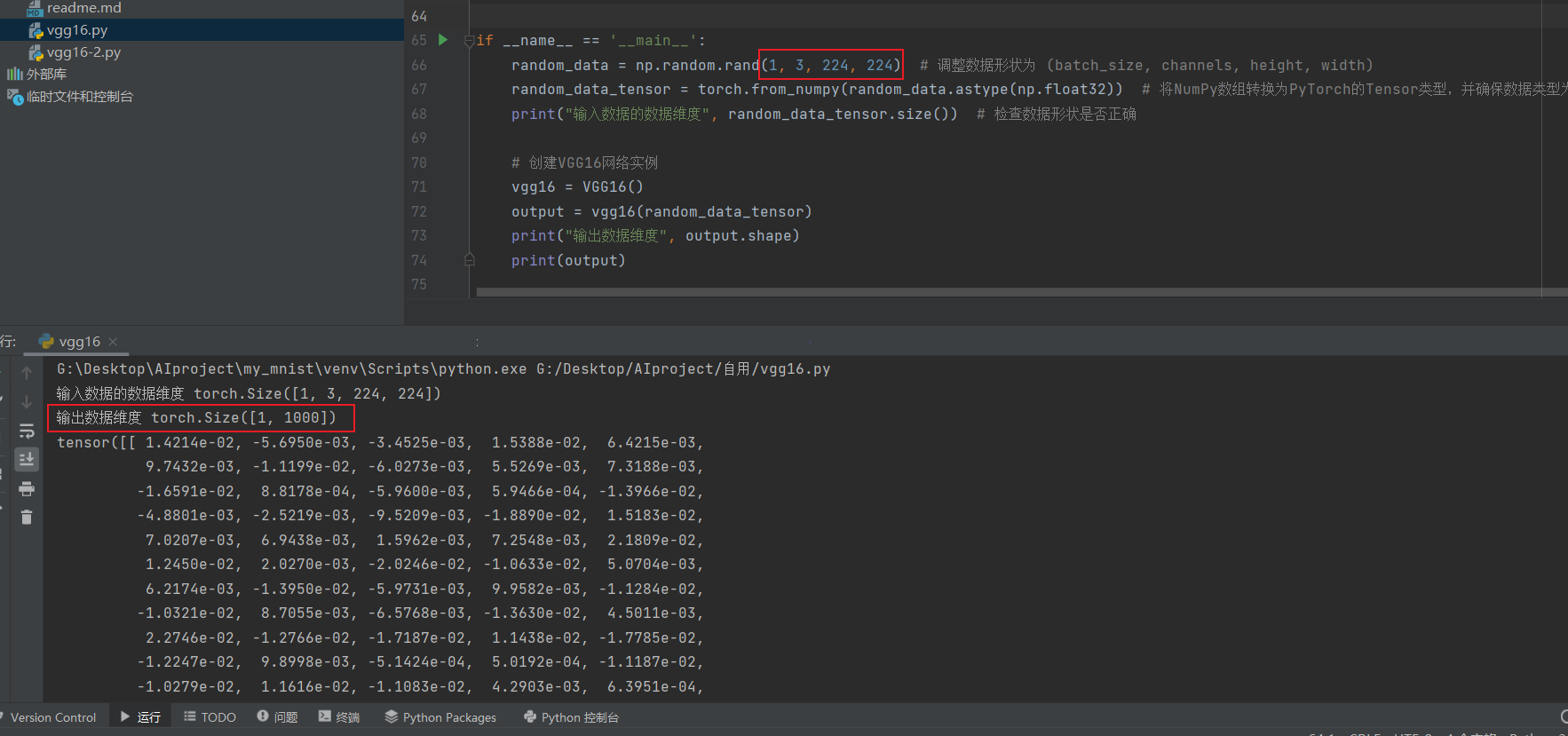
批数为2时: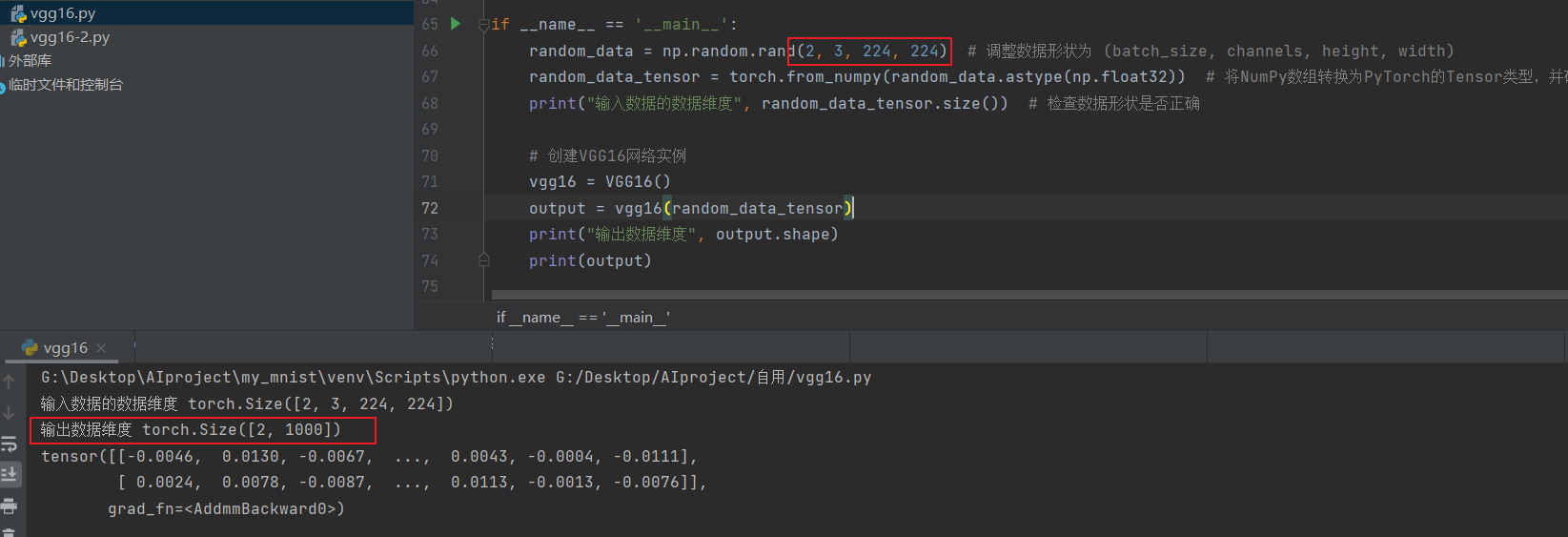
最后
希望我的讲解能够帮助大家入门神经网络的网络构建。
版权归原作者 knighthood2001 所有, 如有侵权,请联系我们删除。