
1、模型rotated_rtmdet的论文链接与配置文件
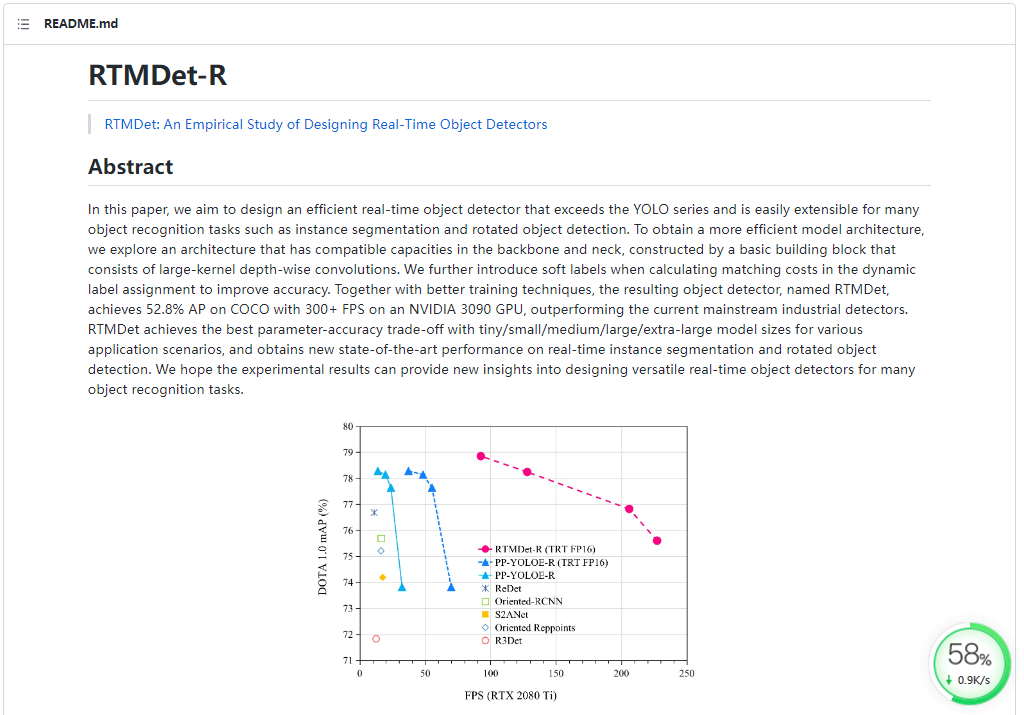

注意:
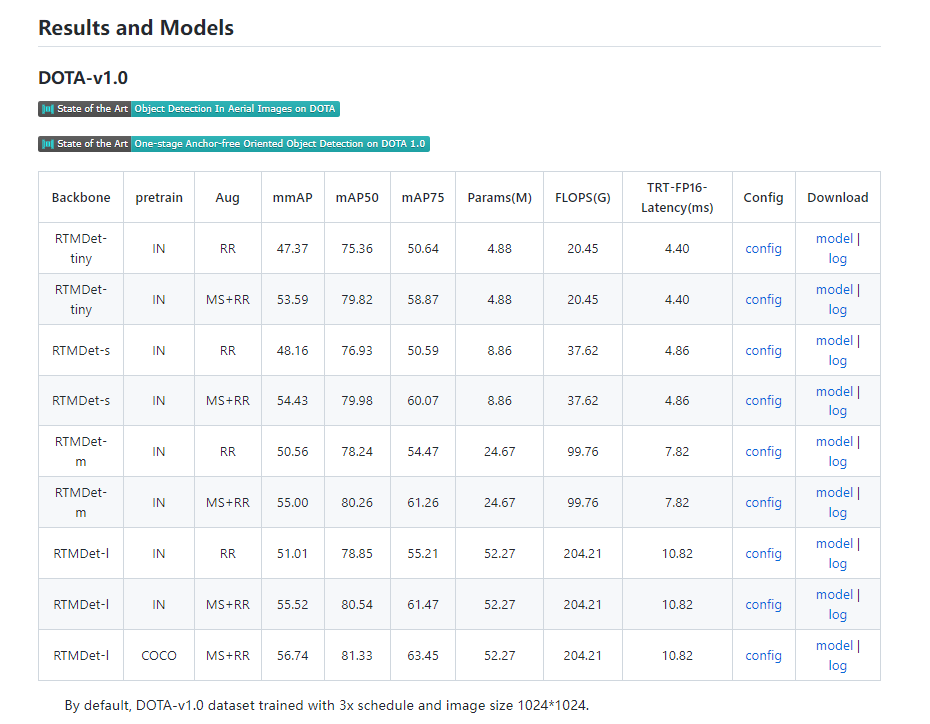
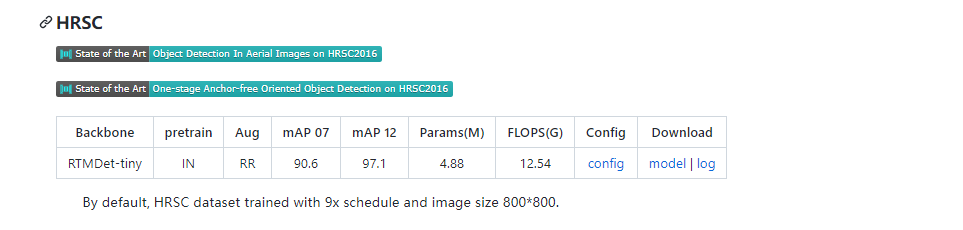
我们按照 DOTA 评测服务器的最新指标,原来的 voc 格式 mAP 现在是 mAP50。
IN表示ImageNet预训练,COCO表示COCO预训练。
与报告不同的是,这里的推理速度是在 NVIDIA 2080Ti GPU 上测量的,配备 TensorRT 8.4.3、cuDNN 8.2.0、FP16、batch size=1 和 NMS。
2、修改RTMDet-tiny的配置文件
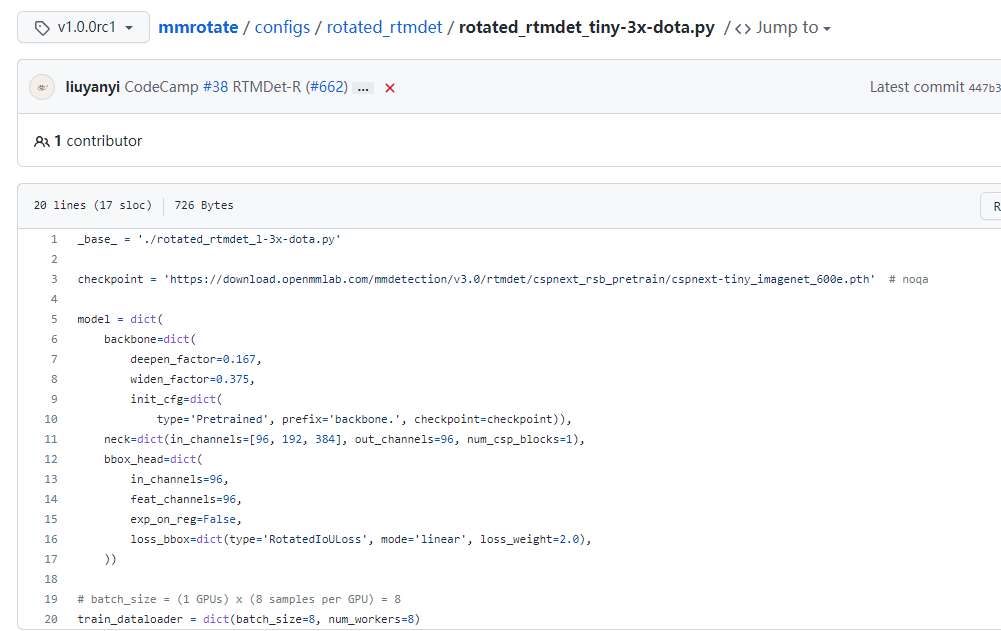
基础配置文件:rotated_rtmdet_l-3x-dota.py
_base_ = [
'./_base_/default_runtime.py', './_base_/schedule_3x.py',
'./_base_/dota_rr.py'
]
checkpoint = 'https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-l_8xb256-rsb-a1-600e_in1k-6a760974.pth' # noqa
angle_version = 'le90'
model = dict(
type='mmdet.RTMDet',
data_preprocessor=dict(
type='mmdet.DetDataPreprocessor',
mean=[103.53, 116.28, 123.675],
std=[57.375, 57.12, 58.395],
bgr_to_rgb=False,
boxtype2tensor=False,
batch_augments=None),
backbone=dict(
type='mmdet.CSPNeXt',
arch='P5',
expand_ratio=0.5,
deepen_factor=1,
widen_factor=1,
channel_attention=True,
norm_cfg=dict(type='SyncBN'),
act_cfg=dict(type='SiLU'),
init_cfg=dict(
type='Pretrained', prefix='backbone.', checkpoint=checkpoint)),
neck=dict(
type='mmdet.CSPNeXtPAFPN',
in_channels=[256, 512, 1024],
out_channels=256,
num_csp_blocks=3,
expand_ratio=0.5,
norm_cfg=dict(type='SyncBN'),
act_cfg=dict(type='SiLU')),
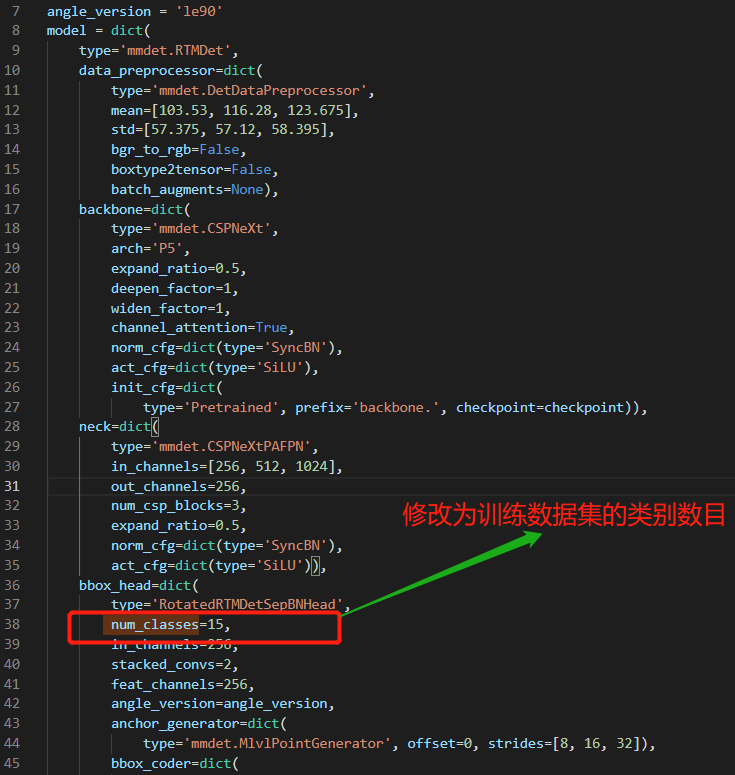
bbox_head=dict(
type='RotatedRTMDetSepBNHead',
num_classes=15,
in_channels=256,
stacked_convs=2,
feat_channels=256,
angle_version=angle_version,
anchor_generator=dict(
type='mmdet.MlvlPointGenerator', offset=0, strides=[8, 16, 32]),
bbox_coder=dict(
type='DistanceAnglePointCoder', angle_version=angle_version),
loss_cls=dict(
type='mmdet.QualityFocalLoss',
use_sigmoid=True,
beta=2.0,
loss_weight=1.0),
loss_bbox=dict(type='RotatedIoULoss', mode='linear', loss_weight=2.0),
with_objectness=False,
exp_on_reg=True,
share_conv=True,
pred_kernel_size=1,
