
关于本博文的所有代码可以在地址下载:GitHub - liu-xiao-guo/python-vector-private
我将在本博文中其中深入研究人工智能和向量嵌入的深水区。 ChatGPT 令人大开眼界,但有一个主要问题。 这是一个封闭的托管系统。 在一个被大型网络公司改变的世界里生活了二十年之后,我们作为人们担心我们的私人信息甚至我们的知识仅仅因为我们使用互联网就成为他人的财产。 作为建立在竞争基础上的经济的参与者,我们对知识和数据集中在有反竞争行为历史的公司手中抱有强烈的不信任。
因此,眼前的问题是:我能否获得本地大型语言模型,并在不使用云服务的情况下在我的笔记本电脑上运行生成式人工智能聊天? 本文将展示如何在本地部署大模型,并使用 Elasticsearch 进行向量搜索。
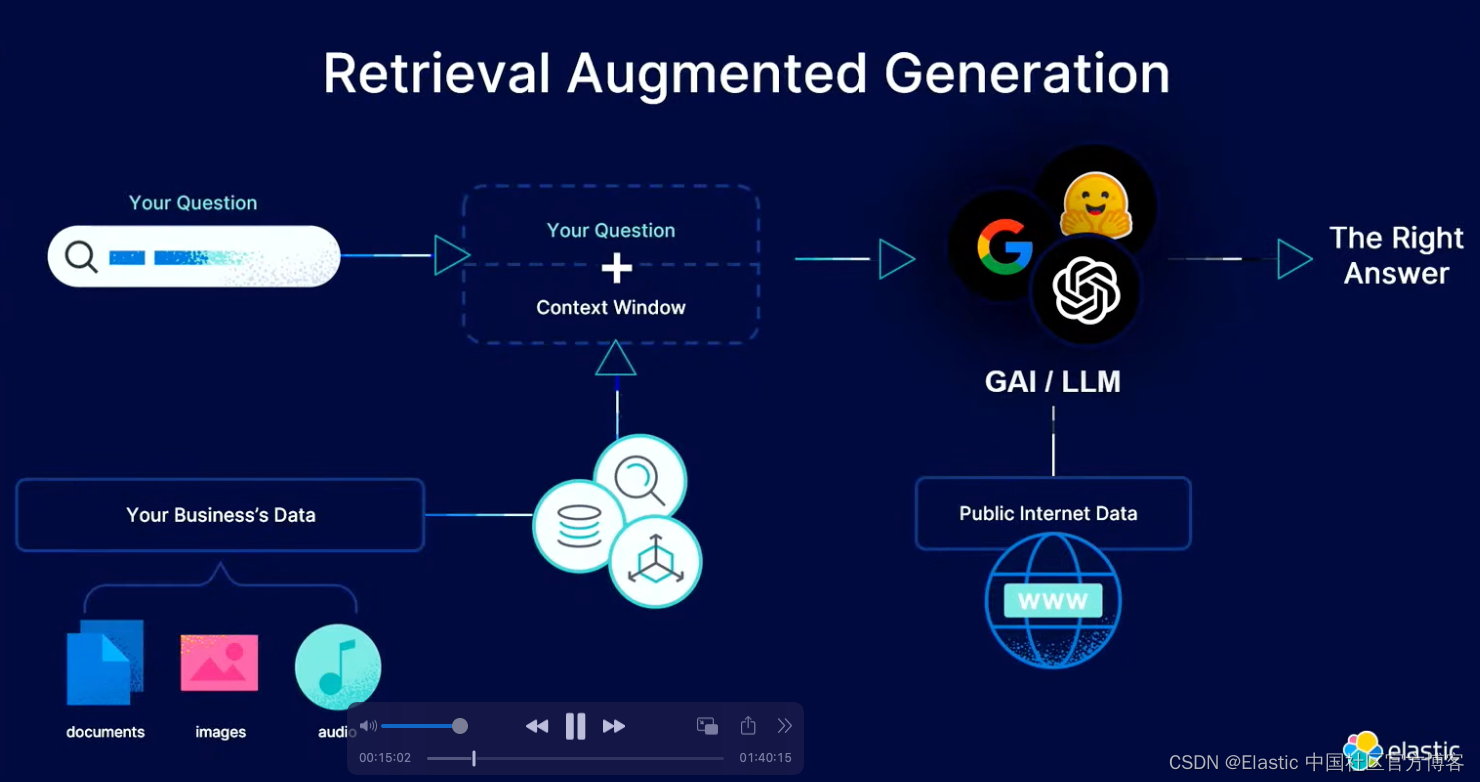
我要建造什么?
