
目录
最近,AIGC 这块领域可谓是热火朝天。OpenAI 研究的 Sora 宣布刚不久,许多新兴 AI 公司便紧随其后,各种各样的 AI 视频生成大模型如雨后春笋般在这个行业中涌现,许多中国公司也开始推出了自己的 AI 视频生成产品。近几天,我也在看许多 AI 相关的资讯,媒体都把那些大模型吹得天花乱坠。这些消息勾动了我的好奇心,于是将一部分目前比较流行的 AI 视频生成大模型浅浅地体验了一下。本文就给大家介绍一下目前的几个 AI 视频生成大模型,并评价一下这些模型的浅体验(文生视频)效果。
国外 AI 视频生成大模型
Sora——值得期待的引领者

官方描述拥有强大的能力
Sora 是美国人工智能研究公司 OpenAI 推出的人工智能文生视频大模型。 它于 2024 年 2 月 15 日(美国当地时间)正式对外发布,根据官方的报告以及相关资讯,Sora 可以根据用户的文本提示创建最长 60 秒的逼真视频,了解这些物体在物理世界中的存在方式,可以深度模拟真实物理世界。它能生成具有多个角色、包含特定运动的复杂场景,继承了 DALL-E 3 的画质和遵循指令能力,能理解用户在提示中提出的要求。
一经发布,立即爆火
Sora 官方给出的示例生成视频的提示词是:
A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about.
在 Sora 生成的视频里,女士身着黑色皮衣、红色裙子在霓虹街头行走,不仅主体连贯稳定,还有多镜头,包括从大街景慢慢切入到对女士的脸部表情的特写,以及潮湿的街道地面反射霓虹灯的光影效果。

视频发出后,网友用无数种语言,在全球的社交媒体上惊呼:现实,不存在了。
不同业内人士的评价
周鸿祎的评价
360 集团创始人周鸿祎在 Sora 发布后,很快发了一条长微博和视频,预言 Sora 可能给广告业、电影预告片、短视频行业带来巨大的颠覆,但它不一定那么快击败 TikTok,更可能成为 TikTok 的创作工具。
他认为大语言模型的厉害之处在于,能完整地理解这个世界的知识。而此前所有的文生图、文生视频都是在 2D 平面上对图形元素进行操作,并没有适用物理定律。
“这次很多人从技术上、从产品体验上分析 Sora,强调它能输出 60 秒视频,保持多镜头的一致性,模拟自然世界和物理规律,实际这些都比较表象。最重要的是 Sora 的技术思路完全不一样。Sora 产生的视频里,它能像人一样理解坦克是有巨大冲击力的,坦克能撞毁汽车,而不会出现汽车撞毁坦克这样的情况。”
周鸿祎认为,这也代表未来的方向。有强劲的大模型做底子,基于对人类语言的理解,对人类知识和世界模型的了解,再叠加很多其他的技术,就可以创造各个领域的超级工具。并预测,Sora 的出现,或意味着 AGI 实现将从 10 年缩短到 1 年。
(摘自《Sora 火爆 3 天,圈内人士纷纷表态》)
陈楸帆的评价
知名科幻作家、中国科普作家协会副理事长陈楸帆长期从事科幻文学、影视相关领域的工作。他说:这几天圈子里都在讨论 Sora,跟同类 AI 相比,它进步还挺大的。”陈楸帆也曾用 Pika、Runway 等大模型制作过视频,但无论是时长、精细程度,都是 Sora 更胜一筹。“现在 Sora 还没向公众开放,发布的视频应该也是精挑细选的。”陈楸帆表示,OpenAI 的 CEO 山姆·奥特曼是业内公认的营销高手,他在此时放出示例视频,吊足了市场胃口。奥特曼拟为 AI 芯片计划“募资 7 万亿美元”,Sora 发布必然有造势的目的。
陈楸帆认为,Sora 已经能理解现实世界的部分物理规则,比如空间透视、物体遮挡、液体流动等,但这种认识水平可能更像是低龄儿童,常有各种误判,所以一些示例视频中还有不自然的地方。后期,随着AI训练量的累计,应该还能越来越好。他认为,Sora 还不够成熟稳定,这是 OpenAI 未将其向公众开放的原因之一。