use_hbbox_loss=False,
scale_angle=False,
loss_angle=None,
norm_cfg=dict(type='SyncBN'),
act_cfg=dict(type='SiLU')),
train_cfg=dict(
assigner=dict(
type='mmdet.DynamicSoftLabelAssigner',
iou_calculator=dict(type='RBboxOverlaps2D'),
topk=13),
allowed_border=-1,
pos_weight=-1,
debug=False),
test_cfg=dict(
nms_pre=2000,
min_bbox_size=0,
score_thr=0.05,
nms=dict(type='nms_rotated', iou_threshold=0.1),
max_per_img=2000),
)
# batch_size = (2 GPUs) x (4 samples per GPU) = 8
train_dataloader = dict(batch_size=4, num_workers=4)
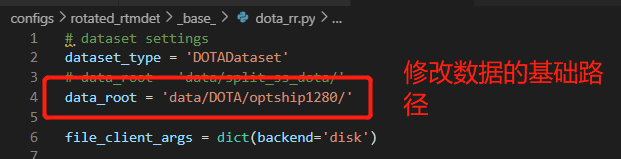
修改数据集路径信息——'./base/dota_rr.py'
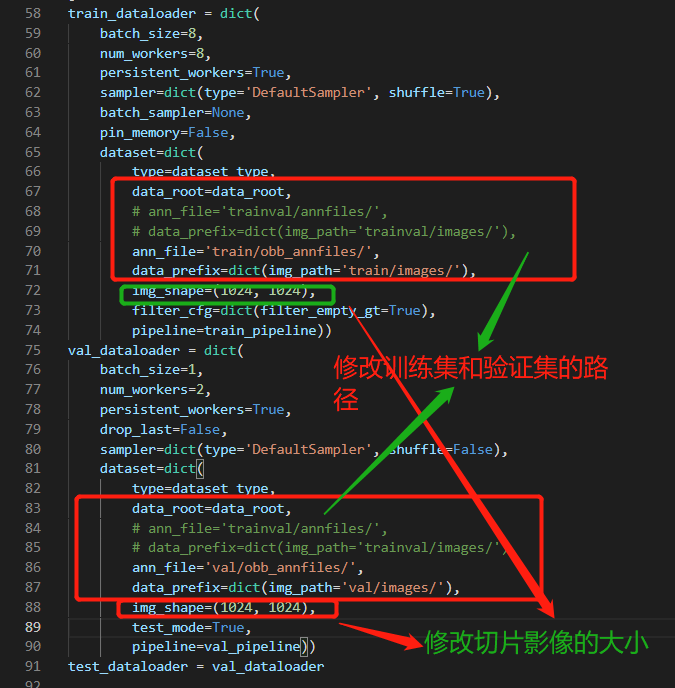
更改数据集基础路径及训练、验证和测试路径、以及影像切片的大小
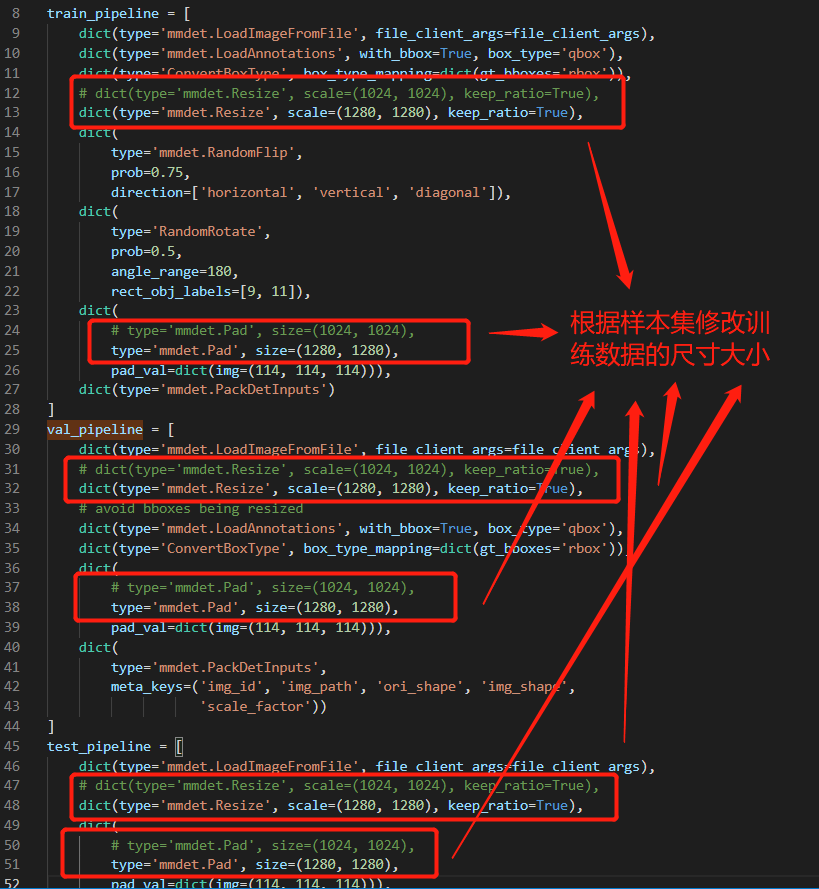
修改训练数据的类别数——rotated_rtmdet_l-3x-dota.py
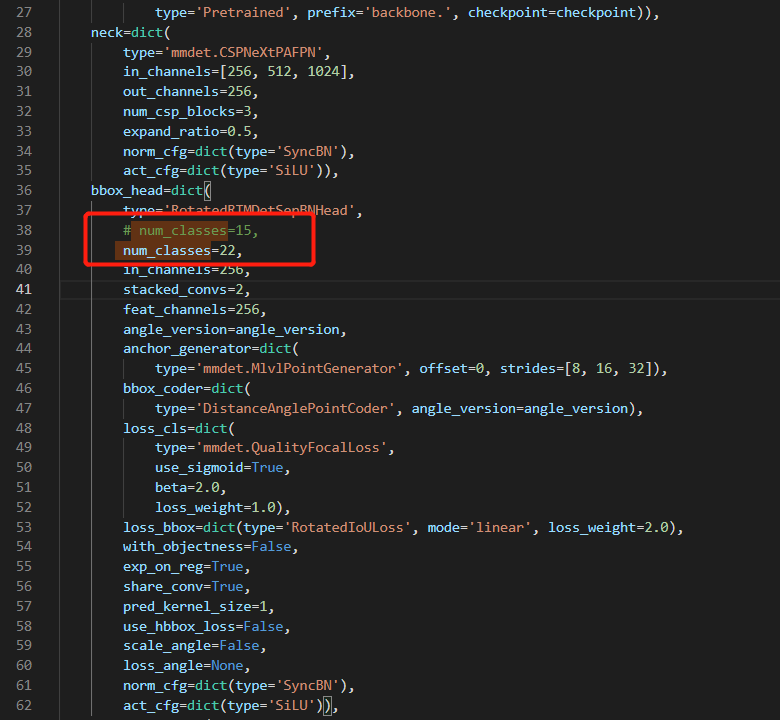
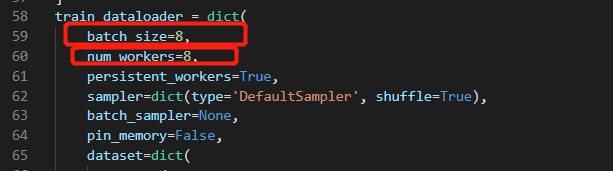
修改线程和batch_size('./base/dota_rr.py')
'./base/dota_rr.py'
rotated_rtmdet_l-3x-dota.py

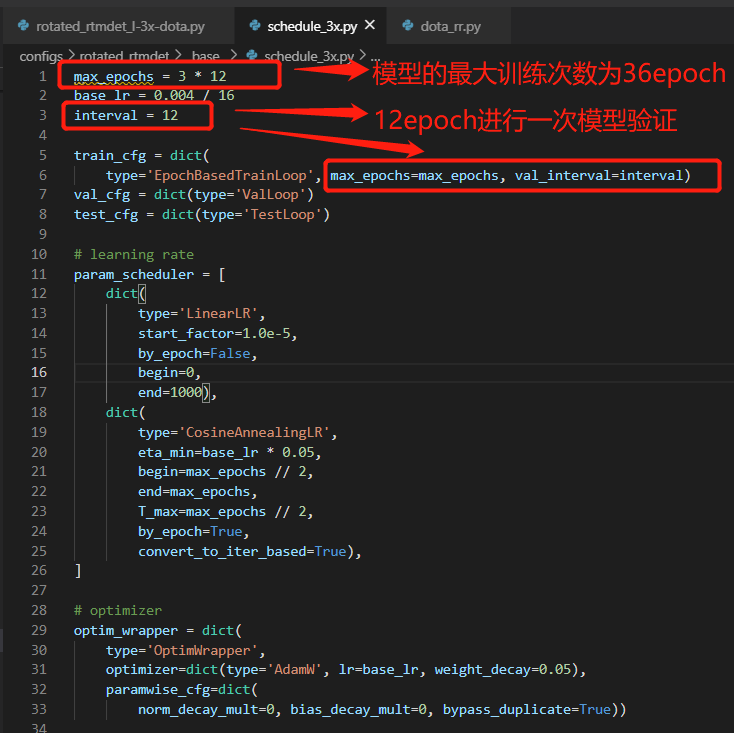
4.修改训练epoches('./base/schedule_3x.py')
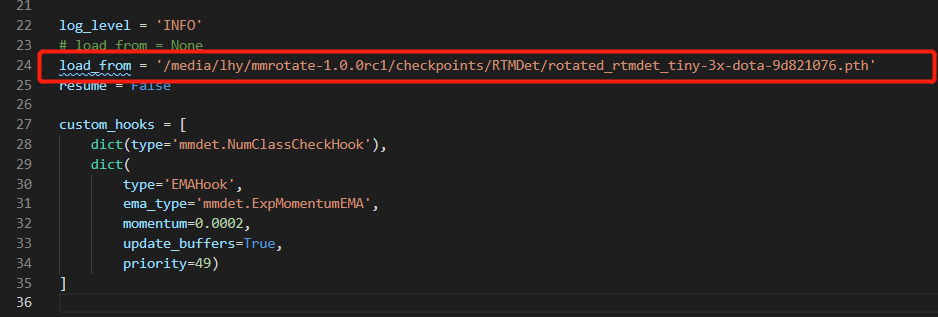
5.修改模型训练的日志打印和load from 加载与训练模型(configs_base_/default_runtime.py)

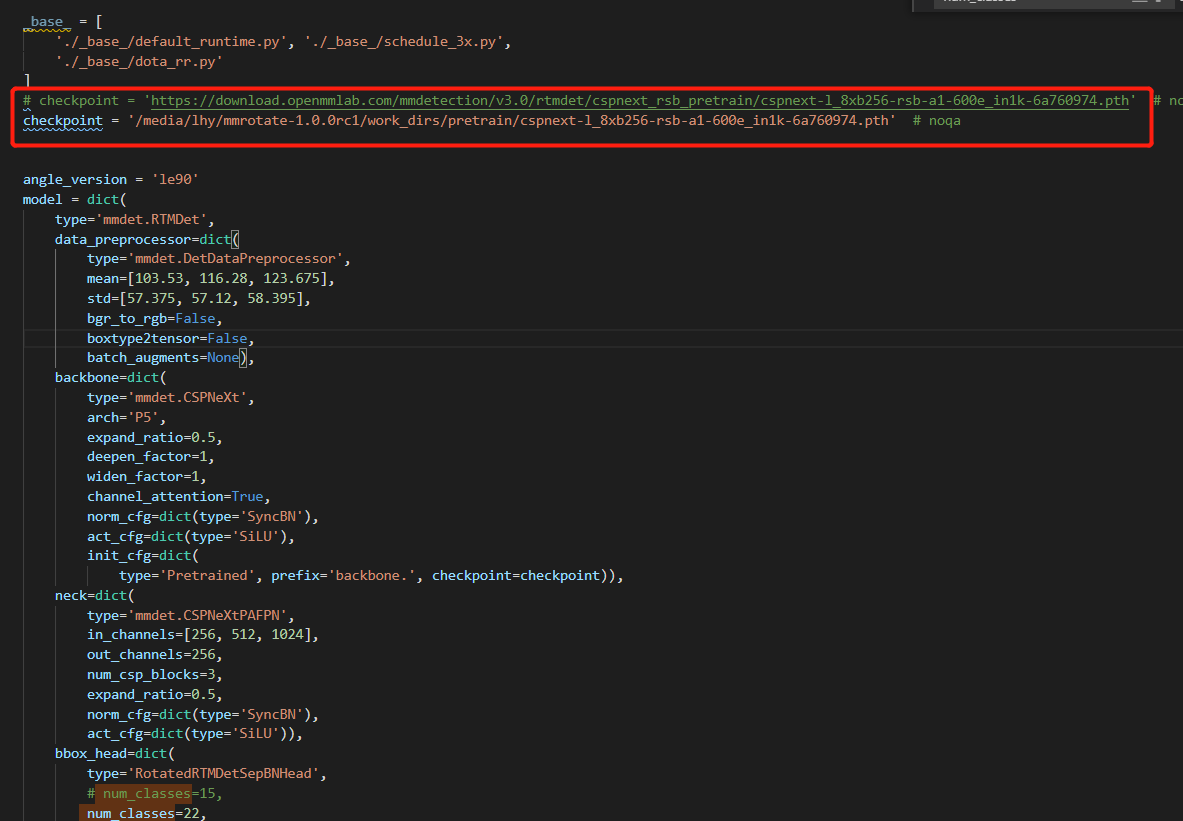
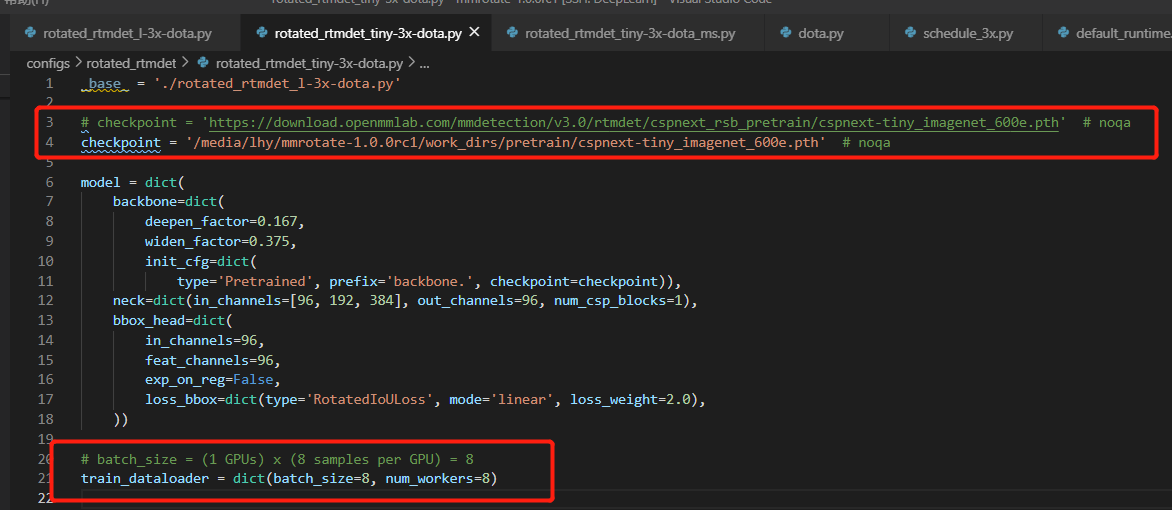
6.修改模型model的与训练模型路径

7.修改数据集的类别名称(mmrotate\datasets\dota.py)
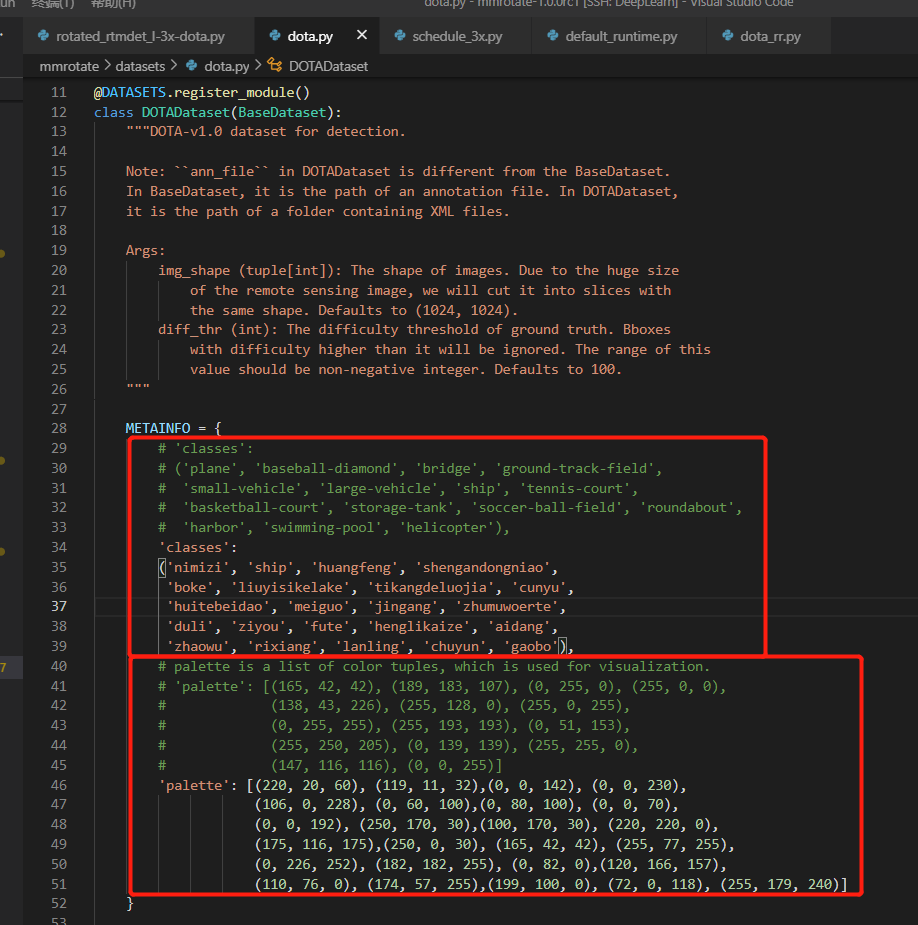
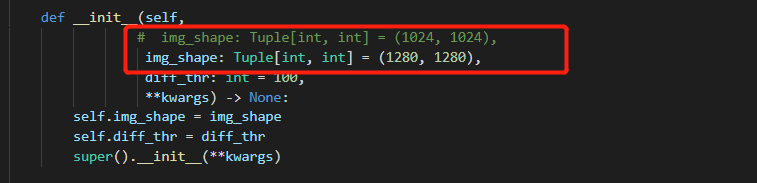
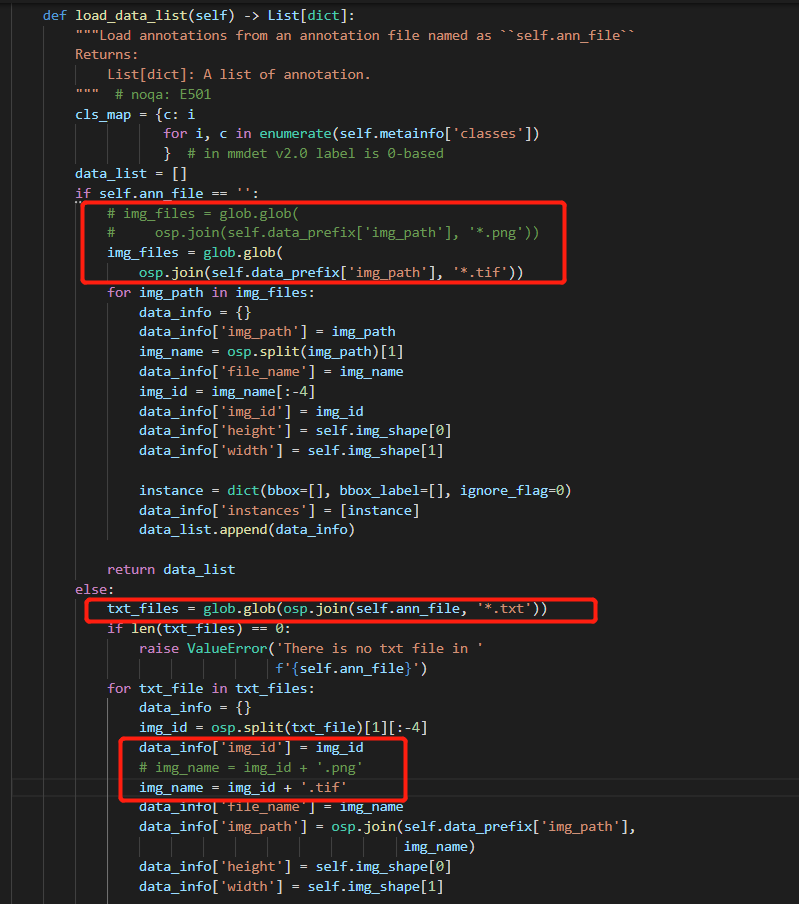
8、修改图像数据集的后缀和图片大小(修改mmrotate/mmrotate/datasets/dota.py)
整个配置文件
default_scope = 'mmrotate'
default_hooks = dict(
timer=dict(type='IterTimerHook'),
logger=dict(type='LoggerHook', interval=50),
param_scheduler=dict(type='ParamSchedulerHook'),
checkpoint=dict(type='CheckpointHook', interval=12, max_keep_ckpts=3),
sampler_seed=dict(type='DistSamplerSeedHook'),
visualization=dict(type='mmdet.DetVisualizationHook'))
env_cfg = dict(
cudnn_benchmark=False,
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
dist_cfg=dict(backend='nccl'))