简而言之:我将构建一个人工智能聊天机器人,通过将 LLM 与向量存储相结合,它 “知道” 其预先训练的神经网络中没有的东西。
我将从一个经常辅导的项目开始,最好将其描述为 “与我的书交谈”。 我没有发明这个,快速搜索发现其他一些通常使用付费 OpenAI API 的方法。 示例,视频示例
我将从我用来搜索的第一部分私人数据开始。一本从网上可以直接进行下载的一部书。 我将其转换为简单的 .txt 文件,并保存于项目中的 data/sample.txt 文件中。
这将如何运作
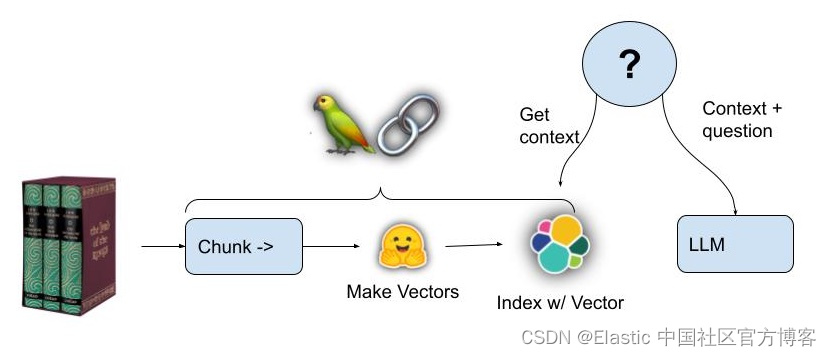
关键步骤:
- 文本被提取成小段落大小的块(chunks),足以容纳有关书的问题问题的所有答案。
- 每个文本块都被传递给句子转换器,它生成一个密集向量,以向量嵌入的形式表示其语义含义
- 这些块及其向量嵌入存储在 Elasticsearch 中
- 当提出问题时,系统会为问题文本创建一个向量,然后查询 Elasticsearch 以查找语义上最接近问题的文本块; 想必有些文字会有答案。
- 为 LLM 编写提示,将检索到的文本块作为额外的上下文知识 “填充”。
- LLM 创建问题的答案
有关为什么需要把文本分成不同大小的 chunks,原因如下:


在本示例中,我将使用 sentence-transformers/all-mpnet-base-v2 模型。根据模型的描述,该模型的最大 token 长度为 384:

也就是说,我们需要把书分成最多不超过 384 的 chunks。
Langchain 让一切变得简单
有一个很棒的 Python 库,名为 Langchain,它不仅包含实用程序库,使变压器和向量存储的使用变得简单,而且在某种程度上可以互换。 Langchain 拥有比我在这里使用的更高级的与 LLM 合作的模式,但这是一个很好的第一个测试。
许多 Langchain 教程都需要使用付费 OpenAI 帐户。 OpenAI 很棒,并且目前可能在 LLM 质量竞赛中处于领先地位,但出于上述所有原因,我将使用免费的 HuggingFace 模型和 Elasticsearch。
获取一些离线模型
必须在 Huggingface 中创建一个帐户并获取 API 密钥。 之后,你可以使用 Huggingface_hub Python 或 Langchain 库以编程方式下拉模型。在运行代码的 terminal 中,你必须先打入如下的命令:
export HUGGINGFACEHUB_API_TOKENs="YOUR TOKEN"
我们在示例中使用如下的模型:
- Sentence-transformers/all-mpnet-base-v2- 作为我的向量嵌入生成器
- google/flan-t5-large - 作为我用于对话交互的大型语言模型
安装
如果你还没有安装好自己的 Elasticsearch 及 Kibana 的话,那么请参考如下的链接:
- 如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
- Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在安装的时候,我们选择 Elastic Stack 9.x 的安装指南来进行安装。在默认的情况下,Elasticsearch 集群的访问具有 HTTPS 的安全访问。
生成证书
为了能使得 python 应用能够正常访问 Elasticsearch,我们使用如下的命令来生成 pem 证书:
$ pwd