至于 Sora 对于行业的影响,陈楸帆认为,短期不会有颠覆性影响,中长期(3~5年)则有可能。“影视、游戏行业以往需要建模的场景、人物以后都有望通过 AI 来完成。甚至一些科研工作中,需要物理模拟大气、水体的流动扩散,以后也可能用 Sora 实现。”
(摘自《Sora 降世,行业变天?业内人士:不慌!》)
值得期待的引领者
虽然 Sora 目前还处在内测阶段,但它还是一个很值得期待的 AI 产品。由于未向大众开放,这里不作体验及评价。
现在,各大视频网站上已经出现了很多各种 Sora 实测的视频,虽然无法确定“实测”的真实性,但可见 AIGC 的视频还是有一定质量的。虽然这些视频时不时露出一点“马脚”(比如老爷爷拄的拐杖不会拿起来再放下),但根据既往 OpenAI 取得的一些成绩,成熟后的 Sora 还是值得期待的。希望 Sora 将来随着训练量的增加,能够变得更好!
Dream Machine——宣传虽好,但仍需努力

新兴的 AI 视频生成大模型
2024 年 6 月 13 日,由硅谷知名创投公司安德森·霍洛维茨(Andreessen Horowitz,简称 a16z)投资的美国初创公司 Luma AI,宣布推出其文生视频/图生视频模型 Dream Machine,并免费向公众开放。 它可以通过文字或图片生成高质量的逼真视频。更重要的是,它的 API 免费向全球用户开放试用,用户进入官网后用谷歌账号登录即可马上试用。这个大模型还承诺,可以在 120 秒内生成一个包含 120 帧的高质量视频。每位用户每月可以免费生成 30 次视频。(本人实测:另外,免费版每天只能最多生成 5 个视频)
Dream Machine 一出,瞬间吸引了大批用户前来使用,服务器一度被挤爆。Dream Machine 高质量的生成效果也获得了不少网友的好评。
媒体强烈的追捧
Dream Machine 一经发布,各大媒体都炸了锅。大家可以看看下面这些标题:
最强视频大模型易主?比 Sora 更真实还直接免费!服务器瞬间挤爆
服务器被挤爆!英伟达投资、效果直逼“电影级”,这款视频 AI 火了
AI 视频新霸主诞生!Dream Machine 官宣免费用,电影级大片全网玩疯
不可否认,Dream Machine 在一开始的确表面上得到了非常好的反响。可是我个人认为,很多文章都是基于 Luma 官方发布的生成视频 demo 作出的评价的。比如某文章这样写道:
不过好在,Dream Machine 的视频生成表现,没有辜负网友们的耐心等待。从 Luma 官方发布的 demo 就可以看出,其生成的视频可谓是“电影感”十足。
结果,其官方发布的示例视频与我自己生成的视频的质量,简直就是天壤之别。本人只能说,有的时候公司官方的东西是权威的、有效的,可有的时候是基于一些商业目的的。
更有甚者,直接做出了一个让人难以理解的判断。这是某文章中的内容:

截图末尾这个人本来写的是:“The quality is awful.”
文章里翻译的是:“果不其然最后「真香」了。”
文章当中还补充道:“这个视频质量是值得等一会儿的。”
。。。
不过在网络上各种各样的文章中,也有一些披露缺点的。比如烟雾飘散形态不太正常、小狗动作有点扭曲等,但这都是小事。接下来我给大家看一下我的实测体验。
实测体验:粗糙的画质,游戏般的运镜
登录过程
在这里给大家放一下 Dream Machine 的官网:Dream Machine - Lumalabs
这个网站要去访问的话是需要翻墙的,打开后是这样的界面:
我们点击右上角“Try Now”,登陆 Google 账号即可使用。
体验过程
进入 Dream Machine 的创作界面,我输入的提示词是:
A man wearing a white space suit floats in space, showing an incredible expression, surrounded by dazzling stars, the International Space Station, and the beautiful Earth. Lens from close to far.