vis_backends = [dict(type='LocalVisBackend')]
visualizer = dict(
type='RotLocalVisualizer',
vis_backends=[dict(type='LocalVisBackend')],
name='visualizer')
log_processor = dict(type='LogProcessor', window_size=50, by_epoch=True)
log_level = 'INFO'
load_from = '/media/lhy/mmrotate-1.0.0rc1/checkpoints/RTMDet/rotated_rtmdet_tiny-3x-dota-9d821076.pth'
resume = False
custom_hooks = [
dict(type='mmdet.NumClassCheckHook'),
dict(
type='EMAHook',
ema_type='mmdet.ExpMomentumEMA',
momentum=0.0002,
update_buffers=True,
priority=49)#在训练时对模型进行指数移动平均运算,目的是提高模型的鲁棒性
]
max_epochs = 36
base_lr = 0.00025
interval = 12
train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=36, val_interval=12)
val_cfg = dict(type='ValLoop')
test_cfg = dict(type='TestLoop')
param_scheduler = [
dict(
type='LinearLR', start_factor=1e-05, by_epoch=False, begin=0,
end=1000),
dict(
type='CosineAnnealingLR',
eta_min=1.25e-05,
begin=18,
end=36,
T_max=18,
by_epoch=True,
convert_to_iter_based=True)
]
optim_wrapper = dict(
type='OptimWrapper',#标准的单精度训练
optimizer=dict(type='AdamW', lr=0.00025, weight_decay=0.05),
paramwise_cfg=dict(
norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
#paramwise_cfg可以设置参数
#lr_mult:所有参数的学习率。
#decay_mult:所有参数的衰减系数。
#bias_lr_mult:偏置的学习率系数(不包括归一化层的偏置和可变形卷积的偏置)。
#bias_decay_mult:偏差的权重衰减系数(不包括归一化层的偏差和可变形卷积的偏移量)。
#norm_decay_mult:归一化层的权重和偏差的权重衰减系数。
#flat_decay_mult:一维参数的权重衰减系数。
#dwconv_decay_mult:深度卷积的衰减系数。
#bypass_duplicate: 是否跳过重复参数,默认为False.
#dcn_offset_lr_mult:可变形卷积的学习率。
dataset_type = 'DOTADataset'
data_root = 'data/DOTA/optship1280/'
file_client_args = dict(backend='disk')
train_pipeline = [
dict(
type='mmdet.LoadImageFromFile', file_client_args=dict(backend='disk')),
dict(type='mmdet.LoadAnnotations', with_bbox=True, box_type='qbox'),
dict(type='ConvertBoxType', box_type_mapping=dict(gt_bboxes='rbox')),
dict(type='mmdet.Resize', scale=(1280, 1280), keep_ratio=True),
dict(