/Users/liuxg/elastic/elasticsearch-8.10.0
$ ./bin/elasticsearch-keystore list
keystore.seed
xpack.security.http.ssl.keystore.secure_password
xpack.security.transport.ssl.keystore.secure_password
xpack.security.transport.ssl.truststore.secure_password
$ ./bin/elasticsearch-keystore show xpack.security.http.ssl.keystore.secure_password
GcOUL8b2RxKooxJU-VymFg
$ openssl pkcs12 -in ./config/certs/http.p12 -cacerts -out ./python_es_client.pem
Enter Import Password:
Enter PEM pass phrase:
Verifying - Enter PEM pass phrase:
Enter PEM pass phrase:
Verifying - Enter PEM pass phrase:
$ ls
LICENSE.txt bin jdk.app modules
NOTICE.txt config lib plugins
README.asciidoc data logs python_es_client.pem
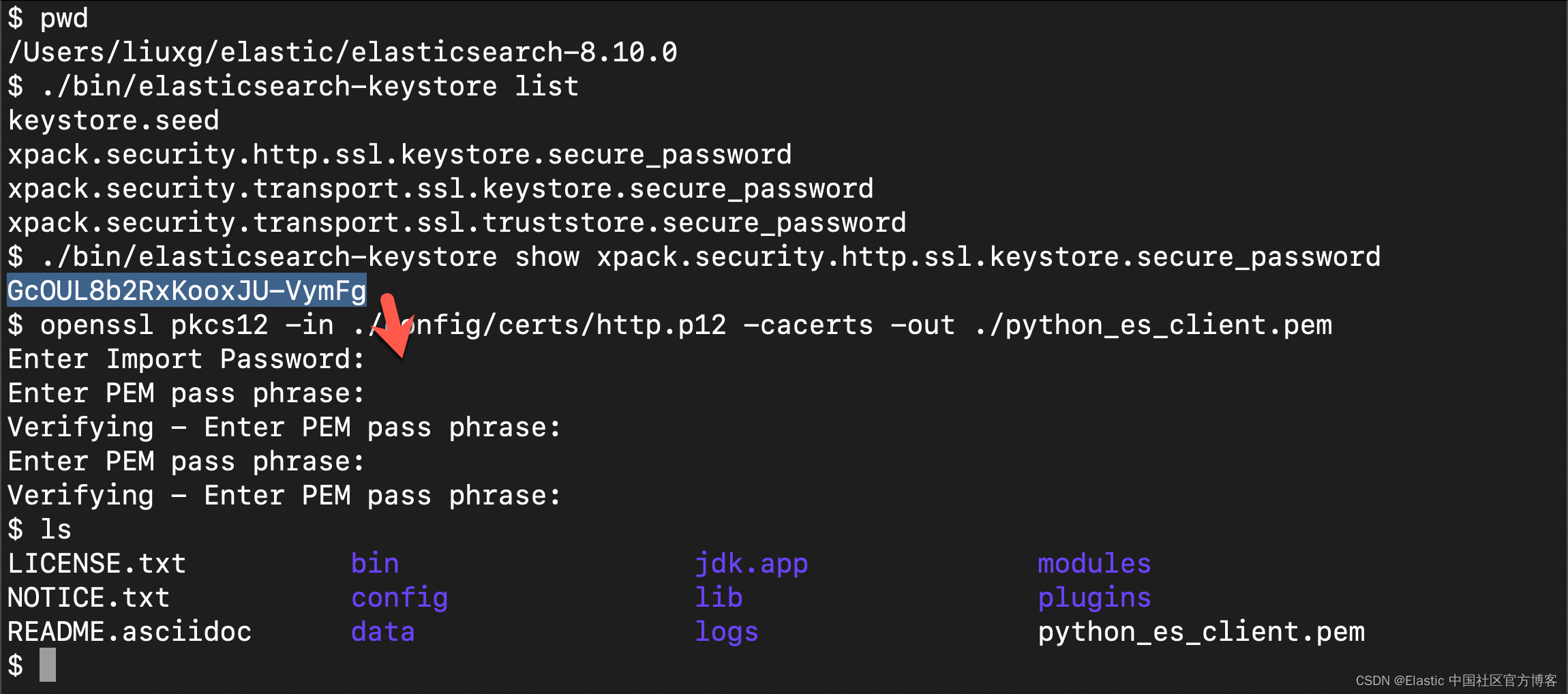
我们把上面生成的 python_es_client.pem 文件拷贝到应用的根目录下。这样整个应用的目录架构如下:
$ tree -L 3
.
├── README.md
├── app-book.py
├── data
│ └── sample.txt
├── lib_book_parse.py
├── lib_embeddings.py
├── lib_llm.py
├── lib_vectordb.py
├── python_es_client.pem
├── requirements.txt
└── simple.cfg
配置项目
如上所示,我们有一个叫做 simple.cfg 的配置文件:
simple.cfg
ES_SERVER: "localhost"
ES_PASSWORD: "vXDWYtL*my3vnKY9zCfL"
ES_FINGERPRINT: "e2c1512f617f432ddf242075d3af5177b28f6497fecaaa0eea11429369bb7b00"
我们需要根据自己的 Elasticsearch 服务器的地址来配置 ES_SERVER。我们也需要配置 elastic 超级用户的密码。这个密码可以在安装 Elasticsearch 时得到。当然你也可以使用其他用户的信息来进行练习。如果这样,你需要做相应的配置和代码改动。
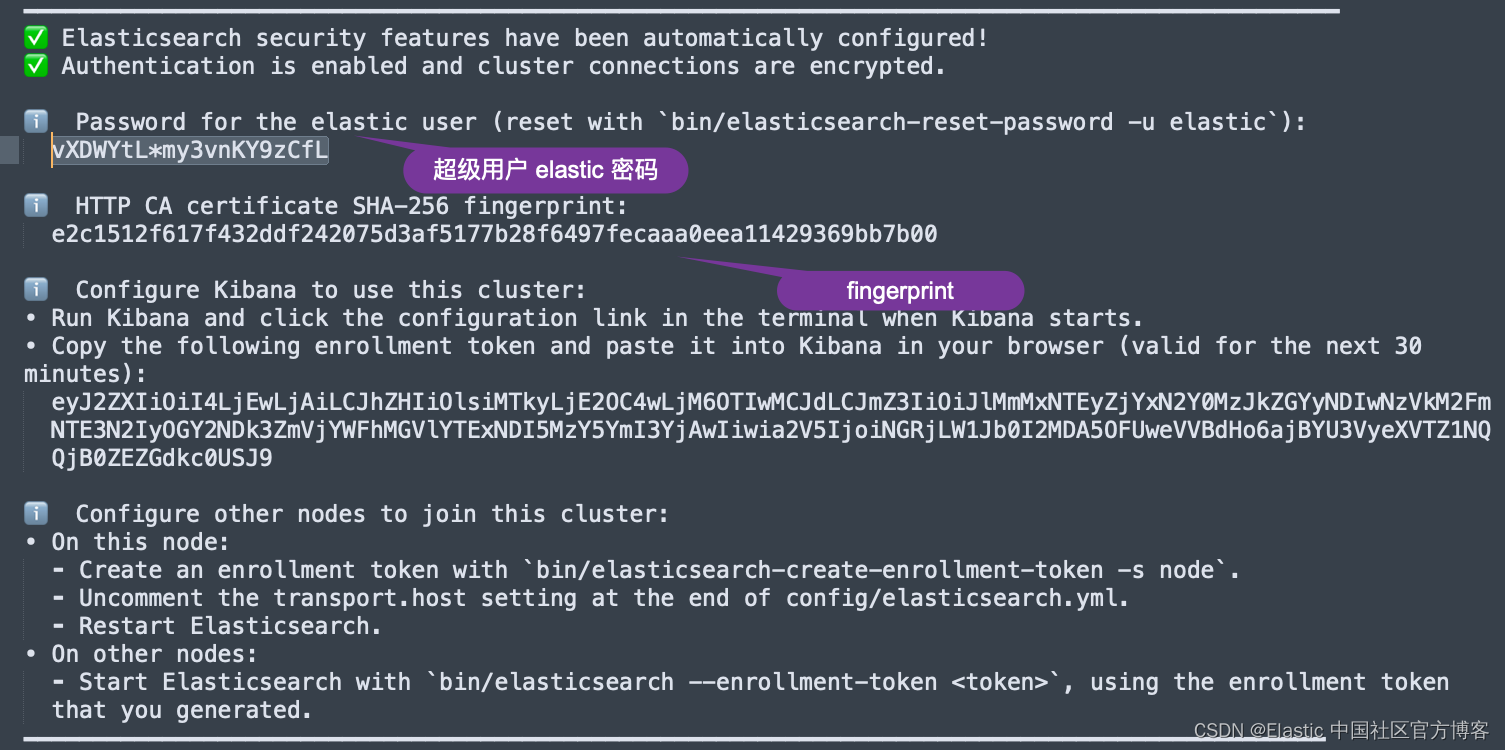
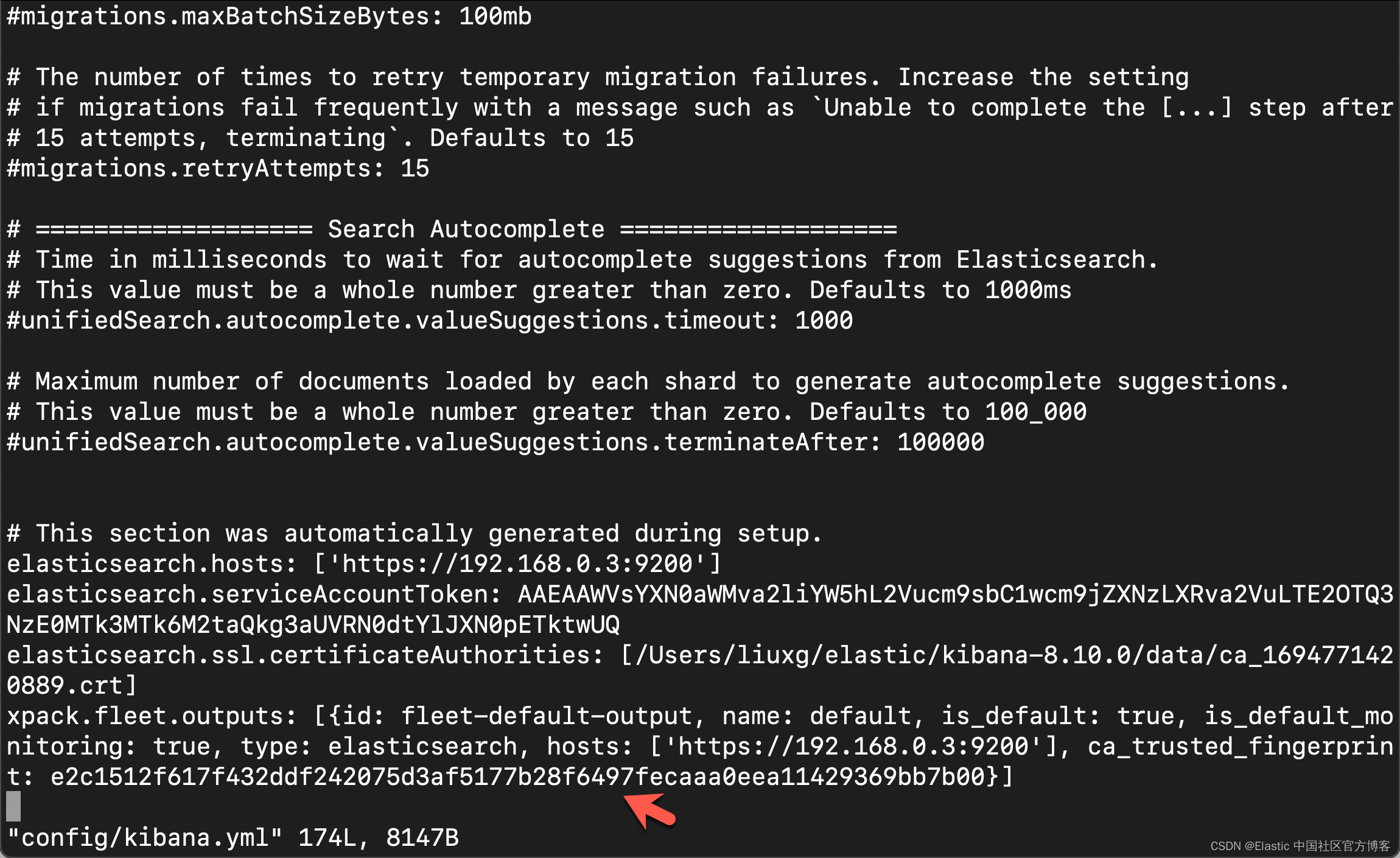
你还可以在 Kibana 的配置文件 confgi/kibana.yml 文件中获得 fingerprint 的配置:
运行项目
在运行项目之前,你需要做一下安装的动作:
python3 -m venv env
source env/bin/activate