得到的视频是:
Dream Machine Video Demo
视频当中,远处星星和地球的样子还是比较真实的,但一眼看去,瑕疵也非常多。
首先,我们把目光聚集在远处的两位宇航员身上。一开始出现的左边的宇航员手臂只有大臂,小臂和手直接消失了;随着镜头推移,右边的宇航员也露了出来,也是没有小臂和手。另外,两位宇航员身上都没有系安全绳而他们背后的国际空间站(International Space Station),实际呈现的只是三块孤零零漂浮的太阳能板!更令人诧异的是,一开始左边的宇航员还漂浮在远处的空间站的前面,镜头一转,他就马上飘到空间站的背后了。根据视频当中的细节,空间站是离镜头越来越远,而宇航员在视频的末尾却飘到空间站后面去了——这只能说明一点,视频中的宇航员的移动速度是比空间站要快的。
我们再来看一看前景的人物。Dream Machine 对于宇航员的面部神态和身上的宇航服的刻画还是不错的。但有些缺憾的地方是这个人头盔上的光线:光打得太聚焦了,不像太阳射出的光线,显得有些虚假。
在整个视频当中,我们可以看到它的运镜。我在输入的过程中给出的提示词是:
Lens from close to far.
但是实际的运镜是环绕式的:宇航员从画面最右侧出现,镜头一直向右,然后忽地向前,宇航员从画面左侧消失。这样僵硬的运镜方式,让人不禁想到了游戏当中的画面变化。
另外,令整个视频大打折扣的地方就是清晰度。在我体验其他模型的过程中,我发现,别的模型都能生成较高清晰度的视频,可唯独 Dream Machine 的清晰度非常糟糕。这也是我认为 Luma 将来需要改进的地方之一。
总之,一句话:“理想很丰满,现实很骨感。”
宣传虽好,但仍需努力