type='mmdet.RandomFlip',
prob=0.75,
direction=['horizontal', 'vertical', 'diagonal']),
dict(
type='RandomRotate',
prob=0.5,
angle_range=180,
rect_obj_labels=[9, 11]),
dict(
type='mmdet.Pad', size=(1280, 1280),
pad_val=dict(img=(114, 114, 114))),
dict(type='mmdet.PackDetInputs')
]
val_pipeline = [
dict(
type='mmdet.LoadImageFromFile', file_client_args=dict(backend='disk')),
dict(type='mmdet.Resize', scale=(1280, 1280), keep_ratio=True),
dict(type='mmdet.LoadAnnotations', with_bbox=True, box_type='qbox'),
dict(type='ConvertBoxType', box_type_mapping=dict(gt_bboxes='rbox')),
dict(
type='mmdet.Pad', size=(1280, 1280),
pad_val=dict(img=(114, 114, 114))),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor'))
]
test_pipeline = [
dict(
type='mmdet.LoadImageFromFile', file_client_args=dict(backend='disk')),
dict(type='mmdet.Resize', scale=(1280, 1280), keep_ratio=True),
dict(
type='mmdet.Pad', size=(1280, 1280),
pad_val=dict(img=(114, 114, 114))),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor'))
]
train_dataloader = dict(
batch_size=8,
num_workers=8,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
batch_sampler=None,
pin_memory=False,
dataset=dict(
type='DOTADataset',
data_root='data/DOTA/optship1280/',
ann_file='trainval/obb_annfiles/',
data_prefix=dict(img_path='trainval/images/'),
img_shape=(1280, 1280),
filter_cfg=dict(filter_empty_gt=True),
pipeline=[
dict(
type='mmdet.LoadImageFromFile',
file_client_args=dict(backend='disk')),
dict(
type='mmdet.LoadAnnotations', with_bbox=True, box_type='qbox'),
dict(
type='ConvertBoxType',
box_type_mapping=dict(gt_bboxes='rbox')),
dict(type='mmdet.Resize', scale=(1280, 1280), keep_ratio=True),
dict(
type='mmdet.RandomFlip',
prob=0.75,
direction=['horizontal', 'vertical', 'diagonal']),
dict(
type='RandomRotate',
prob=0.5,
angle_range=180,
rect_obj_labels=[9, 11]),
dict(
type='mmdet.Pad',
size=(1280, 1280),
pad_val=dict(img=(114, 114, 114))),