python3 -m pip install --upgrade pip
pip install -r requirements.txt
创建嵌入模型
lib_embedding.py
## for embeddings
from langchain.embeddings import HuggingFaceEmbeddings
def setup_embeddings():
# Huggingface embedding setup
print(">> Prep. Huggingface embedding setup")
model_name = "sentence-transformers/all-mpnet-base-v2"
return HuggingFaceEmbeddings(model_name=model_name)
创建向量存储
lib_vectordb.py
import os
from config import Config
## for vector store
from langchain.vectorstores import ElasticVectorSearch
def setup_vectordb(hf,index_name):
# Elasticsearch URL setup
print(">> Prep. Elasticsearch config setup")
with open('simple.cfg') as f:
cfg = Config(f)
endpoint = cfg['ES_SERVER']
username = "elastic"
password = cfg['ES_PASSWORD']
ssl_verify = {
"verify_certs": True,
"basic_auth": (username, password),
"ca_certs": "./python_es_client.pem",
}
url = f"https://{username}:{password}@{endpoint}:9200"
return ElasticVectorSearch( embedding = hf,
elasticsearch_url = url,
index_name = index_name,
ssl_verify = ssl_verify), url
创建使用带有上下文和问题变量的提示模板的离线 LLM
lib_llm.py
## for conversation LLM
from langchain import PromptTemplate, HuggingFaceHub, LLMChain
from langchain.llms import HuggingFacePipeline
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, AutoModelForSeq2SeqLM
def make_the_llm():
# Get Offline flan-t5-large ready to go, in CPU mode
print(">> Prep. Get Offline flan-t5-large ready to go, in CPU mode")
model_id = 'google/flan-t5-large'# go for a smaller model if you dont have the VRAM