作为今年刚推出的新兴 AI 视频生成大模型,我们可以看出,Dream Machine 刚一发布,反响非常好,同时媒体也把 Dream Machine 和它属于的初创公司 Luma 吹得天花乱坠。Dream Machine 官方展示的示例视频也看起来非常不错。可是实际体验起来,这款大模型的瑕疵还是非常多的。或许,Dream Machine 会随着训练量的增加成为一款炙手可热的 AI 产品,但或许它也会湮没在 AIGC 汹涌的浪潮当中。不管怎么样,我认为,Dream Machine 和 Luma 还是需要继续努力,不断优化和改进自己,让这款 AI 视频生成大模型不断完善、稳定。
国内 AI 视频生成大模型
即梦——表现不错的国内霸主

功能强大的国内领头羊
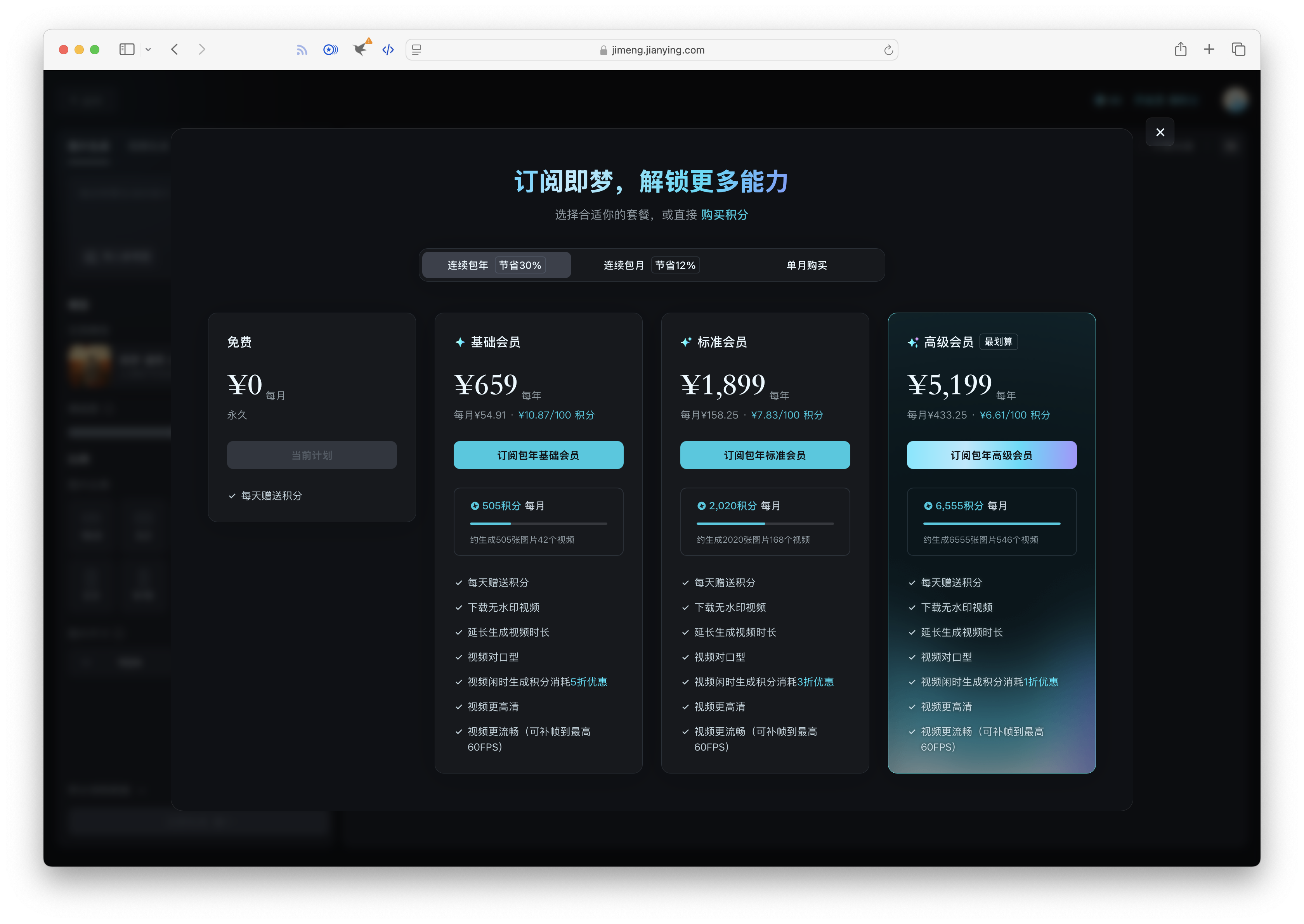
即梦 AI 是字节跳动旗下的一个生成式人工智能创作平台,原名 Dreamina。 它支持通过自然语言及图片输入,生成高质量的图像及视频。这款模型提供智能画布、故事创作模式、以及首尾帧、对口型、运镜控制、速度控制等 AI 编辑能力,并有海量影像灵感及兴趣社区,一站式提供用户创意灵感、流畅工作流、社区交互等资源,为用户的创作提效。即梦 AI 的免费用户,每天会赠送 60 积分。图片生成每次收取 1 积分,但是视频的话,根据生成的时间长短,需要收取的积分从 12 到 48 不等。
抖音生态,前景光明
抖音在 AIGC 的布局已成矩阵。近几年,工具方面,抖音已先后推出 AI 聊天产品“豆包”、AIGC 聚合工具产品“小悟空”;营销方面,巨量引擎推出智能成片工具,定位 AI 智能混剪工具,免费开放给抖音商家使用。内容创作方面,除了即梦外,抖音内部正在开发一款名为“轻涂”的创作平台,或将在不久后上线。
(摘自《抖音测试首个图文类 AIGC 工具 Dreamina,用于抖音内容创作》,有删改)
即梦 AI 与抖音在很大程度是共享用户基数的,这一事实无疑为这款视频编辑工具注入了巨大的潜力。