dict(type='mmdet.PackDetInputs')
]))
val_dataloader = dict(
batch_size=1,
num_workers=2,
persistent_workers=True,
drop_last=False,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=dict(
type='DOTADataset',
data_root='data/DOTA/optship1280/',
ann_file='trainval/obb_annfiles/',
data_prefix=dict(img_path='trainval/images/'),
img_shape=(1280, 1280),
test_mode=True,
pipeline=[
dict(
type='mmdet.LoadImageFromFile',
file_client_args=dict(backend='disk')),
dict(type='mmdet.Resize', scale=(1280, 1280), keep_ratio=True),
dict(
type='mmdet.LoadAnnotations', with_bbox=True, box_type='qbox'),
dict(
type='ConvertBoxType',
box_type_mapping=dict(gt_bboxes='rbox')),
dict(
type='mmdet.Pad',
size=(1280, 1280),
pad_val=dict(img=(114, 114, 114))),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor'))
]))
test_dataloader = dict(
batch_size=1,
num_workers=2,
persistent_workers=True,
drop_last=False,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=dict(
type='DOTADataset',
data_root='data/DOTA/optship1280/',
ann_file='val/obb_annfiles/',
data_prefix=dict(img_path='val/images/'),
img_shape=(1280, 1280),
test_mode=True,
pipeline=[
dict(
type='mmdet.LoadImageFromFile',
file_client_args=dict(backend='disk')),
dict(type='mmdet.Resize', scale=(1280, 1280), keep_ratio=True),
dict(
type='mmdet.LoadAnnotations', with_bbox=True, box_type='qbox'),
dict(
type='ConvertBoxType',
box_type_mapping=dict(gt_bboxes='rbox')),
dict(
type='mmdet.Pad',
size=(1280, 1280),
pad_val=dict(img=(114, 114, 114))),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor'))
]))
val_evaluator = dict(type='DOTAMetric', metric='mAP')#评估数据类型与指标
test_evaluator = dict(type='DOTAMetric', metric='mAP')
checkpoint = '/media/lhy/mmrotate-1.0.0rc1/work_dirs/pretrain/cspnext-tiny_imagenet_600e.pth'
angle_version = 'le90'
model = dict(
type='mmdet.RTMDet',
data_preprocessor=dict(
type='mmdet.DetDataPreprocessor',