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(model_id) #load_in_8bit=True, device_map='auto'
pipe = pipeline(
"text2text-generation",
model=model,
tokenizer=tokenizer,
max_length=100
)
local_llm = HuggingFacePipeline(pipeline=pipe)
# template_informed = """
# I know the following: {context}
# Question: {question}
# Answer: """
template_informed = """
I know: {context}
when asked: {question}
my response is: """
prompt_informed = PromptTemplate(template=template_informed, input_variables=["context", "question"])
return LLMChain(prompt=prompt_informed, llm=local_llm)
装载书籍
以下是我的分块和向量存储代码。 它需要在 Elasticsearch 中准备好组成的 Elasticsearch url、huggingface 嵌入模型、向量数据库和目标索引名称
lib_book_parse.py
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import TextLoader
## for vector store
from langchain.vectorstores import ElasticVectorSearch
from elasticsearch import Elasticsearch
from config import Config
with open('simple.cfg') as f:
cfg = Config(f)
fingerprint = cfg['ES_FINGERPRINT']
endpoint = cfg['ES_SERVER']
username = "elastic"
password = cfg['ES_PASSWORD']
ssl_verify = {
"verify_certs": True,
"basic_auth": (username, password),
"ca_certs": "./python_es_client.pem",
}
url = f"https://{username}:{password}@{endpoint}:9200"
def parse_book(filepath):
loader = TextLoader(filepath)
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=384, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
return docs
def loadBookBig(filepath, url, hf, db, index_name):
es = Elasticsearch( [ url ],
basic_auth = ("elastic", cfg['ES_PASSWORD']),
ssl_assert_fingerprint = fingerprint,
http_compress = True )