想象一下,当抖音上的亿万用户发现,他们可以直接通过即梦编辑出专业级的视频内容时,这将是一种怎样的震撼?抖音平台的影响力与即梦的专业性相结合,将激发出无数创意与灵感的火花。
即梦能否成为未来之星或许还需要打上一个问号,但是依托抖音给予的良好生态环境,或许能为即梦在用户积累上减少不小的压力。而这种模式的潜力不容忽视,在保证文生视频和图生视频的基本功能下,如何让用户更为简便的在抖音、剪映进行内容创作,成为了即梦的重要市场。
最后,从技术的角度来看,即梦虽然在 AI 视频生成方面取得了一定的成果,但与其他同类产品相比,其技术水平和创新能力仍有待提高。例如,在视频生成的细节处理、光影效果、物理模拟等方面,即梦可能还需要进一步的优化和提升。如果即梦不能在这些方面取得突破,哪怕是拥有如此庞大的用户基数的前提下,也可能很难在竞争激烈的市场中脱颖而出。
(摘自《大模型测评 | 国内Sora平替?字节 Dreamina 更名“即梦”,到底效果如何?》,有删改)
实测体验:帧率低,错误多,但效果不错
登录过程
即梦 AI 的官方网站是:即梦 AI - 一站式AI创作平台
打开后是这样的界面:
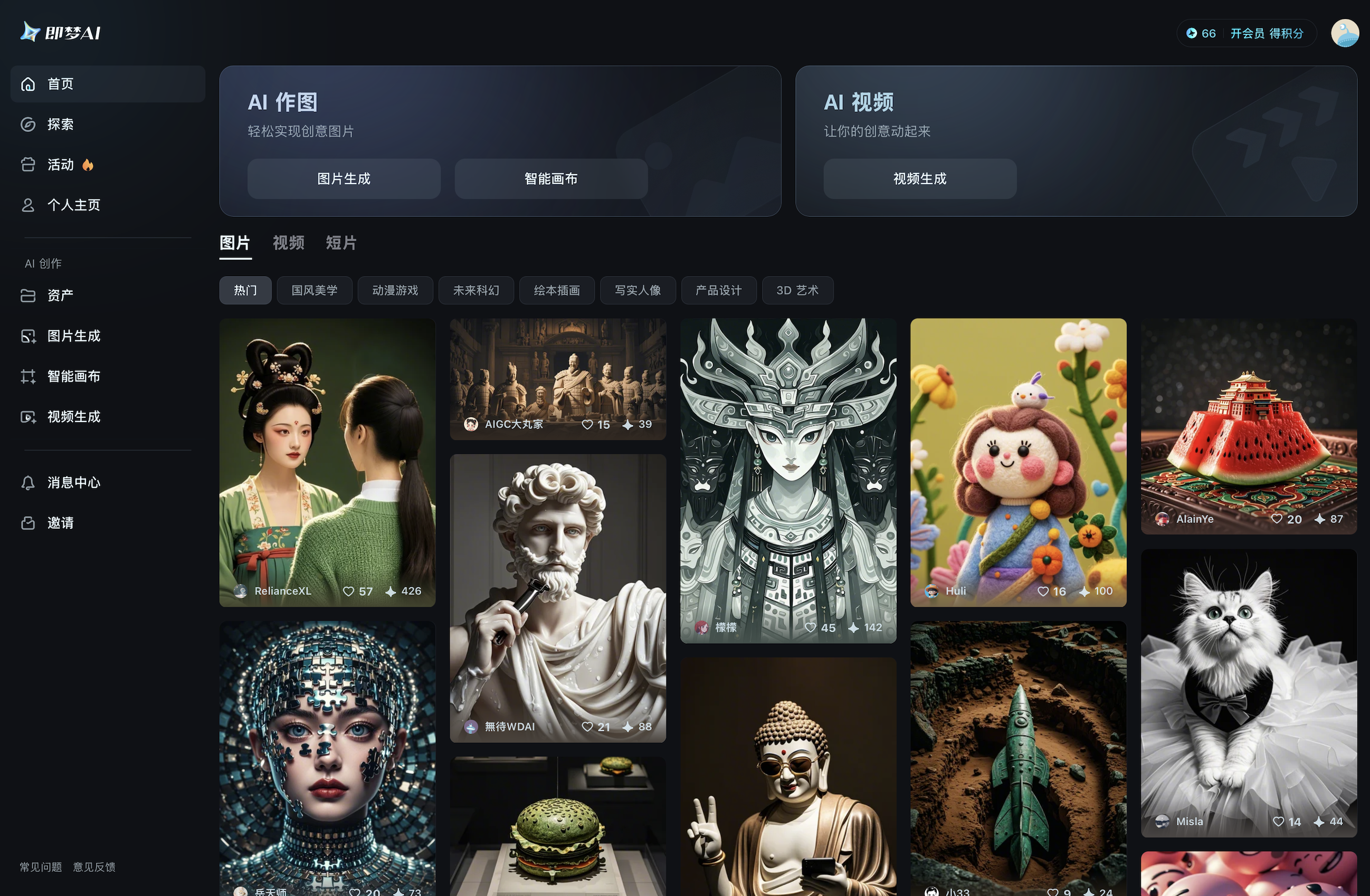
登录后,它会展示这样的界面,里面有“AI 作图”和“AI 视频”两大功能,我们这次只谈“AI 视频”这个功能里面的“文本生视频”。
相对于 Dream Machine,即梦生成视频的界面有更多选项,风格也更多样:

接下来跟大家分享一下我的体验过程——
体验过程
体验即梦时,我也用了和 Dream Machine 相同的提示词(为了好对比),只不过是中文版:
一个穿着白色太空服的男人漂浮在太空中,脸上带着不可思议的表情,周围是耀眼的星星、国际空间站和美丽的地球。