mean=[103.53, 116.28, 123.675],
std=[57.375, 57.12, 58.395],
bgr_to_rgb=False,
boxtype2tensor=False,
batch_augments=None),
backbone=dict(
type='mmdet.CSPNeXt',
arch='P5',
expand_ratio=0.5,
deepen_factor=0.167,
widen_factor=0.375,
channel_attention=True,
norm_cfg=dict(type='SyncBN'),
act_cfg=dict(type='SiLU'),
init_cfg=dict(
type='Pretrained',
prefix='backbone.',
checkpoint=
'/media/lhy/mmrotate-1.0.0rc1/work_dirs/pretrain/cspnext-tiny_imagenet_600e.pth'
)),
neck=dict(
type='mmdet.CSPNeXtPAFPN',
in_channels=[96, 192, 384],
out_channels=96,
num_csp_blocks=1,
expand_ratio=0.5,
norm_cfg=dict(type='SyncBN'),
act_cfg=dict(type='SiLU')),
bbox_head=dict(
type='RotatedRTMDetSepBNHead',
num_classes=22,
in_channels=96,
stacked_convs=2,
feat_channels=96,
angle_version='le90',
anchor_generator=dict(
type='mmdet.MlvlPointGenerator', offset=0, strides=[8, 16, 32]),
bbox_coder=dict(type='DistanceAnglePointCoder', angle_version='le90'),
loss_cls=dict(
type='mmdet.QualityFocalLoss',
use_sigmoid=True,
beta=2.0,
loss_weight=1.0),
loss_bbox=dict(type='RotatedIoULoss', mode='linear', loss_weight=2.0),
with_objectness=False,
exp_on_reg=False,
share_conv=True,
pred_kernel_size=1,
use_hbbox_loss=False,
scale_angle=False,
loss_angle=None,
norm_cfg=dict(type='SyncBN'),
act_cfg=dict(type='SiLU')),
train_cfg=dict(
assigner=dict(
type='mmdet.DynamicSoftLabelAssigner',
iou_calculator=dict(type='RBboxOverlaps2D'),
topk=13),
allowed_border=-1,
pos_weight=-1,
debug=False),
test_cfg=dict(
nms_pre=2000,
min_bbox_size=0,
score_thr=0.05,
nms=dict(type='nms_rotated', iou_threshold=0.1),
max_per_img=2000))
launcher = 'none'
work_dir = 'work_dirs/runs/train/rtmdet_tiny_rrship/'
3、模型训练
1、Train with a single GPU
python tools/train.py ${CONFIG_FILE} [optional arguments]
如果你想在命令中指定工作目录,你可以添加一个参数–work_dir $[YOUR_WORK_DIR]。
2、Train with multiple GPUs
./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [optional arguments]