## Parse the book if necessary
if not es.indices.exists(index=index_name):
print(f'\tThe index: {index_name} does not exist')
print(">> 1. Chunk up the Source document")
docs = parse_book(filepath)
# print(docs)
print(">> 2. Index the chunks into Elasticsearch")
elastic_vector_search= ElasticVectorSearch.from_documents( docs,
embedding = hf,
elasticsearch_url = url,
index_name = index_name,
ssl_verify = ssl_verify)
else:
print("\tLooks like the book is already loaded, let's move on")
用问题循环将所有内容联系在一起
解析这本书后,主控制循环是这样的
# ## how to ask a question
def ask_a_question(question):
# print("The Question at hand: "+question)
## 3. get the relevant chunk from Elasticsearch for a question
# print(">> 3. get the relevant chunk from Elasticsearch for a question")
similar_docs = db.similarity_search(question)
print(f'The most relevant passage: \n\t{similar_docs[0].page_content}')
## 4. Ask Local LLM context informed prompt
# print(">> 4. Asking The Book ... and its response is: ")
informed_context= similar_docs[0].page_content
response = llm_chain_informed.run(context=informed_context,question=question)
return response
# # The conversational loop
print(f'I am the book, "{bookName}", ask me any question: ')
while True:
command = input("User Question>> ")
response = ask_a_question(command)
print(f"\n\n I think the answer is : {response}\n")
运行结果
我们可以通过如下的命令来运行应用:
python3 app-book.py
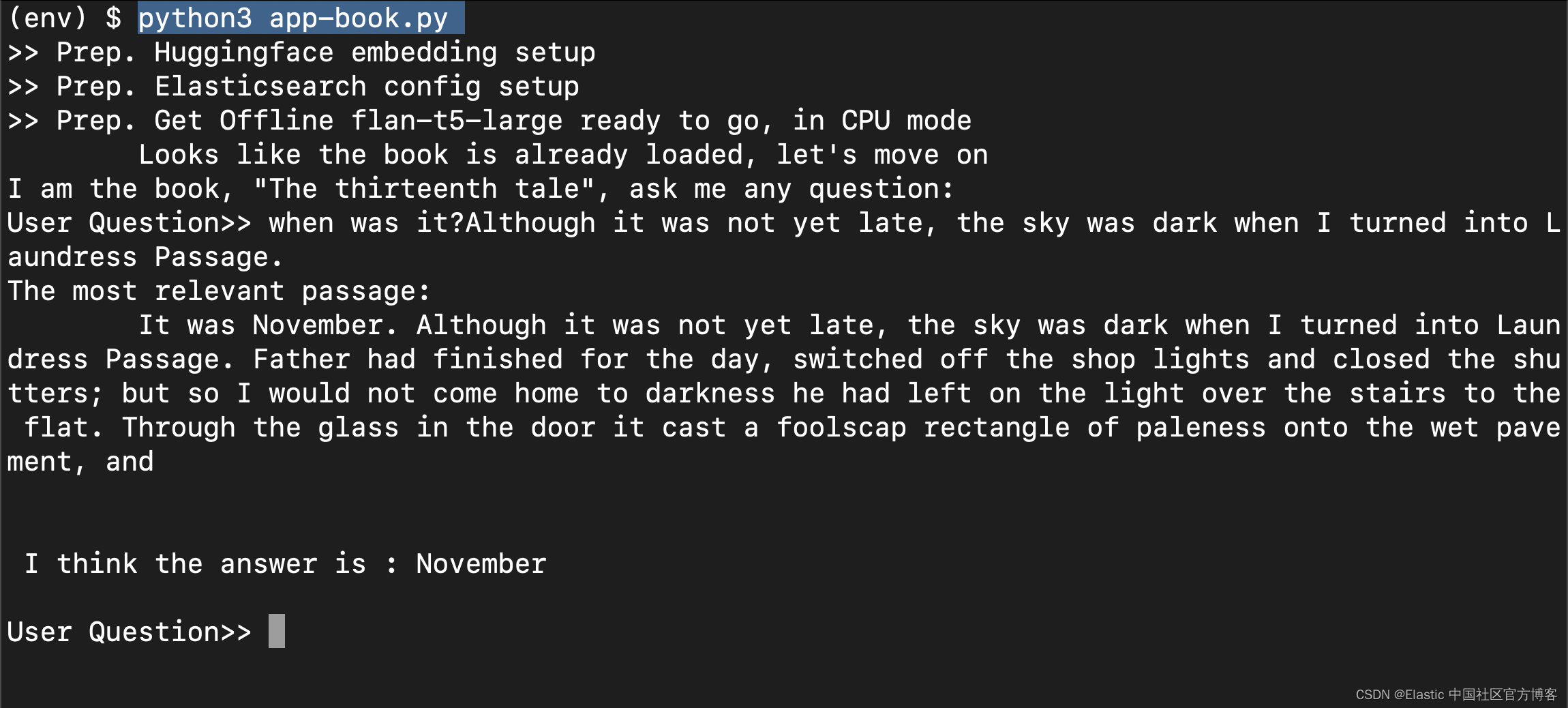
上面的问题是:
when was it?Although it was not yet late, the sky was dark when I turned into Laundress Passage.