后面指定运镜的文字没加,是因为本身上面就有丰富的自定义视频的选项,这就体现了即梦的人性化。我选择的运镜是“变焦拉远·中”,运动速度为“适中”,模式为“标准模式”,时长 6s,视频比例 16:9。得出的视频是这样的:
即梦 AIGC Video Demo
首先,画面出现了一个中国男人和地球这两个基本要素,但没出现应该有的国际空间站。另一个让人诟病的特点就是,画面中这个宇航员居然有三条腿! 但除了这些基本的逻辑错误以外,整体的视频效果还是可以的。画面中对于男人的面部神态刻画可以看出是比 Dream Machine 要细致,地球和远处的星星的刻画也不错,十分真实。
我们还可以明显看出,即梦生成的视频的清晰度比较高,但也有一个显著的缺点:帧率偏低——这就导致画面显得一卡一卡的。后来我在即梦生成的界面当中才看到,它有一个“补帧”的功能,专门为会员开放。也就是说,这个 AI 视频生成大模型本身是可以做到更高的帧率的,可是字节跳动想要 $$,我们也没办法了。

表现不错的国内霸主
总结即梦 AI 的公众表现,用一个词来说,就是低调。从 Dreamina 发布,到改名为即梦 AI,再到现在,这款被部署在字节跳动 AI 生态上的崭新出场的国内 AI 视频生成大模型的宣传都很少,只有许多博主自己测评过。这种低调,让即便自身还未完善的即梦,也能维护好自己的形象。
在网上的博主测试后,我本人又测试了一遍。虽说效果不如网上的那么好,甚至还有一些莫名其妙的逻辑错误(三条腿),但整体效果还是超出我的预期了。毕竟在浅浅体验了 Dream Machine 之后,我对国内 AIGC 产品的预期大大降低,看到国内的视频生成大模型即梦 AI 能够有如此表现,我也是十分惊讶。即梦真的可以称为表现不错的国内霸主了。
如上文我在写即梦“抖音生态,前景光明”的时候引用的第二篇文章,即梦将来若是能发展起来,一定是非常引人注目的。总之,我们期待吧!