Optional arguments are:
–no-validate (not suggested): By default, the codebase will perform evaluation during the training. To disable this behavior, use --no-validate.
–work-dir ${WORK_DIR}: Override the working directory specified in the config file.
–resume-from ${CHECKPOINT_FILE}: Resume from a previous checkpoint file.
Difference between resume-from and load-from: resume-from loads both the model weights and optimizer status, and the epoch is also inherited from the specified checkpoint. It is usually used for resuming the training process that is interrupted accidentally. load-from only loads the model weights and the training epoch starts from 0. It is usually used for finetuning.
3、Train with multiple machines
•如果你启动了多台连接以太网的机器,你可以简单地运行以下命令:
On the first machine:
NNODES=2 NODE_RANK=0 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR sh tools/dist_train.sh $CONFIG $GPUS
On the second machine:
NNODES=2 NODE_RANK=1 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR sh tools/dist_train.sh $CONFIG $GPUS
如果你没有像InfiniBand这样的高速网络,通常会很慢。
4、Manage jobs with Slurm
如果在由slurm管理的集群上运行MMRotate,可以使用脚本slurm_train.sh。(此脚本也支持单机训练。)
[GPUS=${GPUS}] ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${WORK_DIR}
如果您有多台机器与以太网连接,您可以参考PyTorch启动实用程序添加链接描述。如果你没有像InfiniBand这样的高速网络,通常会很慢
5、在一台机器上启动多个作业
如果您在一台机器上启动多个作业,例如,在一台有8个gpu的机器上启动2个4-GPU训练的作业,您需要为每个作业指定不同的端口(默认为29500),以避免通信冲突。
If you use dist_train.sh to launch training jobs, you can set the port in commands.
CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 ./tools/dist_train.sh ${CONFIG_FILE} 4
CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 ./tools/dist_train.sh ${CONFIG_FILE} 4
如果使用Slurm启动培训作业,则需要修改配置文件(通常是配置文件中倒数第6行)以设置不同的通信端口。
In config1.py,
dist_params = dict(backend=‘nccl’, port=29500)
In config2.py,
dist_params = dict(backend=‘nccl’, port=29501)
Then you can launch two jobs with config1.py and config2.py.