我们来尝试其他的问题:
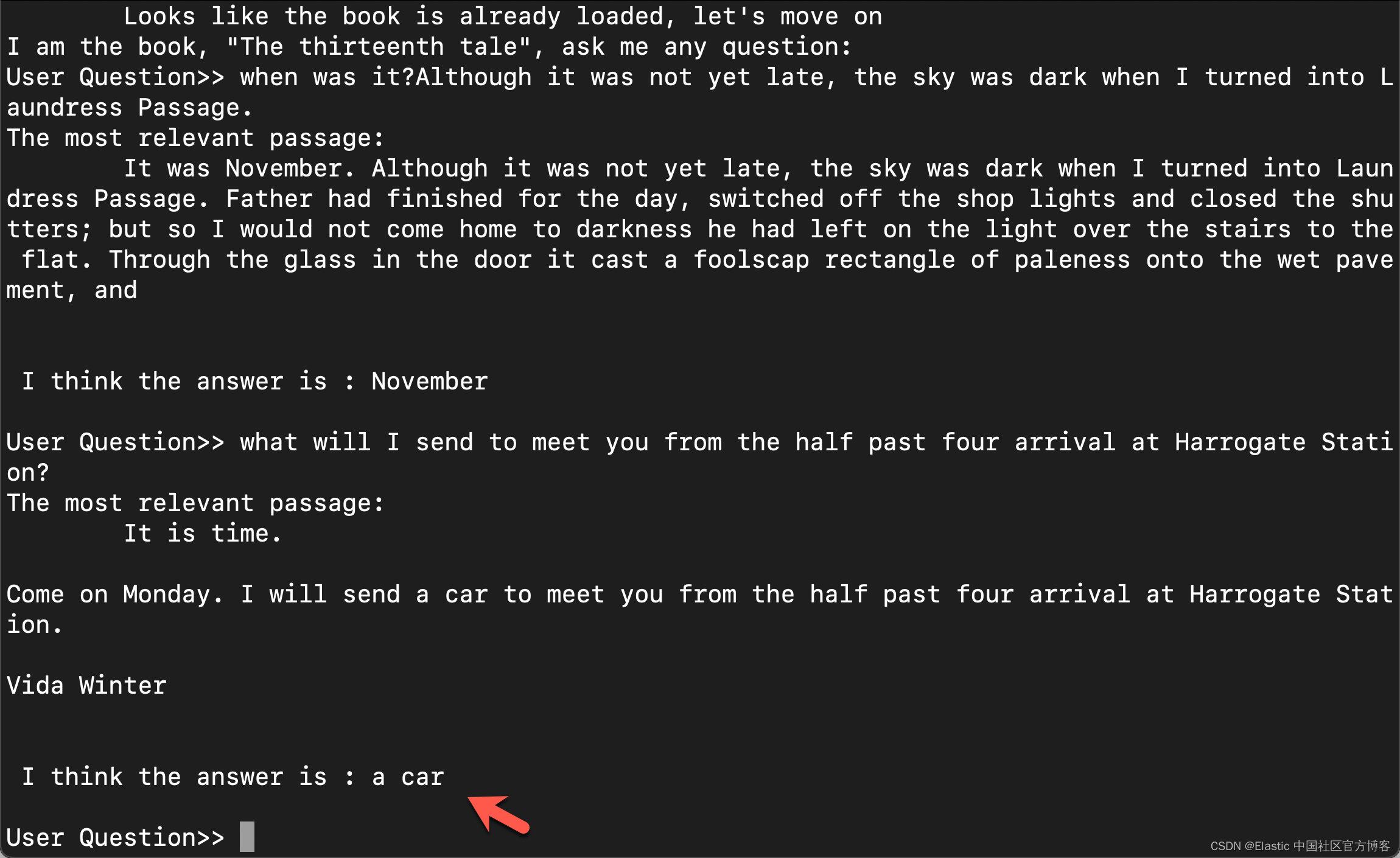
上面的问题是:
what will I send to meet you from the half past four arrival at Harrogate Station?
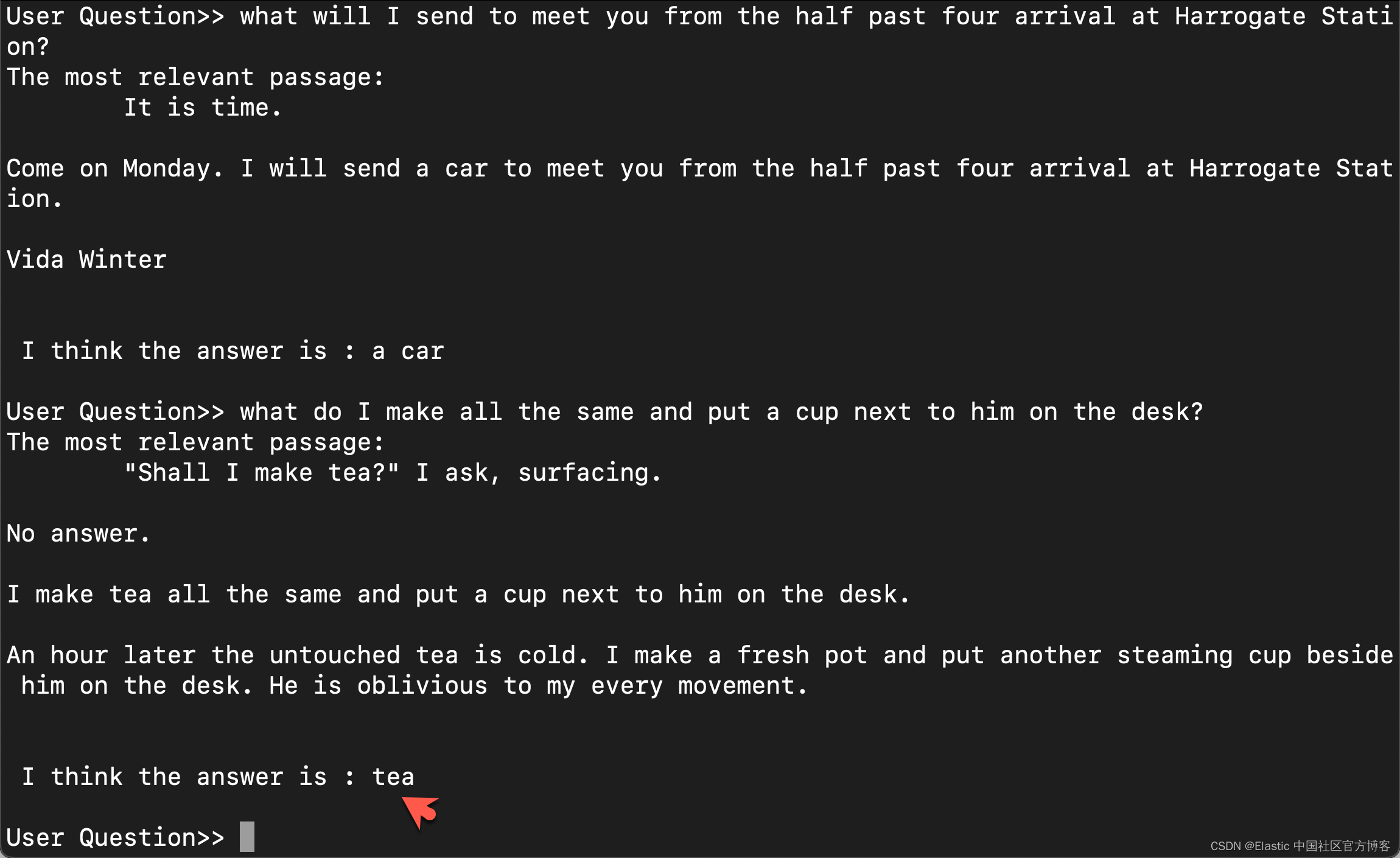
上面的问题是:
what do I make all the same and put a cup next to him on the desk?