PixVerse——登峰造极的 AI “图片”生成工具

方便快捷的生成式大模型
PixVerse 是由中国公司爱诗科技推出的生成式 AI 大模型,海外版于 2024 年 1 月正式发布。 它目前已上线了“Text to Video(文生视频)”、“Image to Video(图生视频)”、“Character to Video(角色生视频)”三大功能。PixVerse 操作界面简单、视频生成速度快,一上线便迅速成为全球用户量最大的国产 AI 视频生成工具。
在底层技术上,PixVerse 采用的是与另一个视频生成大模型 Pika 相同的 Diffusion 模型,通过引入噪声并学习从噪声状态恢复原始数据,生成新数据点,可生成和编辑视频片段,具有高视觉质量和创意灵活性。
迅猛发展,昂首前进
今年 1 月,爱诗科技旗下产品 PixVerse 上线,它的用户主要来自海外,目前用户总量已经突破百万。
与海外同类产品相比,PixVerse 上线时间较晚,但发展很快。北京智源人工智能研究院今年 5 月发布的文生视频评测结果显示,PixVerse 整体性能位列全球第三名,次于 Sora(OpenAI 旗下文生视频产品)和 Runway(美国头部文生视频产品),优于 Pika(美国头部文生视频产品)。
PixVerse 上线之初就面向全球,爱诗科技联合创始人谢旭璋认为:“AI 视频生成天然具有全球化机会。”他说,在移动互联网时代,全世界最成功的短视频产品 TikTok 就发源于中国;在 AI 时代,中国的 AI 视频生成公司也具备和海外头部公司同台竞争的实力。
(摘自《一批中国 AI 应用已登陆美国》)
6 月 14 日,每日经济新闻与上海电影联合主办的以“当 IP 遇见 AI 打开光影新视野”为主题的海上论坛领衔第二十六届上海国际电影节,旨在探讨人工智能技术如何赋能影视产业,推动 IP 的创新与跨界融合。
在海上论坛现场,爱诗科技联合创始人谢旭璋观察到,目前整个 AI 在所有视频内容中的占比非常小。“无论是消费端还是在创作端,全球 AI 创作的视频总量大概在几亿量级,而全世界一天人类创作的视频量可能就是几亿。”
作为 AI 视频生成赛道的头部公司,爱诗科技的视频生成大模型产品 PixVerse 目前得到广泛应用,也是当前用户量最大的国产 AI 视频生成产品。
在谢旭璋看来,目前 AI 视频仍处于一个比较早期的赛道,它并没有真正普及到所有的内容创作者、所有的内容消费过程中。虽然当下 AI 赛道发展迅速,但仍有很长的道路需要走,未来这一领域将有更多的希望。
“视频是人类目前传输信息最主要的媒介载体之一,它不仅仅是一个内容,也是一个巨大的商业生态。在视频中不仅可以看内容、看故事,也可以在里面做生意、直播带货、做本地生活等。所以我们认为在整个 AI 生成领域里面,视频会是最大的商业机会。”
(摘自《爱诗科技联合创始人谢旭璋:在 AI 生成领域,视频将是最大的商业机会》)
实测体验:明为视频,实为图片
登录过程
PixVerse 的登录过程其实很简单,这是官网:PixVerse - Create breath-taking videos with PixVerse AI
我们进入官网后,点击“Get Started in Web”。有三种登录方式:使用 Google 登录、使用 Discord 登录、使用邮箱登录。如果选择邮箱的话,需要先注册账号。注册账号的入口在“Login with Google”的上方。
进入主界面,我们可以看到上方的三个功能。这次我们只体验“Text to Video”。

注:最近 PixVerse 推出了一个重磅功能 Magic Brush,在网上爆火,但它只针对“Image to Video”,由于篇幅有限,这里就不体验了。
进入之后,里面的界面是这样的,可以看出非常简介而人性化:

接下来给大家分享一下我生成视频的过程。
体验过程
我在 PixVerse 上使用的 Prompt 与前面体验 Dream Machine 时使用的相同:
A man wearing a white space suit floats in space, showing an incredible expression, surrounded by dazzling stars, the International Space Station, and the beautiful Earth. Lens from close to far.