CUDA_VISIBLE_DEVICES=0,1,2,3 GPUS=4 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config1.py ${WORK_DIR}
CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=4 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config2.py ${WORK_DIR}
6、开始启动模型训练
1、启动模型训练命令
python tools/train.py configs/rotated_rtmdet/rotated_rtmdet_tiny-3x-dota.py --work-dir work_dirs/runs/train/rtmdet_tiny_rrship/
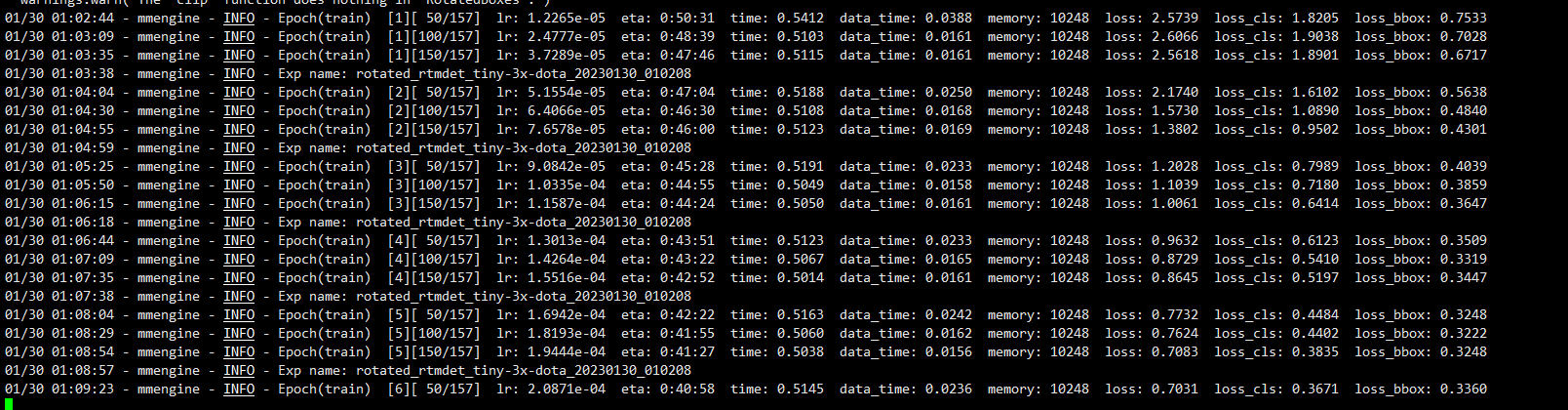
2、模型训练结果

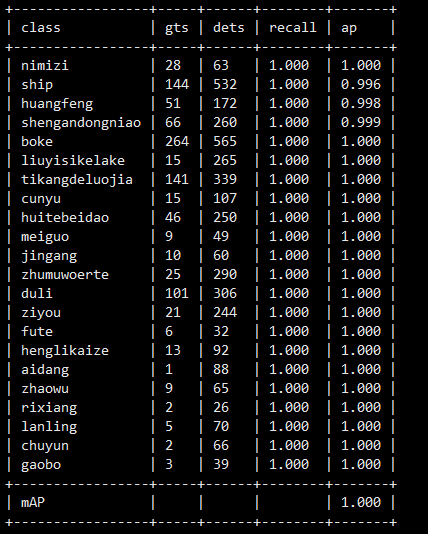
模型验证发现模型检测的目标远远多于真实的目标,我们修改配置文件的训练数据集路径为trainval,扩大训练样本。
4、mmrotate模型测试
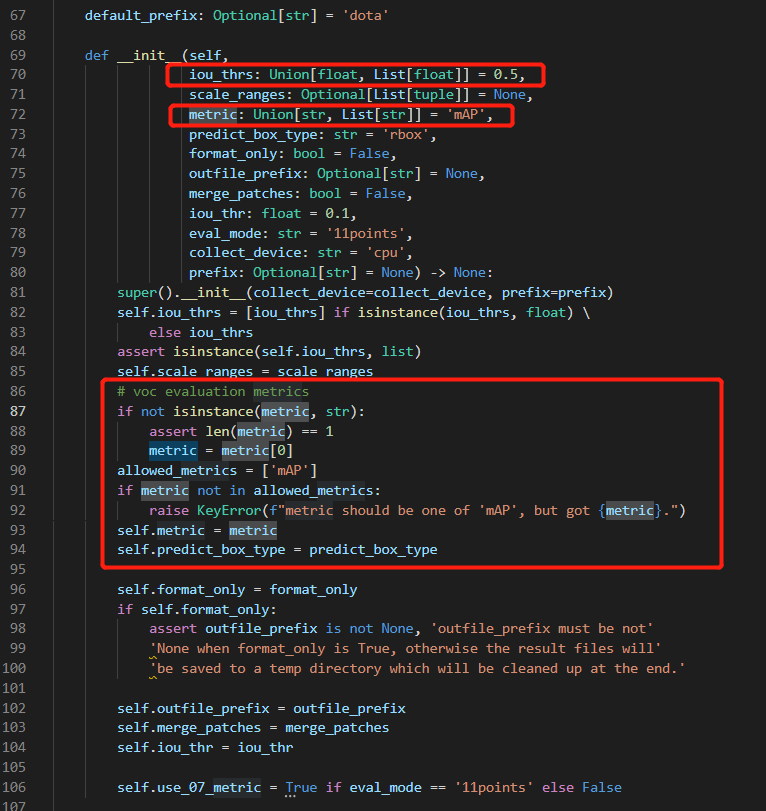
修改模型测试评估的域值map(mmrotate/evaluation/metrics/dota_metric.py)
模型默认的iou阈值为0.5,可以修改为0.75等。
single GPU
single node multiple GPU
multiple node
可以使用以下命令推断数据集。
# single-gpu
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
# multi-gpu
./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [optional arguments]
# multi-node in slurm environment
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments] --launcher slurm
例子:
在DOTA-1.0数据集上推理RotatedRetinaNet,可以生成压缩文件在线提交。(请先更改data_root。)
python ./tools/test.py \
configs/rotated_retinanet/rotated-retinanet-rbox-le90_r50_fpn_1x_dota.py \
checkpoints/SOME_CHECKPOINT.pth --format-only \
--eval-options submission_dir=work_dirs/Task1_results
或者
./tools/dist_test.sh \
configs/rotated_retinanet/rotated-retinanet-rbox-le90_r50_fpn_1x_dota.py \
checkpoints/SOME_CHECKPOINT.pth 1 --format-only \
--eval-options submission_dir=work_dirs/Task1_results
您可以将data_root中的test set路径改为val set或trainval set进行离线评估。
python ./tools/test.py \
configs/rotated_retinanet/rotated-retinanet-rbox-le90_r50_fpn_1x_dota.py \
checkpoints/SOME_CHECKPOINT.pth --eval mAP
或者
./tools/dist_test.sh \
configs/rotated_retinanet/rotated-retinanet-rbox-le90_r50_fpn_1x_dota.py \
checkpoints/SOME_CHECKPOINT.pth 1 --eval mAP
您还可以可视化结果。
python ./tools/test.py \
configs/rotated_retinanet/rotated-retinanet-rbox-le90_r50_fpn_1x_dota.py \
checkpoints/SOME_CHECKPOINT.pth \
--show-dir work_dirs/vis
版权归原作者 qq_41627642 所有, 如有侵权,请联系我们删除。