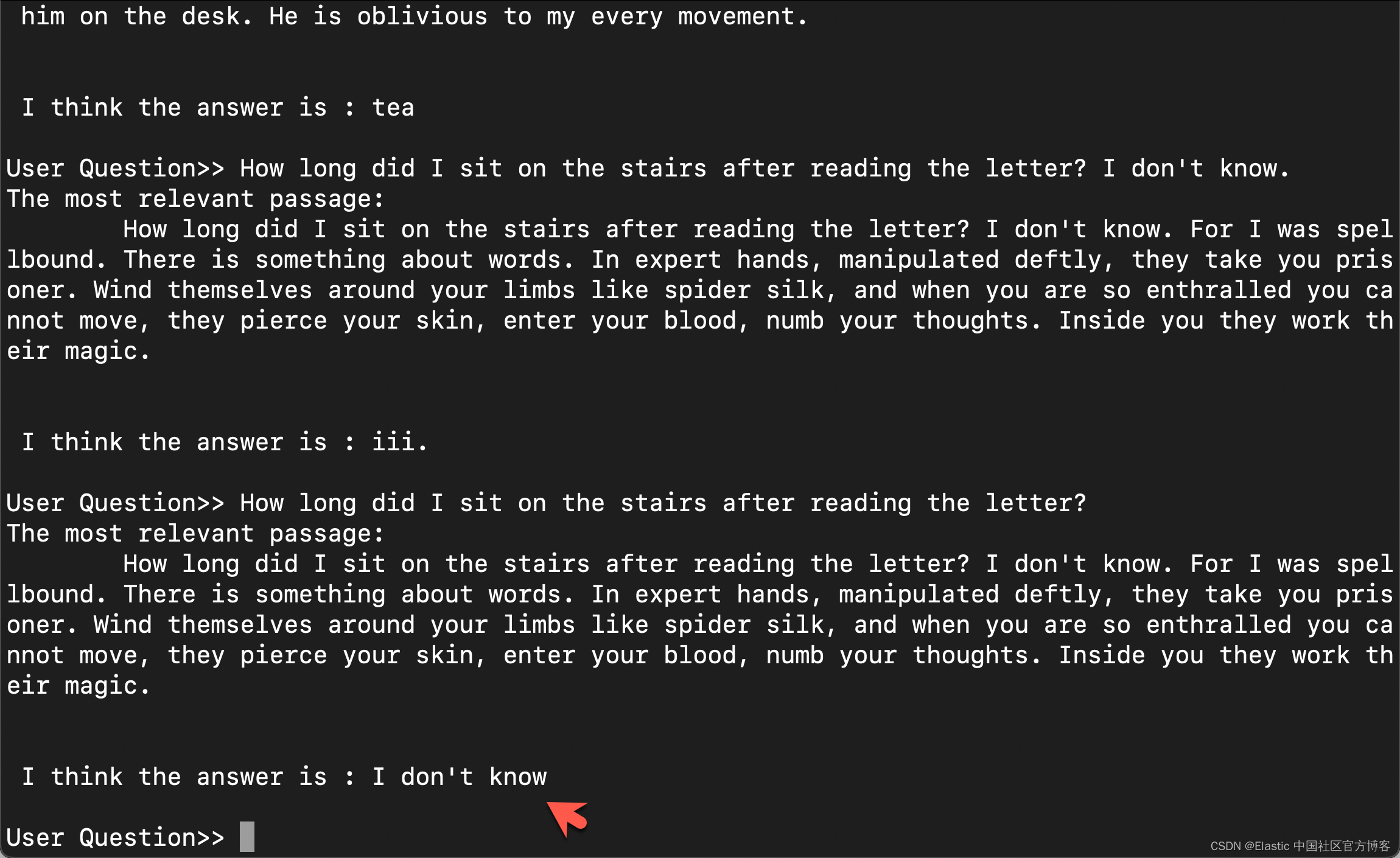
上面的问题是:
How long did I sit on the stairs after reading the letter?
Hooray! 我们完成了问答系统。它可以完美地回答我书里的内容。是不是觉得很神奇 :)
版权归原作者 Elastic 中国社区官方博客 所有, 如有侵权,请联系我们删除。