下方有一个 Negative Prompt,是我之前没见过的,我做了了解之后,把意思简单放在下面:
Negative Prompt 是 AI 生成图片或视频时使用的提示词的一种,中文名叫“反向提示词”。任何你不想在生成的视频里面看到的错误,都可以写在下面。常见的比如:
bad anatomy、
extra fingers、
poorly drawn hands、
too many fingers、
long neck等。
由于之前即梦 AI 在没有反向提示词的情况下生成出了三条腿,所以这次我在 Negative Prompt 的下面输入了:
extra legs
。
Negative Prompt 的下面有一个“Inspiring prompt to dual clips”,可以生成两个镜头,我开启了这一项。风格的话,我使用了“Realistic(写实风)”。视频比例 16:9。
最后生成的的效果如下:
PixVerse Video 1
PixVerse Video 2
两个视频,采用了不同的角度和运镜方式,但生成的效果却非常像。PixVerse 的清晰度和真实度的确是 Dream Machine 和即梦无法比拟的。除了宇航员左臂上的美国国旗以外,基本上没有出现什么逻辑错误。但令人遗憾的一件事是,这两个视频缺少了“视频”的性质,只是把一张照片进行运镜,画面中的任何物体(除了美国国旗)都是纹丝不动的。 我认为,使用这样的模型进行 AI 图片创作是非常好的,但是它在视频方面仍需要加强,起码能保证视频能“动”起来。这是 PixVerse 的缺点。
登峰造极的 AI “图片”生成工具
从产品的历史来看,PixVerse 相较于目前国内外许多比较流行的视频生成大模型而言,发布时间是比较早的。PixVerse 的名声也远播海内外。实际使用上,它的界面非常简洁且人性化,生成的视频的质量无论是从逻辑错误数量还是整体清晰度上来说,都是令人赞叹不已的。 我相信,PixVerse 如果去生成图像,那么它的优势肯定会在市场上十分明显。目前,以我的角度,PixVerse 仍需要改进的是视频的“移动性”,也就是让视频“活”起来,真正体现视频的性质,这样 PixVerse 生成的视频才会更加广泛地被视频创作者应用起来。(不然,放在创作者剪辑的视频当中时,给观看者的感觉就是一张图片被进行简单的变焦运镜)以我概括的方式来形容 PixVerse,它真是登峰造极的 AI “图片”生成工具了。
总结
本篇文章,我一共介绍了 4 个较为流行的 AI 视频生成大模型,体验了其中 3 个(除了还没有开放公共体验渠道的 Sora)。这些模型整体上表现各有优劣,但都具备一个特点:生成效果没有达到官方发出的生成预览 demo。
个人认为,虽然 AIGC 产品大量涌现而产生的“内卷”给许多职业的从事者带来了巨大压力,但实际上 AI 将来要走的路还很长——因为许多新兴的大模型的训练量还很少,还不能完全地应用到大部分行业当中。李彦宏也在 2024 世界人工智能大会暨人工智能全球治理高级别会议全体会议上呼吁:“大家不要卷模型,要卷应用!” 随着人工智能正以一种前所未有的势头迅猛发展,目前行业迫切需要拓宽应用范围,让 AI 产品渗透到人们日常生活的方方面面,以发挥 AI 行业的产业价值。
希望将来 AI 视频生成大模型能够变得越来越成熟,同时也希望 AI 行业蓬勃发展!
版权归原作者 YoungGeeker 所有, 如有侵权,请联系我们删除。